- GreatSQL社区原创内容未经授权不得随意使用,转载请联系小编并注明来源。
- GreatSQL是MySQL的国产分支版本,使用上与MySQL一致。
- 作者: 花家舍
- 文章来源:GreatSQL社区原创
前文回顾
- 实现一个简单的Database系列
译注:cstack在github维护了一个简单的、类似sqlite的数据库实现,通过这个简单的项目,可以很好的理解数据库是如何运行的。本文是第十篇,主要是实现B-tree中叶子节点分裂
Part 10 叶子节点分裂
我们 B-Tree 只有一个节点,这看起来不太像一棵标准的 tree。为了解决这个问题,需要一些代码来实现分裂叶子节点。在那之后,需要创建一个内部节点,使其成为两个新的叶子节点的父节点。
基本上,我们这个系列的文章的目标是从这里开始的:
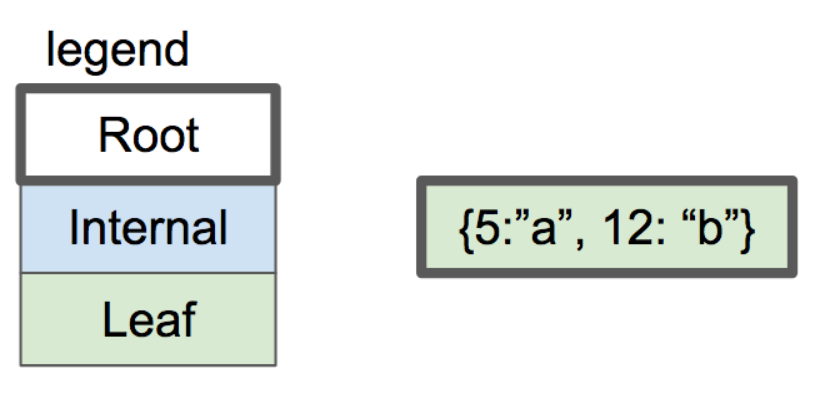
one-node btree
到这样:
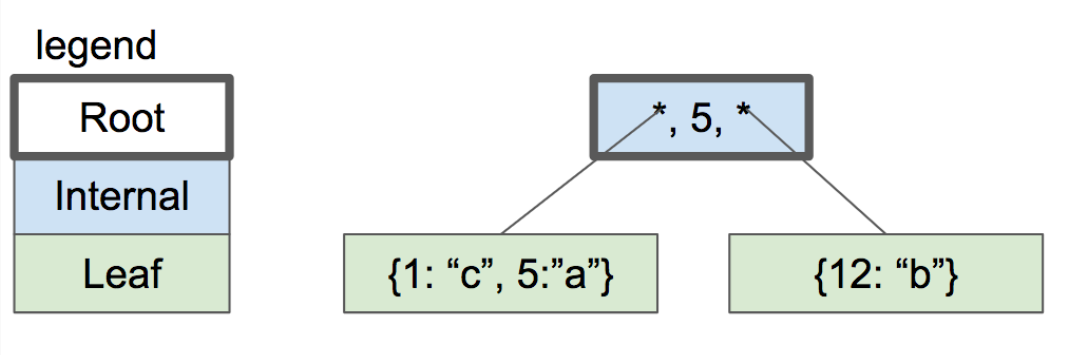
two-level btree
首先中的首先,先把处理节点写满错误移除掉:
void leaf_node_insert(Cursor* cursor, uint32_t key, Row* value) {
void* node = get_page(cursor->table->pager, cursor->page_num);
uint32_t num_cells = *leaf_node_num_cells(node);
if (num_cells >= LEAF_NODE_MAX_CELLS) {
// Node full
- printf("Need to implement splitting a leaf node.\n");
- exit(EXIT_FAILURE);
+ leaf_node_split_and_insert(cursor, key, value);
+ return;
}
ExecuteResult execute_insert(Statement* statement, Table* table) {
void* node = get_page(table->pager, table->root_page_num);
uint32_t num_cells = (*leaf_node_num_cells(node));
- if (num_cells >= LEAF_NODE_MAX_CELLS) {
- return EXECUTE_TABLE_FULL;
- }
Row* row_to_insert = &(statement->row_to_insert);
uint32_t key_to_insert = row_to_insert->id;分裂算法(Splitting Algorithm)
简单的部分结束了。以下是我们需要做的事情的描述(出自:SQLite Database System: Design and Implementation) 原文:If there is no space on the leaf node, we would split the existing entries residing there and the new one (being inserted) into two equal halves: lower and upper halves. (Keys on the upper half are strictly greater than those on the lower half.) We allocate a new leaf node, and move the upper half into the new node. 翻译:如果在叶子节点中已经没有空间,我们需要将驻留在节点中的现有条目和新条目(正在插入)分成相等的两半:低半部分和高半部分(在高半部分中的键要严格大于低半部分中的键)。我们分配一个新的节点,将高半部分的条目移到新的节点中。
现在来处理旧节点并创建一个新的节点:
+void leaf_node_split_and_insert(Cursor* cursor, uint32_t key, Row* value) {
+ /*
+ Create a new node and move half the cells over.
+ Insert the new value in one of the two nodes.
+ Update parent or create a new parent.
+ */
+
+ void* old_node = get_page(cursor->table->pager, cursor->page_num);
+ uint32_t new_page_num = get_unused_page_num(cursor->table->pager);
+ void* new_node = get_page(cursor->table->pager, new_page_num);
+ initialize_leaf_node(new_node);接下来,拷贝节点中每一个单元格到新的位置:
+ /*
+ All existing keys plus new key should be divided
+ evenly between old (left) and new (right) nodes.
+ Starting from the right, move each key to correct position.
+ */
+ for (int32_t i = LEAF_NODE_MAX_CELLS; i >= 0; i--) {
+ void* destination_node;
+ if (i >= LEAF_NODE_LEFT_SPLIT_COUNT) {
+ destination_node = new_node;
+ } else {
+ destination_node = old_node;
+ }
+ uint32_t index_within_node = i % LEAF_NODE_LEFT_SPLIT_COUNT;
+ void* destination = leaf_node_cell(destination_node, index_within_node);
+
+ if (i == cursor->cell_num) {
+ serialize_row(value, destination);
+ } else if (i > cursor->cell_num) {
+ memcpy(destination, leaf_node_cell(old_node, i - 1), LEAF_NODE_CELL_SIZE);
+ } else {
+ memcpy(destination, leaf_node_cell(old_node, i), LEAF_NODE_CELL_SIZE);
+ }
+ }更新节点中头部标记的单元格的数量(更新node’s header)
+ /* Update cell count on both leaf nodes */
+ *(leaf_node_num_cells(old_node)) = LEAF_NODE_LEFT_SPLIT_COUNT;
+ *(leaf_node_num_cells(new_node)) = LEAF_NODE_RIGHT_SPLIT_COUNT;然后我们需要更新节点的父节点。如果原始节点是一个根节点(root node),那么他就没有父节点。这种情况中,创建一个新的根节点来作为它的父节点。这里做另外一个存根(先不具体实现):
+ if (is_node_root(old_node)) {
+ return create_new_root(cursor->table, new_page_num);
+ } else {
+ printf("Need to implement updating parent after split\n");
+ exit(EXIT_FAILURE);
+ }
+}分配新的页面(Allocating New Pages)
让我们回过头来定义一些函数和常量。当我们创建一个新的叶子节点,我们把它放进一个由get_unused_page_num()函数决定(返回)的页中。
+/*
+Until we start recycling free pages, new pages will always
+go onto the end of the database file
+*/
+uint32_t get_unused_page_num(Pager* pager) { return pager->num_pages; }现在,我们假定在一个数据库中有N个数据页,页编码从 0 到 N-1 的页已经被分配。因此我们总是可以为一个新页分配页 N编码。在我们最终实现删除(数据)操作后,一些页可能会变成空页,并且他们的页编号可能没有被使用。为了更有效率,我们会回收这些空闲页。
叶子节点的大小(Leaf Node Sizes)
为了保持的树的平衡,我们在两个新的节点之间平等的分发单元格。如果一个叶子节点可以hold住 N 个单元格,那么在分裂期间我们需要分发 N + 1 个单元格在两个节点之间(N 个原有的单元格和一个新插入的单元格)。如果 N+1 是奇数,我比较随意地选择了左侧节点获取多的那个单元格。
+const uint32_t LEAF_NODE_RIGHT_SPLIT_COUNT = (LEAF_NODE_MAX_CELLS + 1) / 2;
+const uint32_t LEAF_NODE_LEFT_SPLIT_COUNT =
+ (LEAF_NODE_MAX_CELLS + 1) - LEAF_NODE_RIGHT_SPLIT_COUNT;创建新根节点(Creating a New Root)
这里是“SQLite Database System”描述的创建一个新根节点的过程: 原文:Let N be the root node. First allocate two nodes, say L and R. Move lower half of N into L and the upper half into R. Now N is empty. Add 〈L, K,R〉 in N, where K is the max key in L. Page N remains the root. Note that the depth of the tree has increased by one, but the new tree remains height balanced without violating any B+-tree property. 翻译:设 N 为根节点。先分配两个节点,比如 L 和 R。移动 N 中低半部分的条目到 L 中,移动高半部分条目到 R 中。现在 N 已经空了。增加 〈L, K,R〉到 N 中,这里 K 是 L 中最大 key 。页 N 仍然是根节点。注意这时树的深度已经增加了一层,但是在没有违反任何 B-Tree 属性的情况下,新的树仍然保持了高度上平衡。
此时,我们已经分配了右子节点并移动高半部分的条目到这个子节点。我们的函数把这个右子节点作为输入,并且分配一个新的页面来存放左子节点。
+void create_new_root(Table* table, uint32_t right_child_page_num) {
+ /*
+ Handle splitting the root.
+ Old root copied to new page, becomes left child.
+ Address of right child passed in.
+ Re-initialize root page to contain the new root node.
+ New root node points to two children.
+ */
+
+ void* root = get_page(table->pager, table->root_page_num);
+ void* right_child = get_page(table->pager, right_child_page_num);
+ uint32_t left_child_page_num = get_unused_page_num(table->pager);
+ void* left_child = get_page(table->pager, left_child_page_num);旧的根节点已经被拷贝到左子节点,所以我们可以重用根节点(无需重新分配):
+ /* Left child has data copied from old root */
+ memcpy(left_child, root, PAGE_SIZE);
+ set_node_root(left_child, false);最后我们初始化根节点作为一个新的、有两个子节点的内部节点。
+ /* Root node is a new internal node with one key and two children */
+ initialize_internal_node(root);
+ set_node_root(root, true);
+ *internal_node_num_keys(root) = 1;
+ *internal_node_child(root, 0) = left_child_page_num;
+ uint32_t left_child_max_key = get_node_max_key(left_child);
+ *internal_node_key(root, 0) = left_child_max_key;
+ *internal_node_right_child(root) = right_child_page_num;
+}内部节点格式(Internal Node Format)
现在我们终于创建了内部节点,我们就不得不定义它的布局了。它从通用 header 开始,然后是它包含的 key 的数量,接下来是它右边子节点的页号。内部节点的子节点指针始终比它的 key 的数量多一个。这个 子节点指针存储在 header 中。
+/*
+ * Internal Node Header Layout
+ */
+const uint32_t INTERNAL_NODE_NUM_KEYS_SIZE = sizeof(uint32_t);
+const uint32_t INTERNAL_NODE_NUM_KEYS_OFFSET = COMMON_NODE_HEADER_SIZE;
+const uint32_t INTERNAL_NODE_RIGHT_CHILD_SIZE = sizeof(uint32_t);
+const uint32_t INTERNAL_NODE_RIGHT_CHILD_OFFSET =
+ INTERNAL_NODE_NUM_KEYS_OFFSET + INTERNAL_NODE_NUM_KEYS_SIZE;
+const uint32_t INTERNAL_NODE_HEADER_SIZE = COMMON_NODE_HEADER_SIZE +
+ INTERNAL_NODE_NUM_KEYS_SIZE +
+ INTERNAL_NODE_RIGHT_CHILD_SIZE;内部节点的 body 是一个单元格的数组,每个单元格包含一个子指针和一个 key 。每个 key 都必须是它的左边子节点中包含的最大 key 。
+/*
+ * Internal Node Body Layout
+ */
+const uint32_t INTERNAL_NODE_KEY_SIZE = sizeof(uint32_t);
+const uint32_t INTERNAL_NODE_CHILD_SIZE = sizeof(uint32_t);
+const uint32_t INTERNAL_NODE_CELL_SIZE =
+ INTERNAL_NODE_CHILD_SIZE + INTERNAL_NODE_KEY_SIZE;基于这些常量,下边是内部节点布局看上去的样子:

Our internal node format
注意我们巨大的分支因子(也就是扇出)。因为每个子节点指针/键对儿(child pointer / key pair)太小了,我们可以在每个内部节点中容纳 510 个键和 511 个子指针(也就是每个内部节点可以有510个子节点)。这意味着我们从来不用在查找 key 时遍历树的很多层。
| # internal node layers | max # leaf nodes | Size of all leaf nodes |
|---|---|---|
| 0 | 511^0 = 1 | 4 KB |
| 1 | 511^1 = 512 | ~2 MB |
| 2 | 511^2 = 261,121 | ~1 GB |
| 3 | 511^3 = 133,432,831 | ~550 GB |
实际上,我们不能在每个叶子节点中存储满 4KB 的数据,这是因为存储 header 、 keys 的开销和空间的浪费。 但是我们可以通过从磁盘上加载 4 个 pages (树高四层,每层只需检索一页)来检索大约 500G 的数据。这就是为什么 B-Tree 对数据库来说是很有用的数据结构。
下边是读取和写入一个内部节点的方法:
+uint32_t* internal_node_num_keys(void* node) {
+ return node + INTERNAL_NODE_NUM_KEYS_OFFSET;
+}
+
+uint32_t* internal_node_right_child(void* node) {
+ return node + INTERNAL_NODE_RIGHT_CHILD_OFFSET;
+}
+
+uint32_t* internal_node_cell(void* node, uint32_t cell_num) {
+ return node + INTERNAL_NODE_HEADER_SIZE + cell_num * INTERNAL_NODE_CELL_SIZE;
+}
+
+uint32_t* internal_node_child(void* node, uint32_t child_num) {
+ uint32_t num_keys = *internal_node_num_keys(node);
+ if (child_num > num_keys) {
+ printf("Tried to access child_num %d > num_keys %d\n", child_num, num_keys);
+ exit(EXIT_FAILURE);
+ } else if (child_num == num_keys) {
+ return internal_node_right_child(node);
+ } else {
+ return internal_node_cell(node, child_num);
+ }
+}
+
+uint32_t* internal_node_key(void* node, uint32_t key_num) {
+ return internal_node_cell(node, key_num) + INTERNAL_NODE_CHILD_SIZE;
+}对于一个内部节点,最大 key 始终是其右键。对于一个叶子节点,最大 key 就是最大索引键。
+uint32_t get_node_max_key(void* node) {
+ switch (get_node_type(node)) {
+ case NODE_INTERNAL:
+ return *internal_node_key(node, *internal_node_num_keys(node) - 1);
+ case NODE_LEAF:
+ return *leaf_node_key(node, *leaf_node_num_cells(node) - 1);
+ }
+}追踪根节点(Keeping Track of the Root)
我们终于在通用的节点 header 中使用了 is_root 字段。回调它是我们用它来决定怎样来分裂一个叶子节点:
if (is_node_root(old_node)) {
return create_new_root(cursor->table, new_page_num);
} else {
printf("Need to implement updating parent after split\n");
exit(EXIT_FAILURE);
}
}下面是 getter & setter:
+bool is_node_root(void* node) {
+ uint8_t value = *((uint8_t*)(node + IS_ROOT_OFFSET));
+ return (bool)value;
+}
+
+void set_node_root(void* node, bool is_root) {
+ uint8_t value = is_root;
+ *((uint8_t*)(node + IS_ROOT_OFFSET)) = value;
+}初始化这两种类型的节点(内部节点&叶子节点)应默认设置 is_root 为 false。
void initialize_leaf_node(void* node) {
set_node_type(node, NODE_LEAF);
+ set_node_root(node, false);
*leaf_node_num_cells(node) = 0;
}
+void initialize_internal_node(void* node) {
+ set_node_type(node, NODE_INTERNAL);
+ set_node_root(node, false);
+ *internal_node_num_keys(node) = 0;
+}当创建表的第一个节点时我们需要设置 is_root 为 true 。
// New database file. Initialize page 0 as leaf node.
void* root_node = get_page(pager, 0);
initialize_leaf_node(root_node);
+ set_node_root(root_node, true);
}
return table;打印树(Printing the Tree)
为了帮助我们可视化数据库的状态,我们应该更新我们的 .btree 元命令以打印多级树。
我要替换当前的 print_leaf_node() 函数:
-void print_leaf_node(void* node) {
- uint32_t num_cells = *leaf_node_num_cells(node);
- printf("leaf (size %d)\n", num_cells);
- for (uint32_t i = 0; i < num_cells; i++) {
- uint32_t key = *leaf_node_key(node, i);
- printf(" - %d : %d\n", i, key);
- }
-}实现一个递归函数,可以接受任何节点,然后打印它和它的子节点。它接受一个缩进级别作为参数,缩进级别每次在每次递归时会递增。我还在缩进中添加了一个很小的辅助函数。
+void indent(uint32_t level) {
+ for (uint32_t i = 0; i < level; i++) {
+ printf(" ");
+ }
+}
+
+void print_tree(Pager* pager, uint32_t page_num, uint32_t indentation_level) {
+ void* node = get_page(pager, page_num);
+ uint32_t num_keys, child;
+
+ switch (get_node_type(node)) {
+ case (NODE_LEAF):
+ num_keys = *leaf_node_num_cells(node);
+ indent(indentation_level);
+ printf("- leaf (size %d)\n", num_keys);
+ for (uint32_t i = 0; i < num_keys; i++) {
+ indent(indentation_level + 1);
+ printf("- %d\n", *leaf_node_key(node, i));
+ }
+ break;
+ case (NODE_INTERNAL):
+ num_keys = *internal_node_num_keys(node);
+ indent(indentation_level);
+ printf("- internal (size %d)\n", num_keys);
+ for (uint32_t i = 0; i < num_keys; i++) {
+ child = *internal_node_child(node, i);
+ print_tree(pager, child, indentation_level + 1);
+
+ indent(indentation_level + 1);
+ printf("- key %d\n", *internal_node_key(node, i));
+ }
+ child = *internal_node_right_child(node);
+ print_tree(pager, child, indentation_level + 1);
+ break;
+ }
+}并更新对 print 函数的调用,传递缩进级别为零。
} else if (strcmp(input_buffer->buffer, ".btree") == 0) {
printf("Tree:\n");
- print_leaf_node(get_page(table->pager, 0));
+ print_tree(table->pager, 0, 0);
return META_COMMAND_SUCCESS;下面是一个对新的打印函数的测例
+ it 'allows printing out the structure of a 3-leaf-node btree' do
+ script = (1..14).map do |i|
+ "insert #{i} user#{i} person#{i}@example.com"
+ end
+ script << ".btree"
+ script << "insert 15 user15 person15@example.com"
+ script << ".exit"
+ result = run_script(script)
+
+ expect(result[14...(result.length)]).to match_array([
+ "db > Tree:",
+ "- internal (size 1)",
+ " - leaf (size 7)",
+ " - 1",
+ " - 2",
+ " - 3",
+ " - 4",
+ " - 5",
+ " - 6",
+ " - 7",
+ " - key 7",
+ " - leaf (size 7)",
+ " - 8",
+ " - 9",
+ " - 10",
+ " - 11",
+ " - 12",
+ " - 13",
+ " - 14",
+ "db > Need to implement searching an internal node",
+ ])
+ end新格式有点简化,所以我们需要更新现有的 .btree 测试:
"db > Executed.",
"db > Executed.",
"db > Tree:",
- "leaf (size 3)",
- " - 0 : 1",
- " - 1 : 2",
- " - 2 : 3",
+ "- leaf (size 3)",
+ " - 1",
+ " - 2",
+ " - 3",
"db > "
])
end这是新测试本身的 .btree 输出:
Tree:
- internal (size 1)
- leaf (size 7)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- key 7
- leaf (size 7)
- 8
- 9
- 10
- 11
- 12
- 13
- 14在缩进最小的级别,我们看到根节点(一个内部节点)。它输出的 size 为 1 因为它有一个 key 。缩进一个级别,我们看到叶子节点,一个 key ,和一个叶子节点。根节点中的 key (7)是第一个左子节点中最大的 key 。每个大于7的 key 存放在第二个子节点中。
一个主要问题(A Major Problem)
如果你一直密切关注,你可能会注意到我们错过了一些大事。看看如果我们尝试插入额外一行会发生什么:
db > insert 15 user15 person15@example.com
Need to implement searching an internal node哦吼!是谁写的TODO信息?(作者在故弄玄虚!明明是他自己在 table_find() 函数中把内部节点搜索的功能存根的!)
下次我们将通过在多级树上实现搜索来继续史诗般的 B 树传奇。
Enjoy GreatSQL :)
关于 GreatSQL
GreatSQL是由万里数据库维护的MySQL分支,专注于提升MGR可靠性及性能,支持InnoDB并行查询特性,是适用于金融级应用的MySQL分支版本。
相关链接: GreatSQL社区 Gitee GitHub Bilibili
GreatSQL社区:

社区有奖建议反馈: https://greatsql.cn/thread-54-1-1.html
社区博客有奖征稿详情: https://greatsql.cn/thread-100-1-1.html
社区2022年度勋章获奖名单: https://greatsql.cn/thread-184-1-1.html
(对文章有疑问或者有独到见解都可以去社区官网提出或分享哦~)
技术交流群:
微信&QQ群: QQ群:533341697 微信群:添加GreatSQL社区助手(微信号:wanlidbc )好友,待社区助手拉您进群。