目录
- 概述
- 细节
- 背景与整体流程
- 图像级别生成
- 特征级别生成
- 损失函数
- 学习深度感知的特征
概述
本文是基于单目图像的3D目标检测方法。
【2021】【MonoDLE】
研究的问题:
- 能否借助立体图像检测算法提高单目图像检测的效果
- 如何实现右侧图像的生成
解决的方法:
- 受启发于伪点云,提出了伪立体图像的概念,将图像转换成立体图像,然后应用立体图像的检测算法
- 提出两种右侧图像生成的方法,分别是图像级别生成和特征级别生成(基于视差的动态卷积方法)
- 提出一个观点:学习深度感知的特征有利于提高单目检测的性能,比如作者这边的深度估计以及深度损失。
细节
背景与整体流程
为什么要用Pseudo-Stereo?虽然Pseudo-LiDAR效果很好,但是相对于基于雷达的算法还有很大的差距,并且这个差距来源于图像到点云的转化。因为这个转化过程是跨模态的,误差巨大。而单目图像到立体图像的转换相对而言就简单一点,并且基于立体图像的检测算法也具有不错的效果
思想概述:核心就是转换成立体图像然后应用立体图像的检测算法
算法的关键问题:图像到点云转换过程带来的巨大误差也影响到了伪点云算法的性能,使得基于伪点云的算法与基于点云的算法具有较大的差距。因此,如何减小单目图像到立体图像转换过程中的误差是本文的关键,作者提出了两种方法,图像级生成和特征级生成(特征克隆是特征级生成的特殊情况)
注意:虽然是采用基于立体图像的检测算法,但是作者将基于立体图像的检测算法的特征提取模块换成了自己的,也就是算法的输入是左右图的特征或者说是成本容积
图像级别生成
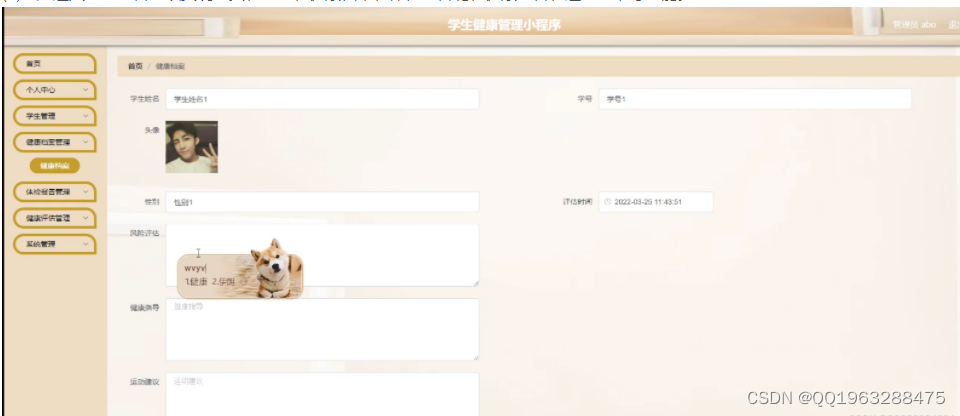
算法流程:基于左图得到深度图,然后将深度图转换成视差图,接着基于左图和视差图生成右图,然后使用共享参数的ResNet34进行左右图的特征提取,用共享参数的SPP模块分别获得左右图对应的全局特征,构造成本容积,然后送入立体图像检测器LIGA-Stereo中。

将深度图转换成视差图基于以下的方法:其中
d
d
d是对应的视差,
z
z
z是估计得到的深度值,
f
,
b
f,b
f,b分别是相机焦距和两台相机之间的基线距离

基于左图和视差图生成右图:主要是两个操作,一个是按照下面的公式扭曲左图得到右图,另一个是为了处理边缘模糊等问题对视差图进行了锐化

特征级别生成
背景:图像级别生成中,用左图+视差图扭曲得到右图非常耗时(相当于是手工做法),所以作者就提出了一种可微分(可学习)的特征变换方法,基于左图特征直接得到右图特征。
算法流程:基于左图得到深度图,然后将深度图转换成视差图,用不共享参数的ResNet34对左图和视差图进行特征提取,然后对左图特征和右图特征作基于视差的卷积(不是计算偏移量)得到右图特征,用共享参数的SPP模块分别获得左右图对应的全局特征,构造成本容积,然后送入立体图像检测器LIGA-Stereo中。

特殊情况:最简单的方式就是直接复制左图特征作为右图特征,这样不需要深度估计、视差图这些杂七杂八的,泛化性能好,但是检测性能嘛,肯定不行。

损失函数
损失函数与LIGA-Stereo相同
学习深度感知的特征
作者提到一个观点:学习深度感知的特征有利于提高单目检测的性能。本文的深度感知体现在两个方面,一个是深度估计,另一个是深度损失。两种方法对深度估计的应用差不多,但是深度损失的应用就有差别,前者生成右图是手工的做法,后者是学习的方法,深度损失能够指导右图的生成。