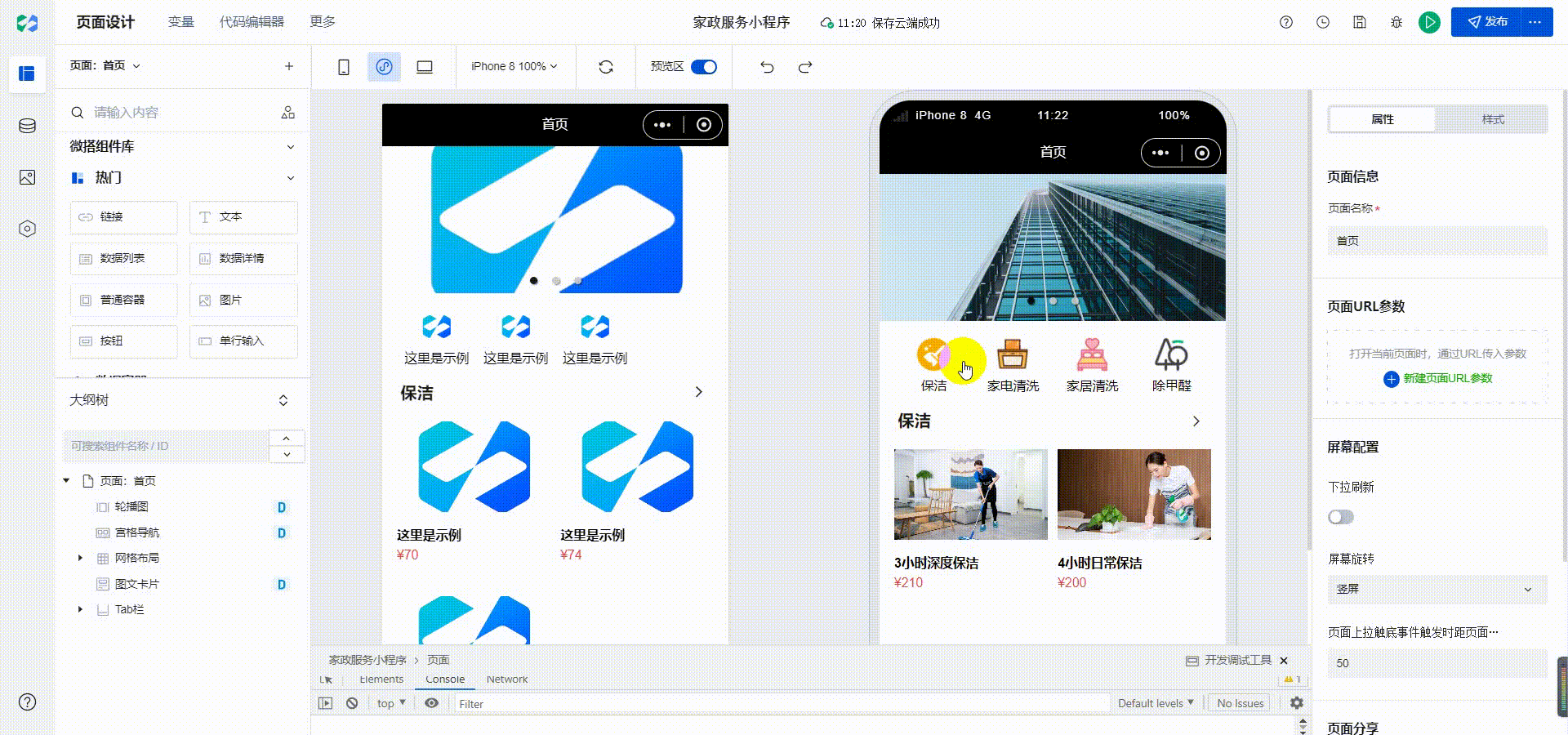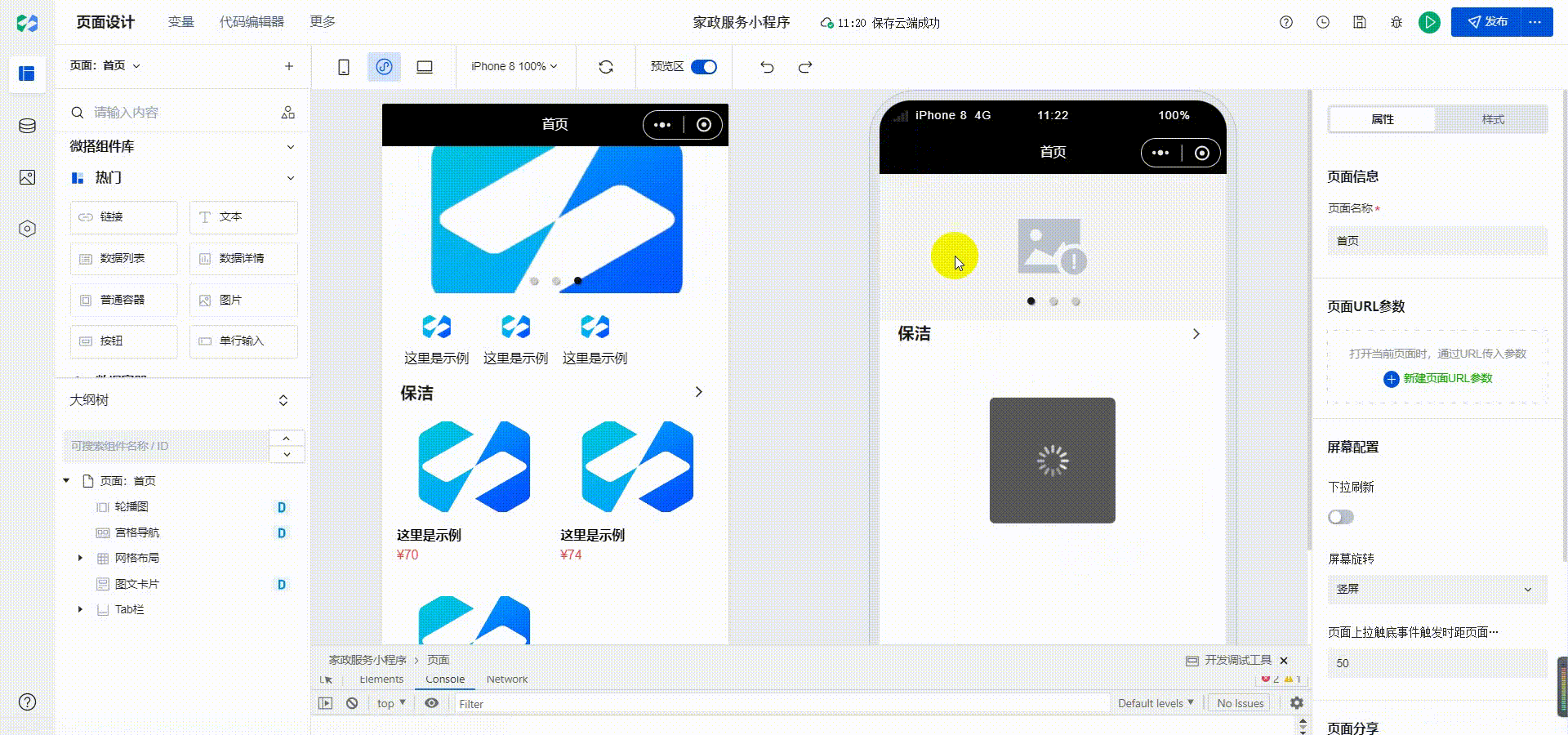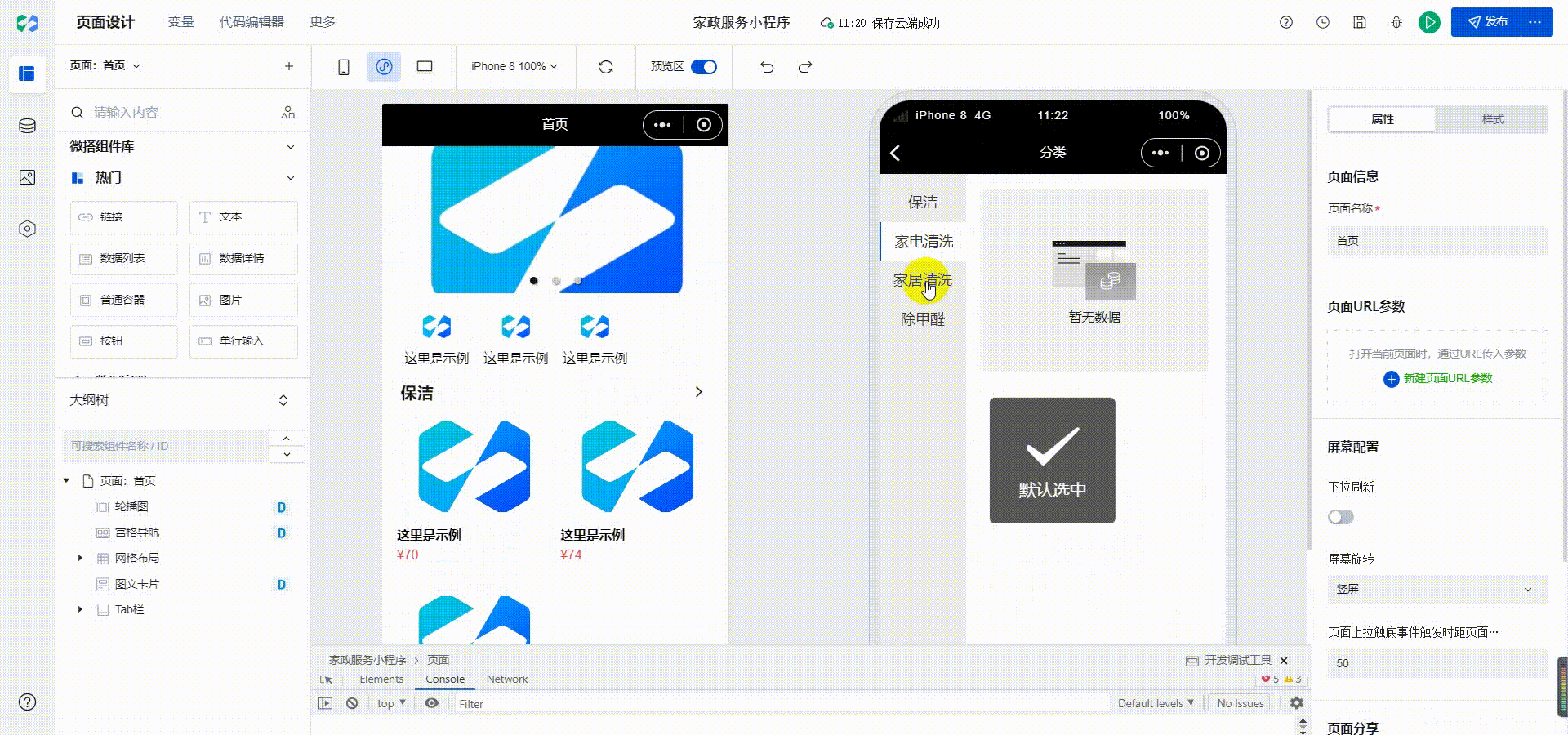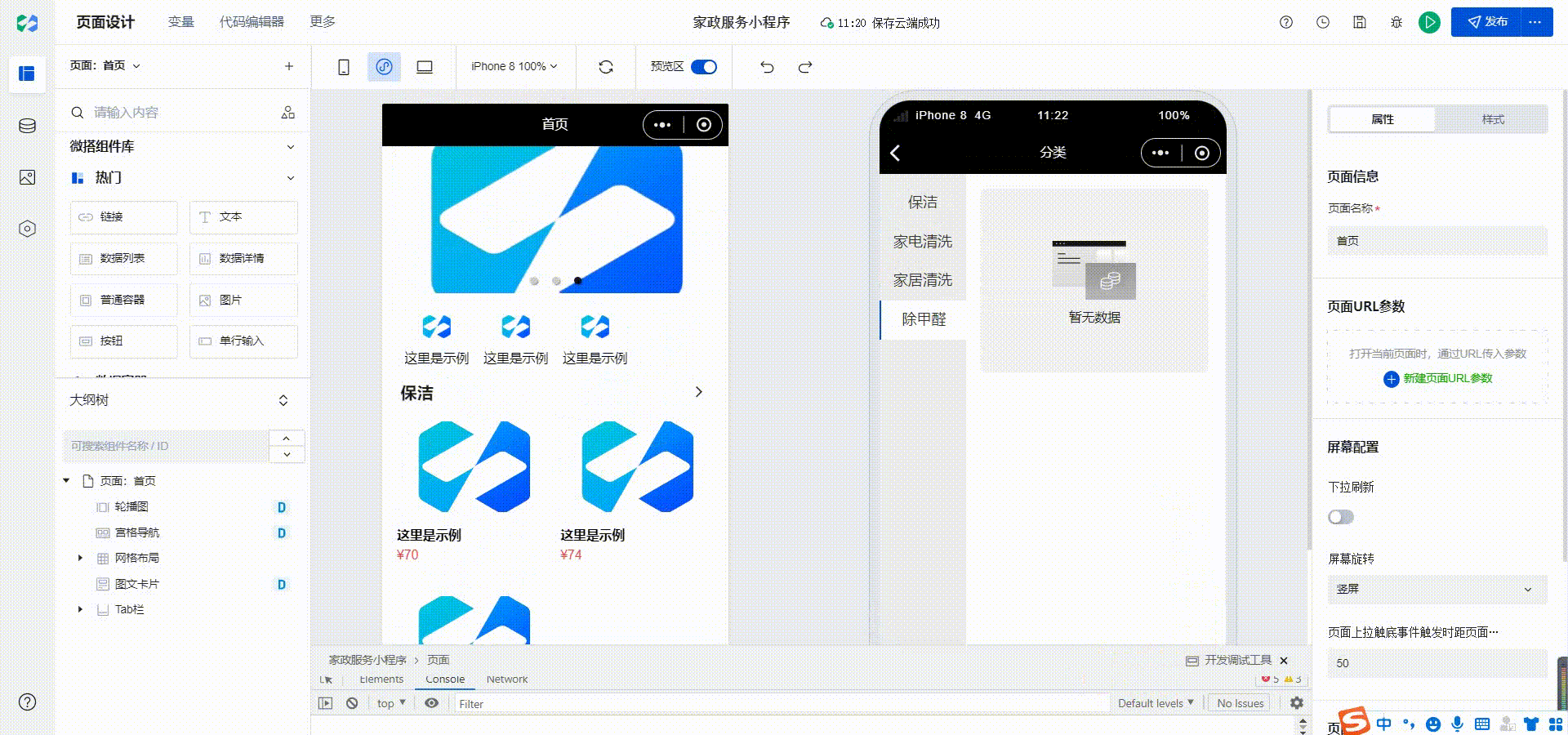
目录
1.什么是三维重建
2.MVS是什么
3.传统MVS的局限性和为什么基于深度学习的MVS性能好于传统三维重建
4.基础概念
5. patchmatchNet环境配置
6.如何测试自己的数据集(位姿计算)
6.1 colmap导出位姿
6.2 将colmap位姿转换成MVS读取的数据格式
1.什么是三维重建
用相机拍摄真实世界的物体、场景,并通过计算机视觉技术进行处理,从而得到物体的三维模型。英文术语:3D Reconstruction。
涉及的主要技术有:多视图立体几何、深度图估计、点云处理、网格重建和优化、纹理贴图、马尔科夫随机场、图割等。
是增强现实(AR)、混合现实(MR)、机器人导航、自动驾驶等领域的核心技术之一。

2.MVS是什么
用RGB-D信息重建3D几何的模型,输入的话是一系列的RGB-D照片,这些照片会有一些重合部分,我们计算这些照片的位姿信息(每个拍摄的相机角度的位置),我们就知道了每帧间的位置关系,然后对它进行一个3D模型的重建,最后将材质信息给它贴上去(纹理贴图,将RGB-D信息贴到几何模型上)。
这里的位姿信息获得是通过SLAM或者SFM来做的,我们就可以得到它的深度图进行点云融合等操作。
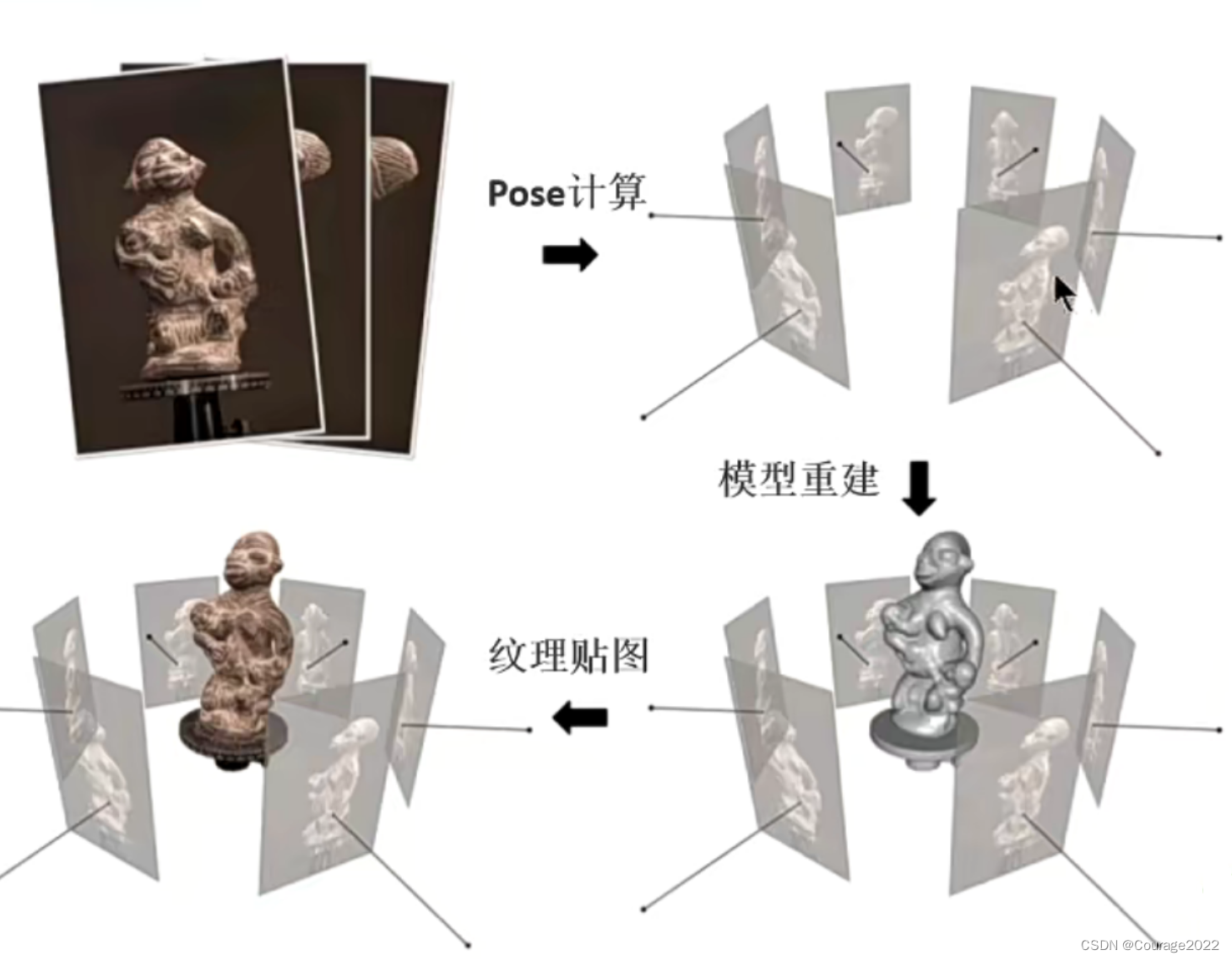
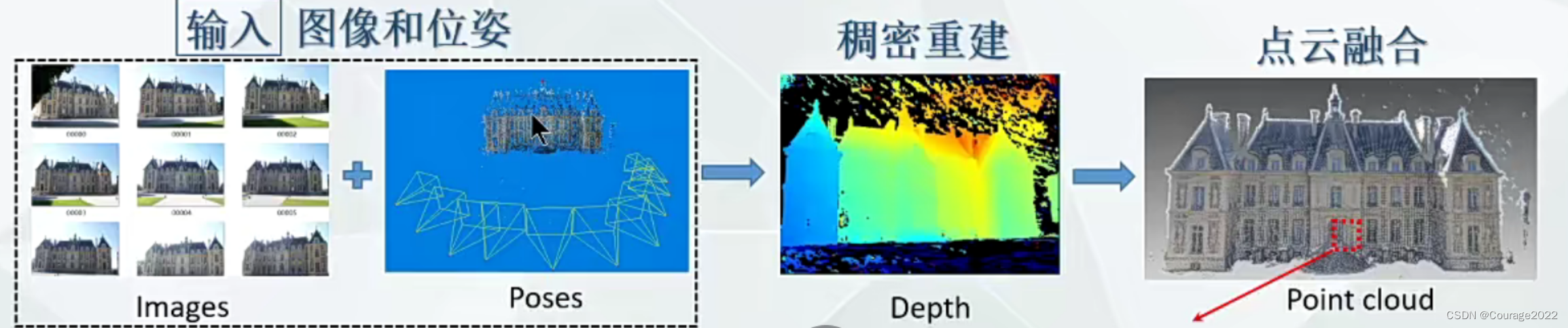
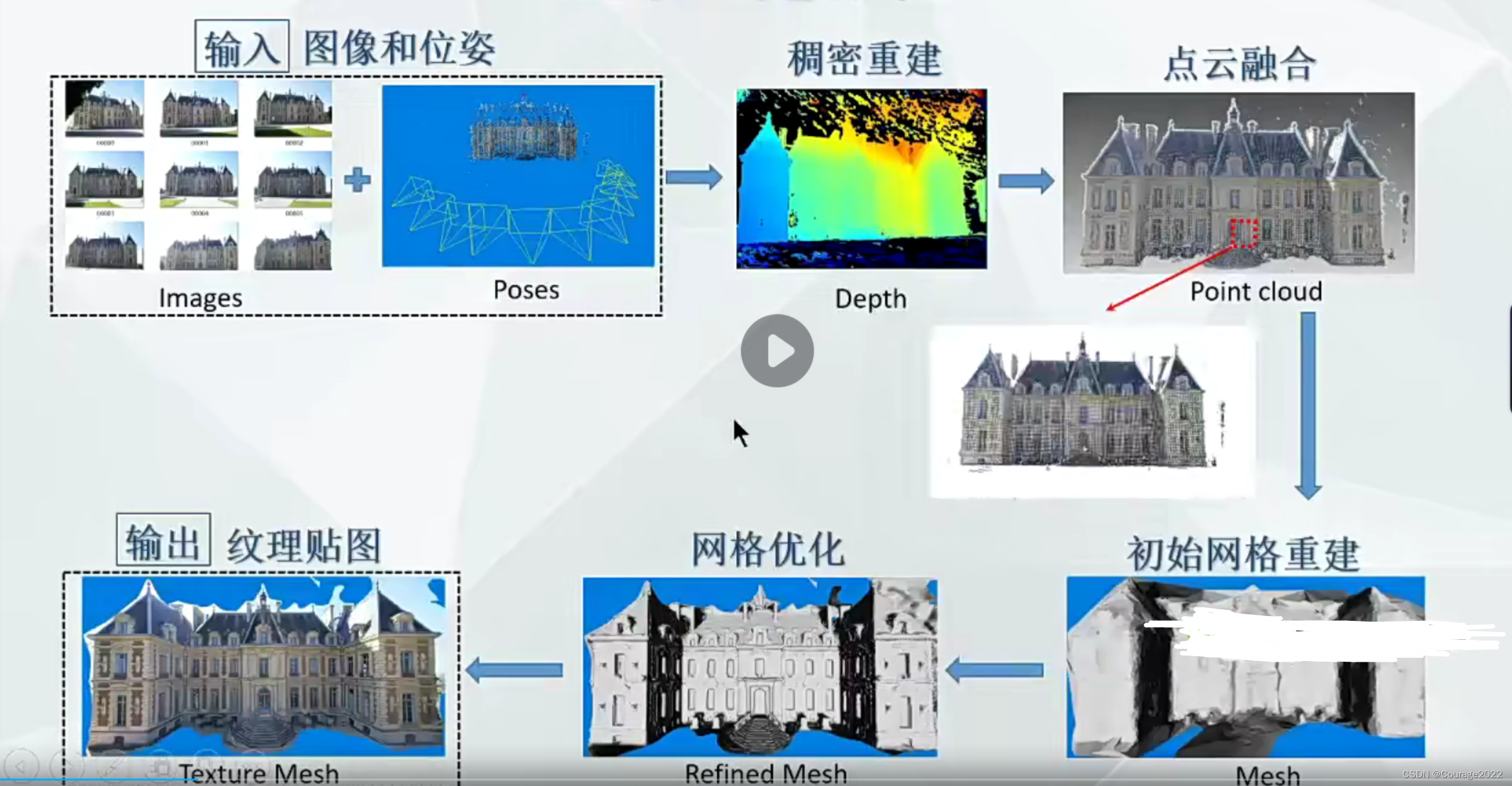
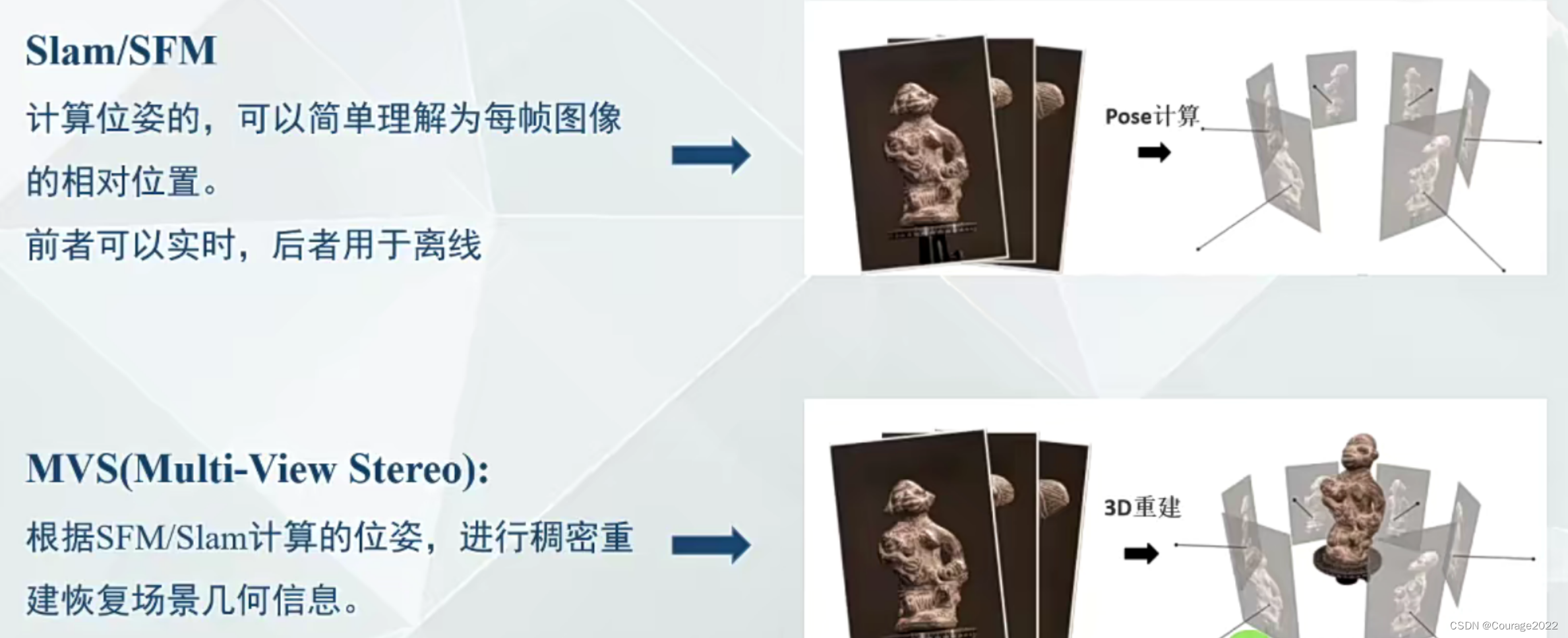
3.传统MVS的局限性和为什么基于深度学习的MVS性能好于传统三维重建
MVS重建我们是基于RGB-D信息做的,也就是说我们恢复3D信息是通过立体匹配等方法进行深度恢复,如果RGB信息出现大面积的单色情况(如下图)没有纹理信息的或者是透明的重复纹理的,那么我们很难进行特征点匹配,也就没有办法通过立体匹配进行深度恢复了,最终导致失败。
在深度学习中,我们通过大量的数据学习一些信息规律和信息。
但其也有一定的缺点,比如依赖显存和内存,依赖大数据,难以重建高分辨率的模型。




4.基础概念
①深度图(depth)/视差图(disparity)
a.深度图:场景中每个点到相机的距离
b.视差图:同一个场景在两个相机下成像的像素的位置偏差dis
c.两者关系:,是三维信息的一种表示方式。
深度图存储的就是相机坐标系下的
值
②三维点云:
a.三维点云是某个坐标系下的点的数据集。
b.包含了丰富的信息,包括三维坐标XYZ、颜色RGB等信息。③三维网格:
由物体的邻接点云构成的多边形组成的,通常由三角形、四边形或者其它的简单凸多边形组成。
④纹理贴图模型:
带有颜色信息的三维网格模型。
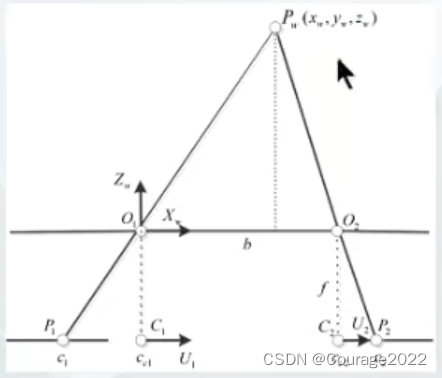
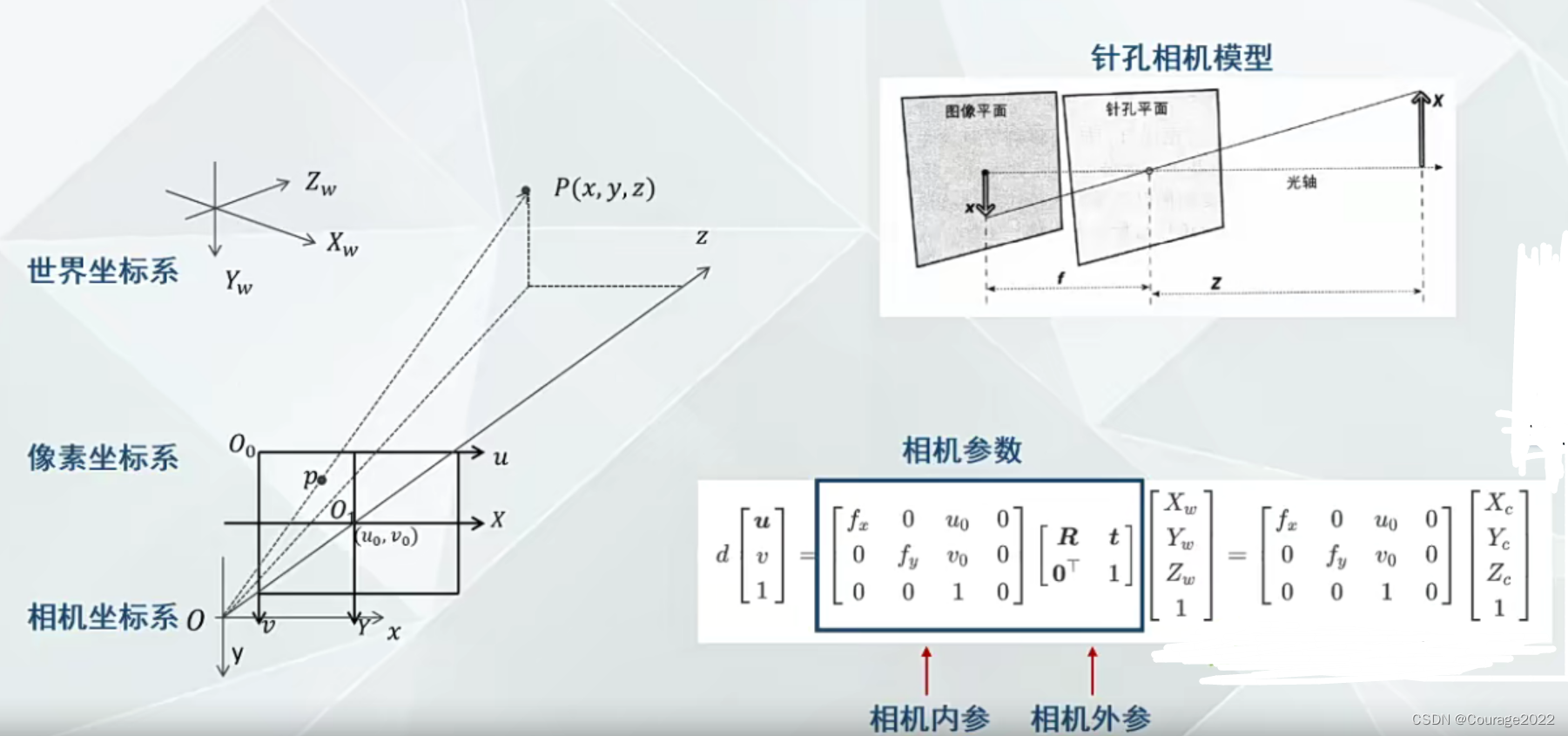
所有的颜色信息存储在一张纹理图上,显示时根据每个网格的纹理坐标和对应的纹理图进行渲染得到高分辨率的彩色模型。⑤相机模型:

5. patchmatchNet环境配置
利用Anaconda配置虚拟环境,python版本为3.7。如果有GPU的话cuda推荐版本为10.1,我是3060显卡,安装的cuda版本为11.3,pytorch版本为1.11.0,可顺利跑通!
下载patchmatchNet源码:
PatchNet Git地址
https://github.com/FangjinhuaWang/PatchmatchNet
里面有个requirements.txt
一键安装:pip install -r requirements.txt
到这里我们就安装成功了,测试一下:
先下载数据集:
下载DTU数据集 dtu.zip,在项目文件夹新建data文件夹,解压到data文件夹中。
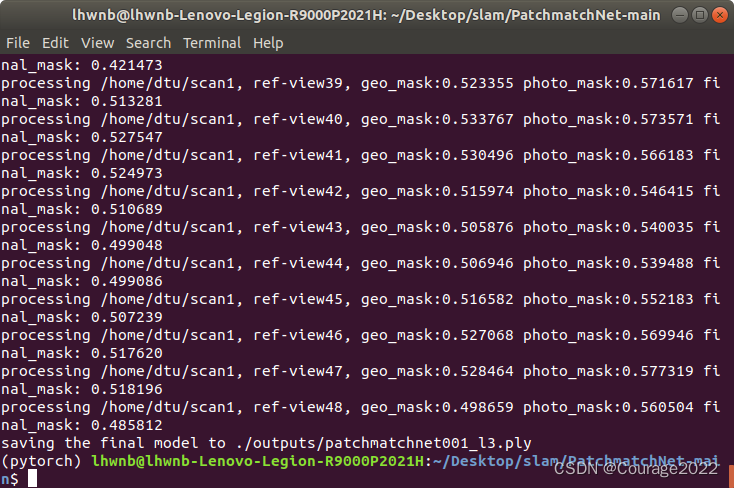
在代码路径下打开终端,激活conda环境,运行eval.sh,如果没有gpu,运行eval_cpu.sh。
运行结果保存在当前目录下./outputs下。
如果显卡性能不好或者CPU跑性能过慢的话,我们可以改变默认的分辨率大小,在eval.py中,main函数中,img_wh = (800,600),可以改为原来的一半。同时也要改dataset/dtu_yao_eval.py文件,MvsDataset类中更改图像分辨率。
最终重建的结果如下,效果还是不错滴!
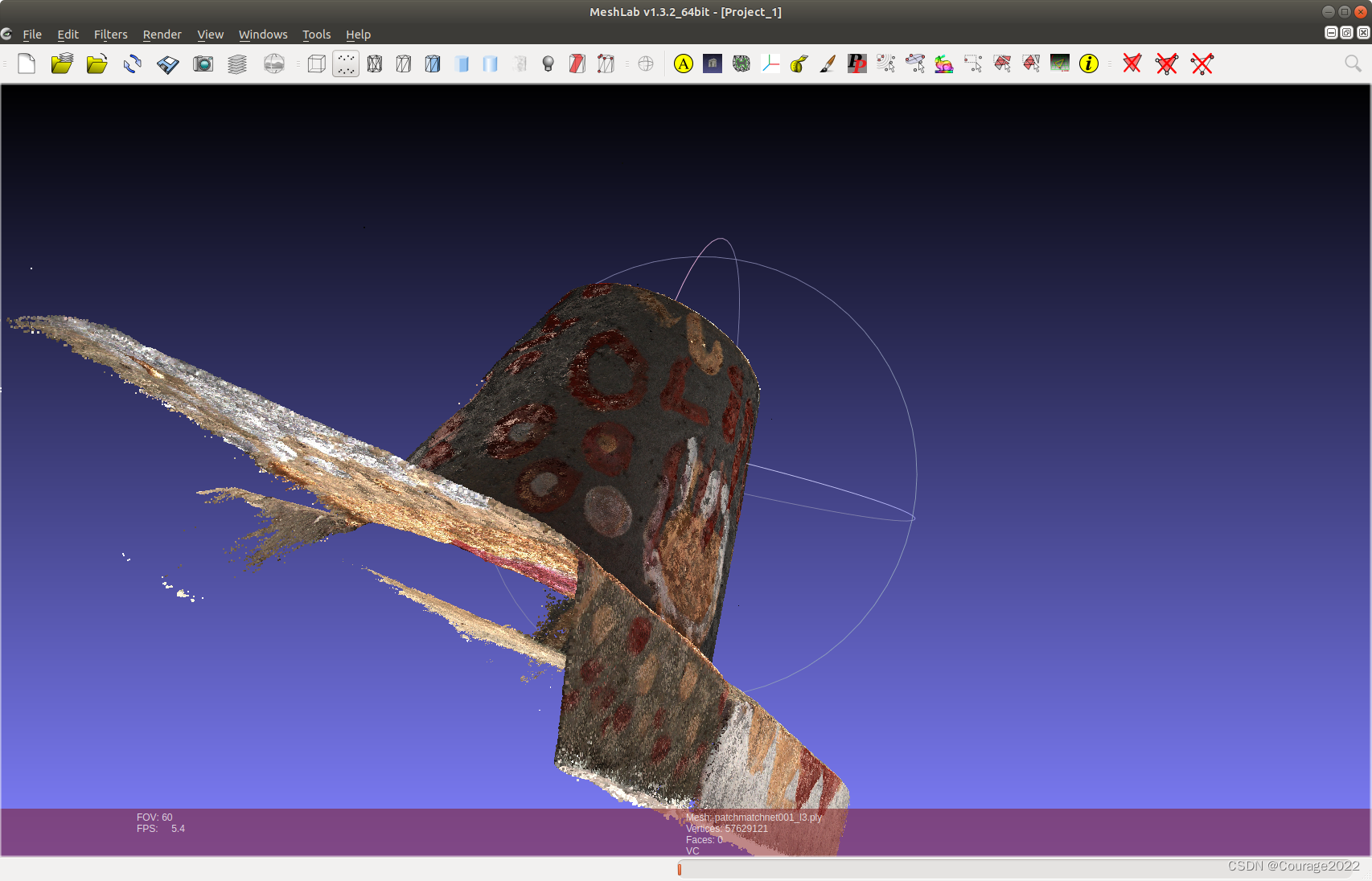
6.如何测试自己的数据集(位姿计算)
6.1 colmap导出位姿
比如我们用手机拍摄了一组照片,要对其进行三维重建,应该怎么做呢?
我们上面说到,输入到patchmatchNet网络中的参数是一组照片以及它们的深度信息(位姿+深度范围或者稀疏点云),因此我们主要做的就是数据格式的转换。
第一步就是位姿的计算,无论是sfm或者SLAM除了输出位姿(R,t)以外都会有稀疏点的输出,并且告诉哪些稀疏点会被哪些相机和关键帧看到,我们就是用这些信息完成重建。
一、数据:
数据要求:图的质量要好不能模糊遮挡、帧之间要有大量的重合区域。(弱纹理,高反光效果不好)
二、位姿计算:使用colmap计算位姿,也可以使用别的比如OpenMVG,Slam这些需要自己写转换脚本参考colmap_input.py。colmap git链接
双击:
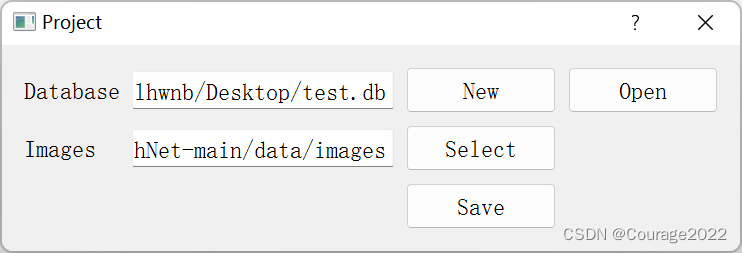
新建一个工程:
Database是新建的数据库名称,Images是包含图片的文件夹。
可以看到桌面已经有这个工程了。
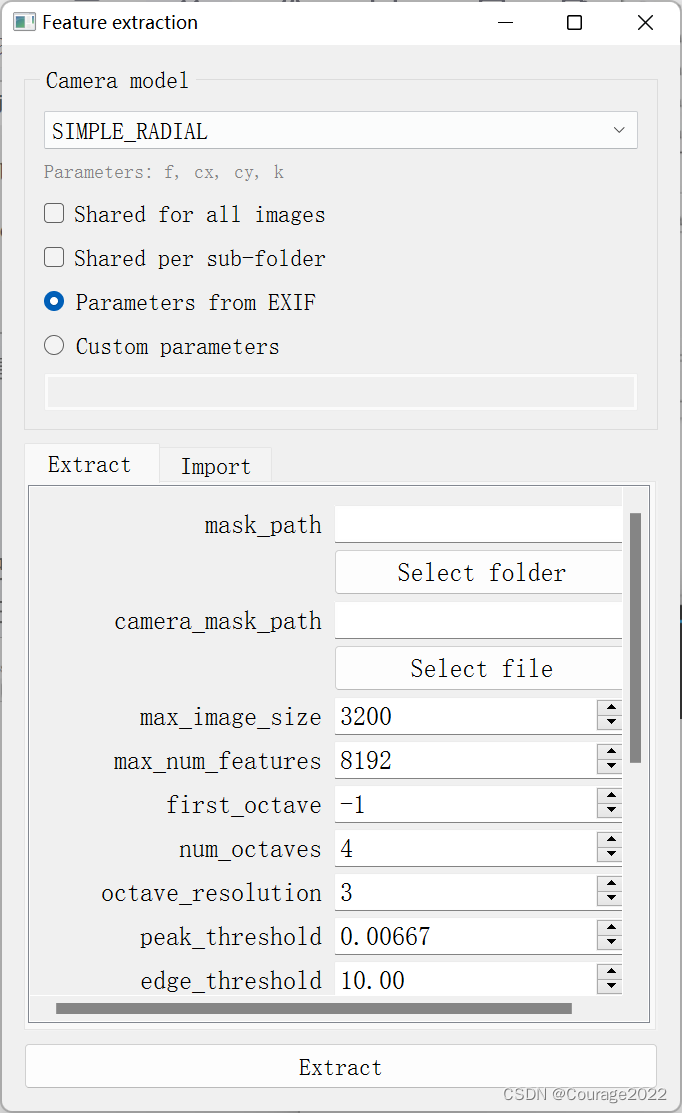
下一步就是特征提取,
点击提取
特征匹配完成!
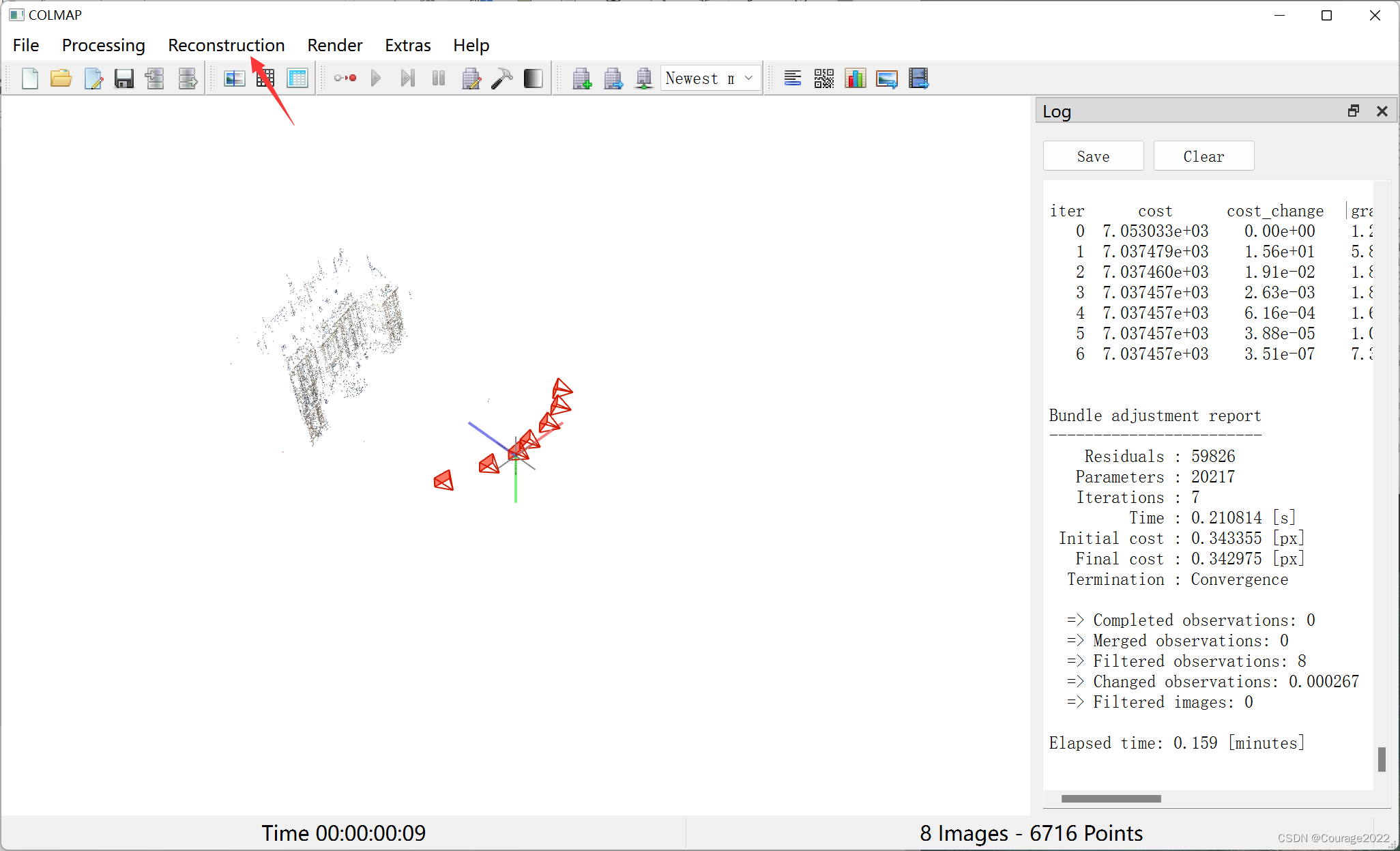
重建,点击开始重建。
红色的就是每帧相机的位置,黑色的就是稀疏的地图点。
现在我们就得到了哪些相机可以观测到哪些点、相机的位姿信息、相机的内参等。
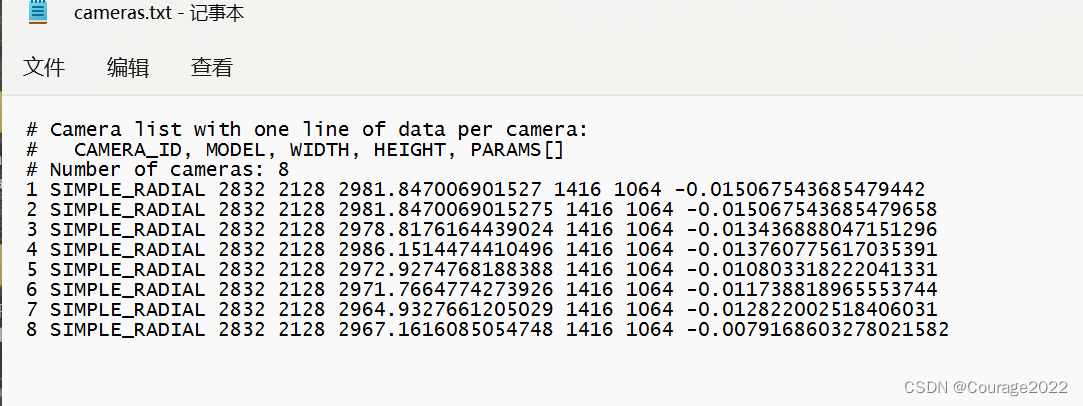
我们就可以用地图点计算深度范围计算初始的深度图都是可以的,接下来我们导出信息。FIle/Import model as text:
camera.txt里面是相机的参数:
images.txt里面存储着图像的参数以及像素坐标系下的坐标:
POINTS2D[] as (X, Y, POINT3D_ID)对应的就是在这个相机下能看到的所有三维点的ID及在这个相机下的投影坐标(u,v)。
points3D.txt里面存储着 3维点的XYZ以及它们的RGB信息以及误差,它们可以被哪些相机看到以及对应的2D点的索引:





6.2 将colmap位姿转换成MVS读取的数据格式
转换成MVS格式直接由DataLoader调用即可:
我们看怎么实现:colmap_input.py 我在源码中进行了标注
未完待续....