5.1NN和2NN工作机制
5.1.1思考:NameNode中的元数据是存储在哪里的?
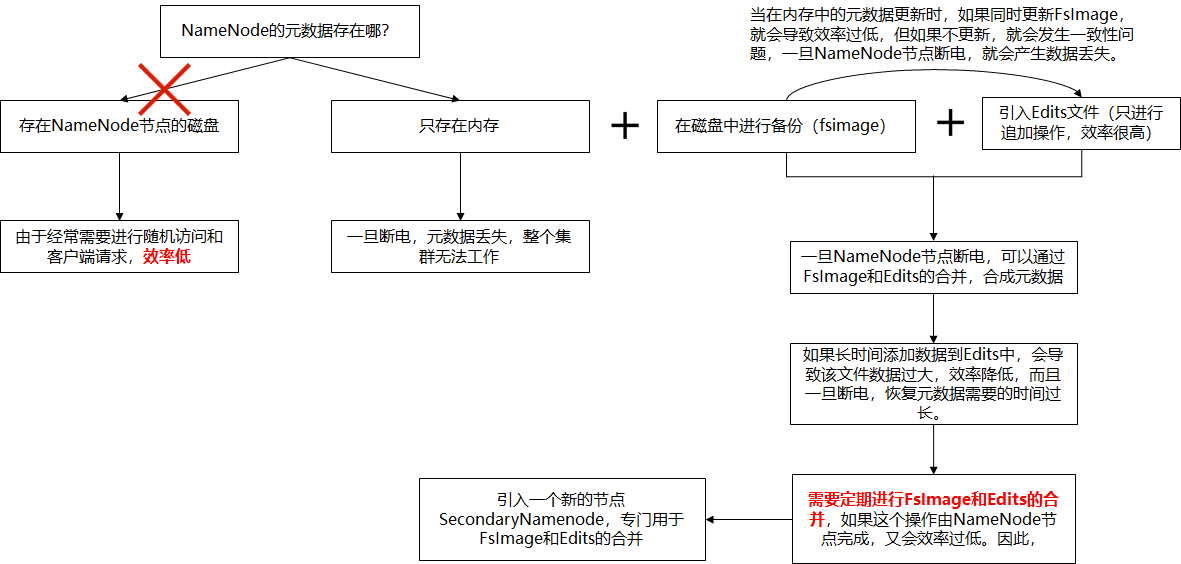
首先,我们做个假设,如果存储在NameNode节点的磁盘中,因为经常需要进行随机访问,还有响应客户请求,必然是效率过低。因此,元数据需要存放在内存中。但如果只存在内存中,一旦断电,元数据丢失,整个集群就无法工作了。因此产生在磁盘中备份元数据的FsImage。
这样又会带来新的问题,当在内存中的元数据更新时,如果同时更新FsImage,就会导致效率过低,但如果不更新,就会发生一致性问题,一旦NameNode节点断电,就会产生数据丢失。因此,引入Edits文件(只进行追加操作,效率很高)。每当元数据有更新或者添加元数据时,修改内存中的元数据并追加到Edits中。这样,一旦NameNode节点断电,可以通过FsImage和Edits的合并,合成元数据。
但是,如果长时间添加数据到Edits中,会导致该文件数据过大,效率降低,而且一旦断电,恢复元数据需要的时间过长。因此,需要定期进行FsImage和Edits的合并,如果这个操作由NameNode节点完成,又会效率过低。因此,引入一个新的节点SecondaryNamenode,专门用于FsImage和Edits的合并。
5.1.2NameNode工作机制
NN和2NN工作机制,如下图所示。

- 第一阶段:NameNode启动
(1)第一次启动NameNode格式化后,创建Fsimage和Edits文件。如果不是第一次启动,直接加载编辑日志和镜像文件到内存。
(2)客户端对元数据进行增删改的请求。
(3)NameNode记录操作日志,更新滚动日志。
(4)NameNode在内存中对数据进行增删改。
- 第二阶段:Secondary NameNode工作
(1)Secondary NameNode询问NameNode是否需要CheckPoint。直接带回NameNode是否检查结果。
(2)Secondary NameNode请求执行CheckPoint。
(3)NameNode滚动正在写的Edits日志。
(4)将滚动前的编辑日志和镜像文件拷贝到Secondary NameNode。
(5)Secondary NameNode加载编辑日志和镜像文件到内存,并合并。
(6)生成新的镜像文件fsimage.chkpoint。
(7)拷贝fsimage.chkpoint到NameNode。
(8)NameNode将fsimage.chkpoint重新命名成fsimage。
5.1.3NN和2NN工作机制详解
Fsimage:NameNode内存中元数据序列化后形成的文件。
Edits:记录客户端更新元数据信息的每一步操作(可通过Edits运算出元数据)。
NameNode启动时,先滚动Edits并生成一个空的edits.inprogress,然后加载Edits和Fsimage到内存中,此时NameNode内存就持有最新的元数据信息。Client开始对NameNode发送元数据的增删改的请求,这些请求的操作首先会被记录到edits.inprogress中(查询元数据的操作不会被记录在Edits中,因为查询操作不会更改元数据信息),如果此时NameNode挂掉,重启后会从Edits中读取元数据的信息。然后,NameNode会在内存中执行元数据的增删改的操作。
由于Edits中记录的操作会越来越多,Edits文件会越来越大,导致NameNode在启动加载Edits时会很慢,所以需要对Edits和Fsimage进行合并(所谓合并,就是将Edits和Fsimage加载到内存中,照着Edits中的操作一步步执行,最终形成新的Fsimage)。SecondaryNameNode的作用就是帮助NameNode进行Edits和Fsimage的合并工作。
SecondaryNameNode首先会询问NameNode是否需要CheckPoint(触发CheckPoint需要满足两个条件中的任意一个,定时时间到和Edits中数据写满了)。直接带回NameNode是否检查结果。SecondaryNameNode执行CheckPoint操作,首先会让NameNode滚动Edits并生成一个空的edits.inprogress,滚动Edits的目的是给Edits打个标记,以后所有新的操作都写入edits.inprogress,其他未合并的Edits和Fsimage会拷贝到SecondaryNameNode的本地,然后将拷贝的Edits和Fsimage加载到内存中进行合并,生成fsimage.chkpoint,然后将fsimage.chkpoint拷贝给NameNode,重命名为Fsimage后替换掉原来的Fsimage。NameNode在启动时就只需要加载之前未合并的Edits和Fsimage即可,因为合并过的Edits中的元数据信息已经被记录在Fsimage中。
5.2 Fsimage和Edits解析
- 概念
NameNode被格式化之后,将在/opt/modult/hadoop-2.7.7/data/tmp/dfs/name/current目录中产生如下文件
edits_inprogress_0000000000000004969
fsimage_0000000000000004966
seen_txid
VERSION
(1)fsimage文件:HDFS文件系统元数据的一个永久性检查点,其中包含HDFS文件系统的所有目录和文件inode的序列化信息。
(2)edits文件:存放HDFS文件系统的所有更新操作的路径,文件系统客户端执行的所有写操作首先会被记录到edits文件中。
(3)seen_txid文件:存放最后一个edits的数字。
(4)每次NameNode启动的时候都会将fsimage文件读入内存,加载edits里面的更新操作,保证内存中的元数据信息是最新的、同步的,可以看成NameNode启动的时候就将fsimage文件进行了合并。
- oiv查看Fsimage文件
(1)查看oiv和oev命令
[root@hdp101 current]# hdfs
oiv apply the offline fsimage viewer to an fsimage
oev apply the offline edits viewer to an edits file
(2)基本语法
hdfs oiv -p 文件类型 -i镜像文件 -o 转换后文件输出路径
(3)案例实操
[root@hdp101 current]# pwd
/opt/module/hadoop-2.7.7/data/tmp/dfs/name/current
[root@hdp101 current]# hdfs oiv -p XML -i fsimage_0000000000000000025 -o /opt/module/hadoop-2.7.7/fsimage.xml
[root@hdp101 current]# cat /opt/module/hadoop-2.7.7/fsimage.xml
将显示的xml文件内容拷贝到Eclipse中创建的xml文件中,并格式化。
思考:可以看出,Fsimage中没有记录块所对应DataNode,为什么?
在集群启动后,要求DataNode上报数据块信息,并间隔一段时间后再次上报。
- oev查看Edits文件
(1)基本语法
hdfs oev -p 文件类型 -i编辑日志 -o 转换后文件输出路径
(2)案例实操
[root@hdp101 current]# hdfs oev -p XML -i edits_0000000000000000012-0000000000000000013 -o /opt/module/hadoop-2.7.7/edits.xml
[root@hdp101 current]# cat /opt/module/hadoop-2.7.7/edits.xml
将显示的xml文件内容拷贝到Eclipse中创建的xml文件中,并格式化。
5.3CheckPoint时间设置
(1)通常情况下,SecondaryNameNode每隔一小时执行一次。
[hdfs-default.xml]
<property>
<name>dfs.namenode.checkpoint.period</name>
<value>3600</value>
</property>
(2)一分钟检查一次操作次数,当操作次数达到1百万时,SecondaryNameNode执行一次。
<property>
<name>dfs.namenode.checkpoint.txns</name>
<value>1000000</value>
<description>操作动作次数</description>
</property>
<property>
<name>dfs.namenode.checkpoint.check.period</name>
<value>60</value>
<description> 1分钟检查一次操作次数</description>
</property >
5.4NameNode故障处理
NameNode故障后,可以采用如下两种方法恢复数据。
方法一:将SecondaryNameNode中数据拷贝到NameNode存储数据的目录;
- kill -9 NameNode进程
- 删除NameNode存储的数据(/opt/module/hadoop-2.7.7/data/tmp/dfs/name)
[root@hdp101 hadoop-2.7.7]# rm -rf /opt/module/hadoop-2.7.7/data/tmp/dfs/name/*
- 拷贝SecondaryNameNode中数据到原NameNode存储数据目录
[root@hdp101 dfs]# scp -r root@hdp103:/opt/module/hadoop-2.7.7/data/tmp/dfs/namesecondary/* ./name/
- 重新启动NameNode
[root@hdp101 hadoop-2.7.7]# sbin/hadoop-daemon.sh start namenode
方法二:使用-importCheckpoint选项启动NameNode守护进程,从而将SecondaryNameNode中数据拷贝到NameNode目录中。
- 修改hdfs-site.xml中的
<property>
<name>dfs.namenode.checkpoint.period</name>
<value>120</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/opt/module/hadoop-2.7.7/data/tmp/dfs/name</value>
</property>
-
kill -9 NameNode进程
-
删除NameNode存储的数据(/opt/module/hadoop-2.7.7/data/tmp/dfs/name)
[root@hdp101 hadoop-2.7.7]# rm -rf /opt/module/hadoop-2.7.7/data/tmp/dfs/name/*
- 如果SecondaryNameNode不和NameNode在一个主机节点上,需要将SecondaryNameNode存储数据的目录拷贝到NameNode存储数据的平级目录,并删除in_use.lock文件
[root@hdp101 dfs]# scp -r root@hdp103:/opt/module/hadoop-2.7.7/data/tmp/dfs/namesecondary ./
[root@hdp101 namesecondary]# rm -rf in_use.lock
[root@hdp101 dfs]# pwd
/opt/module/hadoop-2.7.7/data/tmp/dfs
[root@hdp101 dfs]# ls
data name namesecondary
- 导入检查点数据(等待一会ctrl+c结束掉)
[root@hdp101 hadoop-2.7.7]# bin/hdfs namenode -importCheckpoint
- 启动NameNode
[root@hdp101 hadoop-2.7.7]# sbin/hadoop-daemon.sh start namenode
5.5 集群安全模式
5.5.1概述
1、NameNode启动
NameNode启动时,首先将镜像文件(Fsimage)载入内存,并执行编辑日志(Edits)中的各项操作。一旦在内存中成功建立文件系统元数据的映像,则闯将一个新的Fsimage文件和一个空的编辑日志。此时,NameNode开始监听DataNode的请求。这个过程期间,NameNode一直运行在安全模式,即NameNode的文件系统对于客户端来说是只读的。
2、DataNode启动
系统中的数据块的位置并不是由NameNode维护的,而是以块列表的形式存储在DataNode中。在系统正常操作期间,NameNode会在内存中保留所有块位置的映射信息。在安全模式下,各个DataNode会向NameNode发送最新的块列表信息,NameNode了解到足够多的块信息之后,即可高效运行文件系统。
3、安全模式退出判断
如果满足“最小副本条件”,NameNode会在30s之后就退出安全模式。所谓的最小副本条件指的是在整个文件系统中99.99%的块满足最小副本级别(默认值:dfs.replication.min=1)。在启动一个刚刚格式化的HDFS集群时,因为系统中还没有任何块,所以NameNode不会进入安全模式。
5.5.2基本语法
集群处于安全模式,不能执行重要操作(写操作)。集群启动完成后,自动退出安全模式。
(1)bin/hdfs dfsadmin -safemode get (功能描述:查看安全模式状态)
(2)bin/hdfs dfsadmin -safemode enter (功能描述:进入安全模式状态)
(3)bin/hdfs dfsadmin -safemode leave (功能描述:离开安全模式状态)
(4)bin/hdfs dfsadmin -safemode wait (功能描述:等待安全模式状态)
5.5.3案例
模拟等待安全模式
(1)查看当前模式
[root@hdp101 hadoop-2.7.7]# hdfs dfsadmin -safemode get
Safe mode is OFF
(2)先进入安全模式
[root@hdp101 hadoop-2.7.7]# bin/hdfs dfsadmin -safemode enter
(3)创建并执行下面的脚本
在/opt/module/hadoop-2.7.7路径上,编辑一个脚本safemode.sh
[root@hdp101 hadoop-2.7.7]# touch safemode.sh
[root@hdp101 hadoop-2.7.7]# vim safemode.sh
#!/bin/bash
hdfs dfsadmin -safemode wait
hdfs dfs -put /opt/module/hadoop-2.7.7/README.txt /
[root@hdp101 hadoop-2.7.7]# chmod 777 safemode.sh
[root@hdp101 hadoop-2.7.7]# ./safemode.sh
(4)再打开一个窗口,执行
[root@hdp101 hadoop-2.7.7]# bin/hdfs dfsadmin -safemode leave
(5)观察
(a)再观察上一个窗口
Safe mode is OFF
(b)HDFS集群上已经有上传的数据了。
5.6 NameNode多目录配置
- NameNode的本地目录可以配置成多个,且每个目录存放内容相同,增加了可靠性
- 具体配置如下
(1)在hdfs-site.xml文件中增加如下内容
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///${hadoop.tmp.dir}/dfs/name1,file:///${hadoop.tmp.dir}/dfs/name2</value>
</property>
(2)停止集群,集群中删除data和logs中所有数据。
[root@hdp101 hadoop-2.7.7]$ rm -rf data/ logs/
[root@hadoop103 hadoop-2.7.7]$ rm -rf data/ logs/
[root@hadoop104 hadoop-2.7.7]$ rm -rf data/ logs/
(3)格式化集群并启动。
[root@hdp101 hadoop-2.7.7]$ bin/hdfs namenode –format
[root@hdp101 hadoop-2.7.7]$ sbin/start-dfs.sh
(4)查看结果
[root@hdp101 dfs]$ ll
总用量 12
drwx------. 3 root root 4096 12月 11 08:03 data
drwxrwxr-x. 3 root root 4096 12月 11 08:03 name1
drwxrwxr-x. 3 root root 4096 12月 11 08:03 name2