文章目录
- BeautifulSoup库的基本介绍
- HTML标签的获取和相关属性
- HTML文档的遍历
- prettify()方法
- 使用BeautifulSoup库对HTML文件进行内容查找
- 信息的标记的相关概念(非重点)
- find_all()方法(重点)
- 综合实例:爬取软科2022中国大学排名
承接上文:Python网络爬虫 学习笔记(1)requests库爬虫
BeautifulSoup库的使用背景:即使我们可以通过requests库获得网页的text信息,但是这个text信息只是网页的源代码,我们需要从这个源代码中寻找我们需要的信息,这时候就可以使用BeautifulSoup库来帮助我们实现目的。
BeautifulSoup库的基本介绍
HTML标签的获取和相关属性
Beautifulsoup库概述:
- 一个能够解析HTML和XML文件的功能库。
- 由于一个HTML文档或XML文档对应一个标签树,因此也可以说,该库是解析、遍历、维护标签树的功能库。
- 该库可以将任意一个标签树转换为一个BeautifulSoup类的对象。
- HTML/XML文档、标签树和BeautifulSoup对象之间是一一对应的关系。
最常用的库导入方式:from bs4 import BeautifulSoup。
BeautifulSoup类对象创建:
变量名=BeautifulSoup(HTML文件名/XML文件名,解析器)
- HTML文件名/XML文件名:通过request库的get函数获取的Response对象,其text域即为一个HTML或XML文件,因此可以用来作为参数。
- 解析器:当创建BeautifulSoup对象时需要指定解析器,用于表示文档的类型。自带的对HTML文档的解析器是"
html.parser",一般情况下使用这个解析器即可。
BeautifulSoup类的基本元素:
标签:
- 介绍:最基本的信息组织单元,分别用<>和</>标明开头和结尾。
- 使用方式:
BeautifulSoup变量名.标签名。
备注:如果存在多个名字相同的标签,则只会返回第一个标签对应的内容。
标签名:
- 介绍:< p >…< /p >的标签名为p。
- 使用方式:
BeautifulSoup变量名.标签名.name。
标签的属性:
- 介绍:以字典的形式进行组织。
- 使用方式:
BeautifulSoup变量名.标签名.attrs。 - 返回内容:一个字典,包括标签的各个属性的信息。
标签内非属性字符串:
- 介绍:即一对标签之间的内容,以字符串进行表示。
- 使用方式:
BeautifulSoup变量名.标签名.string。
内容注释:
- 介绍:标签内字符串的注释部分。
- 使用方式:和获取标签内字符串相同,需要通过返回值类型进行区分。
实战案例(BeautifulSoup对象的创建和标签的使用):
# 首先需要导入requests库和BeautifulSoup类
import requests
from bs4 import BeautifulSoup
# 使用get方法爬取测试网站的内容
r=requests.get("https://www.baidu.com/")
# 对可能抛出异常的部分放入try块中
try:
# 检测Response对象的状态码,判断是否抛出异常
r.raise_for_status()
# 如果header中不存在charset字段,则encoding采用默认编码方式,很可能解析错误
if r.encoding=="ISO-8859-1":
# 将网页内容编码方式修改成从内容分析出的编码方式
r.encoding=r.apparent_encoding
# 获取网页的HTML源代码
demo=r.text
###### 新学习的内容 ######
# 使用HTML解析器对源代码进行解析
soup=BeautifulSoup(demo,"html.parser")
# 显示网页的title标签内容
print(soup.title)
##########################
# 检测到异常后执行的语句
except:
print("网页访问失败!")
HTML文档的遍历
HTML文档对应一棵唯一的标签树,因此对HTML文档的遍历也就是对标签树的遍历。共有下行遍历、上行遍历和平行遍历三种方法。
下行遍历:从根节点向叶子节点遍历。
- contents:获取一个标签的子标签的列表。
- children:获取一个标签的子标签,是contents的迭代烈性,用于for…in结构循环遍历子标签。
- descendants:子孙标签的迭代类型,包含所有的子孙标签,用于for…in方式循环遍历。
备注:标签包括标签名和一对标签名中间的内容,而非只是标签名。
上行遍历:从叶子节点向根节点遍历。
- parent:获取当前标签的父标签。
- parents:获取当前标签的所有先辈标签,属于迭代类型,用于for…in结构的循环遍历。
平行遍历:同一层次节点间的遍历。
- next_sibling:按照HTML文本顺序的下一个平行标签。
- previous_sibling:按照HTML文本顺序的上一个平行标签。
- next_siblings:迭代类型,用于for…in结构按照HTML文本顺序遍历后续所有平行标签。
- previous_siblings:迭代类型,用于for…in结构按照HTML文本顺序遍历之前所有平行标签。
备注:只有父标签相同的标签才能进行平行遍历。
prettify()方法
方法概述:在HTML文件中合适的位置插入换行符,使得在展示HTML文件内容时更加方便阅读和程序处理。
备注:prettify方法也可以用于处理单个标签。
测试用例:
# 首先需要导入requests库和BeautifulSoup类
import requests
from bs4 import BeautifulSoup
# 使用get方法爬取测试网站的内容
r=requests.get("https://www.baidu.com/")
# 对可能抛出异常的部分放入try块中
try:
# 检测Response对象的状态码,判断是否抛出异常
r.raise_for_status()
# 如果header中不存在charset字段,则encoding采用默认编码方式,很可能解析错误
if r.encoding=="ISO-8859-1":
# 将网页内容编码方式修改成从内容分析出的编码方式
r.encoding=r.apparent_encoding
# 获取网页的HTML源代码
demo=r.text
###### 新学习的内容 ######
# 使用HTML解析器对源代码进行解析
soup=BeautifulSoup(demo,"html.parser")
# 直接显示HTML源代码
print(soup)
# 对HTML源代码使用prettify方法处理并输出处理完的效果
print(soup.prettify())
##########################
# 检测到异常后执行的语句
except:
print("网页访问失败!")
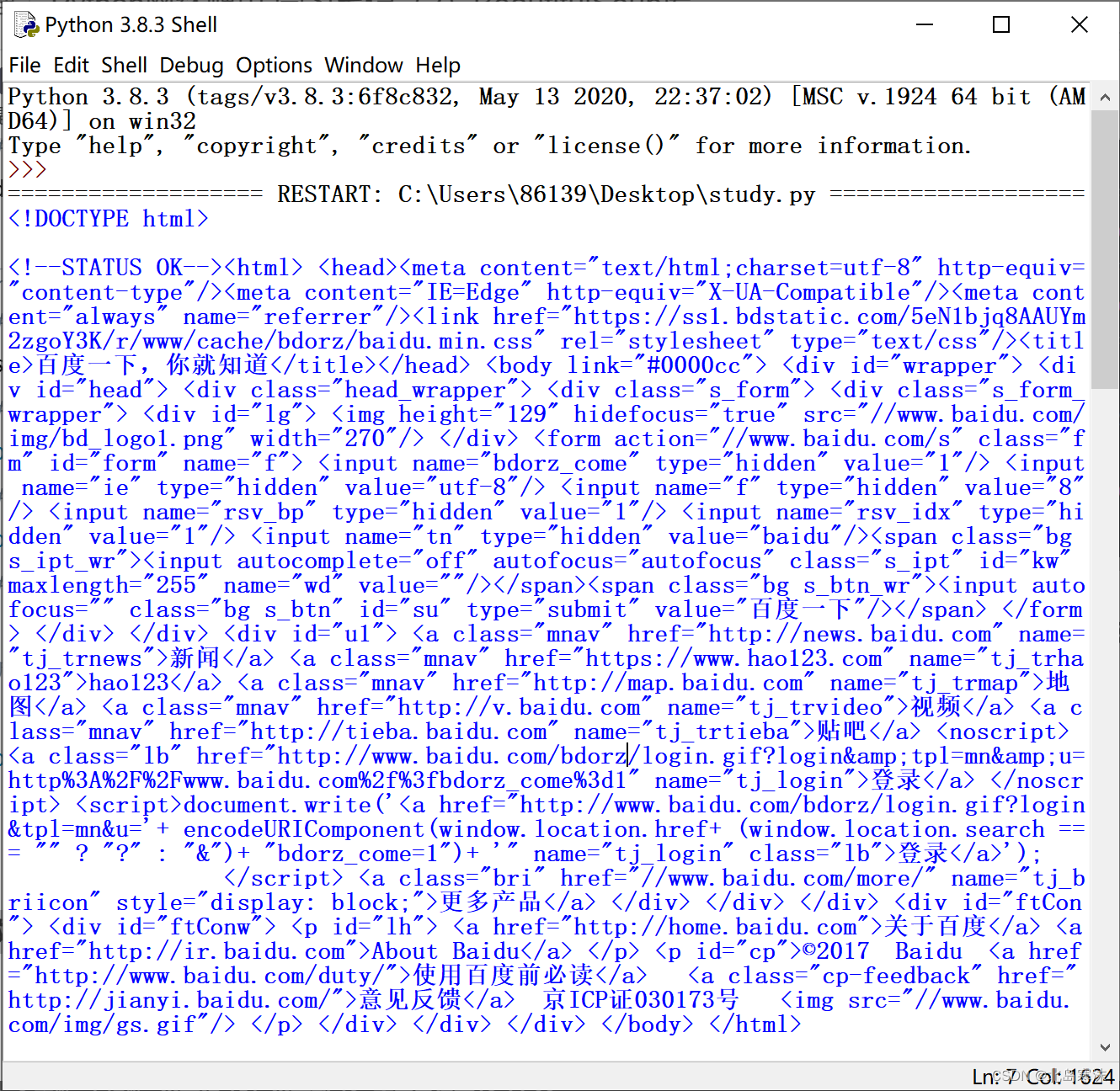
处理前后效果对比:
- 处理前:
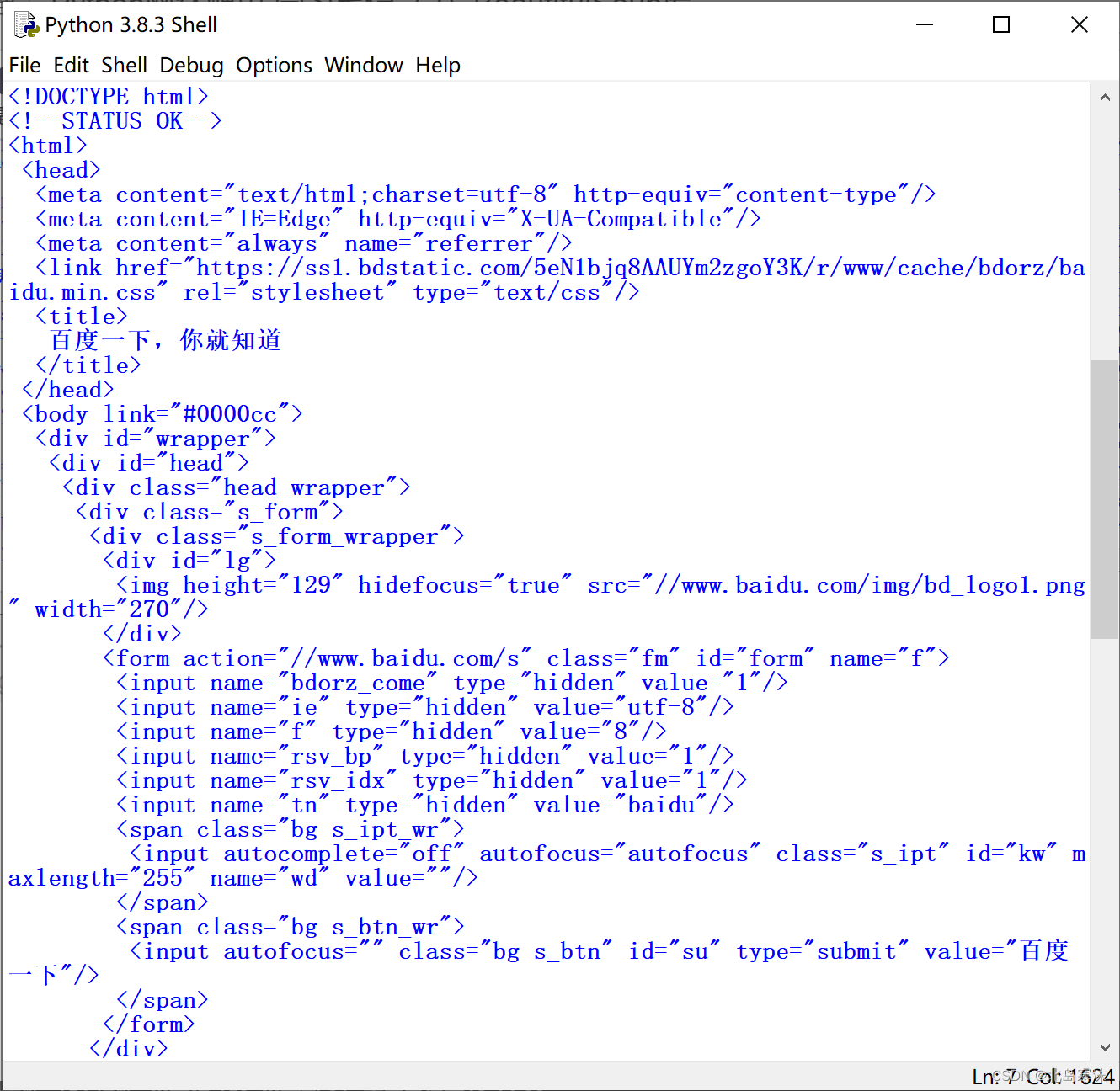
- 处理后:
使用BeautifulSoup库对HTML文件进行内容查找
信息的标记的相关概念(非重点)
信息标记的好处:
- 标记后的信息可以形成信息的组织结构,增加了信息的维度。
- 标记后的信息可以用于通信、存储或展示。
- 标记后的结构和信息一样具有重要价值。
- 标记后的信息有利于程序的理解和应用。
HTML简介:超文本标记语言。HTML是WWW的信息主要组织形式,能够将各种超文本信息嵌入到文本中。HTML通过标签组织不同类型的信息。
信息标记的三种形式:
XML:
- 基本概念:扩展标记语言,是一种与HTML很接近的标记语言,采用以标签为主来构建和表达信息的方式。
- 特点:最早的通用信息标记语言,可扩展性好,但是较为繁琐。
- 举例:(参考北京理工大学慕课)

JSON:
- 基本概念:由有类型的键值对构成的信息表达格式。
- 特点:信息有类型,文本信息比例最高,比XML更加简洁。
- 举例:(参考北京理工大学慕课)

YAML:
- 基本概念:采用无类型的键值对构成的信息表大格式,通过缩进来表示所属关系。
- 特点:信息无类型,文本信息比例最高,可读性好。
- 举例:(参考北京理工大学慕课)

信息提取的一般方法:
- 完整解析信息的标记形式,再提取关键信息。需要标记解析器,如bs4库对标签树的遍历。特点是信息解析准确,但是提取过程繁琐且速度很慢。
- 无视标记形式,直接搜索关键信息,对信息的文本进行查找即可。特点是提取过程简洁且速度较快,但是提取结果的准确性和信息内容相关。
- 融合方法:结合形式解析和搜索方法来提取相关信息,这是实际使用中最好的方法。
find_all()方法(重点)
基本语法:find_all(name,attr,recursive,string)
返回值:返回一个包含满足条件的标签的集合,集合中的每一个元素是一个标签。
- name:对标签的名称进行检索的字符串。如果需要同时查找多个标签名,可以传入一个列表。
- attrs:对标签属性值的检索字符串,可以标注属性检索。用于查找带有某个指定名称属性的指定名称的标签。
- recursive:布尔类型。当为True时表示查找当前标签的所有子孙标签;当为False时表示仅查找当前标签的同一层标签。
- string:对一对标签之间的字符串进行检索。
备注:find_all方法的基本语法都只支持精确查找,例如与查找目标相差一个字符,或包含查找目标的情况都无法查找成功,需要借助正则表达式库。
查找某个指定属性为指定值的语法:find_all(属性名=属性值)
备注:此时find_all方法不能再添加attr参数。
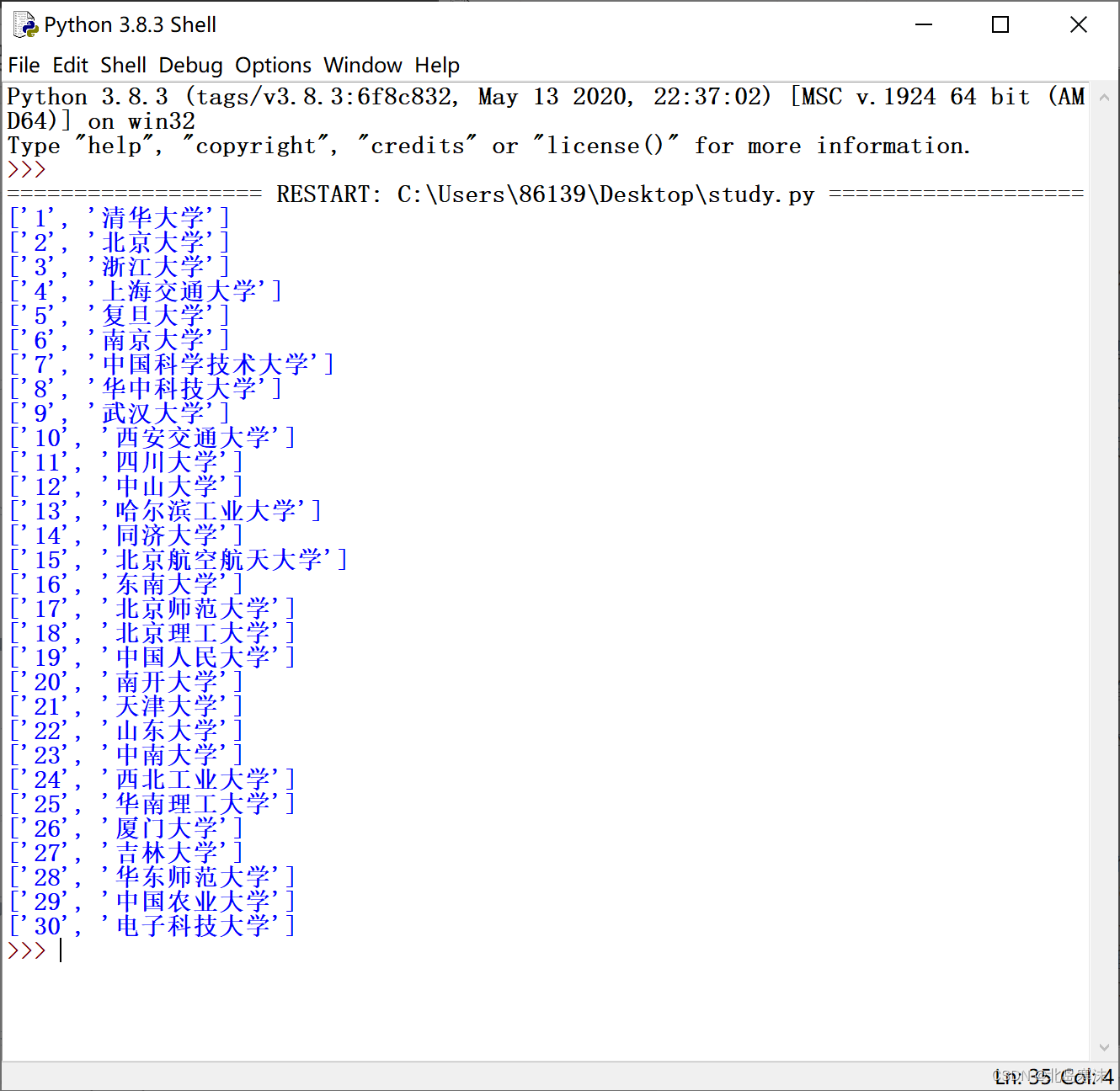
综合实例:爬取软科2022中国大学排名
# 进行网站爬取首先需要导入requests库
import requests
# 对网页的HTML内容进行解析需要用到bs4库
import bs4
# 需要使用到bs4库中的BeautifulSoup类对象
from bs4 import BeautifulSoup
# 设置所爬取的软科大学排名网站的URL
URL="https://www.shanghairanking.cn/rankings/bcur/2022"
# 使用request库的get方法爬取该URL对应的网络资源
r=requests.get(URL,timeout=20)
# 网络资源爬取可能失败抛出异常,因此需要考虑异常处理
try:
# 如果资源爬取异常,则产生一个HTTP异常类对象抛出
r.raise_for_status()
# 判断网站是否被认为采用默认编码,如果是的话则修改编码方式
if r.encoding=="ISO-8859-1":
r.encoding=r.apparent_encoding
# 获取所爬取的网络资源文本
text=r.text
# 使用BeautifulSoup对象对网络资源文本进行HTML格式的解析
HTML=BeautifulSoup(text,"html.parser")
# 设置一个空的列表用于存储结果
results=[]
# 由于所有需要的信息都在body标签中,因此首先截取body标签中的内容
body=HTML.find_all("body")[0]
# 找出body标签中的标签名为tr的子标签,基本每个子标签对应一所大学的信息(第一个标签除外)
trs=body.find_all("tr")
# 通过遍历的方式逐一提取信息
UniversityMaxNumber=len(trs)
for i in range(1,UniversityMaxNumber):
# 从每一个tr标签中寻找名字为td的子标签的第一项并记录其内容(大学排名)
Rank=trs[i].find_all("td")[0].string.strip()
# 从每一个tr标签中寻找名字为a的子标签的第一项并记录其内容(大学名称)
University=trs[i].find_all("a")[0].string.strip()
# 将大学排名和大学名称组合成一个子列表,插入到结果列表中
results.append([Rank,University])
# 输出大学名称和相应的排名
for i in results:
print(i)
# 网络资源爬取失败输出提示信息
except:
print("网站内容爬取失败!")
运行效果: