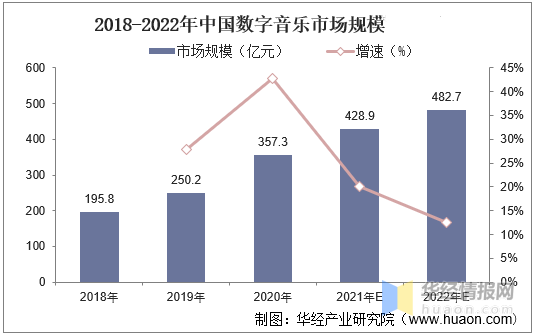
本内容来自公众号“布博士”------(擎创科技资深产品专家)
背景:
作为大型券商企业之一,某券商对深入数字化转型,以及对应用、网络、主机、操作系统、中间件、用户使用体验等的全面可观测性要求越来越强烈。由于可观测性需求的深入及实施,带来了大量的告警需要进行处理,原有的统一事件管理平台仅完成了对告警的收集、告警标准化、丰富和通知等能力。
当前该券商面临的最大问题是告警不能进一步收敛,缺乏运维专家的经验可以将同一问题引发的多个告警进行有效的关联,进而进一步降低告警的处理量。

针对这一问题,该券商AIOPS二期项目主要关注点聚焦在:挖掘告警中潜在的告警关联模式,即通过AI技术对历史告警的关联分析找到告警发生时,不同的告警对象指标之间的相互影响关系,并将有影响的告警关联到一起进行处理,以加速对告警分析、处置过程。
针对该券商的案例分享,我们要分享的内容主要包括
● 人工智能项目一般过程及方法论简介
● 告警关联分析模型建立过程介绍(业务理解、数据理解、数据准备)
● 下一步:产品化
受限于篇幅,本次分享内容将分为上下两篇跟大家见面~
一、AI人工智能项目一般过程及方法论

上图所示的为CRISP-DM方法论,即跨行业的数据挖掘标准流程,这个标准是由IBM SPSS、Daimler Chrysler等几家公司于1999年推出的事实上的标准,笔者从2010年来便开始接触数据挖掘类项目(当下流行叫机器学习、人工智能)至今看到的几乎所有的类似项目都沿用该标准。
按CRISP-DM方法论,该过程包括6大过程,分别为业务理解(Business Understanding)、数据理解(Data Understanding)、数据准备(DataPreparation)、模型搭建(Modeling)、模型评估(Evaluation)和模型发布(Deployment)。在后面的分享中,我们将以该流程为例,对告警关联分析模型建立过程进行详细的介绍。
上述6大过程的顺序也不是固定不变的,在不同的项目中,可有不同的流转过程,不论如何,业务理解这一点一定是项目最开始就要明确的。
另外,该过程是循环的,每次针对不同业务目标的深入理解会不断地进行优化和调整,后续的循环过程可以不断从上一次的6大过程中得到借鉴和启发。
本次项目取得的成果也是我们经过5轮算法优化过程,两轮用户参与评审过程,才不断优化而来的。
二、告警关联分析模型建立过程介绍
这里我们按照上述6大过程来执行并讲解。
1.业务理解(Business Understanding)
业务理解是第一个过程,也是这里面最核心的过程,该过程执行的好坏,直接决定了后续5大过程的准确与否。
在该过程中也包括几个重要环节(项目目标、成功条件、资源、计划、使用的工具等),在这里我们只介绍项目目标:必须要定义好本次AI项目的具体目标,不能有任何模糊,否则无法判断成功的标准、资源的投入、大致的项目计划。
本案例中我们的目标即是通过历史告警数据来挖掘出哪些告警是经常一起发生的,找到这些具有潜在内在关联的告警。
考虑到整个数据中心的数据量比较庞大,同时会产生大量的分析结果,后续审核阶段工作量比较大且数据分散,验证难度也比较大。因此,在本项目中我们选择了该券商最重要的核心业务系统。
2.数据理解(Data Understanding)
AI类的项目是从数据中找到我们认为有价值的知识,因此这种类型的项目都是以数据为核心来进行驱动的。
针对项目目标的理解,我们需要回答:
解决业务目标问题的数据在哪里?
数据长成什么样子?
我们对数据理解么?
数据有什么样的特征?
数据质量如何?有无缺失值

进行告警的关联分析,需要获取原始告警数据,这是我们通过告警辨析中心从不同的监控来源获取的原始告警信息,这些原始告警需要经过一定的标准化和丰富之后才能够给算法使用。
通过对告警数据的理解一定要能够回答如下三个问题:
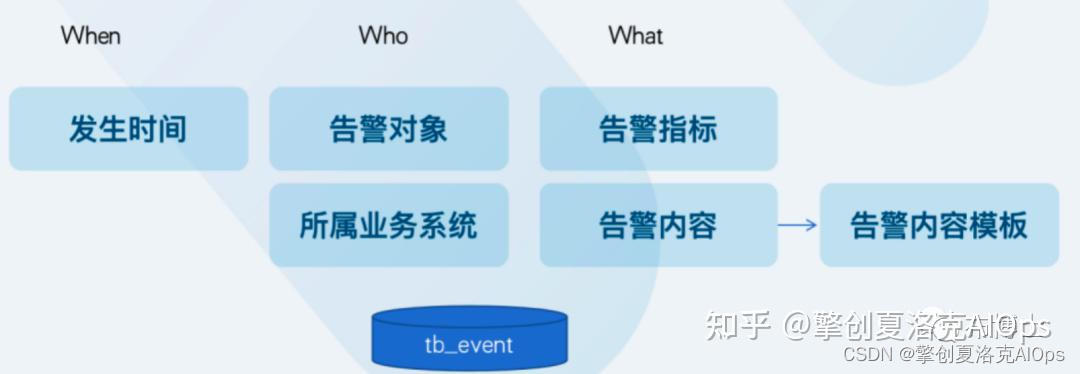
When:即在什么时间发生的告警,这是一个非常重要的时间,后续我们在算法中进行时间窗口切分时依赖该字段。
Who:代表告警的对象是谁,该告警对象所服务的业务系统是谁,也是非常重要的一个字段,我们在进行算法数据输入和处理时从整个数据中心中的告警中进行数据范围选择的依据,针对不同的告警对象类型(网络设备、应用系统、安全设备等)所选择的告警字段、数据筛选和过滤及加工的方式完全不同,而且会严重影响最终产生的效果。
What:代表发生了什么,不同的告警对象类型、告警对象的指标之间是相互影响的,我们主要分析的即为相互之间的影响产生之后,在某个时间段时因为影响而共同发生。
通过一些可视化的数据工具,我们可以详细了解数据的特征、有无缺失、数据质量等的情况,这样可以结合数据特征+业务理解,我们在该步骤确认需要用到什么样的算法来解决问题,针对不同的算法其对数据的输入要求也会有所不同,会直接影响数据准备过程。

如上图数据挖掘工具rapidminer所生生数据统计结果,我们可以看到:
告警指标metric_name存在大量数据丢失的情况,因此我们在后续的告警关联分析挖掘中采用template_id(告警内容模板ID),每一个告警内容对应一条内容模板,用于描述同一类告警问题,等同于告警指标字段字段。
event_time,代表原始告警的发生时间,不能为空。
object、business、content等内容都不为空,这些字段是在进行挖掘模式解读、评审时,都会用到的关键信息。
3.数据准备(Data Preparation)
一般在数据准备阶段需要进行数据的清洗、转换、新特征衍生成等步骤,并转换为算法模型可以接收的数据(这个过程在AI领域被称为特征工程),不同的算法模型对数据的要求不同,在这里我们进行告警关联分析用到的主要是fp-growth算法,这是一个非常经典且常用的关联分析挖掘算法,它的适用场景及原理,在这里我们不再详述,感兴趣的同学可以直接通过搜索引擎在网上搜索。
在之前发表的《利用人工智能算法实现告警的关联分析》一文中,楼主已经详细介绍了算法所需要的输入数据,如下图所示。
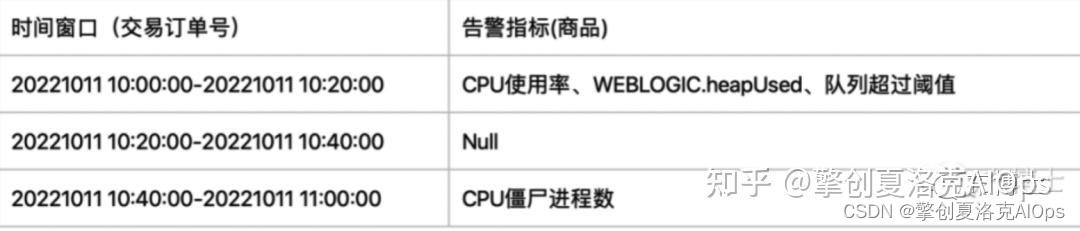
在数据理解阶段,我们发现该券商的告警数据中大部分的告警指标都为空值(在很多客户中都存在此种情况,只有告警的时间、告警ID、告警内容,但是没有告警指标),因此没有办法利用告警指标来做为告警关联的依据,最后采用针对告警内容的模板识别ID做为关联依据。
针对每套可观测性系统而言,每一个指标产生告警之后,其告警的描述性内容基本都是套用同一个格式的,如下图所示CPU使用率指标所产生的告警内容除了取值不同之外,其它内容都是一致的,因此我们在进行关联时采用擎创告警辨析中心产品独有的告警模板ID来代替指标,两者所产生的效果是一致的。

最终我们生成的要送入FP-GROWTH算法的输入数据如下图所示:
ID:即为切分的时间窗口
items:为在该时间窗口内,产生的告警模板ID有哪些

干货很干,今天的分享暂时就到这了,不知道大家看完有没有对“利用AI技术进行告警关联分析”有了一定的了解呢?欢迎评论区留言一起讨论~

擎创科技,Gartner连续推荐的AIOps领域标杆供应商。公司致力于协助企业客户提升对运维数据的洞见能力,优化运维效率,充分体现科技运维对业务运营的影响力。
行业龙头客户的共同选择

更多运维思路与案例持续更新中,敬请期待
随手点关注,更新不迷路