因为需要测试客户端程序与hadoop服务器之间正常通信需要开通的端口, 所以在hadoop各服务器上使用iptables防火墙屏蔽了测试客户端程序的ip和所有端口。然后,根据报错信息提示的端口号来逐步放开直到能正常通信下载文件。
- 在服务器端屏蔽指定ip访问所有端口

#查看防火墙状态,没启动的要启动
service iptables status
service iptables start
#查看已有规则和规则号,iptables的链是从上到下匹配到就结束
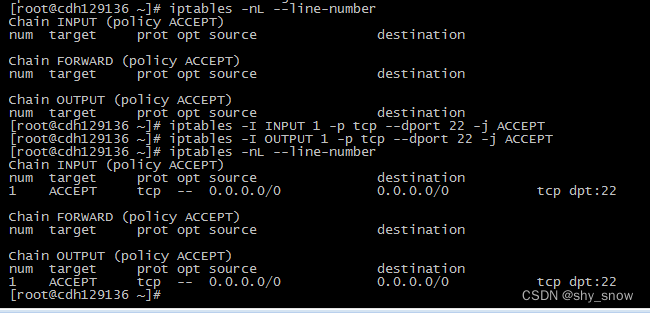
iptables -nL --line-number
# ssh用的22端口不要限制
iptables -I INPUT 1 -p tcp --dport 22 -j ACCEPT
iptables -I OUTPUT 1 -p tcp --dport 22 -j ACCEPT
#尾部插入一条记录,拒绝ip访问除了22端口以外的所有端口
iptables -A INPUT -s 192.1.217.54 -p tcp -m tcp ! --dport 22 -j REJECT
- 测试客户端程序报错端口,然后再放开单个端口
报错无法和namenode通信,需要放开8020端口

#iptables -nL --line-number 查看规则在第几行
# 在第1行插入一条放行的端口,一定要插入在上面那个REJECT屏蔽ip的上面,因为iptables的链是从上到下匹配到就结束
iptables -I INPUT 1 -s 192.1.217.54 -p tcp -m tcp --dport 8020 -j ACCEPT
# 命令说明,
# -I代表插入规则
# INPUT代表是INPUT进入来的链路
# -s 是匹配源,这里是指定了ip
# -p tcp 协议类型,指定了匹配tcp的
#
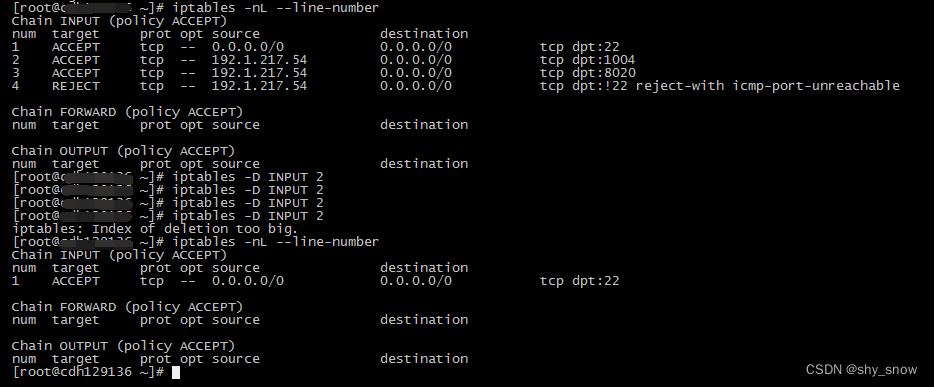
可以读取目录了,继续测试get下载文件,报错1004端, 继续放开1004端口,和上面放开端口的方法一样,iptables -I INPUT 1 -s 192.1.217.54 -p tcp -m tcp --dport 1004 -j ACCEPT。这个端口是datanode的服务端口,需要把hadoop集群的所有datanode机器防火墙上1004端都做处理,因为你也不知道文件会在哪个datanode上保存着。
#iptables -nL --line-number 查看规则在第几行
#在第1行插入一条放行的端口,一定要插入在上面那个REJECT屏蔽ip的上面,因为iptables的链是从上到下匹配到就结束
iptables -I INPUT 1 -s 192.1.217.54 -p tcp -m tcp --dport 1004 -j ACCEPT
开放namenode的8020和datanode的1004端口后,可以下载hdfs文件了。
测试完成后删除规则
#删除规则,谨慎操作, iptables -nL --line-number查看规则前的编号
iptables -D INPUT 规则编号
简单介绍下防火墙的使用:
#根据网络的进出链路,有几个可以增加规则进行控制的地方,一般只会用到INPUT和OUTPUT。
#可以对规则进行指定行号插入-I,修改-R也可以新增-A
#规则内有匹配规则,
#规则匹配后的处理是ACCEPT放行还是REJECT拒绝还是DROP直接抛弃
#在一个链路内,是匹配到规则就结束
- 参考
[1]https://blog.csdn.net/wxh0000mm/article/details/106239509
[2]https://blog.csdn.net/weixin_53139887/article/details/122418822
[3]https://blog.csdn.net/choukuad381324/article/details/100945546
[4]https://blog.csdn.net/m0_59432158/article/details/120369973
[5]https://blog.csdn.net/waghaiping/article/details/118048947
[6]https://blog.51cto.com/benny27/1952689