目录
一、Redis01
1.1 NoSql
1.1.1 NoSql介绍
1.1.2 NoSql起源
1.1.3 NoSql的使用
1.2 常见NoSql数据库介绍
1.3 Redis简介
1.3.1 Redis介绍
1.3.2 Redis数据结构的多样性
1.3.3 Redis应用场景
1.4 Redis安装、配置以及使用
1.4.1 Redis安装的两种方式
1.4.2 Redis配置
1.4.3 远程连接Redis
1.5 Redis简单命令
1.6 常见的数据类型
1.6.1 String类型
1.6.2 list类型
1.6.3 hash类型
1.6.4 set类型
1.6.5 zset类型
1.6.6 各数据的使用场景
一、Redis01
1.1 NoSql
1.1.1 NoSql介绍
NoSQL 是 Not Only SQL 的缩写,意即"不仅仅是 SQL"的意思,泛指非关系型的数据库。强调 Key-Value Stores 和文档数据库的优点。
NoSQL 产品是传统关系型数据库的功能阉割版本,通过减少用不到或很少用的功能,来大幅度提高产品性能
-
不遵循 SQL 标准。 (添加 insert 修改 update )
-
不支持 ACID。
-
远超于 SQL 的性能。
1.1.2 NoSql起源
过去,关系型数据库(SQL Server、Oracle、MySQL)是数据持久化的唯一选择,但随着发展,关系型数据库存在以下问题。
问题 1:不能满足高性能查询需求
我们使用:Java、.Net 等语言编写程序,是面向对象的。但用数据库都是关系型数据库。存储结构是面向对象的,但是数据库却是关系的,所以在每次存储或者查询数据时,我们都需要做转换。类似 Hibernate、Mybatis 这样的 ORM 框架确实可以简化这个过程,但是在对高性能查询需求时,这些 ORM 框架就捉襟见肘了。
问题 2:应用程序规模的变大
网络应用程序的规模变大,需要储存更多的数据、服务更多的用户以及需求更多的计算能力。为了应对这种情形,我们需要不停的扩展。
扩展分为两类:一种是纵向扩展,即购买更好的机器,更多的磁盘、更多的内存等等。另一种是横向扩展,即购买更多的机器组成集群。在巨大的规模下,纵向扩展发挥的作用并不是很大。首先单机器性能提升需要巨额的开销并且有着性能的上限,在 Google 和 Facebook 这种规模下,永远不可能使用一台机器支撑所有的负载。鉴于这种情况,我们需要新的数据库,因为关系数据库并不能很好的运行在集群上
1.1.3 NoSql的使用
①对数据高并发的读写
②海量数据的读写
③对数据高可扩展性的
④秒杀活动
NoSQL 不适用场景
①需要事务支持
②基于 sql 的结构化查询存储,处理复杂的关系,需要即席查询。
当然用不着 sql 的和用了 sql 也不行的情况,考虑用 NoSql
1.2 常见NoSql数据库介绍

1、Memcached
-
很早出现的 NoSql 数据库
-
数据都在内存中,一般不持久化
-
支持简单的 key-value 模式,支持类型单一
-
一般是作为缓存数据库辅助持久化的数据库(MySQL)
2、Redis
-
几乎覆盖了 Memcached 的绝大部分功能
-
数据都在内存中,支持持久化,主要用作备份恢复
-
除了支持简单的 key-value 模式,还支持多种数据结构的存储,比如 list、set、hash、zset 等。
-
一般是作为缓存数据库辅助持久化的数据库
3、MongoDB
-
高性能、开源、模式自由(schema free)的文档型数据库
-
数据都在内存中, 如果内存不足,把不常用的数据保存到硬盘
-
虽然是 key-value 模式,但是对 value(尤其是 json)提供了丰富的查询功能
-
支持二进制数据及大型对象
-
可以根据数据的特点替代 RDBMS,成为独立的数据库。或者配合 RDBMS,存储特定的数
1.3 Redis简介
1.3.1 Redis介绍
① Redis 是一个开源的 key-value 存储系统。
② 和 Memcached 类似,它支持存储的 value 类型相对更多,包括 string(字符串)、list(链表)、set(集合)、zset(sorted set --有序集合)和 hash(哈希类型)。
③ 这些数据类型都支持 push/pop、add/remove 及取交集并集和差集及更丰富的操作,而且这些操作都是原子性的。
④ 在此基础上,Redis 支持各种不同方式的排序。
⑤ 与 memcached 一样,为了保证效率,数据都是缓存在内存中。
⑥ 区别的是 Redis 会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件。
⑦ 并且在此基础上实现了 master-slave(主从)同步。
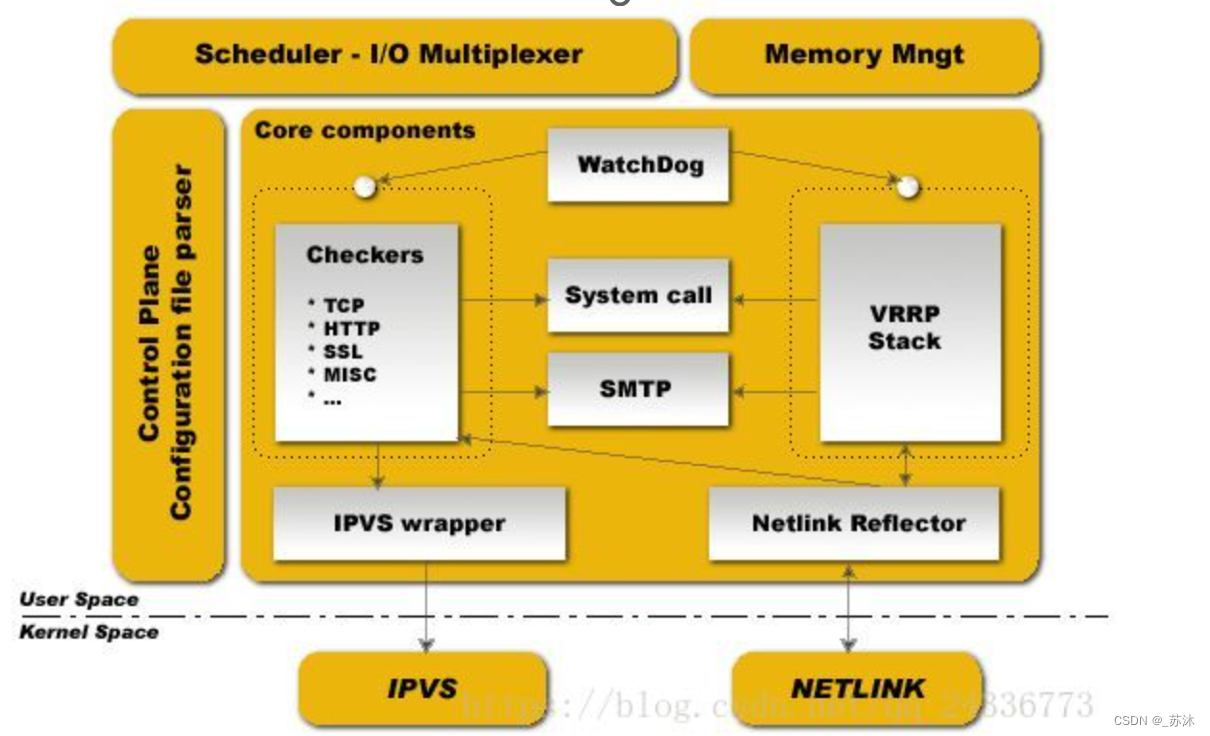
1.3.2 Redis数据结构的多样性
1.3.3 Redis应用场景
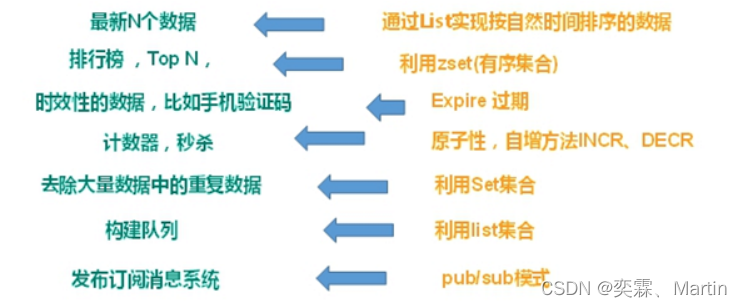
1、数据缓存(提高访问性能)
查询概率 远大于 增删改的概率
将一些数据在短时间之内不会发生变化,而且它们还要被频繁访问,为了提高用户的请求速度和降低网站的负载,降低数据库的读写次数,就把这些数据放到缓存中。
2、会话缓存
session cache,主要适用于 session 共享 (string 类型)
3、排行榜/计数器
(NGINX+lua+redis 计数器进行 IP 自动封禁)(zset)
4、消息队列
(构建实时消息系统,聊天,群聊) (list)
5、统计粉丝数量
对粉丝进行去重(set)
6、用于存储对象 (hash)
Redis各种数据类型应用场景
string :会话信息
list:消息
set:粉丝 共同好友
zset :排行榜
hash: 存储对象1.4 Redis安装、配置以及使用
1.4.1 Redis安装的两种方式
通过压缩包进行安装
1、在官网下载redis压缩包
官网地址:Download | Redis
2、通过Fxtp将压缩包传到Linux系统
3、下载安装redis所依赖的环境
yum -y install gcc-c++
Dependency Updated:
glibc.x86_64 0:2.17-326.el7_9 glibc-common.x86_64 0:2.17-326.el7_9 libgcc.x86_64 0:4.8.5-44.el7 libgomp.x86_64 0:4.8.5-44.el7
libstdc++.x86_64 0:4.8.5-44.el7
Complete!
出现这样的结果就可以4、对压缩包进行解压
tar -zxvf redis-5.0.14.tar.gz5、进入解压后的redis目录,进行编译
[root@localhost tars]# ls
redis-5.0.14 redis-5.0.14.tar.gz
[root@localhost tars]# cd redis-5.0.14
[root@localhost redis-5.0.14]# make
Hint: It's a good idea to run 'make test' ;)
make[1]: Leaving directory `/usr/lwl/tars/redis-5.0.14/src'
出现下面这两句就代表着成功6、安装redis
安装命令:make PREFIX=/usr/lwl/soft/redis install
如果命令执行不成功,换为 make install PREFIX=/usr/lwl/soft/redis
make[1]: Leaving directory `/usr/lwl/tars/redis-5.0.14/src'
最后出现这句即为成功7、启动Redis
进入到安装目录下,找到应用中的bin目录,输入启动命令 ./redis-server
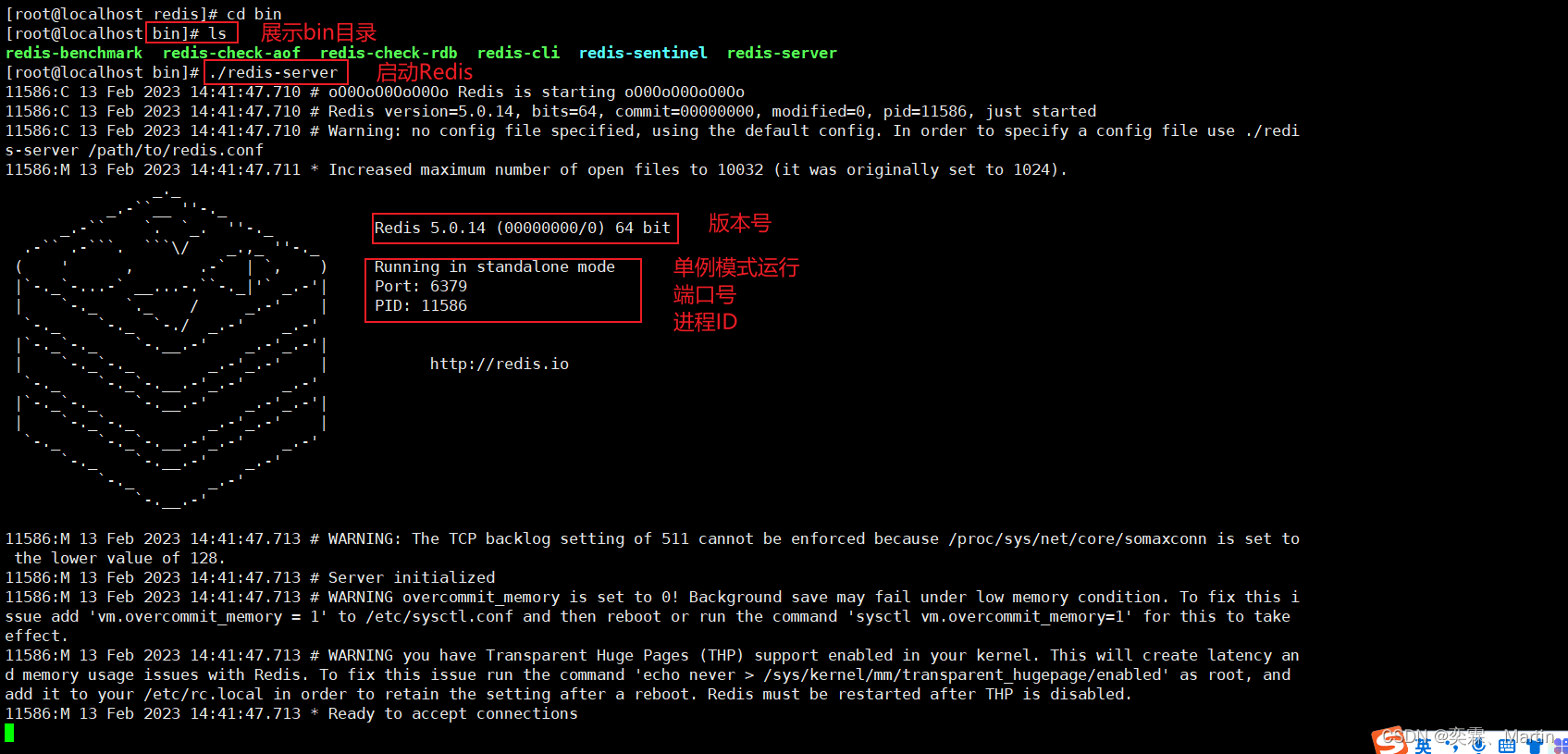
虽然Redis启动成功,但是这种启动方式需要一直打开窗口,不能进行其他操作,不太方便。
使用ctrl+c关闭窗口,程序就停止了
可以修改配置文件解决这个问题
除了使用压缩包安装之外,还有一种使用yum进行安装的方法
1、先查询系统中自带的redis版本
[root@localhost soft]# yum list|grep redis
pcp-pmda-redis.x86_64 4.3.2-13.el7_9 updates 2、使用yum命令进行安装
yum -y install pcp-pmda-redis.x86_643、安装位置
/var/lib/pcp/pmdas/redis1.4.2 Redis配置
将Redis解压目录中的配置文件复制一份,放到应用程序的bin目录下
cp /usr/lwl/tars/redis-5.0.14/redis.conf /usr/lwl/soft/redis/bin/redis.conf1、设置后台启动
在redis.conf 文件将136行的 daemonize no 改成 yes
注:可以在底行 使用 /daemonize 快速查询
134 # By default Redis does not run as a daemon. Use 'yes' if you need it.
135 # Note that Redis will write a pid file in /var/run/redis.pid when daemonized.
136 daemonize yes设置集群时也有可能再改回no
2、设置密码(需要客户端连接时一定要设置密码)
随便在哪一行添加 requirepass 后面的参数是密码
503 # Warning: since Redis is pretty fast an outside user can try up to
504 # 150k passwords per second against a good box. This means that you should
505 # use a very strong password otherwise it will be very easy to break.
506 #
507 requirepass 密码
在设置集群时,最好不要设置密码3、配置远程连接
#注释掉绑定本机,才可以远程连接访问
66 # IF YOU ARE SURE YOU WANT YOUR INSTANCE TO LISTEN TO ALL THE INTERFACES
67 # JUST COMMENT THE FOLLOWING LINE.
68 # ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
69 # bind 127.0.0.14、后台启动Redis
./redis-server ./redis.conf
./redis-server:Redis的服务
./redis.conf: redis的配置
这里如果不使用redis的配置,依然不是后台启动
启动后使用 ps -ef|grep redis 查询进程
[root@localhost bin]# ./redis-server ./redis.conf
11619:C 13 Feb 2023 15:09:31.065 # oO0OoO0OoO0Oo Redis is starting oO0OoO0OoO0Oo
11619:C 13 Feb 2023 15:09:31.066 # Redis version=5.0.14, bits=64, commit=00000000, modified=0, pid=11619, just started
11619:C 13 Feb 2023 15:09:31.066 # Configuration loaded
[root@localhost bin]# ps -ef|grep redis
root 11620 1 0 15:09 ? 00:00:00 ./redis-server *:6379
root 11625 7061 0 15:09 pts/0 00:00:00 grep --color=auto redis5、连接Redis
[root@localhost bin]# ./redis-cli #进行连接
127.0.0.1:6379> ping
(error) NOAUTH Authentication required. #提示输入密码
127.0.0.1:6379> auth 密码 #输入密码
OK
127.0.0.1:6379> ping #ping测试
PONG
127.0.0.1:6379> quit #离开Redis6、连接redis的两种方式
① 只使用密码进行连接
[root@localhost bin]# ./redis-cli -a 密码
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe. #这里会提示命令中携带密码是不安全的
127.0.0.1:6379> ping
PONG
127.0.0.1:6379> ② 完整的命令(用于远程连接redis服务)
[root@localhost bin]# ./redis-cli -h 192.168.111.127 -p 6379 -a 密码
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe. #提示携带密码不安全
192.168.111.127:6379> ping
PONG
192.168.111.127:6379>
-h:代表主机的ip
-p:代表主机的端口号
-a:代表密码
当redis在本机并且端口号是6379时可以省略不写,7、关闭redis的两种方式
① 直接使用密码shutdown
[root@localhost bin]# ./redis-cli -a 密码 shutdown
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
[root@localhost bin]# ps -ef|grep redis
root 11636 7061 0 15:26 pts/0 00:00:00 grep --color=auto redis② 使用完整命令shutdown
[root@localhost bin]# ./redis-cli -h 192.168.111.127 -p 6379 -a 密码 shutdown
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
[root@localhost bin]# ps -ef|grep redis
root 11647 7061 0 15:28 pts/0 00:00:00 grep --color=auto redis
[root@localhost bin]# 8、配置服务启动 (使用 systemctl 的方法)
注:服务启动的时候需要配置文件中的 daemonize 值为no,也就是不允许后台启动
在/lib/systemd/system 目录下创建一个脚本文件 redis.service,里面的内容如下:
[Unit]
Description=Redis
After=network.target
[Service]
ExecStart=/usr/lwl/soft/redis/bin/redis-server /usr/lwl/soft/redis/bin/redis.conf
ExecStop=/usr/lwl/soft/redis/bin/redis-cli -h 127.0.0.1 -p 6379 -a lwl shutdown
[Install]
WantedBy=multi-user.target
配置之前如果没有关闭redis,配置完之后建议重启虚拟机
配置完之后使用的命令:
systemctl daemon-reload 刷新配置
systemctl enable redis 开机自启
systemctl status redis redis 状态
systemctl start redis 开启 redis
systemctl stop redis 关闭 redis
systemctl disable redis 禁止开机自启1.4.3 远程连接Redis
本机可视化的远程连接Linux中的Redis,使用的软件是RESP
连接过程如下: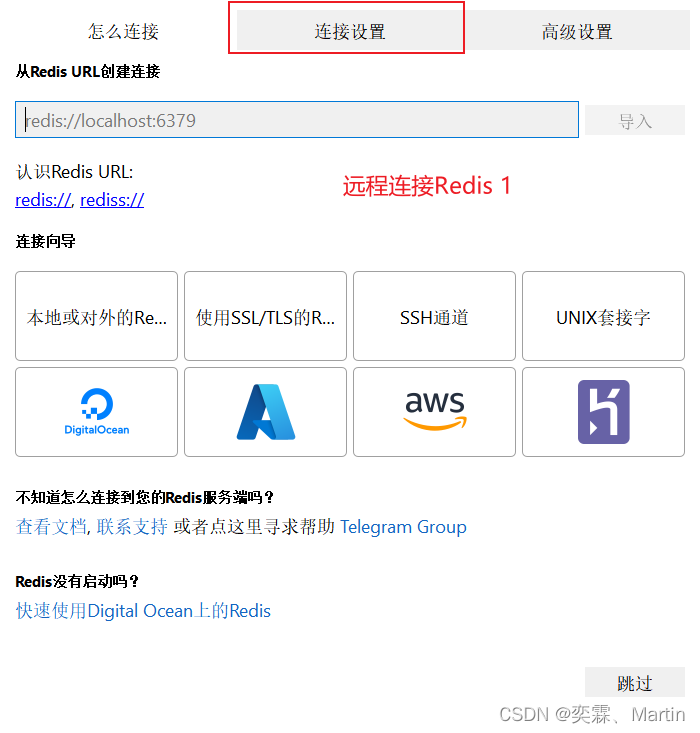


1.5 Redis简单命令
连接之后可以使用一些简单的命令,默认 16 个数据库,类似数组下标从 0 开始,初始默认使用 0 号库
1、查询数据库一共有多少:config get databases
127.0.0.1:6379> config get databases
1) "databases"
2) "16"
在redis.conf文件中第186行可以对初始数据库数量进行设置
2、选中某一个数据库
127.0.0.1:6379> select 1
OK
3、设值、取值
127.0.0.1:6379[1]> set name lwl
OK
127.0.0.1:6379[1]> get name
"lwl"
4、查询当前库所有key值
127.0.0.1:6379[1]> keys *
1) "name"
5、查看当前数据库的 key 的数量
127.0.0.1:6379> dbsize
(integer) 2
6、清空库
flushdb 清空当前库
flushall 清空所有库
7、将当前数据库的key 移动到某个数据库,目标库有,则不嫩移动
将数据库0中的某个key移到数据库1,数据库1有name,没有age
127.0.0.1:6379> move age 1
(integer) 1
127.0.0.1:6379> move name 1
(integer) 0
8、从当前数据库中随机返回一个key值
127.0.0.1:6379> select 1
OK
127.0.0.1:6379[1]> randomkey
"age"
127.0.0.1:6379[1]> randomkey
"name"
127.0.0.1:6379[1]> randomkey
"age"
9、返回key对应的数据类型
127.0.0.1:6379[1]> type name
string
10、删除key
127.0.0.1:6379[1]> del name
(integer) 1
11、判断key值是否存在
127.0.0.1:6379[1]> exists name
(integer) 0
12、给指定的key值设置过期时间
127.0.0.1:6379[1]> expire name 100 #单位是秒
(integer) 1
127.0.0.1:6379[1]> pexpire name 100 #单位是毫秒
(integer) 1
13、删除指定key的过期时间
127.0.0.1:6379[1]> persist name
(integer) 1
14、查看过期时间 (-1表示永不过期;-2表示已经过期)
127.0.0.1:6379[1]> ttl name
(integer) -1 #永不过期1.6 常见的数据类型
1.6.1 String类型
1、简介
String是Redis最基本的类型,你可以理解成与Memcached一模一样的类型,一个key对应一个value。
String类型是二进制安全的。意味着Redis的string可以包含任何数据。比如jpg图片或者序列化的对象。
String类型是Redis最基本的数据类型,一个Redis中字符串value最多可以是512M
2、常用命令
1、 set <key><value>添加键值对
*NX:当数据库中key不存在时,可以将key-value添加数据库
*XX:当数据库中key存在时,可以将key-value添加数据库,与NX参数互斥
*EX:key的超时秒数
*PX:key的超时毫秒数
127.0.0.1:6379[1]> set name yyyy NX
(nil) #因为已经存在了name的key,所以NX添加不进去
127.0.0.1:6379[1]> get name
"fgfg"
127.0.0.1:6379[1]> set name kkll XX
OK #虽然已经有了name的key,使用XX可以添加进去,进行覆盖
127.0.0.1:6379[1]> get name
"kkll"
127.0.0.1:6379> set name XX EX 100 #设置key的过期时间 编写时,要把XX放在前面
OK
2、 get <key>查询对应键值
127.0.0.1:6379> get name
"XX"
3、 setex <key><过期时间><value># 设置键值的同时,设置过期时间,单位秒。
127.0.0.1:6379> setex test 100 test
OK
4、getset <key><value> 以新换旧,设置了新值同时获得旧值。
127.0.0.1:6379> getset test lklk
"test"
5、 mset key1 key2 批量设置key
127.0.0.1:6379> mset aaa a1 bbb b1
OK
6、msetnx <key1><value1><key2><value2>
同时设置一个或多个 key-value 对,当且 仅当所有给定 key 都不存在 才会成功;有一个失败则都失败。
127.0.0.1:6379> msetnx ccc c1 ddd d1
(integer) 1
127.0.0.1:6379> msetnx aaa a2 fff f1
(integer) 0
7、mget key1 key2 批量获取
127.0.0.1:6379> mget aaa bbb
1) "a1"
2) "b1"
8、setnx key value 不存在就插入(not exists)
127.0.0.1:6379> setnx aaa a3
(integer) 0
127.0.0.1:6379> setnx aaaa a4
(integer) 1
9、setrange <key><起始位置index><value> #从 index 开始替换 value
127.0.0.1:6379> get aaa
"a1"
127.0.0.1:6379> setrange aaa 0 1a
(integer) 2
127.0.0.1:6379> get aaa
"1a"
10、getrange <key><起始位置><结束位置>
当结束位置是-1时,代表查询所有的字符串,因为下标从0开始,所以一个字符串的长度是0~n-1
结束位置的值就是n要减去的值
127.0.0.1:6379> get aaa
"12345"
127.0.0.1:6379> getrange aaa 0 -2
"1234"
127.0.0.1:6379> getrange aaa 0 -3
"123"
127.0.0.1:6379> getrange aaa 0 -4
"12"
11、incr <key> 将 key 中储存的数字值增1
只能对数字值操作,如果为空,新增值为1
127.0.0.1:6379> get age
"20"
127.0.0.1:6379> incr age
(integer) 21
127.0.0.1:6379> incr age
(integer) 22
12、decr <key> 将 key 中储存的数字值减1
只能对数字值操作,如果为空,新增值为-1
127.0.0.1:6379> get age
"21"
127.0.0.1:6379> decr age
(integer) 20
127.0.0.1:6379> decr age
(integer) 19
13、incrby <key><步长>将 key 中储存的数字值增加
127.0.0.1:6379> get age
"19"
127.0.0.1:6379> incrby age 10
(integer) 29
14、decrby <key><步长>将 key 中储存的数字值减少。
127.0.0.1:6379> get age
"29"
127.0.0.1:6379> decrby age 5
(integer) 24
15、append <key><value> #将给定的<value> 追加到原值的末尾
127.0.0.1:6379> get aaa
"12345"
127.0.0.1:6379> append aaa 678
(integer) 8
127.0.0.1:6379> get aaa
"12345678"
16、strlen <key> #获得值的长度
127.0.0.1:6379> get aaa
"12345678"
127.0.0.1:6379> strlen aaa
(integer) 8原子性操作
所谓原子操作是指不会被线程调度机制打断的操作;
这种操作一旦开始,就一直运行到结束,中间不会有任何 context switch (切换到另一个线程)。
(1)在单线程中, 能够在单条指令中完成的操作都可以认为是"原子操作",因为中断只能发生于指令之间。
(2)在多线程中,不能被其它进程(线程)打断的操作就叫原子操作。
Redis单命令的原子性主要得益于Redis的单线程。3、数据结构
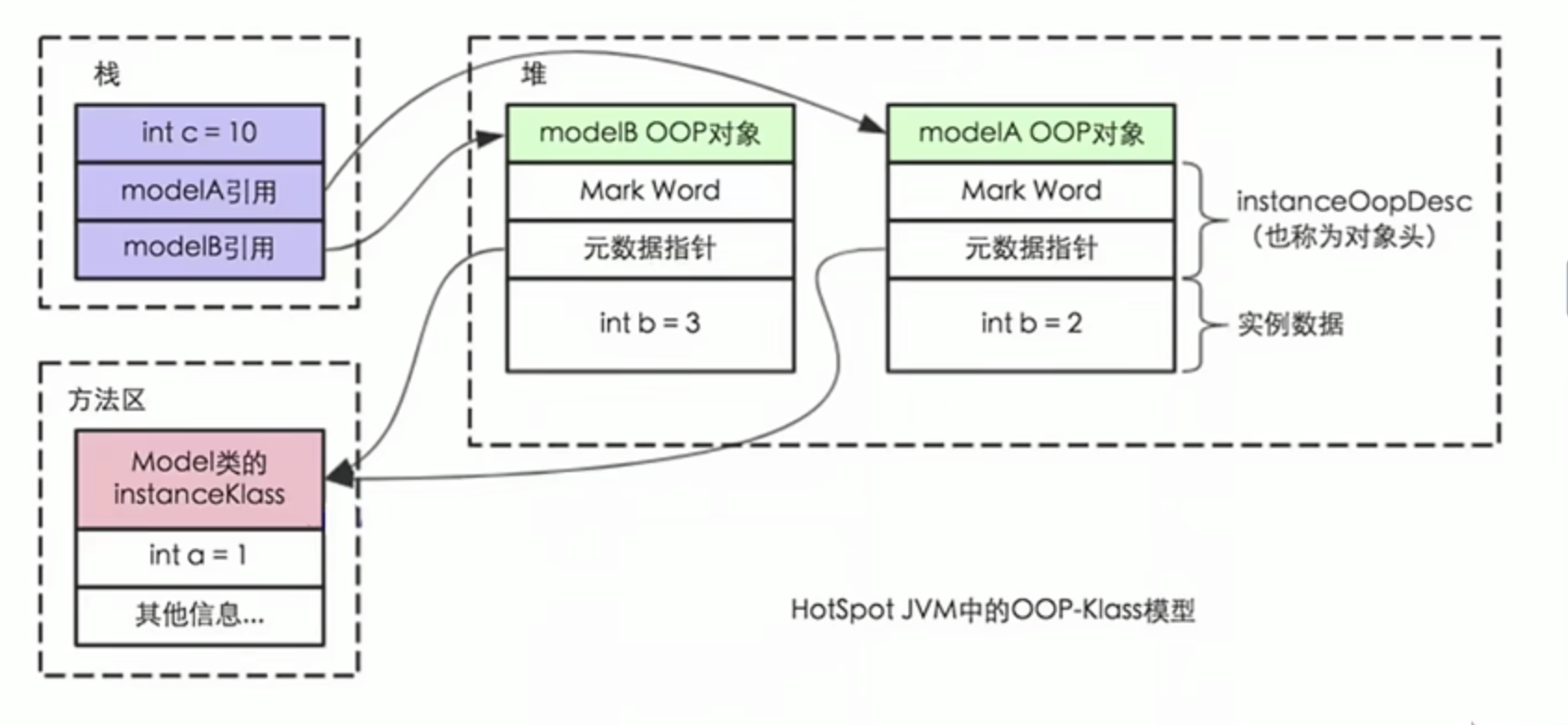
String的数据结构为简单动态字符串(Simple Dynamic String,缩写SDS)。是可以修改的字符串,内部结构实现上类似于Java的ArrayList,采用预分配冗余空间的方式来减少内存的频繁分配.

如图中所示,内部为当前字符串实际分配的空间capacity一般要高于实际字符串长度len。当字符串长度小于1M时,扩容都是加倍现有的空间(2倍),如果超过1M,扩容时一次只会多扩1M的空间。需要注意的是字符串最大长度为512M。
1.6.2 list类型
1、简介
Redis 列表是简单的字符串列表,按照插入顺序排序。你可以添加一个元素到列表的头部(左边)或者尾部(右边)。
它的底层实际是个双向链表,对两端的操作性能很高,通过索引下标的操作中间的节点性能会较差。

两边都可以进行添加或取出 所以取出的顺序可以是 v3 v2 v1 v4 v5
2、常用命令
1、lpush/rpush <key><value1><value2><value3> .... 从左边/右边插入一个或多个值。
127.0.0.1:6379> lpush testlist 1 2 3
(integer) 3
127.0.0.1:6379> rpush testlist 4 5 6
(integer) 6
127.0.0.1:6379> lrange testlist 0 -1
1) "3"
2) "2"
3) "1"
4) "4"
5) "5"
6) "6"
2、lpop/rpop <key> 从左边/右边吐出一个值。值在键在,值光键亡。
127.0.0.1:6379> lpop testlist
"3"
127.0.0.1:6379> lrange testlist 0 -1
1) "2"
2) "1"
3) "4"
4) "5"
5) "6"
127.0.0.1:6379> rpop testlist
"6"
127.0.0.1:6379> lrange testlist 0 -1
1) "2"
2) "1"
3) "4"
4) "5"
3、rpoplpush <key1><key2> 从<key1>列表右边吐出一个值,插到<key2>列表左边。
127.0.0.1:6379> lrange tlist 0 -1 #查询tlist所有值
1) "v2"
2) "v1"
127.0.0.1:6379> lrange testlist 0 -1 #查询testlist所有值
1) "2"
2) "1"
3) "4"
4) "5"
127.0.0.1:6379> rpoplpush testlist tlist #弹出testlist值放到tlist中
"5"
127.0.0.1:6379> lrange tlist 0 -1
1) "5"
2) "v2"
3) "v1"
127.0.0.1:6379> lrange testlist 0 -1
1) "2"
2) "1"
3) "4"
4、lrange <key><start><stop> 按照索引下标获得元素(从左到右)
127.0.0.1:6379> lrange testlist 0 -1
1) "2"
2) "1"
3) "4"
5、lindex <key><index>按照索引下标获得元素(从左到右)
127.0.0.1:6379> lindex testlist 2
"4"
6、llen <key>获得列表长度
127.0.0.1:6379> llen testlist
(integer) 3
7、linsert <key> <before/after> <value><newvalue> 在<value>的后面插入<newvalue>插入值
127.0.0.1:6379> linsert testlist before 4 3 #会在从左往右第一个符合条件的值前面加
(integer) 4
127.0.0.1:6379> lrange testlist 0 -1
1) "2"
2) "1"
3) "3"
4) "4"
8、lrem <key><n><value> 从左边删除n个对应的value值(从左到右)
127.0.0.1:6379> lrange testlist 0 -1
1) "2"
2) "1"
3) "3"
4) "3"
5) "4"
6) "4"
127.0.0.1:6379> lrem testlist 3 3 #删除3个值为3的数,可是只有两个,所以只成功两行
(integer) 2
9、lset<key><index><value>将列表key下标为index的值替换成value
127.0.0.1:6379> lrange testlist 0 -1
1) "2"
2) "1"
3) "4"
4) "4"
127.0.0.1:6379> lset testlist 2 6
OK
127.0.0.1:6379> lrange testlist 0 -1
1) "2"
2) "1"
3) "6"
4) "4"3、数据结构
List的数据结构为快速链表quickList。
① 首先在列表元素较少的情况下会使用一块连续的内存存储,这个结构是ziplist,也即是压缩列表。
压缩列表是将所有的元素紧挨着一起存储,分配的是一块连续的内存。
② 当数据量比较多的时候才会改成quicklist。Redis将链表和ziplist结合起来组成了quicklist,也就是将多个ziplist使用双向指针串起来使用。这样既满足了快速的插入删除性能,又不会出现太大的空间冗余。

因为普通的链表需要的附加指针空间太大,会比较浪费空间。比如这个列表里存的只是int类型的数据,结构上还需要两个额外的指针prev和next。
1.6.3 hash类型
1、简介
hash是一个string类型的field和value的映射表,hash特别适合用于存储对象。
类似Java里面的Map<String,Object>,用户ID为查找的key,存储的value用户对象包含姓名,年龄,生日等信息
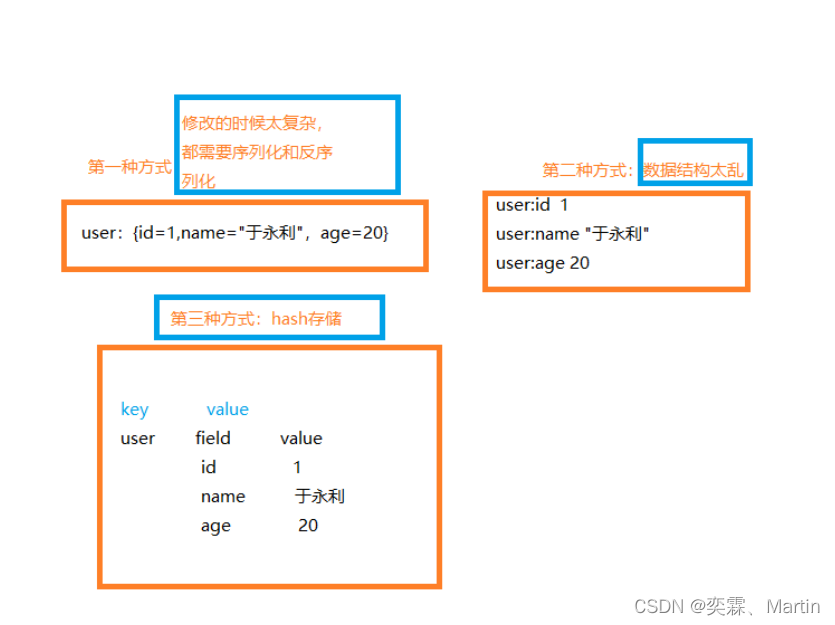
通过第三种方式:( key(用户ID) + field(属性标签)) 就可以操作对应属性数据了,既不需要重复存储数据,也不会带来序列化和并发修改控制的问题
2、常用命令
hset <key><field><value>给<key>集合中的 <field>键赋值<value>
127.0.0.1:6379> hset user name lwl age 30
(integer) 2
hget <key1><field> 从<key1>集合<field>取出 value
127.0.0.1:6379> hget user name
"lwl"
hmset <key1><field1><value1><field2><value2>... 批量设置hash的值
127.0.0.1:6379> hmset people name lwl age 35
OK
hexists<key1><field>查看哈希表 key 中,给定域 field 是否存在。
127.0.0.1:6379> hexists user name
(integer) 1
127.0.0.1:6379> hexists user money
(integer) 0
hkeys <key>列出该hash集合的所有field
hvals <key>列出该hash集合的所有value
127.0.0.1:6379> hkeys user
1) "name"
2) "age"
127.0.0.1:6379> hvals user
1) "lwl"
2) "30"
hincrby <key><field><increment>为哈希表 key 中的域 field 的值加上增量
127.0.0.1:6379> hincrby user age 2
(integer) 32
127.0.0.1:6379> hincrby user age -2
(integer) 30
hsetnx <key><field><value>将哈希表 key 中的域 field 的值设置为 value ,当且仅当域 field 不存在
127.0.0.1:6379> hsetnx user name test
(integer) 0
127.0.0.1:6379> hsetnx user test test
(integer) 13、数据结构
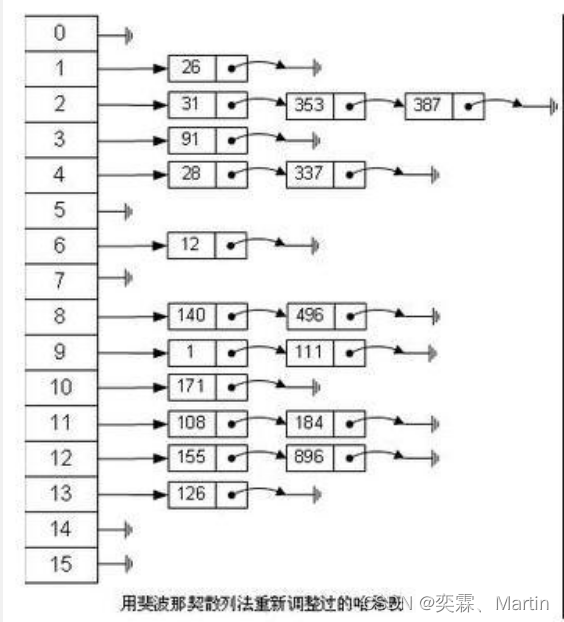
Hash类型对应的数据结构是两种:ziplist(压缩列表),hashtable(哈希表)。当field-value长度较短且个数较少时,使用ziplist,否则使用hashtable。
Hashtable 的实例有两个参数影响其性能:初始容量 和加载因子。容量 是哈希表中桶 的数量,初始容量 就是哈希表创建时的容量。注意,哈希表的状态为 open:在发生“哈希冲突”的情况下,单个桶会存储多个条目,这些条目必须按顺序搜索。加载因子 是对哈希表在其容量自动增加之前可以达到多满的一个尺度。初始容量和加载因子这两个参数只是对该实现的提示。关于何时以及是否调用 rehash 方法的具体细节则依赖于该实现。
通常,默认加载因子(.75)在时间和空间成本上寻求一种折衷。加载因子过高虽然减少了空间开销,但同时也增加了查找某个条目的时间(在大多数 Hashtable 操作中,包括 get 和 put 操作,都反映了这一点)。
初始容量主要控制空间消耗与执行 rehash 操作所需要的时间损耗之间的平衡。如果初始容量大于 Hashtable 所包含的最大条目数除以加载因子,则永远 不会发生 rehash 操作。但是,将初始容量设置太高可能会浪费空间。
如果很多条目要存储在一个 Hashtable 中,那么与根据需要执行自动 rehashing 操作来增大表的容量的做法相比,使用足够大的初始容量创建哈希表或许可以更有效地插入条目。hashtable结构如下图所示:
1.6.4 set类型
1、简介
set对外提供的功能与list类似是一个列表的功能,特殊之处在于set是可以自动排重的,当你需要存储一个列表数据,又不希望出现重复数据时,set是一个很好的选择,并且set提供了判断某个成员是否在一个set集合内的重要接口,这个也是list所不能提供的。
2、常用命令
sadd <key><value1><value2>将一个或多个 member 元素加入到集合 key 中,已经存在的 member元素将被忽略
127.0.0.1:6379> sadd testset v1 v2 v3 v3 v3 v2
(integer) 3
smembers <key>取出该集合的所有值。
127.0.0.1:6379> smembers testset
1) "v2"
2) "v1"
3) "v3"
sismember <key><value>判断集合<key>是否为含有该<value>值,有1,没有0
127.0.0.1:6379> sismember testset v1 #有元素v1
(integer) 1
127.0.0.1:6379> sismember testset v6 #没有元素v6
(integer) 0
scard<key>返回该集合的元素个数。
127.0.0.1:6379> scard testset
(integer) 3
srem <key><value1><value2> 删除集合中的某个元素。
127.0.0.1:6379> srem testset v1 v2 #删除了元素 v1 v2
(integer) 2
spop <key>[count]随机从该集合中吐出几个值。(吐出之后就等于删除)
127.0.0.1:6379> spop testset 2 #随机吐出两个值
1) "v5"
2) "v3"
srandmember <key><n> 随机从该集合中取出n个值。不会从集合中删除
127.0.0.1:6379> srandmember testset 2 #取出两个值
1) "v6"
2) "v4"
smove <source><destination>value 把集合中一个值从一个集合移动到另一个集合
127.0.0.1:6379> sadd testset2 t1 t2 t3
(integer) 3
127.0.0.1:6379> smove testset testset2 v4
(integer) 1
127.0.0.1:6379> smembers testset2
1) "t2"
2) "t1"
3) "v4" #移过来的值
4) "t3"
sinter <key1><key2> 返回两个集合的交集元素。
sunion <key1><key2> 返回两个集合的并集元素。
sdiff <key1><key2> 返回两个集合的差集元素(key1中的,不包含key2中的)
127.0.0.1:6379> smembers testset #查看testset中所有数据
1) "v6"
2) "v4"
127.0.0.1:6379> smembers testset2 #查看testset2中所有数据
1) "t2"
2) "t1"
3) "v4"
4) "t3"
127.0.0.1:6379> sinter testset testset2 #返回两个set的交集
1) "v4"
127.0.0.1:6379> sunion testset testset2 #返回两个set的并集
1) "t1"
2) "v4"
3) "v6"
4) "t3"
5) "t2"
127.0.0.1:6379> sdiff testset testset2 #返回testset中有而testset2中没有的元素
1) "v6"3、数据结构
Set数据结构是dict字典,字典是用哈希表实现的。
Java中HashSet的内部实现使用的是HashMap,只不过所有的value都指向同一个对象。Redis的set结构也是一样,它的内部也使用hash结构,所有的value都指向同一个内部值。
1.6.5 zset类型
1、简介
Redis有序集合zset与普通集合set非常相似,是一个没有重复元素的字符串集合。
不同之处是有序集合的每个成员都关联了一个评分(score),这个评分(score)被用来按照从最低分到最高分的方式排序集合中的成员。集合的成员是唯一的,但是评分可以是重复了 。
因为元素是有序的, 所以你也可以很快的根据评分(score)或者次序(position)来获取一个范围的元素。
访问有序集合的中间元素也是非常快的,因此你能够使用有序集合作为一个没有重复成员的智能列表。
2、常用命令
zadd <key><score1><value1><score2><value2>将一个或多个 member元素及其score值加入到有序集key当中
127.0.0.1:6379> zadd money 1 100 2 90
(integer) 2
zrange <key><start><stop> [WITHSCORES]
返回有序集 key 中,下标在<start><stop>之间的元素 带WITHSCORES,可以让分数一起和值返回到结果集。
127.0.0.1:6379> zadd money 1 100 2 90
(integer) 2
127.0.0.1:6379> zadd money 1 90 #这里已经有了value为90的score2,再次添加会进行覆盖
(integer) 0
127.0.0.1:6379> zadd money 1 80
(integer) 1
127.0.0.1:6379> zrange money 0 2 withscores
1) "100"
2) "1"
3) "80"
4) "1"
5) "90"
6) "1"
zrangebyscore key min max [withscores] [limit offset count]
返回有序集 key 中,所有 score 值介于 min 和 max 之间(包括等于 min 或 max )的成员。有序集成员按 score 值递增(从小到大)次序排列。
zrevrangebyscore key max min [withscores] [limit offset count]
同上,改为从大到小排列。
127.0.0.1:6379> zrangebyscore money 1 2 withscores
#返回score值为1到2的value,并根据score进行排序
1) "100"
2) "1"
3) "80"
4) "1"
5) "90"
6) "1"
7) "85"
8) "2"
9) "95"
10) "2"
zincrby <key><increment><value> 为元素的score加上增量
127.0.0.1:6379> zincrby money 1 100 #如果有这个value和score,会执行成功
"2"
127.0.0.1:6379> zincrby money 1 9 #如果没有这个value或者score,会添加一行
"1"
zrem <key><value>删除该集合下,指定值的元素
127.0.0.1:6379> zrem money 100
(integer) 1
zcount <key><min><max>统计该集合,分数区间内的元素个数
127.0.0.1:6379> zcount money 1 3 #在score值为[1,3]的区间共有五条数据
(integer) 5
zrank <key><value>返回该值在集合中的排名,从0开始。
127.0.0.1:6379> zrange money 0 100
1) "120"
2) "9"
3) "85"
4) "95"
5) "60"
6) "1"
127.0.0.1:6379> zrank money 9 #value值为9的排在第二个
(integer) 1
127.0.0.1:6379> zrank money 60 #value值为60的排在第五个
(integer) 43、数据结构
SortedSet(zset)是Redis提供的一个非常特别的数据结构,一方面它等价于Java的数据结构Map<String, Double>,可以给每一个元素value赋予一个权重score,另一方面它又类似于TreeSet,内部的元素会按照权重score进行排序,可以得到每个元素的名次,还可以通过score的范围来获取元素的列表。
zset底层使用了两个数据结构:
(1)hash,hash的作用就是关联元素value和权重score,保障元素value的唯一性,可以通过元素value找到相应的score值。
(2)跳跃表,跳跃表的目的在于给元素value排序,根据score的范围获取元素列表。
例:对比有序链表和跳跃表,从链表中查询出51
①有序链表:

从1开始对比,依次向后比较,一共要对比六次才能够查询成功
②跳跃表:听起来像是二叉树
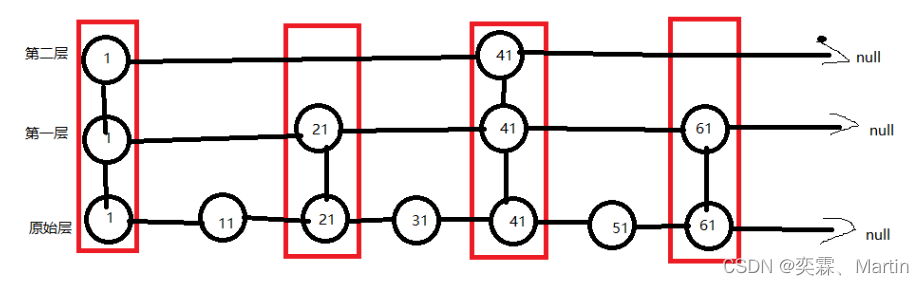
从第二层开始:第一次:和1比较时,51比较大,所以向后比较,
第二次:和41比较时,51比较大,但后面是null,所以先向下,再向后到第一层61
在第一层比较:第一次:和61比较时,51比较小,但前面是刚比较完的41,所以先向下,再向前到原始层51
在原始层比较:第一次:和51比较时,相等,所以就找到了51
一共比较了四次
1.6.6 各数据的使用场景
| 类型 | 简介 | 特性 | 场景 |
|---|---|---|---|
| String(字符串) | 二进制安全 | 可以包含任何数据,比如jpg图片或者序列化的对象,一个键最大能存储512M | --- |
| Hash(字典) | 键值对集合,即编程语言中的Map类型 | 适合存储对象,并且可以像数据库中update一个属性一样只修改某一项属性值(Memcached中需要取出整个字符串反序列化成对象修改完再序列化存回去) | 存储、读取、修改用户属性 |
| List(列表) | 链表(双向链表) | 增删快,提供了操作某一段元素的API | 1、最新消息排行等功能(比如朋友圈的时间线) 2、消息队列 |
| Set(集合) | 哈希表实现,元素不重复 | 1、添加、删除、查找的复杂度都是O(1) 2、为集合提供了求交集、并集、差集等操作 | 1、共同好友 2、利用唯一性,统计访问网站的所有独立ip 3、好友推荐时,根据tag求交集,大于某个阈值就可以推荐 |
| Sorted Set(有序集合) | 将Set中的元素增加一个权重参数score,元素按score有序排列 | 数据插入集合时,已经进行天然排序 | 1、排行榜 2、带权重的消息队列 |





![轨迹误差评估指标[APE/RPE]和EVO](https://img-blog.csdnimg.cn/9d35f2224e894840a49594c7dcfaf622.png)