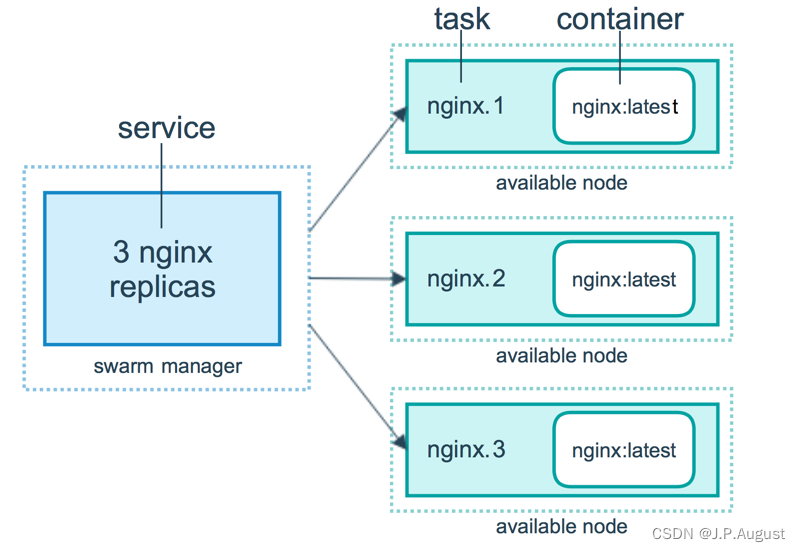
在国内,对海量 RDF 数据的管理有着迫切的实际需求;
RDF:Resource Description Framework,是一个使用XML语法来表示的资料模型(Data model),用来描述Web资源的特性,及资源与资源之间的关系。
Virtuoso可以对 RDF 数据进行有效的存储和管理;
基于Virtuoso 进行 RDF 数据存储的应用也越来越多,BioGateway、Bio2RDF、DBpedia-live 和 Neurocommons;
Virtuoso 提供的开源版本能支持数十亿规模的三元组存储和管理;
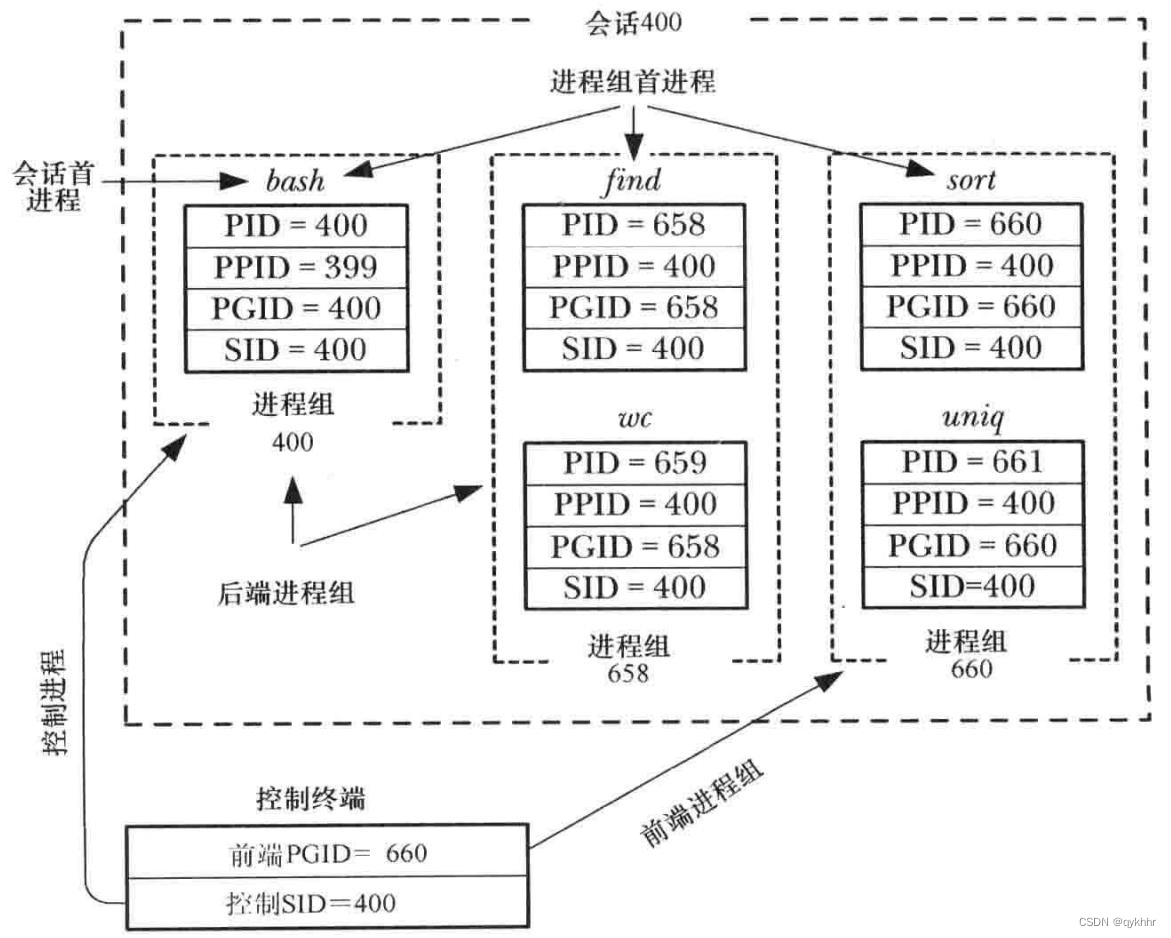
系统架构
Virtuoso 是 OpenLink 公司开发的一款跨平台的对象关系数据库、虚拟 / 通用数据库,拥有强大的过程语言,支持 Java 和.Net 语言的内嵌,可以通过 Web、Web Services、ODBC 和 JDBC 等 进 行 数 据 的 访 问;
JDBC 指 Java 数据库连接,是一种标准Java应用编程接口( JAVA API),用来连接 Java 编程语言和广泛的数据库;
Virtuoso在现有( 对象) 关系数据库上增加了对 RDF 数据的支持,一方面可以充分利用传统数据库的事务处理、查询优化、访问控制、日志和数据恢复等功能,技术成熟度高、系统稳定,另一方面可以实现语义数据和其他数据的无缝连接。

存储模式
Virtuoso 的 RDF 存储机制则是对三元组表模式的一种扩展形式,增加了一列 G 用于对命名图( name graph) 的支持,把所有的三元组连同命名图信息存放在四元组表 DB.DBA.RDF_QUAD 中
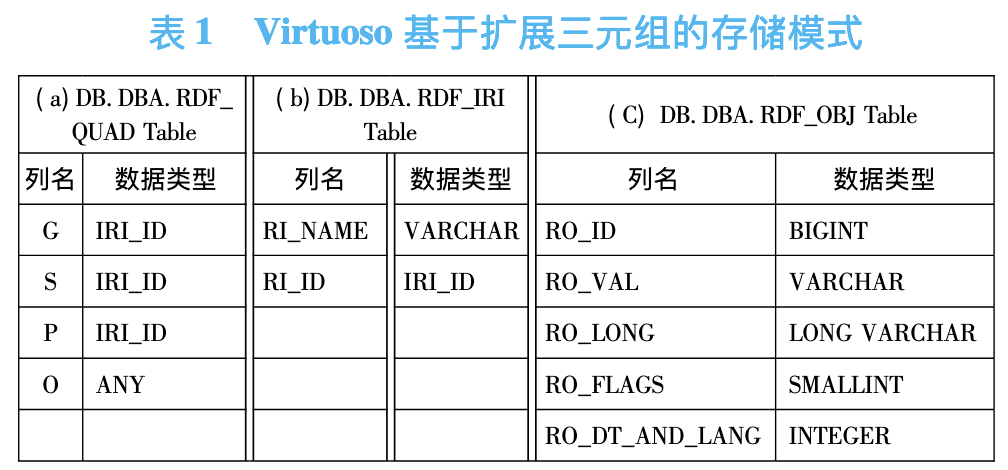
(表中的 G、S、P 和 O 列分别对应命名图、主语、谓语和宾语,为了减少存储空间,将 IRI ( 或URI) 和一些长的 Literal 存放在一些辅组表中,增加两种新的数据类型 IRI_ID 和 ANY 来支持不同表中的数据映射,IRI_ID 为一个 32 位的无符号整数,允许 4G 个不同的 IRI,可以支持数十亿三元组的数据规模,如果数据集规模较大,还可以将 IRI_ID 动态升级到 64 位。)
Virtuoso 不建议用户直接去操作这些表,因为系统通过一种特殊的方式对这些表中的数据进行了索引和缓存,而这些索引和缓存不会随着这些表中的数据的变化而自动进行更新,如果直接对这些表进行数据更新,将会造成数据的不一致性,形成一些脏数据,对这些表中的操作则可通过系统提供的 ISQL、SPARQL 或 HTTP 等方式进行。
查询策略
SPARQL 是 W3C 提出的针对 RDF 数据的查询语言标准,为了利用( 对象) 关系数据库成熟的查询处理技术来支持 SPARQL 查询,流行的方式采用将 SPARQL 直接映 射 到 SQL 的 方 式 来实现,这 样 仅 需 编 写SPARQL 编译器,简化了实现 SPARQL 查询执行引擎的工作量。
Virtuoso 采用了一种更加高效的方式 ,其对原有的 SQL 编译器进行了函数扩充,像 GROUP BY 和其他聚合函数子句一样,Virtuoso 将 SPARQL 查询模式当成一个子查询( 派生表) 内嵌在 SQL 中,这样就避 免 了 编 写 SPARQL 编 译 器 的 工 作,还 可 以 避 免SPARQL 与 SQL 转换后可能出现的 SQL 语句代价过高的问题。
参考论文:http://exhib.nstl.gov.cn/files/3/lw/2011BAH10B03+%E9%82%B9%E7%9B%8A%E6%B0%91+1.pdf