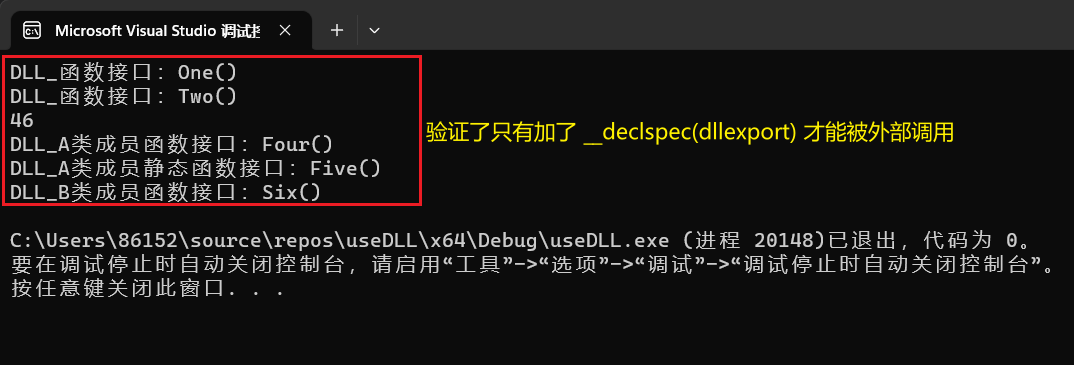
Redis中字符串应该是我们使用最多的一种数据类型了,但是有没有想过Redis是如何存储字符串的呢?Redis并没有用C语言传统的字符串(C语言中的字符串一般末尾采用空字符结尾,'\0'),而是采用它们自己实现的一种简单动态字符串(SDS)实现的;
比如说我们在Redis客户端执行如下命令:
set msg "hello world"那么Redis将会在数据库中创建一个新的键值对,键msg是一个字符串对象,底层就是保存着字符串"msg"的SDS;值也一样,底层也是一个SDS;
SDS的定义
在源代码sds.h的头文件中,可以看到SDS的定义:
==========================stdint.h==================================
/* Unsigned. */
typedef unsigned char uint8_t;
typedef unsigned short int uint16_t;
#ifndef __uint32_t_defined
typedef unsigned int uint32_t;
# define __uint32_t_defined
#endif
#if __WORDSIZE == 64
typedef unsigned long int uint64_t;
==========================分割线(sds.h)===============================
typedef char *sds;
struct __attribute__ ((__packed__)) sdshdr5 {
unsigned char flags; /* 3 lsb of type, and 5 msb of string length */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len; /* used */
uint8_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr16 {
uint16_t len; /* used */
uint16_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr32 {
uint32_t len; /* used */
uint32_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr64 {
uint64_t len; /* used */
uint64_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
=====================================================================可以看到有sdshdr5(没有使用)、sdshdr8、sdshdr16、sdshdr32、sdshdr64;它们有什么区别呢?其实是针对不同长度的字符串采用不同的数据类型去存储对应的值,可以看到sdshdr8,它的len和alloc都是使用的uint8_t,而在stdint.h中可以看到uint8_t使用的是char类型,而其它不同长度对应的类型也不同;不同长度的字符串用不同的数据类型存储,这样就可以节省空间。
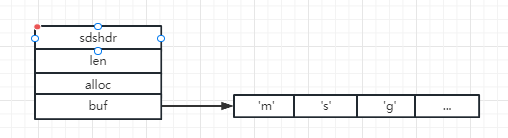
sds存储结构:
其中len表示已经使用了的长度,alloc表示实际分配的长度,buf是真正存储字符串的数组。
为什么要自己定义SDS来存储字符串
(1)SDS获取字符串长度的时间复杂度为O(1),而C语言本身提供的字符串获取长度时间复杂度为O(N)
从上面存储结构可以看出来,在结构中有个len属性,如果我们=想获取字符串的长度直接访问这个len属性即可拿到;而使用C语言本身提供的字符串,要获取长度的话需要遍历整个字符串计算出这个字符串的长度,时间复杂度为O(N);所以在Redis获取一个字符串的长度是很快的。对Redis服务器几乎不会造成任何性能上的影响。
(2)在对字符串进行拼接的时候可以动态扩容并且不会导致缓冲区溢出
在C语言有一个函数,可以把拼接两个字符串:char *strcat(char *dest,const char *src);当dest后面内存如果紧跟的有其它字符串的话,这个函数可能会产生内存溢出;而sds的字符串拼接因为记录了字符串的长度,所以在使用前会先判断,如果不够会再分配足够的内存之后在进行拼接,sds的拼接函数:sds sdscat(sds s,char * t) 。
sds字符串拼接 源代码:
//可以看注释,知道大概流程
sds sdscat(sds s, const char *t) {
return sdscatlen(s, t, strlen(t));
}
sds sdscatlen(sds s, const void *t, size_t len) {
size_t curlen = sdslen(s); //当前字符的长度
s = sdsMakeRoomFor(s,len); //为s扩容,腾出足够的空间,len是拼接字符串的长度
if (s == NULL) return NULL;
memcpy(s+curlen, t, len); //拼接字符串
sdssetlen(s, curlen+len); //将字符串的长度更新为 目前的长度+分配的长度
s[curlen+len] = '\0'; //结尾字符 sds并没有算上它的长度,对用户来说是不可见的
return s;
}
sds sdsMakeRoomFor(sds s, size_t addlen) {
void *sh, *newsh;
size_t avail = sdsavail(s);
size_t len, newlen, reqlen;
char type, oldtype = s[-1] & SDS_TYPE_MASK;
int hdrlen;
size_t usable;
if (avail >= addlen) return s;
len = sdslen(s);
sh = (char*)s-sdsHdrSize(oldtype);
reqlen = newlen = (len+addlen); //需要扩容的长度
assert(newlen > len); /* Catch size_t overflow */
if (newlen < SDS_MAX_PREALLOC) //SDS_MAX_PREALLOC = 1024*1024 = 1M
newlen *= 2; //扩容 新长度的2倍
else
newlen += SDS_MAX_PREALLOC; //大于1M时 直接多分配1M的空间
type = sdsReqType(newlen);
if (type == SDS_TYPE_5) type = SDS_TYPE_8; //如果是sdshdr5 直接向上转换为 sdshdr8
hdrlen = sdsHdrSize(type);
assert(hdrlen + newlen + 1 > reqlen); /* Catch size_t overflow */
if (oldtype==type) {
newsh = s_realloc_usable(sh, hdrlen+newlen+1, &usable);
if (newsh == NULL) return NULL;
s = (char*)newsh+hdrlen;
} else {
/* Since the header size changes, need to move the string forward,
* and can't use realloc */
newsh = s_malloc_usable(hdrlen+newlen+1, &usable);
if (newsh == NULL) return NULL;
memcpy((char*)newsh+hdrlen, s, len+1);
s_free(sh);
s = (char*)newsh+hdrlen;
s[-1] = type;
sdssetlen(s, len);
}
usable = usable-hdrlen-1;
if (usable > sdsTypeMaxSize(type))
usable = sdsTypeMaxSize(type);
sdssetalloc(s, usable);
return s;
}说实话,上面这段源代码的 :sds sdsMakeRoomFor(sds s, size_t addlen) 方法我没有完全看懂,我只知道大概意思,因为我本身是搞Java开发的,C语言是在大学学的,加上很久没有用过了所以导致看起来比较困难,如果你看懂了的话,请留言给我讲解一下。阿里嘎多 /(ㄒoㄒ)/~~
(3)减少了修改字符串时带来的内存重新分配次数
在C语言字符串底层实现使用数组实现的,在每次对字符串进行修改的时候都会对存储字符串的数组进行一次内存重新分配操作(Java可能就是基于这个原因,才把字符串底层的数组设置为final的把把;比如说对字符串进行拼接,那么就需要内存重新分配来扩展底层数组的大小,必然就会像上面说的那样产生内存溢出。因为每次内存重新都会涉及复杂的算法,还有可能会执行系统调用,所以对于Redis这种使用字符串频率很高的系统,会严重影响性能。所以Redis通过空间预分配和惰性空间释放两种优化方案来大大提升了效率。
空间预分配:
可以简单的理解为 在对字符串进行增长操作的时候,可以给这个字符数组多分配一些预留空间(java集合动态扩容也用到了这种思想),它的扩容方式你看过上面的代码应该有印象了,当SDS的长度小于1M时,直接扩容二倍,当超过1M时就直接多1M。
if (newlen < SDS_MAX_PREALLOC) //SDS_MAX_PREALLOC = 1024*1024 = 1M
newlen *= 2; //扩容 新长度的2倍
else
newlen += SDS_MAX_PREALLOC; //大于1M时 直接多分配1M的空间惰性空间释放:
惰性空间释放就是当对字符串进行截取的时候(简单理解为缩短字符串的长度),并不会立即释放已经没有使用的空间,而是预留,以免在后面的时候又使用;我们知道SDS有len和alloc这两个属性,它们会记录记录当前字符数组使用情况;
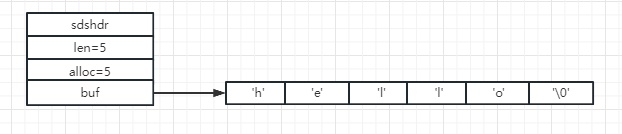
可以看到这时候字符数组已经满了,假设我们对它进行截取操作,只要he了,那么这时候会变成什么样子呢?
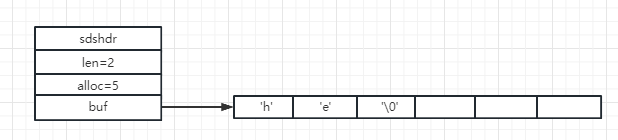
剩余未使用的空间依然保留了,下次在进行增加的时候可以通过len属性知道还有剩余足够空间,不用进行扩容,直接使用就可以了,不需要再去进行内存重新分配;提升了使用效率。
总结
我简单介绍了Redis底层字符串的存储结构,字符串在Redis中使用非常多,它们通过定义简单动态字符串(SDS)来提升了字符串的使用与分配很大程度上提高了Redis的效率;是不是发现人家的思维真的很厉害?光一个字符串都能优化到这种程度,其实去学习一些东西的时候,还是有必要学习一下底层原理,因为有一些设计思想真的很棒。