文章目录
- TensorBoard的使用
- 1、TensorBoard启动:
- 2、使用TensorBoard查看一张图片
- 3、transforms的使用
- pytorch框架基础知识
- 1 nn.module的使用
- 2 nn.conv2d的使用
- 3、池化(MaxPool2d)
- 4 非线性激活
- 5 线性层
- 6 Sequential的使用
- 7 损失函数与反向传播
- 8 优化器
- 9 对现有网络的使用和修改
- 10 网络模型的保存与读取
TensorBoard的使用
1、TensorBoard启动:
在Terminal终端命令中输入:
tensorboard --logdir=logs #logs为创建的文件名
2、使用TensorBoard查看一张图片
writer=SummaryWriter("../logs")
image_path=r'F:\image\1.jpg'
img_PIL=Image.open(image_path)
image_array=np.array(img_PIL)
writer.add_image('test',image_array,1,dataformats='HWC')
writer.close()
3、transforms的使用
作用:使PIL Image 或者np ——》tensor
imgae_path=r'F:\image\1.jpg'
img=Image.open(img_path)
tensor_trans=transsforms.ToTensor() #相当于创建一个工具
tensor_img=tensor_trans(img) #img转化成tensor模式
同理,ToPILIMage是为了tensor 或者 ndarray =》Image
pytorch框架基础知识
1 nn.module的使用
目的:给所有网络提供基本骨架

from torch import nn
class aiy(nn.Module):
def __init__(self):
super().__init__()
def forward(sel,input):
output=input+1
return output
aiy=aiy()
# x=torch.tensor(1.0)
x=1
output=aiy(x)
print(output)
'''
2
'''
2 nn.conv2d的使用
参数代码解释如下:

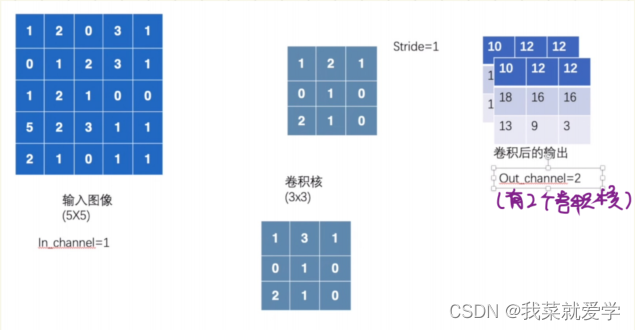
示例:输入一个5x5的矩阵,和一个3x3的卷积核做卷积操作
import torch
import torch.nn.functional as F
input=torch.tensor([[1,2,0,3,1],
[0,1,2,3,1],
[1,2,1,0,0],
[5,2,3,1,1],
[2,1,0,1,1]])
input=input.reshape([1,1,5,5])
kears=torch.tensor([[1,2,1],
[0,1,0],
[2,1,0]])
kears=kears.reshape([1,1,3,3])
output=F.conv2d(input,kears,stride=1)
print(output)
print(output.shape)
'''
tensor([[[[10, 12, 12],
[18, 16, 16],
[13, 9, 3]]]])
torch.Size([1, 1, 3, 3])
'''
若是输入的卷积核的数量有两个,则得到的output也是两个
示例:借用CIFAR10数据集,用自定义的网络模型做一次卷积操作,然后用tensorboard查看卷积之后的结果。
这里需要注意的是,经过卷积得到的大小是[64,6,30,30],而图片的通道一般都是3通道的,6通道的图片不知道怎么显示,需要使用reshpae重新改变矩阵的大小。
output=output.reshape([-1,3,30,30]) #-1自动计算剩余的值,后面[3,30,30]改成指定大小
示例代码:
import torch
import torchvision
from torch.utils.data import DataLoader
from torch import nn
from torch.nn import Conv2d
from torch.utils.tensorboard import SummaryWriter
#数据准备
dataset=torchvision.datasets.CIFAR10("./data",train=False,transform=torchvision.transforms.ToTensor(),download=True)
dataloader=DataLoader(dataset,batch_size=64)
#自定义网络模型
class aiy(nn.Module):
def __init__(self):
super(aiy, self).__init__()
#卷积运算
self.conv1=Conv2d(in_channels=3,out_channels=6,kernel_size=3,stride=1,padding=0)
def forward(self,x):
x=self.conv1(x)
return x
aiy=aiy()
# print(aiy)
step=0
writer=SummaryWriter("../log")
for data in dataloader:
img,targets=data
output=aiy(img)
# print(img.shape)
#torch.Size([64, 3, 32, 32]
# print(output.shape)
#torch.Size([64, 6, 30, 30])
#因为图片的通道是3,需要改变矩阵的大小
# output=output.reshape([-1,3,30,30])
writer.add_images("input",img,step)
output=torch.reshape(output,(-1,3,30,30))
writer.add_images("output", output, step)
# print(output.shape)
step=step+1
print(step)
writer.close()

3、池化(MaxPool2d)
目的:降采样,大幅减少网络的参数量,同时保留图像数据的特征。
需要注意的是: 池化不改变通道数
池化参数

数组演示示例:
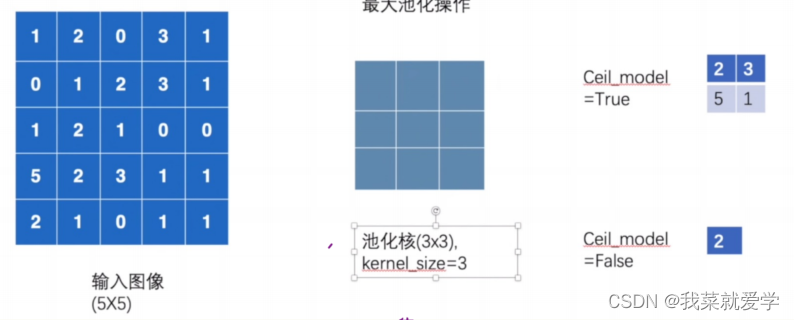
input=torch.tensor([[1,2,0,3,1],
[0,1,2,3,1],
[1,2,1,0,0],
[5,2,3,1,1],
[2,1,0,1,1]],dtype=float)
input=torch.reshape(input,(-1,1,5,5))
output=aiy(input)
print(output.shape)
'''
ceil_mode=True:
tensor([[[[2., 3.],
[5., 1.]]]], dtype=torch.float64)
ceil_mode=False:
tensor([[[[2.]]]], dtype=torch.float64)
'''
示例:同样,借用CIFAR10数据集,用自定义的网络模型做一次池化操作,然后用tensorboard查看卷积之后的结果。
# -*- coding: utf-8 -*-
# Auter:我菜就爱学
import torch
import torchvision
from torch import nn
from torch.nn import MaxPool2d
#带入数组
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
class aiy(nn.Module):
def __init__(self):
super(aiy, self).__init__()
self.maxpool1=MaxPool2d(kernel_size=3,ceil_mode=False)
def forward(self,input):
output=self.maxpool1(input)
return output
aiy=aiy()
#将池化层用数据集测试
dataset=torchvision.datasets.CIFAR10('./data',train=False,transform=torchvision.transforms.ToTensor(),download=True)
dataloader=DataLoader(dataset,batch_size=64)
step=0
writer=SummaryWriter("../logmaxpool")
for data in dataloader:
img,target=data
writer.add_images("input",img,step)
output=aiy(img)
writer.add_images("output",output,step)
step=step+1
有点像打马赛克

4 非线性激活
作用:提高泛化能力,引入非线性特征

ReLu(input,inplace=True)
=>表示原input替换input
out=ReLu(input,inplace=False)
=>表示原input被out替换
5 线性层

6 Sequential的使用
作用:可以简化自己搭建的网络模型
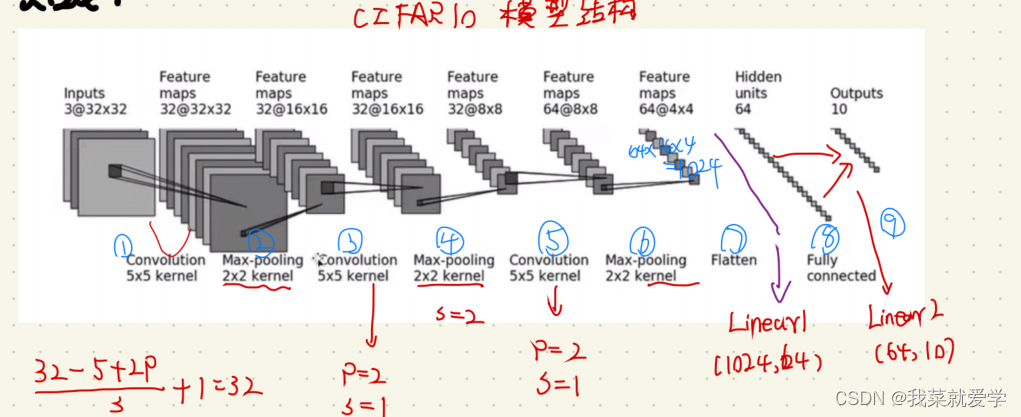
示例:参考CIFAR10的网络模型结构,创建一个网络。
# -*- coding: utf-8 -*-
# Auter:我菜就爱学
import torch
from torch import nn
from torch.nn import Sequential, Conv2d, MaxPool2d, Flatten, Linear
from torch.utils.tensorboard import SummaryWriter
class Aiy(nn.Module):
def __init__(self):
super(Aiy, self).__init__()
self.model=Sequential(
Conv2d(3,32,5,padding=2,stride=1),
MaxPool2d(kernel_size=2),
Conv2d(32,32,5,padding=2),
MaxPool2d(kernel_size=2),
Conv2d(32,64,5,padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024,64),
Linear(64,10)
)
def forward(self,input):
output=self.model(input)
return output
aiy=Aiy()
# print(aiy)
input=torch.ones((64,3,32,32))
output=aiy(input)
print(output.shape)
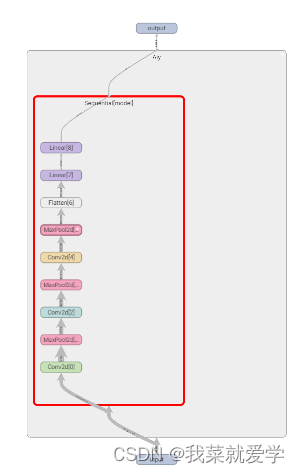
使用tensorboard中的命令可以查看网络模型结构
writer=SummaryWriter('../logmodel')
writer.add_graph(aiy,input)
writer.close()
7 损失函数与反向传播
作用:
- 计算处实际输出与目标之间的差距
- 更新输出提供一定的依据
通过小土堆举的示例可以很好的理解损失函数

说明:假设一张试卷满分是100分,其中选择30,填空20,解答50.第一次我们得到的结果是:选择10,填空10,解答20.第一次损失值是60.
然后通过不断的训练,让选择提高到20,填空提高20,解答提高到40,这个时候与满分差距20,损失值也就越来越小。
# -*- coding: utf-8 -*-
# Auter:我菜就爱学
import torch
from torch.nn import L1Loss
input=torch.tensor([1,2,3],dtype=torch.float32)
input=torch.reshape(input,(1,1,1,3))
target=torch.tensor([1,2,5],dtype=torch.float32)
target=torch.reshape(target,(1,1,1,3))
#设置一个损失函数
loss=L1Loss(reduction='sum')
output=loss(input,target)
print(output)
'''
tensor(2.)
'''
8 优化器
优化器参数解释:

for epoch in range (20):
sum_loss=0.0
for data in dataloader:
imgs,targets=data
output=aiy(imgs)
result_loss=loss(output,targets)
optim.zero_grad()
result_loss.backward() #反向传播,更新对应的梯度
optim.step() #调整更新的参数
sum_loss=sum_loss+result_loss
print(sum_loss)
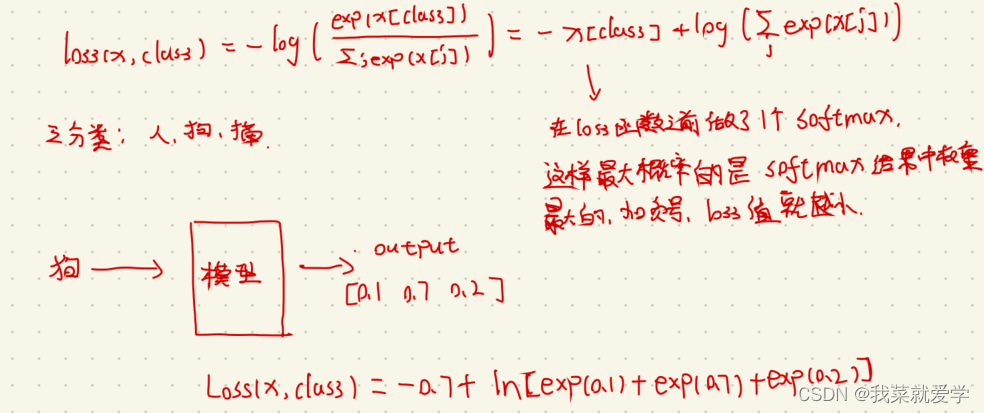
下面是对优化器中的交叉熵的解释:
9 对现有网络的使用和修改
- 下载现有网络,并使用数据集更新好的参数
vgg16_True=torchvision models vgg16(pretrained=True)
一般下载好的模型保存路径:==C:\user.cache\torch\hub\checkpoints
- 在已有的网络模型中新添自己需要的层
vgg16_True.classifier.add_module("7",nn.Linear(1000,10))
10 网络模型的保存与读取
方法一:直接把模型和参数保存下来
注意: 有 一个陷阱,自定义的模型在下载的时候运行会报错,得需要复制下载原模型。只能导入专门经典的模型
#保存
torch.save(vgg16_true,"vgg16_method1.pth")
#下载
model=torch.load("vgg16_method1.pth")
方法二:保存模型的参数,一般使用这个。内存比较小,节省空间;以字典的形式保存。
#保存
torch.save(vgg16_true.state_dict(),"vgg16_method1.pth")
#下载
vgg16_false=torchvision.models.vgg16(pretrained=False)
vgg16_false.load_state_dict(torch.long("wgg166_method2.pth"))