文章目录
- 1.ClickHouse介绍
- 2.StarRocks介绍
1.ClickHouse介绍
ClickHouse是面向联机分析处理(OLAP)的开源分析引擎。最初由俄罗斯第一搜索引擎Yandex开发,于2016年开源,开发语言为C++。由于其优良的查询性能,PB级的数据规模,简单的架构,在国内外公司被广泛采用。
它是列存数据库,具有完备的DBMS功能,备份列式存储和数据压缩。它的MPP架构易于扩展,易于维护。除此之外,它支持向量化的查询,完善的SQL以及实时的数据更新,查询速度可以达到亚秒级的响应。
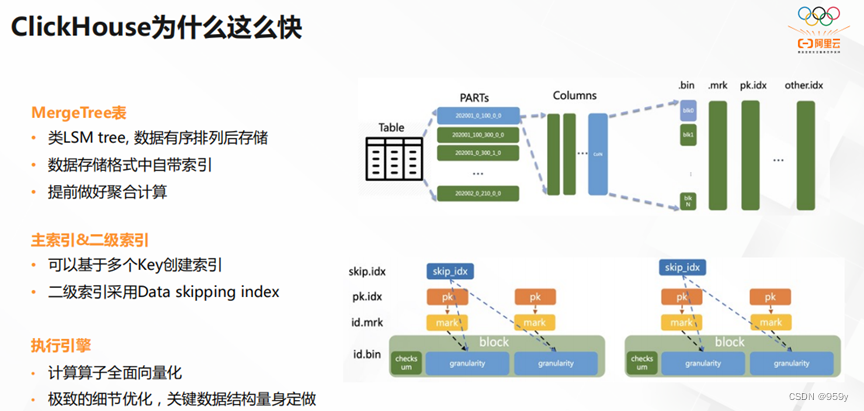
那么ClickHouse的查询速度为什么会这么快呢?它类似于LSM tree,所有数据都是经过有序排列,提前做好聚合计算,再存储。并且它的数据存储格式自带索引。
其次,ClickHouse可以基于多个Key创建索引。它的二级索引采用Data skipping index。
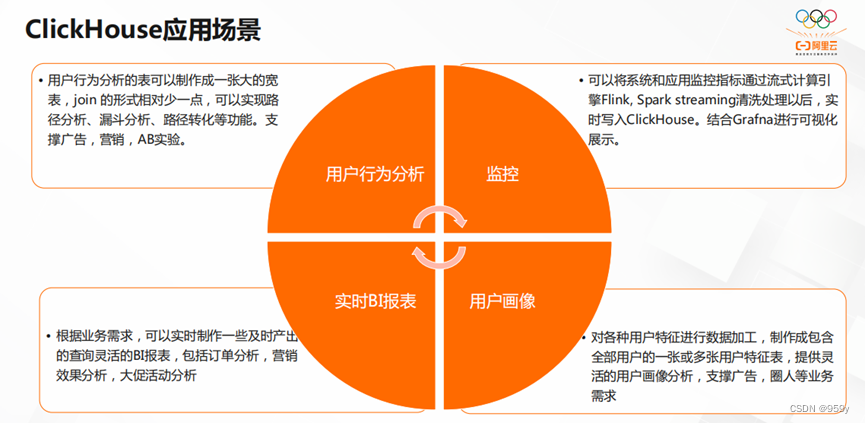
ClickHouse的应用场景主要有四个方面。
第一,用户行为分析。ClickHouse将用户行为分析表制作成一张大的宽表,减少join的形式,实现路径分析、漏斗分析、路径转化等功能。除此之外,它还能支撑广告,营销和AB实验。
第二,实时BI报表。ClickHouse可以根据业务需求,实时制作及时产出,查询灵活的BI报表,包括订单分析,营销效果分析,大促活动分析等等。
第三,监控。ClickHouse可以将系统和应用监控指标通过流式计算引擎Flink,Spark streaming清洗处理以后,实时写入ClickHouse。结合Grafna进行可视化展示。
第四,用户画像。ClickHouse可以对各种用户特征进行数据加工,制作成包含全部用户的一张或多张用户特征表,提供灵活的用户画像分析,支撑广告,圈人等业务需求等等。
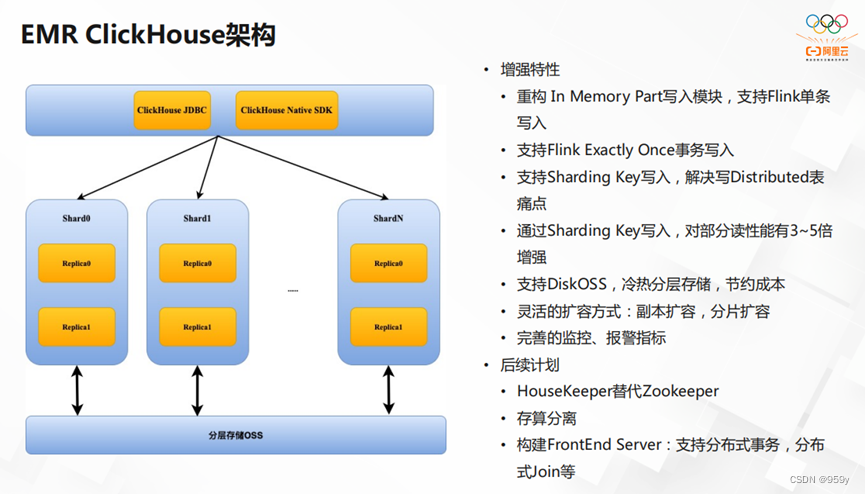
我们在ClickHouse的基础上做了一定的增强。首先,我们重构了In Memory Part写入模块,让它支持Flink单条写入,Flink Exactly Once事务写入以及Sharding Key写入。成功解决了写Distributed表的痛点,提升了整体性能。其次,它还支持DiskOSS。实现了冷热的分层存储,节约了成本。最后,我们实现了副本扩容和分片扩容,让扩容方式变得更灵活。
2.StarRocks介绍

StarRocks单节点100M/秒的写入速度,让它每秒可处理100亿行数据。StarRocks的综合查询速度比其他产品快10到100倍。数据秒级实时更新可见。其次,StarRocks支持数千用户同时分析,部分场景每秒可支持1万以上的QPS,TP99控制在1秒以内。最后,StarRocks基于多种数据模型,实现了极速分析,缩短业务交付时间。提升了数据工程师和分析师工作效率。
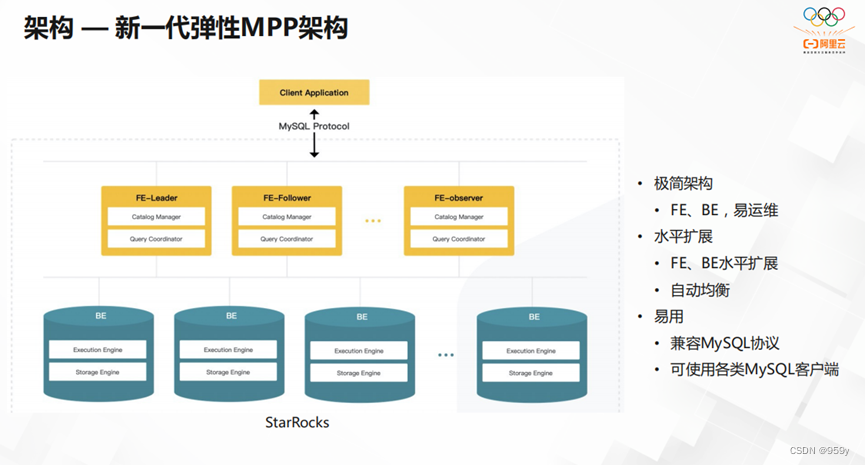
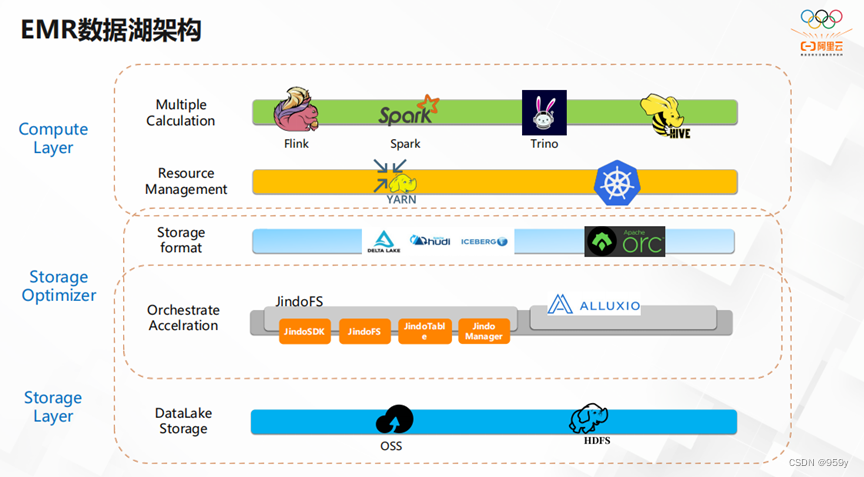
如上图所示,StarRocks的架构简洁明了,兼容MySQL协议,可使用各类MySQL客户端。并且支持FE、BE的水平扩展,从而实现自动均衡。让运维和使用都非常方便。
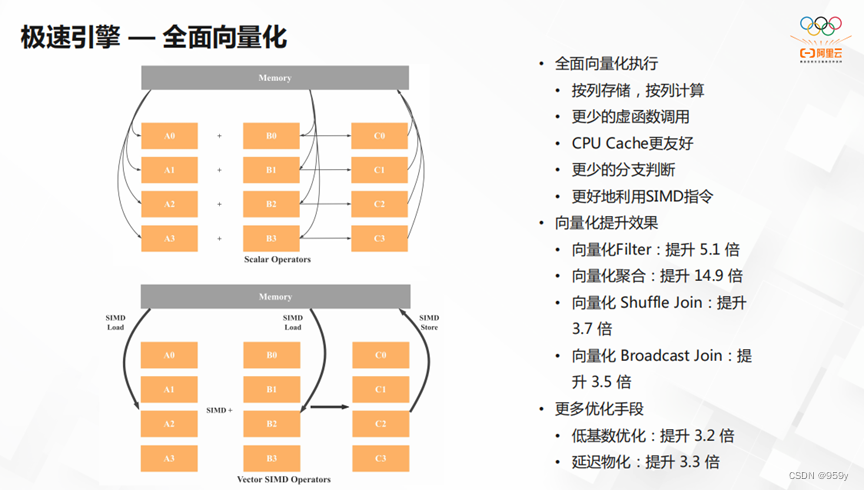
StarRocks的极速引擎,实现了全面向量化执行。它可以按列存储,按列计算。用更少的虚函数调用,更少的分支判断,更好地利用SIMD指令并且对CPU Cache更友好。其次,StarRocks向量化提升的效果明显。向量化Filter,向量化聚合和向量化Shuffle Join的效果都有几何倍数的提升。
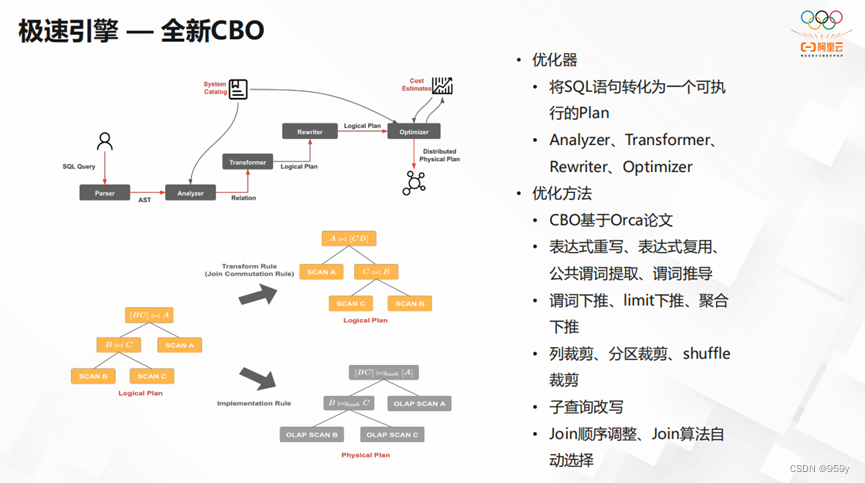
StarRocks的极速引擎,具有全新的CBO。基于Orca论文,将表达式重写、表达式复用。用公共谓词提取、谓词推导。将子查询改写,调整Join顺序、让Join算法自动选择。成功的将SQL语句转化为一个可执行Plan。
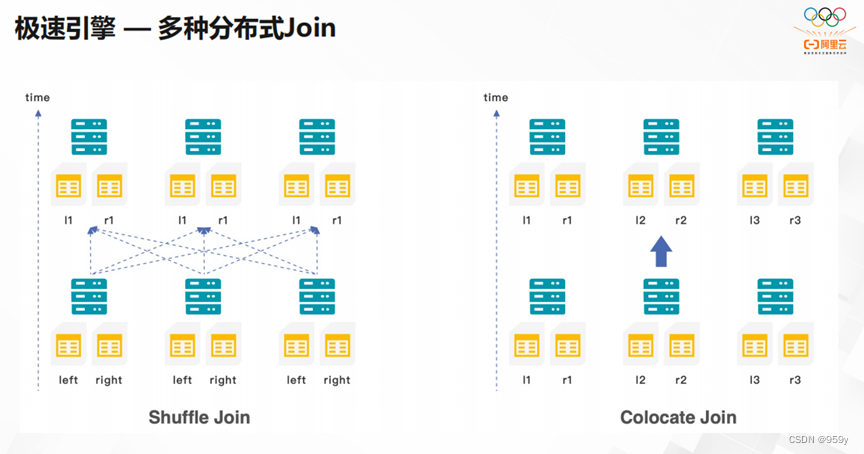
StarRocks的极速引擎,具有多种分布式的Join。目前,这种分布式Join是ClickHouse比较缺乏的功能。右图是更加高效的Join方式,它通过提前完成bucket分类,让整体运行更加高效。

StarRocks为全场景提供了四种数据模型。
第一,明细模型。用于保存和分析原始明细数据,数据写入后几乎无更新。主要用于日志,操作记录,设备状态采样等等。
第二,聚合模型。用于保存,分析,汇总数据。不需要查询明细数据。数据导入后实时完成聚合,数据写入后几乎无更新。适用于按时间、地域、机构汇总的数据。
第三,主键模型。支持基于主键的更新,Delete and insert,大批量导入时保证高性能查询。用于保存和分析需要更新的数据。
第四,更新模型。支持基于主键的更新,Merge On Read,更新频率比主键模型更高。用于保存和分析需要更新的数据。主键模型和更新模型都适用于状态会发生变动的订单,设备状态等。
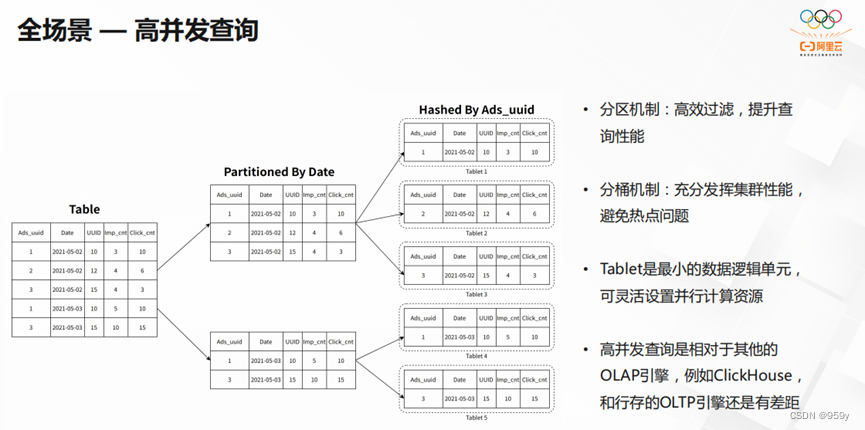
StarRocks在全场景中,还实现了高并发的查询。StarRocks的分区机制可以高效过滤,提升查询性能。StarRocks的分桶机制充分发挥了集群的性能,成功避免了热点问题。但StarRocks相对于其他的OLAP引擎和行存的OLTP引擎还有一定的差距。

在LakeHouse场景中,StarRocks的联合查询,不但屏蔽了底层数据源的细节,而且可以对异构数据据源数据联合分析,与增量数据湖格式完美结合。为了提升查询速度,StarRocks对每种数据源,进行针对性优化。增强了向量化解析ORC、Parquet格式,字典过滤,延迟物化等能力。
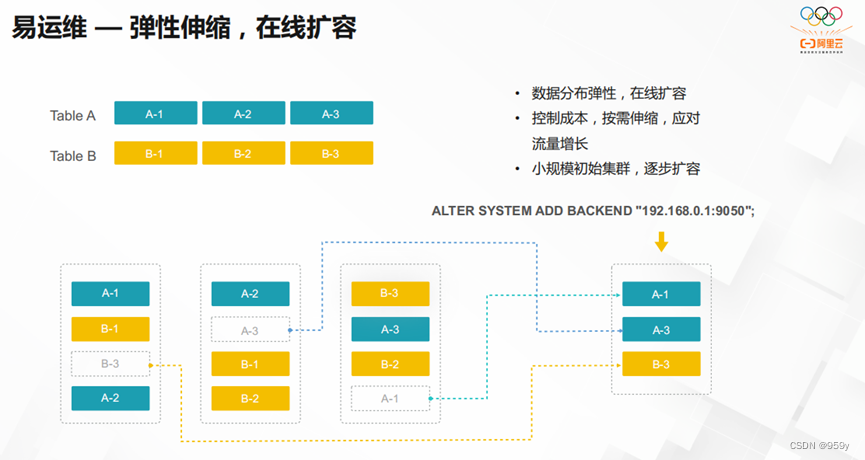
StarRocks除了极致的引擎性能和全场景优化的能力,它还实现了弹性伸缩,支持在线扩容,让运维变得简单。面对流量增长,用户不但可以按需伸缩,节省成本。StarRocks还支持小规模初始集群的逐步扩容,大大节省了运维成本。









![[Vivado那些事儿]将自定义 IP (HDL)添加到 Vivado 模块设计(Block Design)](https://img-blog.csdnimg.cn/img_convert/3d5903d64f515403586b11db28e93c63.png)