作者:马蕊 Lazada推荐算法团队
在Lazada各域推荐场景中,既有优质商品优质卖家不断涌现带来的机会,也有商品质量参差带来的问题。如何才能为用户提供更好的体验,对卖家变化行为进行正向激励呢?下面本文将为大家分享我们在与商品的演变成长性和商品的购买体验相关的三个环节中探索实践的经验。
一、背景
Lazada 作为阿里在东南亚的重要电商板块,近年来发展迅速。其发展一方面体现在不断增长的用户体量上,另一方面也体现在快速变化的业务和供给上。数据显示,Lazada 首页猜你喜欢每日到访新客,这些用户也经历着不同的成长轨迹,从站外投放到成为注册用户,从未开单用户到成为开单用户,从低活用户成为高活用户。与此同时,在供给侧,东南亚六国每日新发的商品数量也十分可观,商品从上架到首单,经历降价、免邮、广告等运营动作,获得销量和评论的累积,最终或成为头部的热销商品。在这样一个用户和商品螺旋式交互成长的过程中,作为用户和商品的连接者,平台应该推荐什么阶段的商品给什么阶段的用户、从而形成一种怎样的体验?
推荐领域的前序工作,无论在工业界还是学术界,更多在于用户行为的利用和兴趣的建模。而在电商推荐中,被推荐的主体——商品,既不同于新闻的强时效性和强聚集性(快速出现快速消逝),也有别于电影的稳定性(与用户兴趣之间相对稳定),它具有一种特殊的“演变成长性”(即商品的转化效率一边受到逐渐累积的销量评论带来的缓慢渗透,一边受到卖家和平台的随时可能发生的运营动作的快速影响),这种演变成长性同样需要被建模在推荐排序当中。尤其对于成长型电商,候选的商品集中存在大量“变化”的商品,其对变化捕捉的准确度也决定了其对效率预估的准确度。除此之外,用户在电商平台与目标商品的完整交互包括购前和购后 (pre-purchase & post-purchase) 两个阶段,当前绝大多数的推荐系统只将购前行为的信息纳入到模型的样本和特征中,而购后的体验虽然并不会影响当前推荐系统的点击和转化效率指标,但对于用户的留存和复购都起到了至关重要的作用。尤其对于新用户而言,他对平台的首次购买体验很大程度上决定了他对平台的信任程度,不好的首单体验可能会导致无效的“拉新”。
在当前作为一个发展型电商的 Lazada 而言,在其各域推荐场景中,我们能够看到优质商品优质卖家不断涌现带来的机会,也需要正视商品质量参差带来的问题。其供给“变化”的速度之快,需要算法能力予以捕捉和反馈,一方面提供给用户更好的体验,另一方面也是对卖家变化行为的正向激励。因而在此,我们将商品演变抽象成一个单独命题,致力于让推荐随着 Lazada 供给侧的变化健康地“动”起来,并梳理出了与商品的演变成长性和商品的购买体验相关的三个环节,和大家分享我们在这些环节中探索实践的经验。

图1. 用户、卖家(商品)、平台三方交互下遇到的问题
二、整体设计
以 Lazada 首页猜你喜欢为例,在商品推荐的实操过程中,我们发现当前以用户侧特征和用户行为建模为主、以场景内的点击和成交效率最大化作为推荐的单一目标,容易造成场景内购前环节的自我闭环,从而与供给侧商品和业务的快速变化断层。从用户的角度来说,用户的体感多样性、发现性有待提高,优质的稀缺供给透出不足,付款后的购物体验没有机制来保证。从卖家的角度来说,新品新卖家进入平台后,难以获得曝光流量,启动困难;卖家在投入成本购买广告、站外引流、参加促销活动等只能在特定域内获得即时的额外流量,在活动结束后无法得到持续的跨场景的收益;卖家在进行商品核心属性的修改后(如打折、免邮等),平台对该变化的响应较慢。从平台的角度来说,商业信号的孵化同样面临启动困难的问题;同时在无法快速响应变化的推荐背景下,业务的测试周期也更长,影响迭代效率。
基于以上的诸多问题,我们从供给侧理解的角度入手,一方面宽进严出,让更多更新的商品进入候选获得流量,同时严格控制曝光商品的质量保障用户的满意度,另一方面,通过基于全域数据的商品“演变成长性”建模(此处全域指 Lazada 平台中用户在不同场景行为的汇总),打破场景内闭环,让推荐的成交预估更精准更具实效性。最终归纳为以下三个环节:
-
打开高潜入口:通过建设独立链路,探测高潜新发商品、承接商业孵化信号,打开推荐候选商品池入口。
-
优化成交排序:基于全域成交行为和商品核心属性演变建模,优化转化预估,服务多域商品推荐排序。
-
把控服务质量:追踪用户购后体验,把控推荐商品的服务质量,进一步建模购买满意度提升用户回访复购。
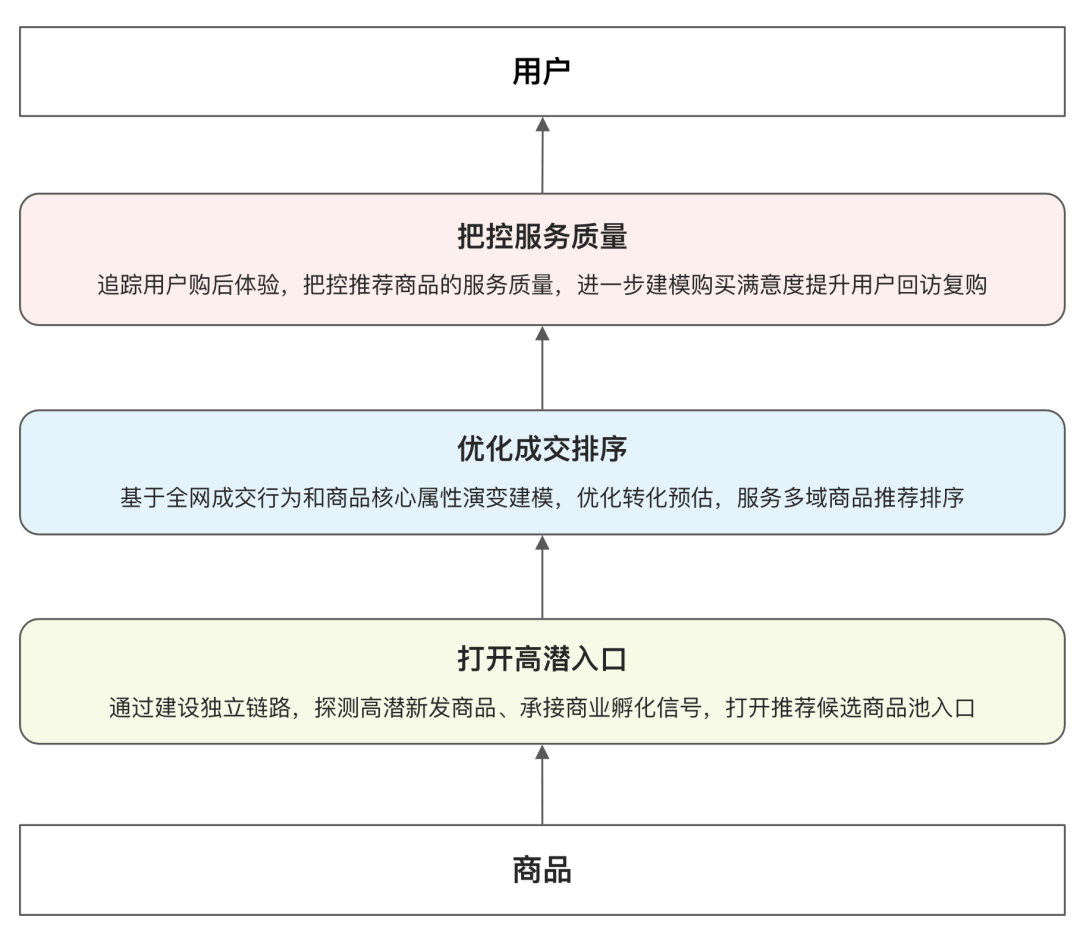
图2. 整体设计
三、打开高潜入口:通过建设独立链路,探测高潜新发商品、承接商业孵化信号。
对于不断发展的 Lazada 供给侧,除了把握好变化的头部商品之外,从 0 到 1 的新商品和新卖家的冷启动也是一个重要的问题。不同于搜索域用户主动发起的 query 具有较高的相关性要求,推荐域的流量分配相对自由,因此它也承担起了用户和平台的发现性作用。从平台的角度而言,新发的商品需要启动流量,新的业务也需要流量机制的保证,由此启发了我们在独立链路上的一系列工作。基于独立链路的冷潜品探测工作,经过长期的效果累积,东南亚六国指标已经实现了用户侧指标持平或提升的情况下,供给侧曝光商品数量显著增长,开单商品数量显著增加。同时,当前独立连路也以固定曝光占比的方式支持了多项供给业务。
1.1 背景和动机
为什么一定要搭建独立链路?纵观当前 Lazada 首猜的推荐机制,从全量商品池,到选品,再到基于历史行为的召回、粗排和排序,可以看到在每个阶段的透出都存在一定的限制。对于新发商品,以及行为稀疏、没有被加购或成交过的商品,难以通过在精排阶段使用传统的分数加权的方式拿到流量。然而这些新发的商品、新发之后一直没有得到启动的商品、或是由于周期性原因没有进入精品池或行为较少的商品,并不应该被一刀切地被认为是“差”的商品。除此之外,当前首页猜你喜欢的一些特定业务,覆盖的商品也存在透出困难的情况,需要绕开当前推荐的主链路,以直通的形式保证透出。
1.2 方案及算法
为了避免不必要的资源消耗,我们尽可能地复用了主链路的结构和算法模型,形成了与主链路平行的独立打分链路,并在混排层实现两个链路的混合。同时为了保证独立链路有能力透出新品和行为稀疏的商品,我们针对性地优化了其中的选品和个性化召回模型。
1.2.1 实现框架和工程架构
独立链路与主链路平行选品打分的基本框架如下图所示。当一次用户发起请求后,独立链路在混排之前与主链路完全平行且独立打分,其中粗排和精排复用了主链路的模型,选品和召回进行了针对性地调整。在实际工程部署中,独立链路单独构成一个与主链路并列的场景,其返回结果在混排层与主链路合并,最终根据混排配置曝光给用户。
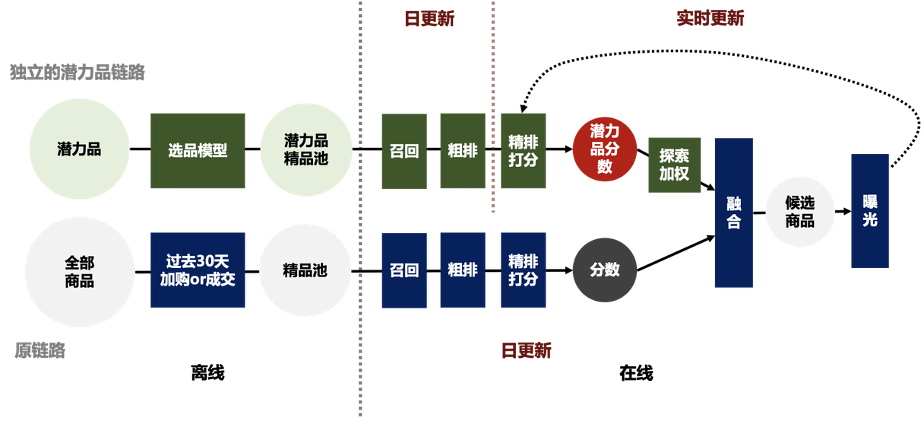
图3. 基本框架:独立平行的选品和打分
1.2.2 基于商品属性的个性化召回
在当前主链路的个性化召回模型中,商品侧的输入特征仅包含 item_id 特征。当我们在商品侧引入商品的属性特征时(包括商品的类目、品牌以及图片标题等),尽管在整体样本上的表现并无明显提升,但是通过将样本按照其目标商品的 30d 曝光量进行分档后可以看出,仅用 item_id 的 deepmatch 模型,其在商品上的 Hitrate 随着商品曝光量增大而提高,也就是说该模型的表现与商品的热度成正相关;而加入商品属性等 side information 后,在商品上的泛化能力得到了明显提升,模型在高热度商品上的表现接近,在低热度商品上的表现显著变好。因此,我们在独立链路中选用了基于商品属性的个性化召回模型。
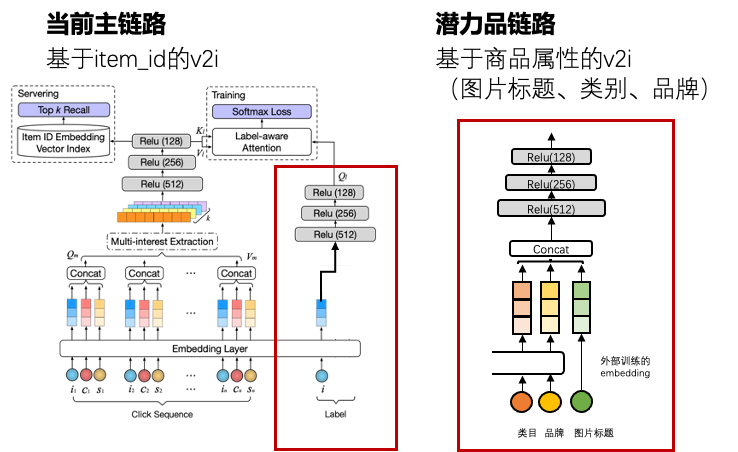
图4. 主链路和独立链路中的个性化召回
1.2.3 冷潜品探测实验中的选品
上述的技术框架和基于商品属性的深度召回是独立链路的通用解决方案,而针对冷潜品的“翻地”,我们按照下述的选品方案完成冷潜品的圈选:首先选出全部30天内上架的新品和过去30天内有过用户加购或成交行为的老品。无论对于新品还是老品,通过过去30天的曝光量来确定商品是否为冷品,作为第一轮的筛选条件,冷品要求商品过去30天曝光量 < α * 同类目同生命周期的平均曝光量,且商品过去30天曝光量 < 全局阈值。然后对于新品冷品,则根据商品多维度评估的蜂巢模型产出的综合稀缺性、流行趋势、卖家投入、行为历史、店铺力、品牌力六个维度的潜力分数,选出有潜力新冷品进行透出;而对于老品冷品,认为过去30天有过用户加购和成交行为,具有一定的竞争力的表现,故给到这部分满足条件的商品足够的启动机会,即全部进入冷潜品精品池。
1.3 实验方法和扩量
与传统的用户侧实验不同,冷潜品探测工作的预期收益并非是用户点击或成交指标的提升,而是推荐流量供给的变化。当主链路的推荐算法足够完善时,独立链路并不应该能为大盘指标带来即时的正向收益,甚至带来短期的负向。因此在实验观测上,我们一定程度上借鉴了手淘推荐在类似工作上的尝试,采用了“商品分组”ד用户分组”联合实验的方式:
分桶分组
-
用户分桶:通过 Hyper 分层将用户分为 N=10 个桶 {U0, U1, ..., U9}
-
商品分组:通过 Hash 算法将商品分为 M=10 个组 {I0, I1, ..., I9}
实验部署:分桶分组实验部署在一组 UI-Pair 上,如 (U0, I0)。
指标观测:效率总收益 = 商品组效率提升 - 大盘损耗
-
大盘损耗:U0 vs. {U1, ..., U9} 观察用户整桶指标,探索流量对大盘的消耗;
-
商品组收益:(Ux, I0) vs. {(Ux, I1), ..., (Ux, I9)}|x≠0 观测商品组之间效率变化、曝光商品数、Gini系数、精品池商品量等;
在实验阶段,我们指定商品分组 I0 进行冷潜品探测,在测试桶 U0 用户上通过独立链路的方式曝光 I0 组商品中的冷潜品。通过对比有实验的用户桶 U0 和没有实验的用户桶 {U1, ..., U9},可以获得冷潜品探测对大盘带来的损耗(用户指标);而对比有实验的商品组 I0 和没有实验的商品组 {I1, ..., I9} 在没有实验的用户桶上的表现 Ux|x≠0 即可评估商品组获得的收益(用户指标和供给指标)。
在对冷潜品探测实验扩量时,需要商品组和用户桶同时进行扩量操作,即同时在 k 个用户桶上对 k 个商品组进行探测。此时,每个用户组用于探测的流量不变,假设为 q,那么 k 个用户组同时探测,共用了 kq 的流量,分摊到每个商品组的流量仍然为 q,与扩量前的状态一致。因此可以认为,在用户-商品同步扩量的操作下,预期观测到的商品组效率提升和用户桶大盘损耗不变,效率总收益不变。
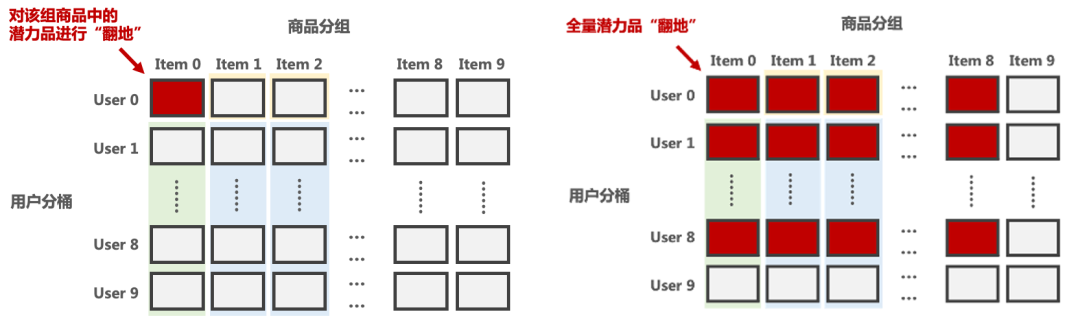
图5. 扩量前在一个用户分桶和一个商品分组上实验
图6. 全量后保留一个用户分桶和一个商品分组作反向
1.4 线上实验效果
1.4.1 短期探测损失及收益
在印尼的单用户分桶对单商品分组进行探测的实验上,短期效果如下:
-
探测损失:测试桶大盘 点击微负;
-
探测收益:探测商品组 曝光量和点击率显著正向;
-
供给侧变化:探测组 猜你喜欢曝光商品数显著增加
可以看到在点击率维度,效率总收益是正向的,同时该探测组商品在供给侧的提升显著。
1.4.2 长期观测获得即时正向
基于短期结果的正向,我们对冷潜品的探测实验进行了全量(保留反向用户桶和空白商品组),探测实验进行了数月,可以看到在全量效果下,冷潜品探测获得了即时的正向表现。数月内东南亚六国用户侧指标持平或提升,供给侧曝光商品数量迅速增长,开单商品数量显著增加,为推荐主链路的成交优化提供了更加肥沃的土壤。
四、优化成交排序:基于全域行为和核心属性演变建模的商品成交能力预估。
针对特定场景内的成交预估优化,除了背景中提到的商品的演变成长性问题之外,还面临着样本选择偏差和稀疏性的问题。在本节中,1)我们首先介绍了我们基于商品核心属性演变的商品序列建模 CAEN,在场景内单任务上论证了该方法优于业界的 SOTA 方法,并被 RecSys'22 接收为会议长文《CAEN: A Hierarchically Attentive Evolution Network for Item-Attribute-Change-Aware Recommendation in the Growing E-commerce Environment》;2)在具体实践中,我们将 CAEN 结构运用在全域点击到成交的预估任务中,通过分数加权的方式将全域成交信息补充在首页猜你喜欢和商品详情页的跨店推荐场景排序中,在成交指标上获得了显著提升。
2.1 商品核心属性演变建模
2.1.1 动机及概述
如背景中所述,商品具有一种特殊的“演变成长性”,它的转化效率既受到逐渐累积的销量评论带来的缓慢渗透,又受到卖家和平台的随时可能发生的运营动作的快速影响。尤其对于成长型电商,卖家侧的商品新发和运营动作十分频繁,对商品变化的捕捉也决定了效率预估的准确性。
前序的商品推荐工作,更多地建模在用户的行为和兴趣上,只有少量工作专注于商品的变化和与商品交互的用户序列[1~5]。这些工作将与目标商品有过交互的用户组织成“商品的用户行为序列”并在其上应用不同的结构进行特征抽取,如 Topo-LSTM[2] 和 DIB[3] 在序列上应用了 LSTM 和 Target Attention。手淘搜索提出的 TIEN[5] 通过在商品行为序列中标注交互时间,同时在时间序列的建模上进一步引入了感知时间的演化模块,使得点击预估模型能够更好地捕捉用户的新兴兴趣。尽管这些工作已经在商品与用户的交互中尽可能地抽取足够的信息,但是对于商品而言,其“演变成长性”外在表现为其对用户的吸引力和效率的变化,而内在归因于商品的核心属性和环境因素的变化。
以一个奢侈品包为例,当它的价格发生不同程度的变化时,它对用户的吸引力也随之发生变化:其中用户A在它打六折时被它的低价吸引,用户B在商品促销后积累了一定成交后,被它的销量/好评所吸引。因此,可以发现在当前商品侧序列建模中仍然存在着以下局限性:1)商品的核心属性变化,即导致商品的效率发生变化的原因,并没有被考虑在建模中;2)以商品和用户的每次交互作为商品时间序列建模的状态单元,会导致不必要的信息冗余和计算开销。
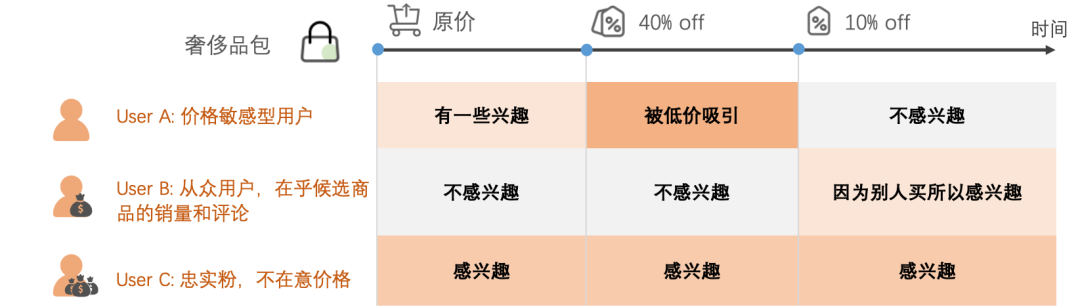
图7. 示例:商品核心属性(价格)变化带来的用户兴趣的变化
基于以上,我们提出了基于商品核心属性演变建模的 Core Attributes Evolution Network (CAEN) 。商品的行为序列,即一组按时间顺序与目标商品进行过交互的用户,根据商品上的核心属性变化被划分为若干个状态,CAEN 通过对状态下用户群体的特征提取从而建模商品在不同状态之间的变化。在这个框架下,我们进一步设计了一个分层注意力网络,该网络包含两层的注意力机制:上层为一个个性化注意力层,它从交互历史中激活相似用户,评估目标用户的匹配度;下层为一个属性感知注意力层,它对状态下的用户群体中“筛选”出被该属性所吸引的用户,通过对这些用户赋予更多权重以获得对该状态更准确地表达。
2.1.2 算法方案
此处我们以点击率预估任务为例,以论证 CAEN 结构用于商品行为序列建模的效果。在推荐系统中,目标用户和目标商品的点击率预估通常可以表示为:
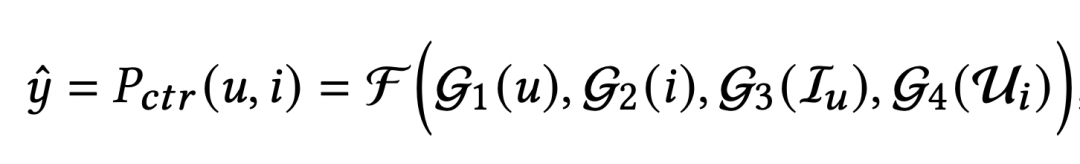
其中 F(·) 表示最后的决策层,在决策层之前的四个函数分别表示用户画像模块、商品画像模块、用户行为序列模块和商品行为序列模块;其中 Iu 表示和目标用户存在历史交互的商品序列,则 Ui 则表示和目标商品存在历史交互的商品序列。我们工作的主要关注点在于商品行为序列建模的模块。
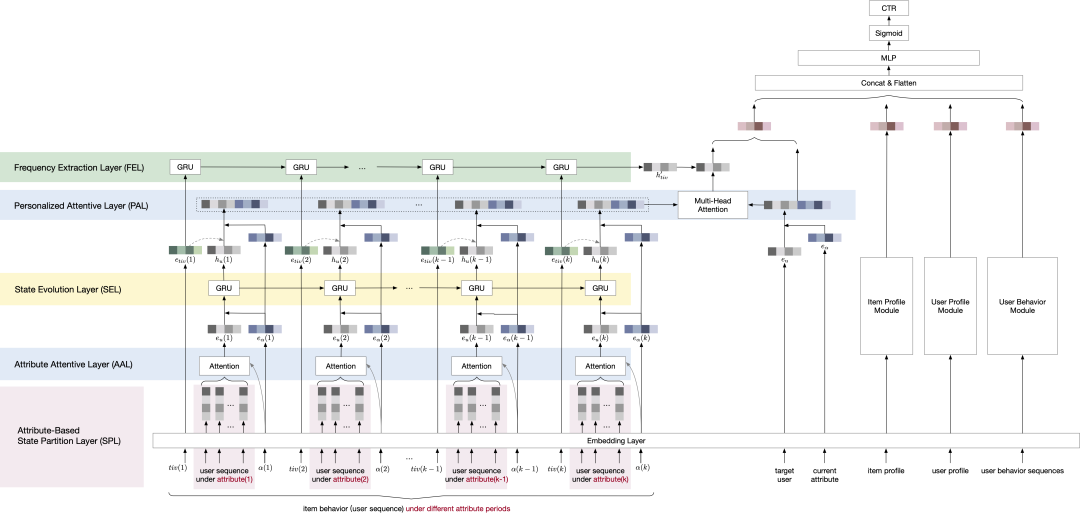
图8. 左侧为CAEN的模型结构,应用于右侧CTR预估框架下的商品行为序列模块
对于电商平台上的商品,其核心属性的修改可能会引起用户兴趣的发生变化,包括价格、促销活动、邮费、保修服务等等。由于 Lazada 平台促销活动多样、价格变动频繁,此处我们以价格作为核心属性的代表。CAEN 的整个算法框架由底层至顶层共包含 5 个算法层:
-
Attribute-Based State Partition Layer (SPL):在基于属性的状态划分层中,根据目标商品的核心属性变化,商品的生命周期被划分为多个属性状态。因此在每个状态下的特征,包括属性的取值、该状态下与目标商品交互过的用户序列、属性状态发生的时间戳被组织起来,经过Embedding层后传递给下一算法层。
-
Attribute Attention Layer (HAN-AAL):对每个属性状态应用基于属性的注意力提取,聚合该状态下的相关用户从而获得属性状态下用户群体的表征。不同于简单的池化结构或多重池化策略,基于属性的注意力机制除了可以获取用户的恒定兴趣之外,还强化了由当前属性(如低价)吸引而来的用户交互。
-
State Evolution Layer (SEL):由于商品的受欢迎程度不仅取决于当前的即时状态,还与过去状态下的积累有关。此处我们使用 GRU 建模相邻属性状态之间的演变。HAN-AAL 的输出被输入到一个 GRU 单元中,然后该单元的隐藏状态被视为当前状态的表征,并传递给下一个 GRU 单元。
-
Personalized Attention Layer (HAN-PAL):与多数推荐中的 target attention 类似,目标用户和商品在当前的属性组合在一起作为query,每一个状态的表征与其对应的属性组合作为key。于是在计算每个属性状态的权重时,既考虑了目标用户和历史用户之间的相似度,又考虑了商品当前属性和历史属性之间的相似度。
-
Frequency Extraction Layer (FEL):除了目标与历史的相似性度量之外,我们引入了状态变化频率的提取层,即在属性状态发生时间上应用循环神经网络,以提取出卖家在目标商品上的经营程度,同时也刻画了属性演变建模对该商品效率预估的重要程度。
上述两个穿插其中的注意力层 Attribute Attention Layer (AAL) 和 Personalized Attention Layer(PAL) 共同组成了一个多层注意力网络 Hierarchical Attention Network (HAN)。我们在这两个注意力层中应用了多头注意力机制,选取 scaled dot-product attention 作为 attention 的基础形式。通过输入 query Q,d_k 维 key K,以及 d_v 维的 value V,可以得到 softmax 归一化后的 value 权重。进一步地,有选择性地在 Q、K、V上进行线性映射,可以得到更高的模型表达能力;同时多头注意力机制可以允许多个不同的线性映射同时存在,从而聚合不同子空间下的表征信息。
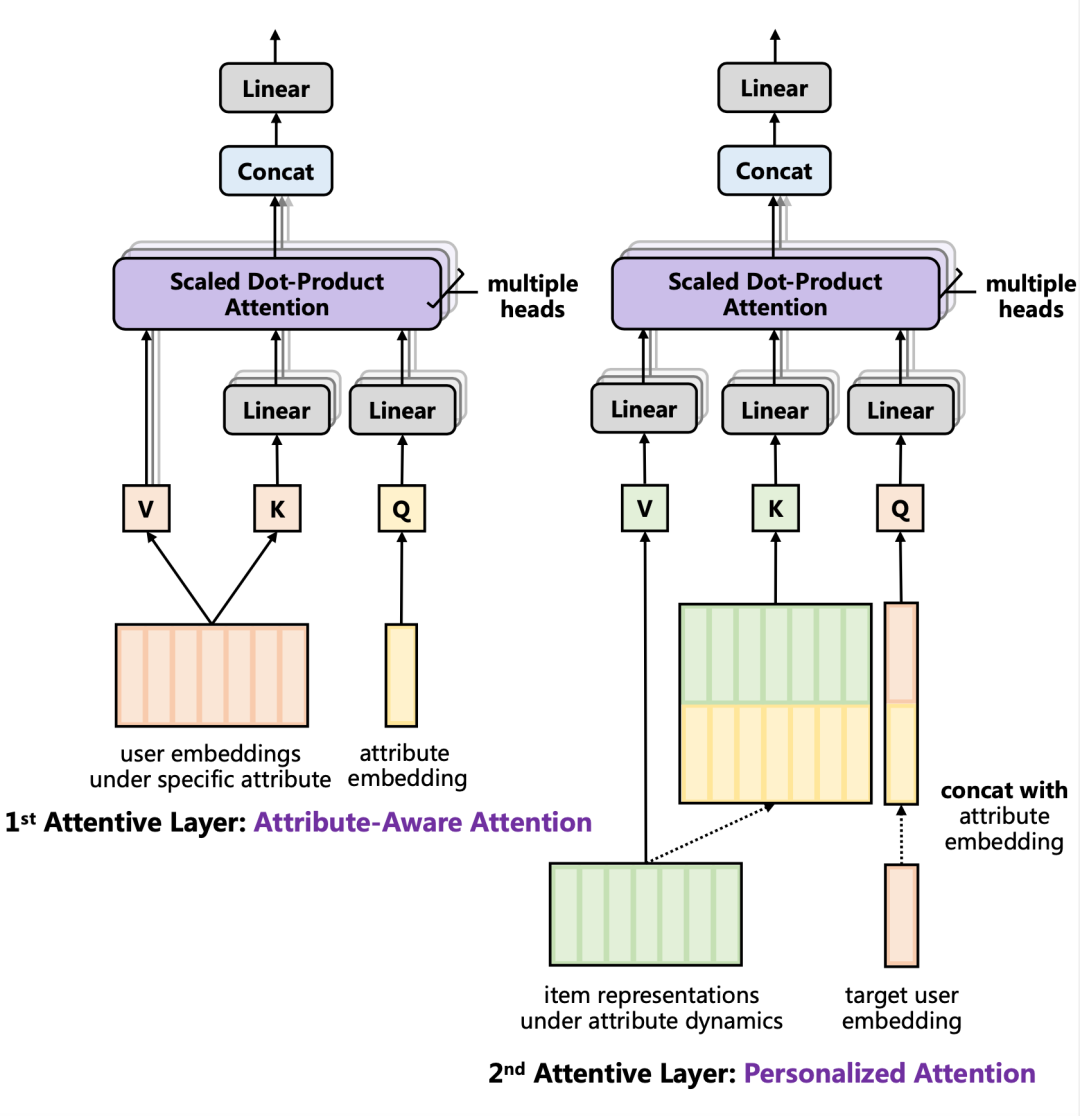
图9. 多层注意力机制网络 (HAN) 中两层结构的具体细节
具体地在 CAEN 中,如上图左边所示,在每一个状态中 Attribute Attention Layer 中,Query 为属性状态的 embedding,Key 和 Value 均为该状态下与目标商品交互过的用户 embedding。Query 和 Key 被分别映射到其他空间中以计算得到合适的相似度量值作为 attention 权重,而为了使得状态下用户群体的的表征与单一用户 embedding 的空间一致,我们将 Value 保留在了其原始空间。这样的 Attribute Attention Layer 被分别作用在每一个属性状态 下,但在每个单元中共享一套矩阵参数。而在 HAN 上一层的 Personalized Attention Layer 中,注意力机制用于从历史的商品属性和历史的用户交互中,获取与当前商品属性和目标用户相似的信息。因此,如上图右边所示,Value 为 SEL 输出的经过时间序列模型过滤后的属性状态下的用户群体表征,Key 为每一个状态下人群表征和对应的状态属性组合而成的显式的“用户群体+属性状态”矩阵,而 Query 则为“当前用户+当前商品属性值”。
2.1.3 离线实验验证
单点击任务
为了全面评估 CAEN,我们选取了 Lazada 平台在2021年1月中在印尼单站8天的曝光日志进行实验,包括该次曝光是否被点击,以及对应的用户、商品和它们在过去30天的历史序列行为。在实验中,我们选择价格这一核心属性的变化作为划分状态的依据,并将前7天的数据作为训练数据,第8天的数据作为测试数据。在发表的论文中,我们回答了以下五个问题。
-
RQ1 整体表现:CAEN 相比于 State-of-the-Art 序列建模方法在 CTR 预估任务上的表现如何?
-
RQ2 消融实验:CAEN 中的不同模块是否都能够帮助推荐效率的提升?
-
RQ3 实用性实验:CAEN 作为商品侧建模模块是否可以适配不同的用户侧建模模块用于点击率预估?
-
RQ4 在变化商品上的表现:CAEN 在不同属性变化程度的商品上有何表现?
-
RQ5 超参选择:超参的取值如何影响模型效果?
多目标任务
根据点击效率预估的通用框架,我们又将 CAEN 作为商品侧序列建模模块叠加应用于了当前 Lazada 首猜线上精排的点击、加购、成交多目标任务结构中,相比于原结构,在离线数据中取得了点击不降、加购和成交任务显著提升的效果。这说明了 CAEN 对商品核心属性演变的建模是有效的,且商品价格的变化,对用户成交心智的影响要高于对用户点击引导的影响,这也是符合认知的。
2.2 全域行为的利用及业务效果
在上一节的工作中,我们论证了 CAEN 模型结构的有效性,也论证了商品核心属性演变建模对商品成交预估的作用。然而首猜场景当前的目标是“逛”,它是一个成交稀疏的场景。为了更好地捕捉商品在成交效率上的变化,并且能够尽可能地利用到商品全部的行为信息,我们进一步将 CAEN 用到了全域点击到加购、点击到成交的预估任务中,然后将该任务的产出作用到不同的推荐域中。
2.2.1 非个性化全域成交分数
由简入繁,我们首先选取了非个性化的方式在推荐域中生效全域的转化率预估分数。对于图1左侧的 CAEN 结构,我们省去了 Personalized Attention Layer 即与目标用户和状态进行 Target Attention 的部分,将 CAEN 的输出与商品画像特征共同输出给 MMOE,形成对全域点击到加购成交的预估。
得到商品在全域的非个性化转化率分数后,我们将其作为额外的加权项,在首页猜你喜欢和商品详情页底部的跨店推荐场景的商品排序中生效,在两个场景中均得到了点击不降和成交显著提升的线上业务效果。同时对供给流量变化分析可以看到,有评分和高评分商品曝光变多,免邮的商品曝光变多,高销量以及有过内投广告的商品曝光变多;而新品和未开单商品曝光变少,但成交笔数均提升。可以看到该分数的引入使得原来无效的尾部流量给到了头部成交商品。非个性化全域成交分数虽然在预估效率上略逊于个性化,但由于其并不与用户侧耦合、可离线计算,线上资源开销较小,是轻量级场景的不错选择。
2.2.2 个性化全域成交分数
与用户侧序列建模不同,我们发现在商品侧序列建模的实际部署中有着前所未有的困难。当一个用户访问首猜场景,发起一次请求时,只需调用一次用户侧特征,而调用商品侧特征的量级与当前排序阶段的候选商品数量成正比,可能会是用户侧的百倍甚至千倍。
为了能够将个性化的全域成交分数部署上线,我们针对这一问题进行了诸多的尝试,最终采用了单阶段训练、两阶段模型部署的方式。即训练的方式保持不变,而在上线部署时,首先通过离线计算从商品完整的序列特征提取出商品的属性状态表征序列,将商品的属性状态表征序列存储在商品内容表中;在线上阶段,用目标用户与商品属性对商品状态表征序列进行个性化交互,完成后续的打分计算。

图10. 个性化全域成交分数的两阶段部署
拆图后在线上生效的后半阶段模型如下图所示,只保留了商品属性向量的多值特征读取、基于目标用户和当前商品属性的 Multi-head Attention、属性变化频率捕捉层中的 GRU,以及后续决策层中的结构。这种方式通过损失一定的特征序列的时效性,简化了线上计算的复杂度。最终,个性化全域成交分数的上线进一步拿到了线上成交效果的提升。
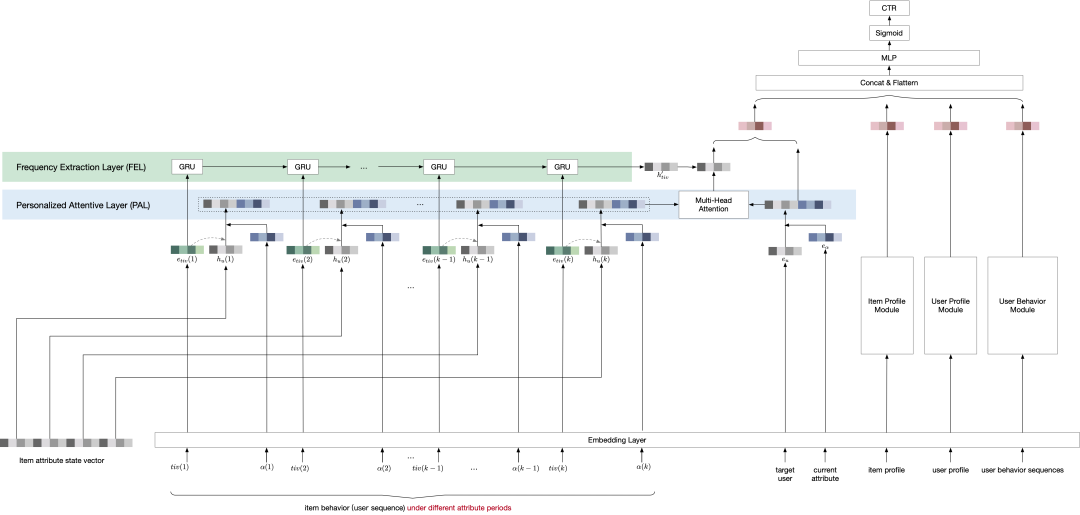
图11. 拆图后在线上进行计算的的后半阶段模型
五、把控服务质量:购后体验追踪和成交满意度建模。
除了提高用户与商品之间成交匹配的及时效率之外,我们发现用户成交的有效性和体验可能比成交行为本身更加重要。平台在外投和促成首单的过程中都有一定的成本开销,而未开单用户的首购体验很大程度决定他对平台的体感,即决定了拉新的质量。用户在平台上与商品的完整交互包括购前和购后 (pre-purchase & post-purchase) 两个阶段,而目前我们的推荐链路中重点考虑了购前行为,然而购后的体验虽然并不会影响当前推荐系统的点击和转化效率指标,但对于用户的留存和复购都起到了至关重要的作用。
根据初步的摸底,我们了解到 Lazada 平台当前用户在提交订单后的购后流程如下所示,包括卖家备货、分配物流、物流揽件&配送、货品送达、退货退款、评分评论等等。在整个过程中涉及到的用户“不满意”可体现在由于各方原因导致的订单取消、配送失败,以及买家发起的退货退款、评分评论等,这些“不满意”在整体订单数量中的占比是不可忽略的。
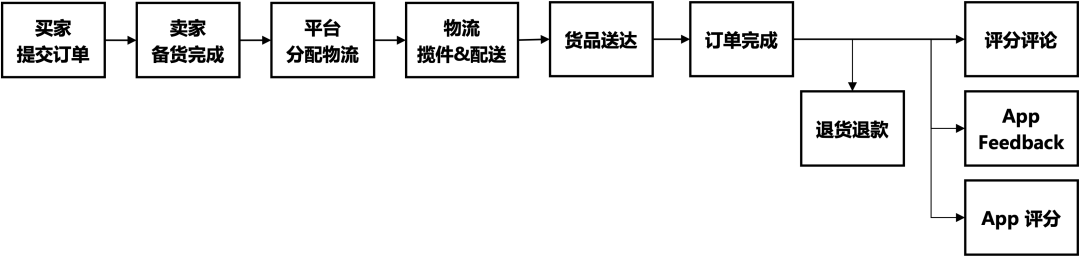
图12. 用户在平台的购后过程
在当前工作中,我们沿着非个性化到个性化的路径,逐步建模并更加准确地完成用户对商品的成交满意度预估,将满意度作为分数作用在购前的推荐环节中,并通过即时观测当日订单整体预估满意度、延迟观测实际满意度水平,评估成交满意度的模型和生效效果;通过长期的用户留存、回访和复购指标,评估成交满意度工作对平台的价值。在现阶段的实验中我们也发现,利用购后行为信息重新分配用户的浏览和购买结构,不仅能够带来后置成交满意度的提高,也可以提升前置用户购买决策过程的体验,体现在即时的成交指标中。
六、总结与展望
为了使推荐系统能够随着平台的快速发展健康地“动”起来,我们从供给侧理解的角度围绕高潜新冷品的探测和进入、商品的演变成长性建模、成交满意度的追踪和控制三个方面展开。在高潜新冷品的探测工作中,通过搭建和主链路平行打分的独立链路实现了新冷品的保量透出;该探测机制在短期实验中达到用户侧损失和收益持平,供给侧正向;在长期和全量的探测获得了即时的用户正向,以及供给侧曝光商品数的显著提升,支持了平台的可持续发展。在商品的演变成长性建模中,通过基于商品核心属性的变化对商品的历史行为进行状态划分和演变建模,有效地提高了对变化商品的效率预估能力;在实际业务中,由于成交能力可以被看作商品在演变成长过程中的重要表现,该模型被应用于全域成交的预估当中,并得到全域成交分数作用在推荐子域场景里,获得了点击不降成交能力的显著提升。成交满意度的追踪和控制不仅能够带来成交满意度的提高,也可以提升用户购买决策过程中的体验,从而提高成交效率。
同时,我们也可以看到,用户与商品相互影响、共同发展的问题,不仅是 Lazada 国际化过程中面临的问题,同时适用于很多新平台、发展型平台。尤其是其中商品的演变成长性建模,也具有一定的学术延续性和创新性,对于商品或是长生命周期目标的推荐问题都存在一定的参考意义。
接下来,Lazada 也将继续快速的发展和迭代,平台中的买家卖家也会继续不断的变化和成长。作为连接者,我们也将在供给侧方向持续发力,给买家更好的购买体验,帮助商家更快地优化推新,助力用户和商品螺旋式的交互成长。
参考文献
[1] Wu, L.; Yang, Y.; Zhang, K.; Hong, R.; Fu, Y.; and Wang, M. 2020. Joint item recommendation and attribute inference: An adaptive graph convolutional network approach. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, 679–688.
[2] Wang, C.; Zhang, M.; Ma, W.; Liu, Y.; and Ma, S. 2020. Make it a chorus: knowledge-and time-aware item modeling for sequential recommendation. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, 109–118.
[3] Wang, J.; Zheng, V. W.; Liu, Z.; and Chang, K. C.-C. 2017. Topological recurrent neural network for diffusion prediction. In 2017 IEEE International Conference on Data Mining (ICDM), 475–484. IEEE.
[4] Guo, G.; Ouyang, S.; He, X.; Yuan, F.; and Liu, X. 2019. Dynamic Item Block and Prediction Enhancing Block for Sequential Recommendation. In IJCAI, 1373–1379.
[5] Li, X.; Wang, C.; Tong, B.; Tan, J.; Zeng, X.; and Zhuang, T. 2020. Deep Time-Aware Item Evolution Network for Click-Through Rate Prediction. In Proceedings of the 29th ACM International Conference on Information & Knowledge Management, 785–794.