论文:Real-Time Sign Language Detection using Human Pose Estimation
Github:https://github.com/google-research/google-research/tree/master/sign_language_detection
SLRTP 2020
手语识别任务包括手语检测(Sign language detection),手语识别(sign language recognition)2个部分。本文主要研究手语检测,目的就是判断当前视频的某一帧是否有做手语操作。文章首先使用openpose进行人体的关键点检测,然后基于前后帧的关键点归一化位移基于lstm进行2分类判断,即输出当前视频帧是否有做手语操作。最终文章在DGS Corpus(German Sign Language)数据集上达到了91%的准确性。
论文首先考虑使用光流方法区别每一帧图片的动作区别,但是这样会将背景等信息的变化也引入,这是不想看到的。所以决定使用关键点的归一化位移作为特征。

关键点的检测使用openpose实现,
Pose-all:全部的关键点,包括脸部,身体,手部
Pose-body:身体的关键点
Pose-hand:手部关键点
BBOX:身体框,脸部框,手部框
最终实验效果Pose-all的效果是最佳的,因此论文也采用Pose-all。
通过将每个身体部位的位移特征向量可视化,更可以直接看出不同身体部位的影响程度。

蓝色的线条代表不同身体部位的位移特征,主要的特征集中在手部,最下面的黄色线表示是否进行手语的ground_truth。
具体的身体不同部位的特征向量的计算方式如下,
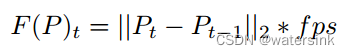
其中fps表示视频的帧率,P表示关键点坐标,t表示t时刻,t-1表示t-1时刻,然后将t时刻的关键点坐标和t-1时刻的关键点坐标计算L2距离,然后再乘以fps,得到归一化的关键点位移特征,保证了该特征不会随着视频帧率不同而有差异。

得到相邻帧的关键点位移特征向量后,在该向量的基础上做一个包含64个隐藏层的一层单向lstm。然后再做一个卷积操作,将特征维度变化为2维,然后直接基于这2维特征进行是否有打手语的2分类就可以。
总结:
使用openpose进行关键点检测,然后基于关键点位移特征向量进行2分类操作。