1、Seata是什么
Seata 是一款开源的分布式事务解决方案,致力于提供高性能和简单易用的分布式事务服务。Seata 将为用户提供了 AT、TCC、SAGA 和 XA 事务模式,为用户打造一站式的分布式解决方案。AT模式是阿里首推的模式,阿里云上有商用版本的GTS(Global Transaction Service 全局事务服务)
官网:https://seata.io/zh-cn/index.html
源码: https://github.com/seata/seata
官方Demo: https://github.com/seata/seata-samples
seata版本:v1.4.0
1.1 Seata的三大角色
在 Seata 的架构中,一共有三个角色:
- TC (Transaction Coordinator) - 事务协调者:维护全局和分支事务的状态,驱动全局事务提交或回滚。
- TM (Transaction Manager) - 事务管理器:定义全局事务的范围:开始全局事务、提交或回滚全局事务。
- RM (Resource Manager) - 资源管理器:管理分支事务处理的资源,与TC交谈以注册分支事务和报告分支事务的状态,并驱动分支事务提交或回滚。
其中,TC 为单独部署的 Server 服务端,TM 和 RM 为嵌入到应用中的 Client 客户端。
在 Seata 中,一个分布式事务的生命周期如下:
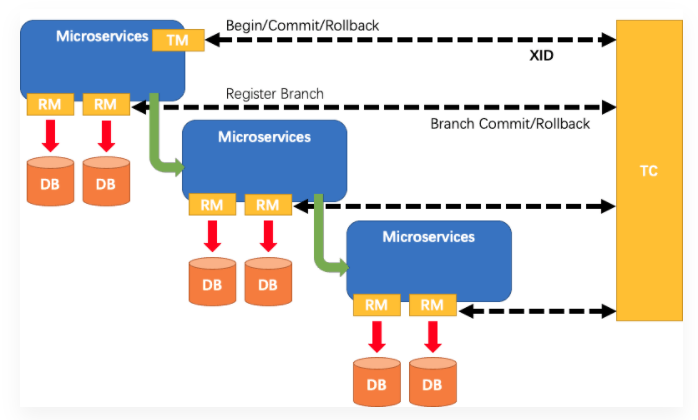
1、TM 请求 TC 开启一个全局事务。TC 会生成一个 XID 作为该全局事务的编号。XID,会在微服务的调用链路中传播,保证将多个微服务的子事务关联在一起。当一进入事务方法中就会生成XID , global_table 就是存储的全局事务信息。
2、RM 请求 TC 将本地事务注册为全局事务的分支事务,通过全局事务的 XID 进行关联。当运行数据库操作方法,branch_table 存储事务参与者。
3、TM 请求 TC 告诉 XID 对应的全局事务是进行提交还是回滚。
4、TC 驱动 RM 们将 XID 对应的自己的本地事务进行提交还是回滚。

1.2 设计思路
AT模式的核心是对业务无侵入,是一种改进后的两阶段提交,其设计思路如图:
第一阶段
业务数据和回滚日志记录在同一个本地事务中提交,释放本地锁和连接资源。核心在于对业务sql进行解析,转换成undolog,并同时入库,这是怎么做的呢?先抛出一个概念DataSourceProxy代理数据源,通过名字大家大概也能基本猜到是什么个操作,后面做具体分析。
参考官方文档: https://seata.io/zh-cn/docs/dev/mode/at-mode.html
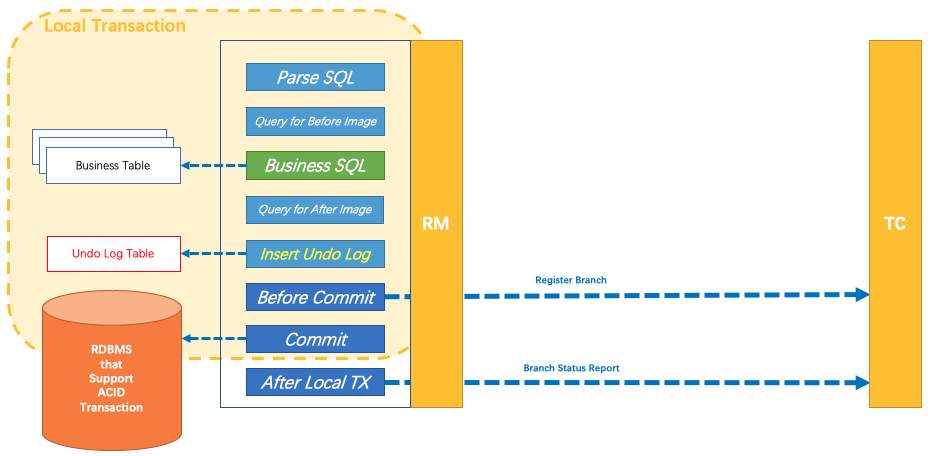
第二阶段
分布式事务操作成功,则TC通知RM异步删除undolog。
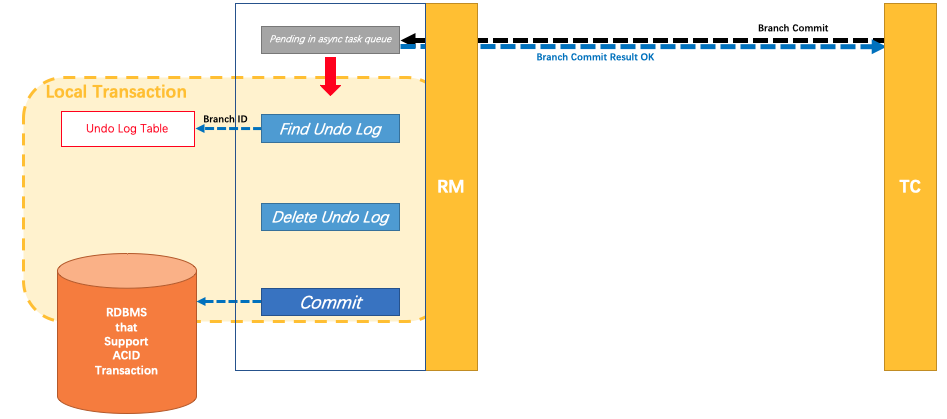
分布式事务操作失败,TM向TC发送回滚请求,RM 收到协调器TC发来的回滚请求,通过 XID 和 Branch ID 找到相应的回滚日志记录,通过回滚记录生成反向的更新 SQL 并执行,以完成分支的回滚。
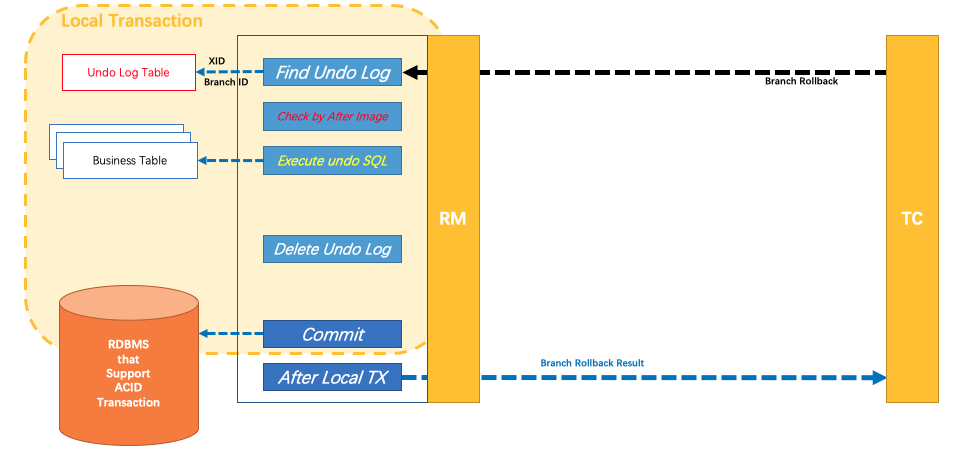
整体执行流程
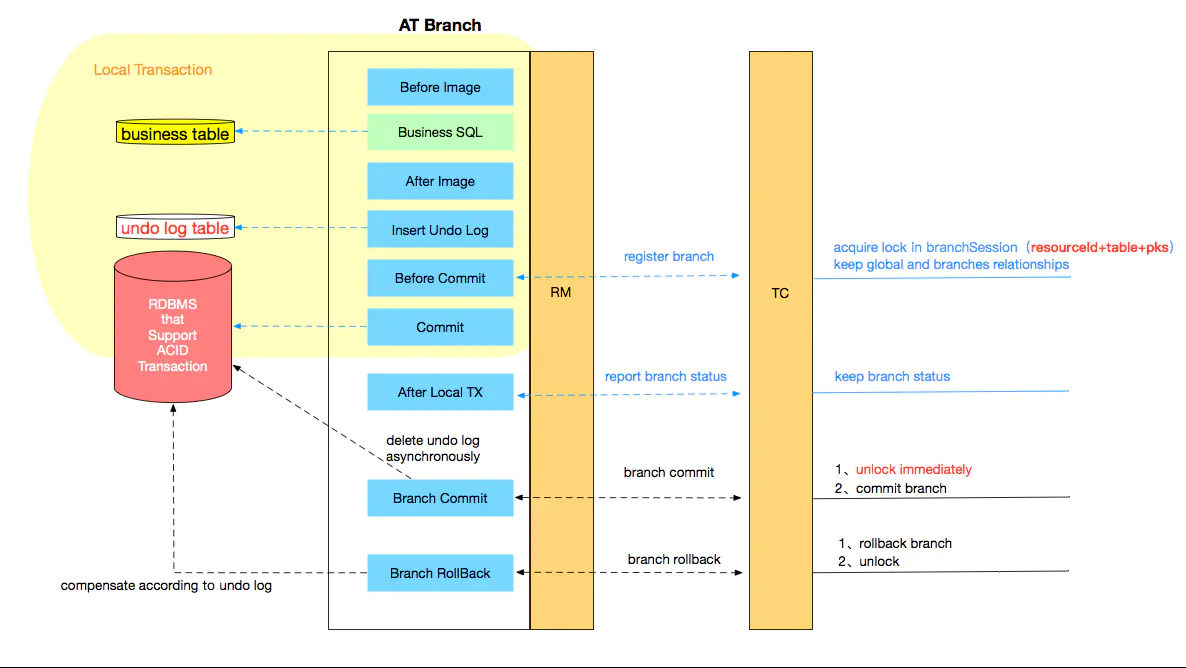
1.3 设计亮点
相比与其它分布式事务框架,Seata架构的亮点主要有几个:
1、应用层基于SQL解析实现了自动补偿,从而最大程度的降低业务侵入性;
2、将分布式事务中TC(事务协调者)独立部署,负责事务的注册、回滚;
3、通过全局锁实现了写隔离与读隔离。
1.4 存在的问题
性能损耗
一条Update的SQL,则需要全局事务xid获取(与TC通讯)、before image(解析SQL,查询一次数据库)、after image(查询一次数据库)、insert undo log(写一次数据库)、before commit(与TC通讯,判断锁冲突),这些操作都需要一次远程通讯RPC,而且是同步的。另外undo log写入时blob字段的插入性能也是不高的。每条写SQL都会增加这么多开销,粗略估计会增加5倍响应时间。
性价比
为了进行自动补偿,需要对所有交易生成前后镜像并持久化,可是在实际业务场景下,这个是成功率有多高,或者说分布式事务失败需要回滚的有多少比率?按照二八原则预估,为了20%的交易回滚,需要将80%的成功交易的响应时间增加5倍,这样的代价相比于让应用开发一个补偿交易是否是值得?
全局锁
热点数据
相比XA,Seata 虽然在一阶段成功后会释放数据库锁,但一阶段在commit前全局锁的判定也拉长了对数据锁的占有时间,这个开销比XA的prepare低多少需要根据实际业务场景进行测试。全局锁的引入实现了隔离性,但带来的问题就是阻塞,降低并发性,尤其是热点数据,这个问题会更加严重。
回滚锁释放时间
Seata在回滚时,需要先删除各节点的undo log,然后才能释放TC内存中的锁,所以如果第二阶段是回滚,释放锁的时间会更长。
死锁问题
Seata的引入全局锁会额外增加死锁的风险,但如果出现死锁,会不断进行重试,最后靠等待全局锁超时,这种方式并不优雅,也延长了对数据库锁的占有时间。
2、Seata快速开始
2.1 Seata Server(TC)环境搭建
https://seata.io/zh-cn/docs/ops/deploy-guide-beginner.html
步骤一:下载安装包
https://github.com/seata/seata/releases
Server端存储模式(store.mode)支持三种:
- file:(默认)单机模式,全局事务会话信息内存中读写并持久化本地文件root.data,性能较高(默认)
- db:(5.7+)高可用模式,全局事务会话信息通过db共享,相应性能差些
- 打开config/file.conf
- 修改mode=“db”
- 修改数据库连接信息(URL\USERNAME\PASSWORD)
- 创建数据库seata_server
- 新建表: 可以去seata提供的资源信息中下载:
- 点击查看
- \script\server\db\mysql.sql
- branch 表 存储事务参与者的信息
- branch 表 存储事务参与者的信息
store {
mode = "db"
db {
## the implement of javax.sql.DataSource, such as DruidDataSource(druid)/BasicDataSource(dbcp)/HikariDataSource(hikari) etc.
datasource = "druid"
## mysql/oracle/postgresql/h2/oceanbase etc.
dbType = "mysql"
driverClassName = "com.mysql.jdbc.Driver"
url = "jdbc:mysql://192.168.65.220:3306/seata_server"
user = "root"
password = "123456"
minConn = 5
maxConn = 30
globalTable = "global_table"
branchTable = "branch_table"
lockTable = "lock_table"
queryLimit = 100
maxWait = 5000
}
}
- redis:Seata-Server 1.3及以上版本支持,性能较高,存在事务信息丢失风险,请提前配置适合当前场景的redis持久化配置
资源目录:https://github.com/seata/seata/tree/1.3.0/script
- client : 存放client端sql脚本,参数配置
- config-center: 各个配置中心参数导入脚本,config.txt(包含server和client,原名nacos-config.txt)为通用参数文件
- server: server端数据库脚本及各个容器配置
db存储模式+Nacos(注册&配置中心)部署
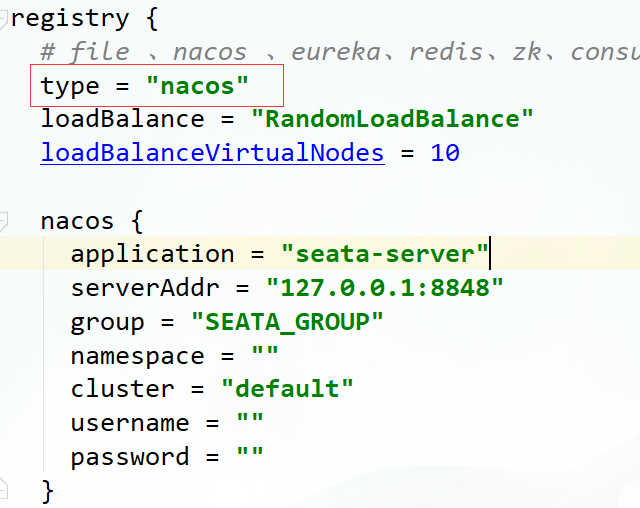
步骤五:配置Nacos注册中心 负责事务参与者(微服务) 和TC通信
将Seata Server注册到Nacos,修改conf目录下的registry.conf配置
然后启动注册中心Nacos Server
#进入Nacos安装目录,linux单机启动
bin/startup.sh -m standalone
# windows单机启动
bin/startup.bat
步骤六:配置Nacos配置中心
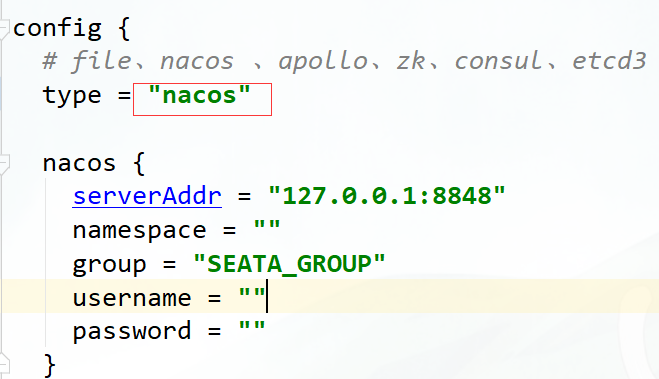
注意:如果配置了seata server使用nacos作为配置中心,则配置信息会从nacos读取,file.conf可以不用配置。 客户端配置registry.conf使用nacos时也要注意group要和seata server中的group一致,默认group是"DEFAULT_GROUP"
获取/seata/script/config-center/config.txt,修改配置信息
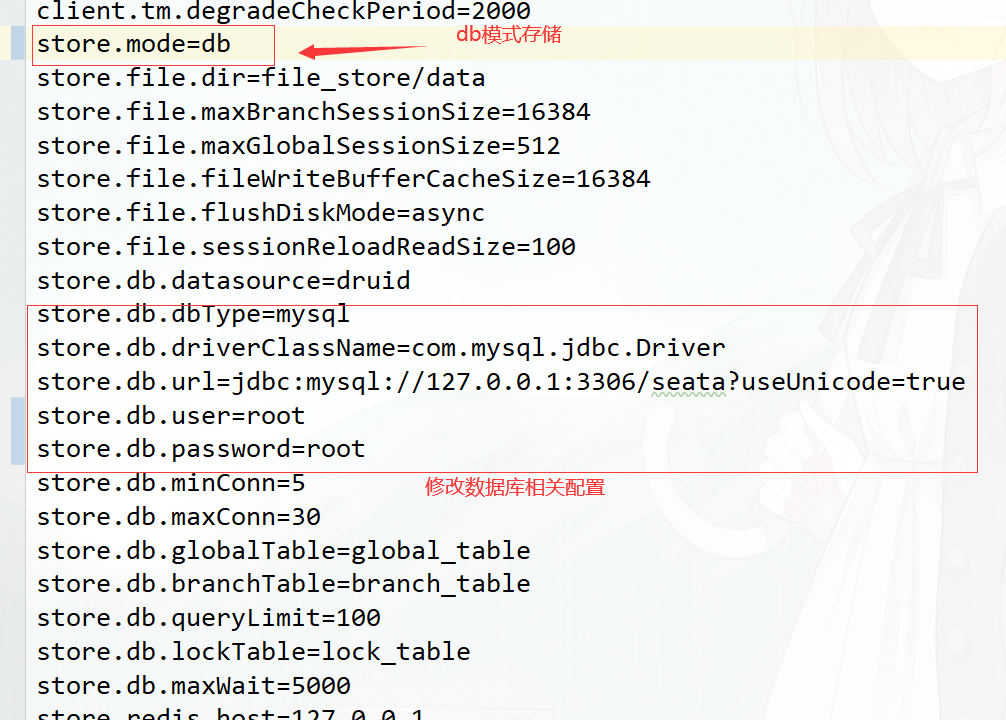
配置事务分组, 要与客户端配置的事务分组一致
#my_test_tx_group需要与客户端保持一致 default需要跟客户端和registry.conf中registry中的cluster保持一致
(客户端properties配置:spring.cloud.alibaba.seata.tx‐service‐group=my_test_tx_group)
事务分组: 异地机房停电容错机制
my_test_tx_group 可以自定义 比如:(guangzhou、shanghai…) , 对应的client也要去设置
seata.service.vgroup-mapping.projectA=guangzhou
default 必须要等于 registry.confi cluster = “default”

配置参数同步到Nacos
shell:
sh ${SEATAPATH}/script/config-center/nacos/nacos-config.sh -h localhost -p 8848 -g SEATA_GROUP -t 5a3c7d6c-f497-4d68-a71a-2e5e3340b3ca
参数说明:
-h: host,默认值 localhost
-p: port,默认值 8848
-g: 配置分组,默认值为 ‘SEATA_GROUP’
-t: 租户信息,对应 Nacos 的命名空间ID字段, 默认值为空 ‘’
精简配置
service.vgroupMapping.my_test_tx_group=default
service.default.grouplist=127.0.0.1:8091
service.enableDegrade=false
service.disableGlobalTransaction=false
store.mode=db
store.db.datasource=druid
store.db.dbType=mysql
store.db.driverClassName=com.mysql.jdbc.Driver
store.db.url=jdbc:mysql://127.0.0.1:3306/seata?useUnicode=true
store.db.user=root
store.db.password=root
store.db.minConn=5
store.db.maxConn=30
store.db.globalTable=global_table
store.db.branchTable=branch_table
store.db.queryLimit=100
store.db.lockTable=lock_table
store.db.maxWait=5000
步骤七:启动Seata Server
- 源码启动: 执行server模块下io.seata.server.Server.java的main方法
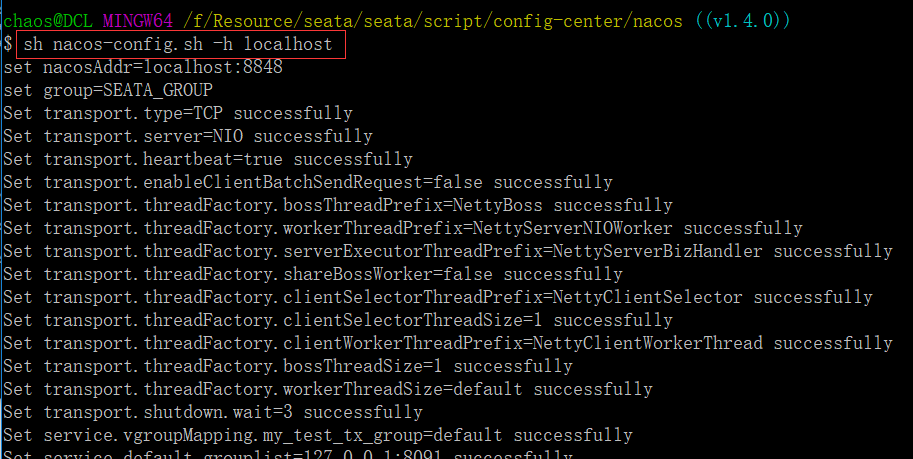
- 命令启动: bin/seata-server.sh -h 127.0.0.1 -p 8091 -m db -n 1 -e test
启动Seata Server
bin/seata-server.sh -p 8091 -n 1
bin/seata-server.sh -p 8092 -n 2
bin/seata-server.sh -p 8093 -n 3
启动成功,默认端口8091

在注册中心中可以查看到seata-server注册成功
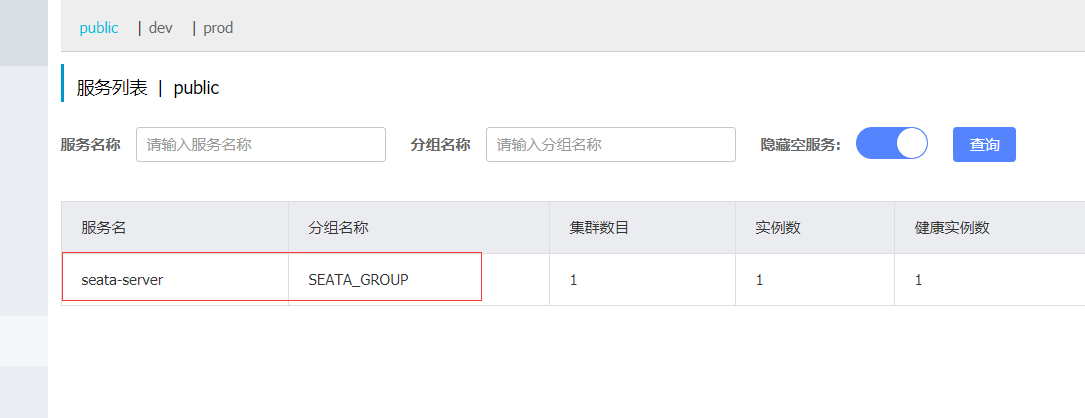
2.2 Seata Client快速开始
接入微服务应用
业务场景:
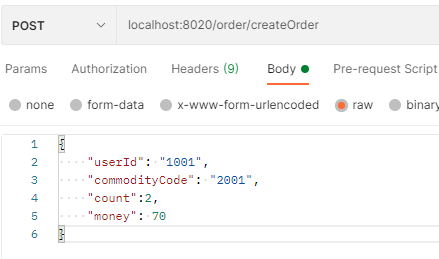
用户下单,整个业务逻辑由三个微服务构成:
- 订单服务:根据采购需求创建订单。
- 库存服务:对给定的商品扣除库存数量。
1) 启动Seata server端,Seata server使用nacos作为配置中心和注册中心(上一步已完成)
2)配置微服务整合seata
第一步:添加pom依赖
<!-- seata-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-seata</artifactId>
</dependency>
第二步: 各微服务对应数据库中添加undo_log表
CREATE TABLE `undo_log` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`branch_id` bigint(20) NOT NULL,
`xid` varchar(100) NOT NULL,
`context` varchar(128) NOT NULL,
`rollback_info` longblob NOT NULL,
`log_status` int(11) NOT NULL,
`log_created` datetime NOT NULL,
`log_modified` datetime NOT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `ux_undo_log` (`xid`,`branch_id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
第三步:修改register.conf,配置nacos作为registry.type&config.type,对应seata server也使用nacos
注意:需要指定group = “SEATA_GROUP”,因为Seata Server端指定了group = “SEATA_GROUP” ,必须保证一致
registry {
# file 、nacos 、eureka、redis、zk、consul、etcd3、sofa
type = "nacos"
nacos {
serverAddr = "localhost"
namespace = ""
cluster = "default"
group = "SEATA_GROUP"
}
}
config {
# file、nacos 、apollo、zk、consul、etcd3、springCloudConfig
type = "nacos"
nacos {
serverAddr = "localhost"
namespace = ""
group = "SEATA_GROUP"
}
}
如果出现这种问题:

一般大多数情况下都是因为配置不匹配导致的:
1.检查现在使用的seata服务和项目maven中seata的版本是否一致
2.检查tx-service-group,nacos.cluster,nacos.group参数是否和Seata Server中的配置一致
跟踪源码:seata/discover包下实现了RegistryService#lookup,用来获取服务列表
NacosRegistryServiceImpl#lookup
》String clusterName = getServiceGroup(key); #获取seata server集群名称
》List<Instance> firstAllInstances = getNamingInstance().getAllInstances(getServiceName(), getServiceGroup(), clusters)
第四步:修改application.yml配置
配置seata 服务事务分组,要与服务端nacos配置中心中service.vgroup_mapping的后缀对应
server:
port: 8020
spring:
application:
name: order-service
cloud:
nacos:
discovery:
server-addr: 127.0.0.1:8848
alibaba:
seata:
tx-service-group:
my_test_tx_group # seata 服务事务分组
datasource:
type: com.alibaba.druid.pool.DruidDataSource
druid:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/seata_order?useUnicode=true&characterEncoding=UTF-8&serverTimezone=Asia/Shanghai
username: root
password: root
initial-size: 10
max-active: 100
min-idle: 10
max-wait: 60000
pool-prepared-statements: true
max-pool-prepared-statement-per-connection-size: 20
time-between-eviction-runs-millis: 60000
min-evictable-idle-time-millis: 300000
test-while-idle: true
test-on-borrow: false
test-on-return: false
stat-view-servlet:
enabled: true
url-pattern: /druid/*
filter:
stat:
log-slow-sql: true
slow-sql-millis: 1000
merge-sql: false
wall:
config:
multi-statement-allow: true
第五步:微服务发起者(TM 方)需要添加@GlobalTransactional注解
@Override
//@Transactional
@GlobalTransactional(name="createOrder")
public Order saveOrder(OrderVo orderVo){
log.info("=============用户下单=================");
log.info("当前 XID: {}", RootContext.getXID());
// 保存订单
Order order = new Order();
order.setUserId(orderVo.getUserId());
order.setCommodityCode(orderVo.getCommodityCode());
order.setCount(orderVo.getCount());
order.setMoney(orderVo.getMoney());
order.setStatus(OrderStatus.INIT.getValue());
Integer saveOrderRecord = orderMapper.insert(order);
log.info("保存订单{}", saveOrderRecord > 0 ? "成功" : "失败");
//扣减库存
storageFeignService.deduct(orderVo.getCommodityCode(),orderVo.getCount());
//扣减余额
accountFeignService.debit(orderVo.getUserId(),orderVo.getMoney());
//更新订单
Integer updateOrderRecord = orderMapper.updateOrderStatus(order.getId(),OrderStatus.SUCCESS.getValue());
log.info("更新订单id:{} {}", order.getId(), updateOrderRecord > 0 ? "成功" : "失败");
return order;
}
测试:
分布式事务成功,模拟正常下单、扣库存,扣余额
分布式事务失败,模拟下单扣库存成功、扣余额失败,事务是否回滚