索引是一种数据结构,帮助我们在mysql表中更高效获取数据的数据结构
常用作为索引的数据结构:二叉树,红黑树,Hash表,B树,B+树
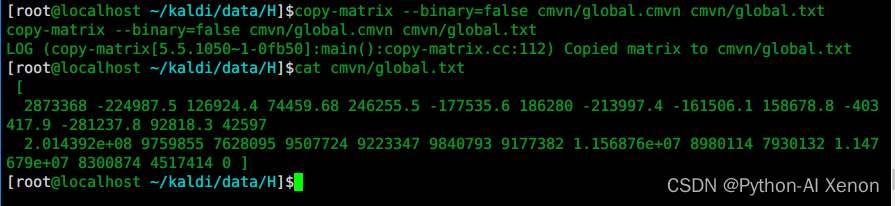
下面的数据表中有两个字段,第一个字段是col1,第二个字段是col2,前面0x07表示这行记录在磁盘里面的地址,现在执行下面的sql语句
select * from t where t.col2=89;
如果没有索引,需要跟磁盘做六次I/O交互,才能在第六行找到我们要的记录
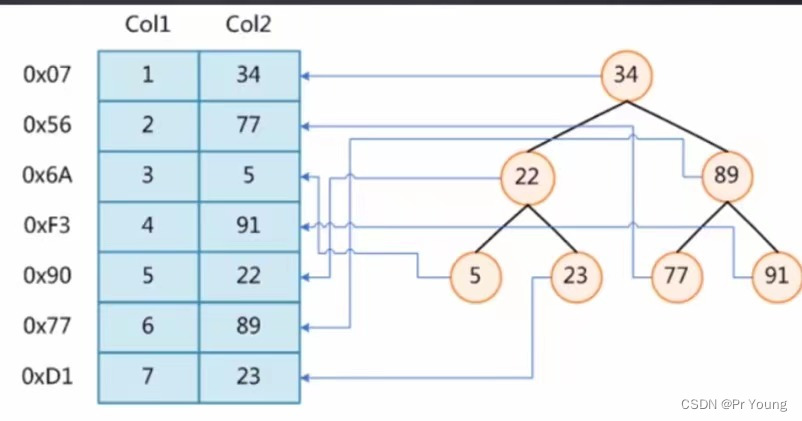
右边是一颗二叉树,二叉树的每一个结点存key-value,key是索引字段(这里我们以col2字段作为索引,所以结点里面存的key就是col字段的值),value是这行记录的磁盘文件地址(比如说0x07)
显然,有了索引之后,只需要和磁盘做两次I/O即可,就可以找到key=89的结点,然后把这个结点的value值(磁盘中的文件地址)拿出来,去磁盘中的这个地址取出这行记录
用二叉树作为索引的问题是:假如用col1字段作为索引,那么二叉树就会退化成链表
比如执行下面的sql查询语句:select * from t where t.col1=6;
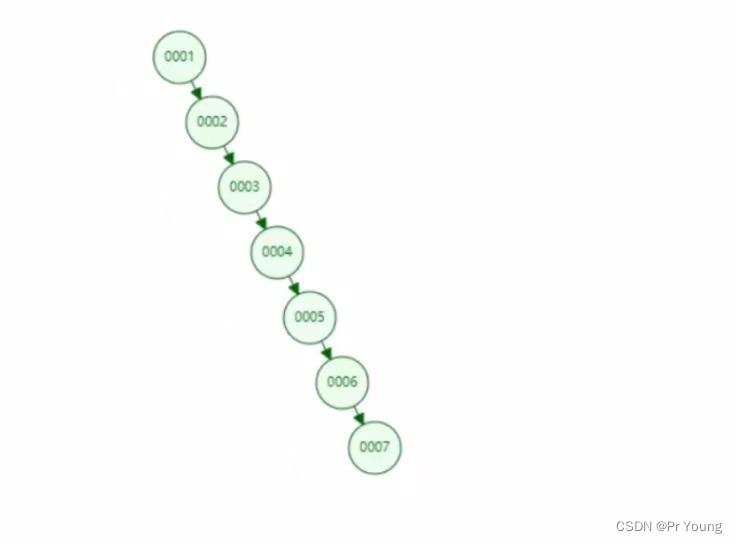
也就是说用递增列字段作为索引,用二叉树作为索引,意义不大
col1作为索引,如果用红黑树来存储
红黑树在插入新元素过程中,会自我平衡,所以select * from t where t.col1=6;只需要3次I/O即可
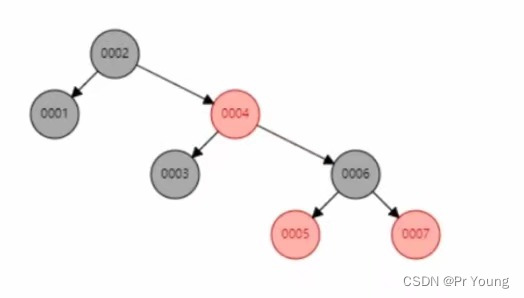
红黑树的树高还是太高了,比如当表里面有500w条记录 (也就是500w个索引),全部放到红黑树里面,树的高度会非常高,可能放完500w个索引,树的高度会达到20,所以可能要进行20次I/O操作,我们希望能够降低树的高度
给红黑树每一个结点分配的空间比较小,可能就只能放一个索引字段
现在将结点的空间变得更大一些,可以放几十几百个索引,这就是多路树(不是二叉树)
现在介绍B树
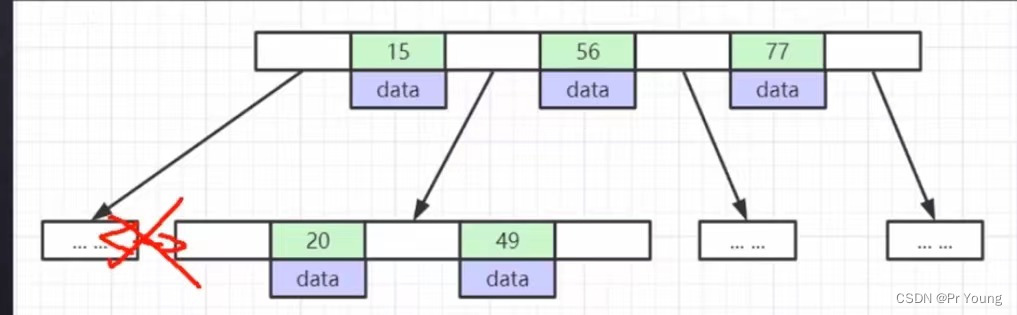
结点中的索引不重复(没有冗余的索引)
相邻叶子节点之间没有指针进行连接,即不存储相邻结点在磁盘中的文件位置
B+树
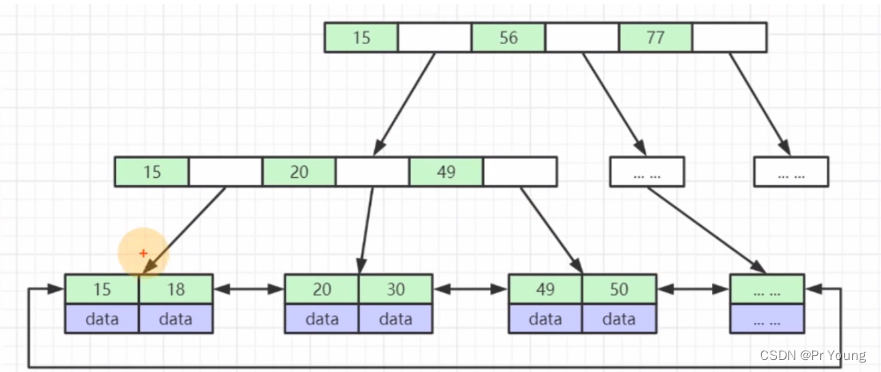
非叶子结点只存储索引,叶子结点存储索引+data
索引冗余:比如下面的B+树第一层存储了15这个索引字段,第二层又存储了15这个索引字段,第三层还存储了15这个索引字段
最后一层存储了所有的索引
叶子结点之间用指针相连,(存相邻叶子结点的磁盘文件地址)提高区间访问性能
将结点中的数据加载到内存里面,进行二分查找,这个时间和一次I/O的时间相比,可以忽略不计
另外:不使用哈希表作为索引,是因为哈希表不支持范围查找
select * from table where id>=10&&id<=20
B+树与红黑树作比较:
红黑树一个结点空间比较小,只存储一个索引,所以导致数据量太大的时候,树高就会很高,树高的话I/O次数就会更多
但是B+树每个结点空间更大,可以存储很多个索引,树高会更低,所以I/O次数会更少
B+树和B树作比较:
(1)b树非叶子节点,叶子结点都存数据,b+树非叶子结点不存数据,只有叶子节点才存数据
所以这也导致b树进行检索时,可能不用查到叶子结点,数据就已经被查到了
而b+树必须从根节点一路检索到叶子节点,数据才能被检索到
(2)b树叶子节点之间没有任何关系,是独立的,相邻叶子节点之间没有指针进行连接,即不存储相邻结点在磁盘中的文件位置,b+树的叶子节点有指针指向与它相邻的叶子节点
(3)B树没有冗余的重复的索引,B+树的非叶子节点和叶子节点有冗余的,重复的索引