-
梯度提升算法
from sklearn.ensemble import GradientBoostingClassifier
clf = GradientBoostingClassifier(subsample=0.8,learning_rate = 0.005)
clf.fit(X_train,y_train)1、交叉熵
1.1、信息熵
- 构建好一颗树,数据变的有顺序了(构建前,一堆数据,杂乱无章;构建一颗,整整齐齐,顺序),用什么度量衡表示,数据是否有顺序:信息熵
- 物理学,热力学第二定律(熵),描述的是封闭系统的混乱程度
- 信息熵,和物理学中熵类似的
1.2、交叉熵
由信息熵可以引出交叉熵!
小明在学校玩王者荣耀被发现了,爸爸被叫去开家长会,心里悲屈的很,就想法子惩罚小明。到家后,爸爸跟小明说:既然你犯错了,就要接受惩罚,但惩罚的程度就看你聪不聪明了。这样吧,我们俩玩猜球游戏,我拿一个球,你猜球的颜色,我可以回答你任何问题,你每猜一次,不管对错,你就一个星期不能玩王者荣耀,当然,猜对,游戏停止,否则继续猜。当然,当答案只剩下两种选择时,此次猜测结束后,无论猜对猜错都能100%确定答案,无需再猜一次,此时游戏停止。
1.2.1、题目一
爸爸拿来一个箱子,跟小明说:里面有橙、紫、蓝及青四种颜色的小球任意个,各颜色小球的占比不清楚,现在我从中拿出一个小球,你猜我手中的小球是什么颜色?
为了使被罚时间最短,小明发挥出最强王者的智商,瞬间就想到了以最小的代价猜出答案,简称策略1,小明的想法是这样的。

1.2.2、题目二
爸爸还是拿来一个箱子,跟小明说:箱子里面有小球任意个,但其中1/2是橙色球,1/4是紫色球,1/8是蓝色球及1/8是青色球。我从中拿出一个球,你猜我手中的球是什么颜色的?
小明毕竟是最强王者,仍然很快得想到了答案,简称策略2,他的答案是这样的。

这就需要引入交叉熵,其用来衡量在给定的真实分布下,使用非真实分布所指定的策略消除系统的不确定性所需要付出的努力的大小。
1.3、sigmoid
后面算法推导过程中都会使用到上面的基本方程,因此先对以上概念公式,有基本了解!
2、GBDT分类树
2.1、梯度提升分类树概述
GBDT分类树 sigmoid + 决策回归树 一一> 概率问题!
-
损失函数是交叉熵
-
概率计算使用sigmoid
-
使用 mse 作为分裂标准(同梯度提升回归树)
2.2、梯度提升分类树应用
1、加载数据
import numpy as np
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.tree import DecisionTreeClassifier
X,y = datasets.load_iris(return_X_y = True)
X_train,X_test,y_train,y_test = train_test_split(X,y,random_state = 1124)2、普通决策树表现
model = DecisionTreeClassifier()
model.fit(X_train,y_train)
model.score(X_test,y_test) # 输出:0.84210526315789473、梯度提升分类树表现
from sklearn.ensemble import GradientBoostingClassifier
clf = GradientBoostingClassifier(subsample=0.8,learning_rate = 0.005)
clf.fit(X_train,y_train)
clf.score(X_test,y_test) # 输出:0.94736842105263153、GBDT分类树算例演示
3.1、算法公式
-
概率计算(sigmoid函数)
-
函数初始值(这个函数即是sigmoid分母中的F(x),用于计算概率)
逻辑回归中的函数是线性函数,GBDT中的函数不是线性函数,但是作用类似!
-
计算残差公式
-
均方误差(根据均方误差,筛选最佳裂分条件)
-
决策树叶节点预测值(相当于负梯度)
-
梯度提升
-
根据以上公式,即可进行代码演算了~
3.2、算例演示
3.2.1、创建数据
import numpy as np
from sklearn.ensemble import GradientBoostingClassifier
from sklearn import tree
import graphviz
X = np.arange(1,11).reshape(-1,1)
y = np.array([0,0,0,1,1]*2)
display(X,y)3.2.2、构造GBDT训练预测
# 默认情况下,损失函数就是Log-loss == 交叉熵!
clf = GradientBoostingClassifier(n_estimators=3,learning_rate=0.1,max_depth=1)
clf.fit(X,y)
y_ = clf.predict(X)
print('真实的类别:',y)
print('算法的预测:',y_)
proba_ = clf.predict_proba(X)
print('预测概率是:\n',proba_)3.2.3、GBDT可视化
第一棵树
dot_data = tree.export_graphviz(clf[0,0],filled = True)
graph = graphviz.Source(dot_data)
graph第二棵树
dot_data = tree.export_graphviz(clf[1,0],filled = True)
graph = graphviz.Source(dot_data)
graph第三棵树
dot_data = tree.export_graphviz(clf[2,0],filled = True)
graph = graphviz.Source(dot_data)
graph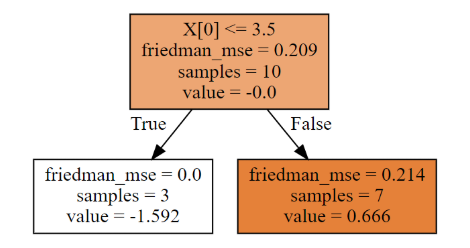
每棵树,根据属性进行了划分,每棵树的叶节点都有预测值,这些具体都是如何计算的呢?且看,下面详细的计算工程~
3.2.4、计算步骤
首先,计算初始值 :
F0 = np.log(y.sum()/(1-y).sum())
F0 # 输出结果:-0.40546510810816444
# 此时未裂分,所有的数据都是F0
F0 = np.array([F0]*10)
# 然后,计算残差
# 残差,F0带入sigmoid计算的即是初始概率
residual0 = y - 1/(1 + np.exp(-F0))
residual0
# 输出:array([-0.4, -0.4, -0.4, 0.6, 0.6, -0.4, -0.4, -0.4, 0.6, 0.6])3.2.5、拟合第一棵树
根据残差的mse,计算最佳分裂条件
lower_mse = ((residual0 - residual0.mean())**2).mean()
best_split = {}
# 分裂标准 mse
for i in range(0,10):
if i == 9:
mse = ((residual0 - residual0.mean())**2).mean()
else:
left_mse = ((residual0[:i+1] - residual0[:i+1].mean())**2).mean()
right_mse = ((residual0[i+1:] - residual0[i+1:].mean())**2).mean()
mse = left_mse*(i+1)/10 + right_mse*(10-i-1)/10
if lower_mse > mse:
lower_mse = mse
best_split.clear()
best_split['X[0] <= '] = X[i:i + 2].mean()
print('从第%d个进行分裂'%(i + 1),np.round(mse,4))
# 从第八个样本这里进行分类,最优的选择,和算法第一颗画图的结果一致
print('最小的mse是:',lower_mse)
print('最佳裂分条件是:',best_split)
现在我们知道了,分裂条件是:X[0] <= 8.5!然后计算决策树叶节点预测值(相当于负梯度),其中的 就是残差residual0
3.2.6、拟合第二棵树
第一棵树的负梯度(预测值)
# 第一棵预测的结果,负梯度
gamma = np.array([gamma1]*8 + [gamma2]*2)
gamma '''输出:array([-0.625, -0.625, -0.625, -0.625, -0.625, -0.625,
-0.625, -0.625, 2.5 , 2.5 ])'''梯度提升
# F(x) 随着梯度提升树,提升,发生变化
learning_rate = 0.1
F1 = F0 + gamma*learning_rate
F1 ''' 输出 array([-0.46796511, -0.46796511, -0.46796511, -0.46796511,
-0.46796511, -0.46796511, -0.46796511, -0.46796511, -0.15546511, -0.15546511])'''根据 F1 计算残差
residual1 = y - 1/(1 + np.exp(-F1))
residual1 '''array([-0.38509799, -0.38509799, -0.38509799, 0.61490201,
0.61490201, -0.38509799, -0.38509799, -0.38509799, 0.53878818, 0.53878818])'''根据新的残差residual1的mse,计算最佳分裂条件
lower_mse = ((residual1 - residual1.mean())**2).mean()
best_split = {}
# 分裂标准 mse
for i in range(0,10):
if i == 9:
mse = ((residual1 - residual1.mean())**2).mean()
else:
left_mse = ((residual1[:i+1] - residual1[:i+1].mean())**2).mean()
right_mse = ((residual1[i+1:] - residual1[i+1:].mean())**2).mean()
mse = left_mse*(i+1)/10 + right_mse*(10-i-1)/10
if lower_mse > mse:
lower_mse = mse
best_split.clear()
best_split['X[0] <= '] = X[i:i + 2].mean()
print('从第%d个进行分裂'%(i + 1),np.round(mse,4))
# 从第八个样本这里进行分类,最优的选择,和算法第一颗画图的结果一致
print('最小的mse是:',lower_mse)
print('最佳裂分条件是:',best_split)现在我们知道了,第二棵树分裂条件是:X[0] <= 8.5 !然后计算决策树叶节点预测值(相当于负梯度),其中的 就是残差residual1
3.2.7、拟合第三棵树
第二棵树的负梯度
# 第二棵树预测值
gamma = np.array([gamma1]*8 + [gamma2]*2)
gamma梯度提升
# F(x) 随着梯度提升树,提升,发生变化
learning_rate = 0.1
F2 = F1 + gamma*learning_rate
F2根据 F2 计算残差
residual2 = y - 1/(1 + np.exp(-F2))
residual2根据新的残差residual2的 mse,计算最佳分裂条件
lower_mse = ((residual2 - residual2.mean())**2).mean()
best_split = {}
# 分裂标准 mse
for i in range(0,10):
if i == 9:
mse = ((residual2 - residual2.mean())**2).mean()
else:
left_mse = ((residual2[:i+1] - residual2[:i+1].mean())**2).mean()
right_mse = ((residual2[i+1:] - residual2[i+1:].mean())**2).mean()
mse = left_mse*(i+1)/10 + right_mse*(10-i-1)/10
if lower_mse > mse:
lower_mse = mse
best_split.clear()
best_split['X[0] <= '] = X[i:i + 2].mean()
print('从第%d个进行分裂'%(i + 1),np.round(mse,4))
# 从第八个样本这里进行分类,最优的选择,和算法第一颗画图的结果一致
print('最小的mse是:',lower_mse)
print('最佳裂分条件是:',best_split)现在我们知道了,第三棵树分裂条件是:X[0] <= 3.5!然后计算决策树叶节点预测值(相当于负梯度),其中的 就是残差residual2
# 计算第三颗树的预测值
# 前三个是一类
# 后七个是一类
# 左边分支
gamma1 = residual2[:3].sum()/((y[:3] - residual2[:3])*(1 - y[:3] +
residual2[:3])).sum()
print('第三棵树左边决策树分支,预测值:',gamma1)
# 右边分支
gamma2 =residual2[3:].sum()/((y[3:] - residual2[3:])*(1 - y[3:] +
residual2[3:])).sum()
print('第三棵树右边决策树分支,预测值:',gamma2)3.2.8、预测概率计算
计算第三棵树的F3(x)
# 第三棵树预测值
gamma = np.array([gamma1]*3 + [gamma2]*7)
# F(x) 随着梯度提升树,提升,发生变化
learning_rate = 0.1
F3 = F2 + gamma*learning_rate概率公式如下:
proba = 1/(1 + np.exp(-F3))
# 类别:0,1,如果这个概率大于等于0.5类别1,小于0.5类别0
display(proba)
# 进行转换,类别0,1的概率都展示
np.column_stack([1- proba,proba])
# 算法预测概率
clf.predict_proba(X)结论:
-
手动计算的概率和算法预测的概率完全一样!
-
GBDT分类树,计算过程原理如上
4、GBDT分类树原理推导
4.1、损失函数:
-
定义交叉熵为函数
其中 ,即sigmoid函数
表示决策回归树 DecisionTreeRegressor F(x) 表示每一轮决策树的value,即负梯度
4.2、损失函数化简
-
损失函数化简:
-
-
化简过程
4.3、损失函数求导
将F(x)看成整体变量,进行求导
一阶导数:
4.4、初始值  计算
计算
4.4.1、初始值方程构建
之前的GBDT回归树,初始值是多少:平均值
现在的GBDT分类树 ,计算初始值 ,令
5、GBDT二分类步骤总结
Step - 1:
Step - 2:for i in range(M):
a.
b. 根据残差 ,寻找最小 mse 裂分条件
c.
d.









![P1217 [USACO1.5]回文质数 Prime Palindromes](https://img-blog.csdnimg.cn/e6c728c311434e828beedce19afb4d17.png)