文章目录
- 一、概述
- 1.1 图的结构
- 1.2 特征处理
- 1.3 学习任务
- 1.3.1 节点分类
- 1.3.2 链接预测
- 1.3.3 图级任务
- 二、传统方法
- 三、统计特征与核方法
- 3.1 节点层面
- 3.2 连接层面
- 3.3 图层面
- 3.4 节点袋
- 参考文献
Datawhale开源学习社区 x 同济子豪兄 Stanford课程中文精讲系列笔记
本文同时发布在:本人博客 https://wumorfr.github.io/
一、概述
图是一种常见的数据结构,是节点的集合以及这些节点之间关系的集合。图的强大之处在于关注节点之间的关系以及通用性,比如相同的图结构可以表示社交网络,也可以表示分子内原子的关系。当前语音与图像数据往往呈现一个Euclidean Structure(欧氏结构)的数据相关,而分子结构,社交网络,3D图像等往往呈现非欧氏结构,而研究非欧氏结构的一种方法就是图。机器学习不是分析图数据的唯一方法,但是在随着图数据规模和复杂性的增加,机器学习在图数据上的建模和分析起着越来越重要的作用。
1.1 图的结构
图( G r a p h Graph Graph): G = ( V , E ) G = (V,\ E) G=(V, E)
点( V e r t i c e s Vertices Vertices): V = { v 1 , v 2 , . . . , v n } , n = 6 V= \{ v_1,v_2,...,v_n\},n=6 V={v1,v2,...,vn},n=6
边( E d g e Edge Edge): E = { e 1 , 2 , e 1 , 5 , . . . , e 4 , 6 , e 2 , 1 , e 5 , 1 , . . . , e 6 , 4 } E=\{e_{1,2},e_{1,5},...,e_{4,6},\ e_{2,1},e_{5,1},...,e_{6,4}\} E={e1,2,e1,5,...,e4,6, e2,1,e5,1,...,e6,4}
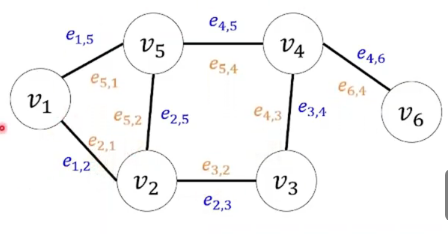
=>邻接矩阵( A d j a c e n c y M a t r i x Adjacency\ Matrix Adjacency Matrix)
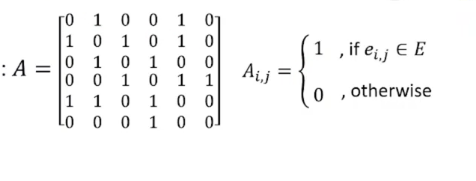
=>节点特征向量( F e a t u r e V e c t o r o f N o d e s Feature\ Vector\ of\ Nodes Feature Vector of Nodes): x = [ x 1 , x 2 , . . . , x 6 ] T , x i ∈ R x=[x_1,x_2,...,x_6]^T,x_i\in R x=[x1,x2,...,x6]T,xi∈R
1.2 特征处理
为了利用传统机器学习执行图上的计算任务,需要找到节点的表示形式。实现此目标的方法主要包含两种:特征工程和特征学习。特征工程需要手动设计特征,而特征学习可以自动学习节点的特征。手动的设计特征需要大量人力并且对于下游任务不一定就是最理想的,而特征学习可以由下游任务指导,学到可能适合下游任务的特征,获取更好的性能。
大多数情况下,谈到的信息指的是节点层面的信息,如节点的属性信息,在极少数形况下,边会带有实值特征,更少数的情况是把实值特征和整张图关联起来得到图的特征信息。
-
图特征选择(移除节点上无关和冗余的特征)
特征选择旨在自动选择一小部分特征,具有最小的冗余度但于学习目标最相关。传统特征选择假定数据实例是独立同分布的,然而,许多应用中的数据样本是嵌入在图上的,本质上不是独立同分布的。
-
图表示学习(生成一组新的节点特征)
图表示学习的目的是生成新的节点特征,已经在谱聚类,基于图的降维,矩阵分解的背景下进行了研究。在谱聚类中,数据点作为图中的节点,然后聚类问题转化为将图划分为节点社区。谱聚类的关键是谱嵌入,旨在将节点嵌入到低维空间中,在该空间中使用传统聚类算法。基于图的降维技术可以直接用于学习节点表示。基于数据样本的原始特征,使用预定义的距离函数构建相似度图,通过保留相似度图得结构信息学习节点表示。矩阵是表示图的最流行的方法,矩阵分解目的是将节点嵌入到低维空间中,在该空间中利用新的节点表示重构邻接矩阵。图嵌入方法一般归为矩阵分解方法。
前文提到的方法都是基于浅层模型,随着深度学习的发展图神经网络受到了大家的关注。图神经网络大致分为基于空间的方法和谱方法。空间方法显式利用图结构,通过空间上的邻居节点信息来学习;谱方法利用图的谱视图,通过图的傅里叶变换和逆变换来学习节点表示。
1.3 学习任务
1.3.1 节点分类
在现实场景中,节点常与有用的信息相关联,这些信息被视作标签,用于描述节点的特征。但是很难为所有节点获得完整的标签集,只有一部分节点有标签,而那些无标签的节点需要通过预测来得到,这就是节点分类任务。
用 G = ( V , E ) G=(V,E) G=(V,E)表示一个图, V V V为节点集, E E E为边集。节点集 V V V中那些有标签的节点构成的子集记为Vl。节点分类的目标是利用图G(所有节点)和Vl的标签信息学习一个映射来预测无标签节点的标签。
节点分类任务和标准的监督学习最重要的差别在于图中的节点不满足独立同分布假设。传统的监督学习要求每个样本与其他样本是独立的,否则建模时需要考虑样本之间的依赖关系。并且还需要样本分布相同,否则难以保证模型对新数据点适用。研究者根据节点分类任务的特点将其归为半监督学习,因为在训练过程中,图中的全部节点都被用到了,包括未标记的节点。但是标准的半监督学习也是以独立同分布为前提的,所以,图机器学习任务不是标准的机器学习任务。
1.3.2 链接预测
在许多数据中,图并不是完整的,会缺失一些节点之间的连接,可能是因为未被观察或者图的自然演变。用G=(V,E)表示一个图,V为节点集,E为边集,M是所有可能的节点对。边的补集定义为H=M/E。链接预测的目的为H中每个边赋值,表示这条边出现的可能性。
1.3.3 图级任务
图级别的任务包括图分类,图匹配,图生成,图回归,图聚类,社区发现等等。
图分类是为每个图预测一个标签,而节点分类是为每个节点预测一个标签。给定一组带标签的图数据集D={(Gi, yi)},其中yi是图Gi的标签,图分类任务的目的是学到一个映射预测未标记的图的标签。
图聚类任务的目标是学习一个无监督的方法测量图与图之间的相似性。该任务的挑战是在考虑每张图内部结构关系的前提下定义有效特征。
社区发现常被类比为图领域的无监督学习中的聚类任务,通过输入一张图,推断潜在的社区结构
二、传统方法
图表示学习之前已经有很多优秀的方法被提出。比如,在节点分类或图分类中用到的图的统计特征,核方法等;在关联预测时使用节点邻域重叠测量等方法。
传统的使用图数据进行分类的方法遵循标准的机器学习范式。首先,基于启发式函数或邻域知识提取一些统计特征,然后,将其作为标准机器学习分类器的输入。
三、统计特征与核方法
3.1 节点层面
节点层面的统计特征通常包括节点的度,节点中心性,聚类系数,motifs等。其中节点的度和中心性是从单个节点的连接关系来区分节点的;聚类系数从结构的角度,衡量在一个节点的局部邻域中闭合三角形的比例。它度量了节点的邻居节点聚类的紧密程度(邻居节点之间相互连接的程度)。
常见计算聚类系数局部变量的方法如下,
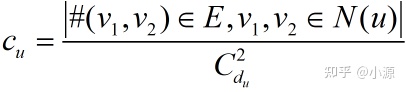
其中,分子表示节点u的邻居节点之间的边的数量,分母表示节点u的所有邻居节点彼此连接产生的边的数目,du是节点u的度。
整体聚类系数是一个图中所有闭三点组的数量与所有连通三点组(三个点封闭或者不闭)的数量的比值。处了统计三角形之外,还可以统计节点的ego-network中任意的motifs或者Graphlets的数量或者计算各种motifs在节点的ego-network中出现的频率来刻画节点特征。本质上来讲,通过审查节点的ego-network,可以将计算节点层面统计特征的任务转化为图层面的任务。
节点层面实现任务:
1.半监督学习任务

如图所示案例,任务是预测灰点属于红点还是绿点。区分特征是度数(红点度数是1,绿点度数是2)
2.特征抽取目标:找到能够描述节点在网络中结构与位置的特征(连接数,节点的重要度,节点的抱团程度,自己定义的子图)

3.度数 n o d e d e g r e e node\ degree node degree:通过以连接数目为关键,认为连接数目越多的节点越重要。缺点使认为节点所有邻居是同等重要的。
如下图:如果只考虑数量而不考虑数量,则A和C的特征相同,但是两者的重要程度或者说影响能力则完全不同
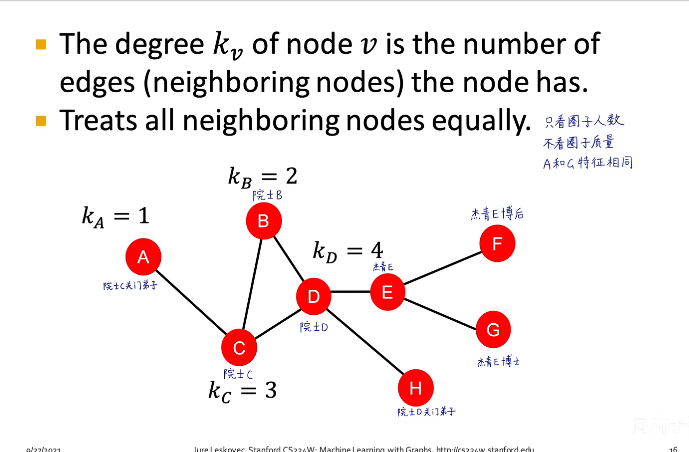
对node degree的计算,将adjacency Matrix 与column Vector 相乘,相当于计算每一行的大小

例如下图,通过对上海地铁的数据绘制的Node degree的图像,我们可以看出上海的几个地铁交通枢纽。

4. n o d e c e n t r a l i t y c v node\ centrality\ c_v node centrality cv考虑了节点的重要性
-
eigenvector centrality:认为如果节点邻居重要,那么节点本身也重要
因此节点 v v v 的centrality是邻居centrality的加总: c v = 1 λ ∑ u ∈ N ( v ) c u c_v=\frac{1}{\lambda}\sum\limits_{u\in N(v)}c_u cv=λ1u∈N(v)∑cu
( λ \lambda λ是某个正的常数,可以看成归一化系数)
这是个递归式,解法是将其转换为矩阵形式: λ c = A c A \lambda \mathbf{c}=\mathbf{Ac}\ \mathbf{A} λc=Ac A是邻接矩阵, c \mathbf{c} c是 c e n t r a l t y centralty centralty向量。
从而发现 c e n t r a l i t y centrality centrality就是特征向量。根据 P e r r o n − F r o b e n i u s T h e o r e m 2 Perron-Frobenius\ Theorem^2 Perron−Frobenius Theorem2可知最大的特征值 $ \lambda_{max}$ 总为正且唯一,对应的leading eigenvector c m a x \mathbf{c}_{max} cmax就是centrality向量。上海地铁站的 Eigenvector Centrality

-
betweenness centrality:认为如果一个节点处在很多节点对的最短路径上,那么这个节点是重要的。(衡量一个节点作为bridge或transit hub的能力。)
c v = ∑ s ≠ v ≠ t # ( s 和 t 之间包含 v 的最短路径 ) # ( s 和 t 之间的最短路径 ) c_v=\sum\limits_{s\neq v \neq t}\frac{\#(s和t之间包含v的最短路径)}{\#(s和t之间的最短路径)} cv=s=v=t∑#(s和t之间的最短路径)#(s和t之间包含v的最短路径)
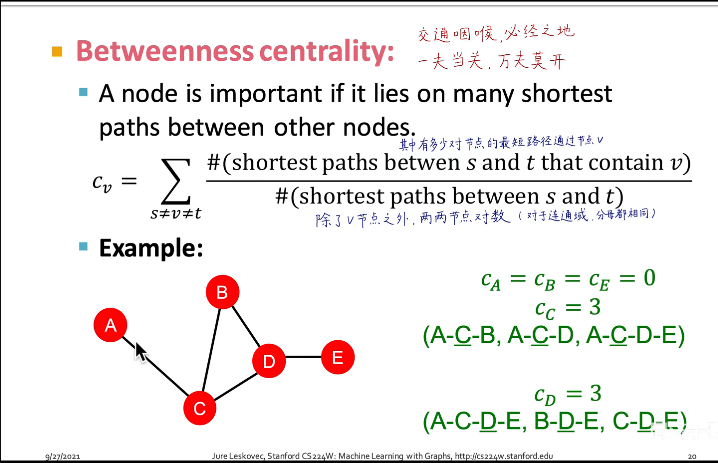
上海地铁站的 betweenness centrality

-
closeness centrality:(去哪都近)认为如果一个节点距其他节点之间距离最短,那么认为这个节点是重要的

上海地铁站的 closeness centrality

-
clustering coefficient3:(集群系数(有多抱团))衡量节点邻居的连接程度,描述节点的局部结构信息
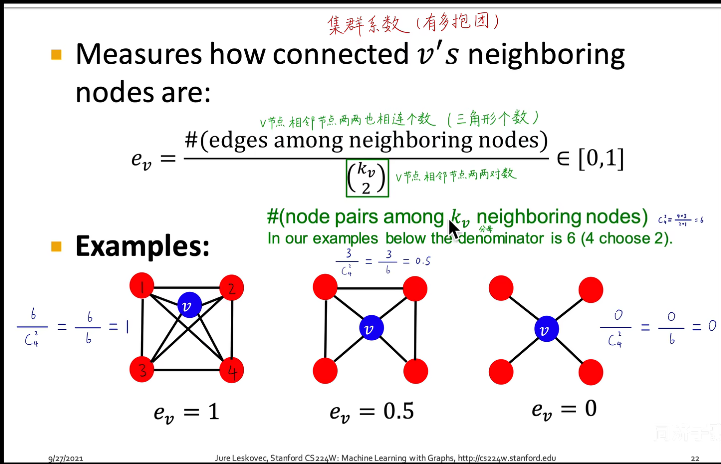
这种
( k v 2 ) \bigl(\begin{smallmatrix} k_v\\2\end{smallmatrix}\bigr) (kv2)是组合数的写法,和国内常用的C写法上下是相反的4
所以这个式子代表 v v v 邻居所构成的节点对,即潜在的连接数。整个公式衡量节点邻居的连接有多紧密第1个例子: e v = 6 / 6 e_v=6/6 ev=6/6
第2个例子:$ e_v=3/6$
第3个例子:$e_v=0/6 $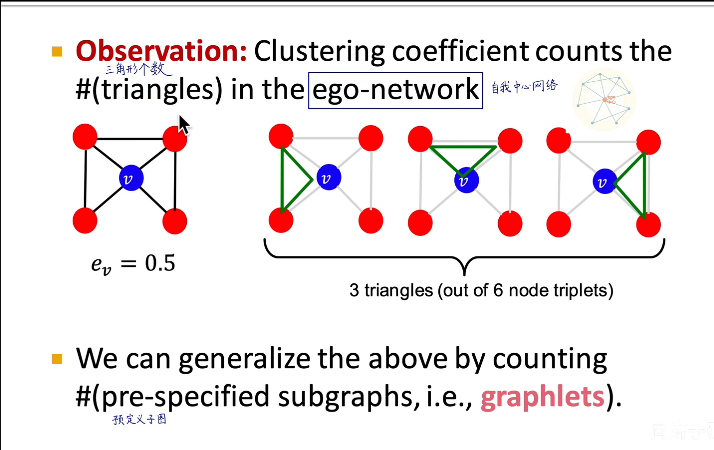
ego-network of a given node is simply a network that is induced by the node itself and its neighbors5. So it’s basically degree 1 neighborhood network around a given node.
这种三角形:How manys triples are connected
在社交网络之中会有很多这种三角形,因为可以想象你的朋友可能会经由你的介绍而认识,从而构建出一个这样的三角形/三元组。上海地铁站的 clustering coefficient

这种三角形可以拓展到某些预定义的子图pre-specified subgraph6上,例如如下所示的graphlet
-
graphlets有根连通异构子图

对于某一给定节点数 k k k ,会有 n k n_k nk 个连通的异构子图。
就是说,这些图首先是connected的6,其次这些图有k个节点,第三它们异构。
异构,就是说它们形状不一样,就是怎么翻都不一样……就,高中化学应该讲过这个概念,我也不太会解释,反正就是这么一回事:举例来说,3个节点产生的全连接异构子图只有如图所示的2个,4个点就只有6个。如果你再构建出新的子图形状,那么它一定跟其中某个子图是同构的。
图中标的数字代表根节点可选的位置。例如对于 G 0 G_0 G0 ,两个节点是等价的(类似同分异构体),所以只有一种graphlet;对于 G 1 G_1 G1,根节点有在中间和在边上两种选择,上下两个边上的点是等价的,所以只有两种graphlet。其他的类似。节点数为2-5情况下一共能产生如图所示73种graphlet。7
这73个graphlet的核心概念就是不同的形状,不同的位置。
注意这里的graphlet概念和后文图的graphlet kernel的概念不太一样。具体的后文再讲-
Graphlet Degree Vector (GDV): Graphlet-base features for nodes
GDV与其他两种描述节点结构的特征的区别: -
Degree counts #(edges) that a node touches
-
Clustering coefficient counts #(triangles) that a node touches.
-
GDV counts #(graphlets) that a node touches
-
Graphlet Degree Vector (GDV): A count vector of graphslets rooted at a given node.

如图所示,对四种graphlet,v vv 的每一种graphlet的数量作为向量的一个元素。
注意:graphlet c的情况不存在,是因为像graphlet b那样中间那条线连上了。这是因为graphlet是induced subgraph5,所以那个边也存在,所以c情况不存在。
考虑2-5个节点的graphlets,我们得到一个长度为73个坐标coordinate(就前图所示一共73种graphlet)的向量GDV,描述该点的局部拓扑结构topology of node’s neighborhood,可以捕获距离为4 hops的互联性interconnectivities。
相比节点度数或clustering coefficient,GDV能够描述两个节点之间更详细的节点局部拓扑结构相似性local topological similarity。
-
-
Node Level Feature: Summary
这些特征可以分为两类:
-
Importance-based features: 捕获节点在图中的重要性

-
Structure-based features: 捕获节点附近的拓扑属性

Discussion

大致来说,传统节点特征只能识别出结构上的相似,不能识别出图上空间、距离上的相似,即节点分析只强调了节点的属性(连接数,数据,重要程度等)。
-
3.2 连接层面
-
预测任务是基于已知的边,预测新链接的出现。测试模型时,将每一对无链接的点对进行排序,取存在链接概率最高的K个点对,作为预测结果。
-
特征在点对上
-
有时你也可以直接将两个点的特征合并concatenate起来作为点对的特征,来训练模型。但这样做的缺点就在于失去了点之间关系的信息。
-
链接预测任务的两种类型:随机缺失边;随时间演化边

图中的 ’ 念prime
第一种假设可以以蛋白质之间的交互作用举例,缺失的是研究者还没有发现的交互作用。(但这个假设其实有问题,因为研究者不是随机发现新链接的,新链接的发现会受到已发现链接的影响。在网络中有些部分被研究得更彻底,有些部分就几乎没有什么了解,不同部分的发现难度不同)
第二种假设可以以社交网络举例,随着时间流转,人们认识更多朋友。 -
基于相似性进行链接预测:计算两点间的相似性得分(如用共同邻居衡量相似性),然后将点对进行排序,得分最高的n组点对就是预测结果,与真实值作比

-
distance-based feature:两点间最短路径的长度

这种方式的问题在于没有考虑两个点邻居的重合度the degree of neighborhood overlap,如B-H有2个共同邻居,B-E和A-B都只有1个共同邻居。
-
local neighborhood overlap:捕获节点的共同邻居数

common neighbors的问题在于度数高的点对就会有更高的结果,Jaccard’s coefficient是其归一化后的结果。
Adamic-Adar index在实践中表现得好。在社交网络上表现好的原因:有一堆度数低的共同好友比有一堆名人共同好友的得分更高。 -
global neighborhood overlap
local neighborhood overlap的限制在于,如果两个点没有共同邻居,值就为0。
但是这两个点未来仍有可能被连接起来。所以我们使用考虑全图的global neighborhood overlap来解决这一问题。
-
Katz index:计算点对之间所有长度路径的条数
-
计算方式:邻接矩阵求幂
邻接矩阵的k次幂结果,每个元素就是对应点对之间长度为k的路径的条数 -
证明:

显然$ \mathbf{A}_{uv}$ 代表u和v之间长度为1的路径的数量

计算 u u u和 $v $ 之间长度为2的路径数量,就是计算每个 u u u的邻居 A u i \mathbf{A}_{ui} Aui(与 u u u 有1条长度为1的路径)与 v v v 之间长度为1的路径数量 P i v ( 1 ) \mathbf{P}^{(1)}_{iv} Piv(1)即 $ \mathbf{A}_{iv}$的总和 ∑ i A u i ∗ A i v = A u v 2 \sum_i \mathbf{A}_{ui}*\mathbf{A}_{iv}=\mathbf{A}_{uv}^2 ∑iAui∗Aiv=Auv2
同理,更高的幂(更远的距离)就重复过程,继续乘起来
-
从而得到Katz index的计算方式:


discount factor β \beta β 会给比较长的距离以比较小的权重,exponentially with their length.
closed-form闭式解,解析解 8 ^8 8
解析解的推导方法我去查了,见尾注 9 ^9 9
-
-
-
Summary
- Distance-based features: Uses the shortest path length between two nodes but does not capture how neighborhood overlaps.
- Local neighborhood overlap:
- Captures how many neighboring nodes are shared by two nodes.
- Becomes zero when no neighbor nodes are shared.
- Global neighborhood overlap:
- Uses global graph structure to score two nodes.
- Katz index counts #paths of all lengths between two nodes.
3.3 图层面
-
目标:提取出的特征(一个D维向量)反应全图结构特点
-
实现:bag-of-words(BOW):不同特征在图中实现的个数,目的:将一篇文章转换为向量形式,毕竟无法将文章直接输入机器学习模型,但向量可以。

(e.g:图相当于文章,节点相当于单词)
问题:只看节点有没有,不看连接结构

改良:bag-of-node-degrees:不看节点,也不看连接结构,看的是graphlets(个人理解:图像结构)
关键点:统计不同数量的在图中的图像结构

graphlets
基于多个节点之间的通过线段相连的,节点数固定但连接不同的结构
e . g e.g e.g
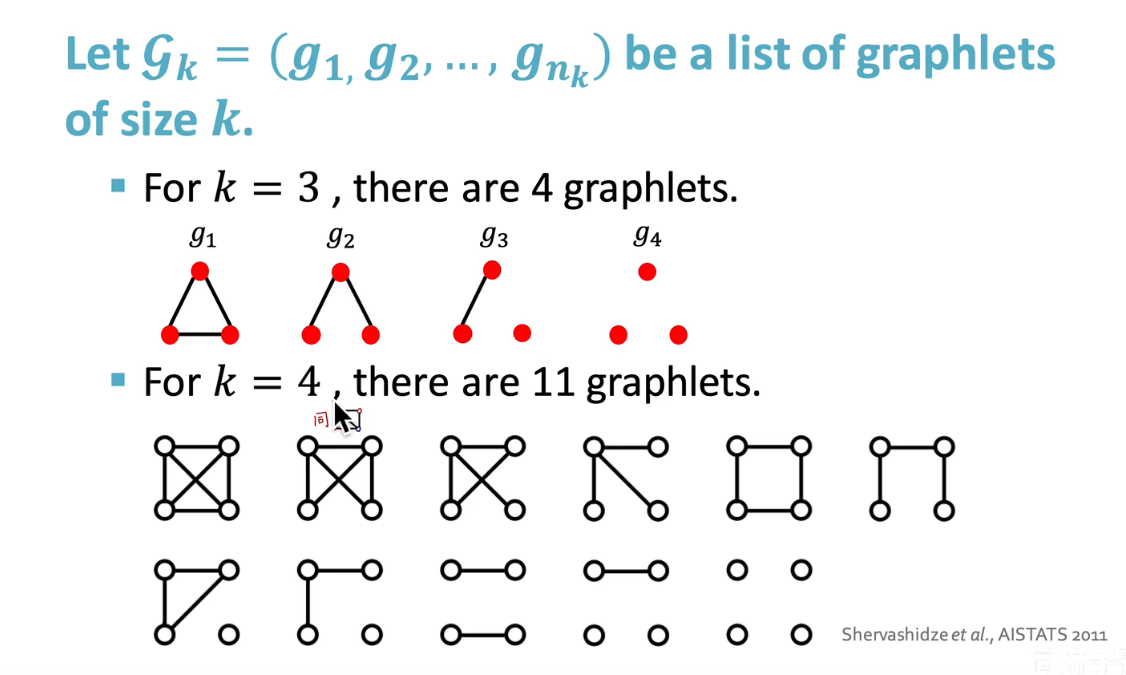
对一个数据处理后样本如图
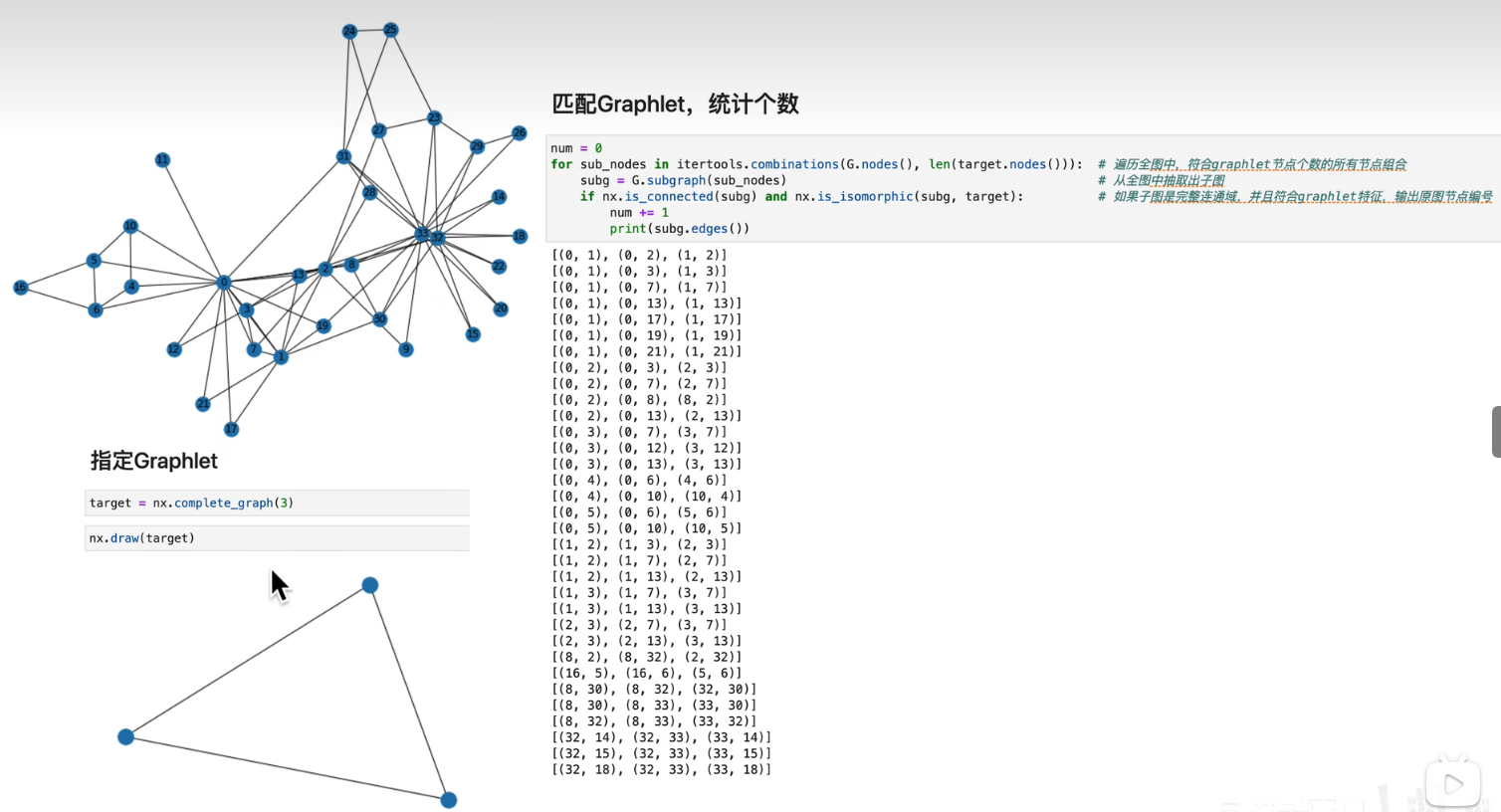
-
与节点层面的不同点:
- 可以存在孤立节点
- 计数全图 g r a p h l e t graphlet graphlet个数,而非特定节点邻域的 g r a p h l e t graphlet graphlet个数
-
Graphlet核
-
定义:通过零个图的Graphlet Count Vector数量积
K ( G , G ‘ ) = f G T f G ‘ K(G,G`)\ =\ f_G^T f_{G`} K(G,G‘) = fGTfG‘
-
如果两个节点的大小不同,则需要进行归一化
h G = f G S u m ( f G ) K ( G , G ‘ ) = h G T h G ‘ h_G= \frac{f_G}{Sum(f_G)} \ K(G,G`)\ =\ h_G^T h_{G`} hG=Sum(fG)fG K(G,G‘) = hGThG‘
-
问题:
- 时间复杂度是一个多项式复杂度,因为需要进行子图匹配,复杂度为 O ( n k ) O(n^k) O(nk), k k k为图的大小
- 计算时会出现NP问题
-
-
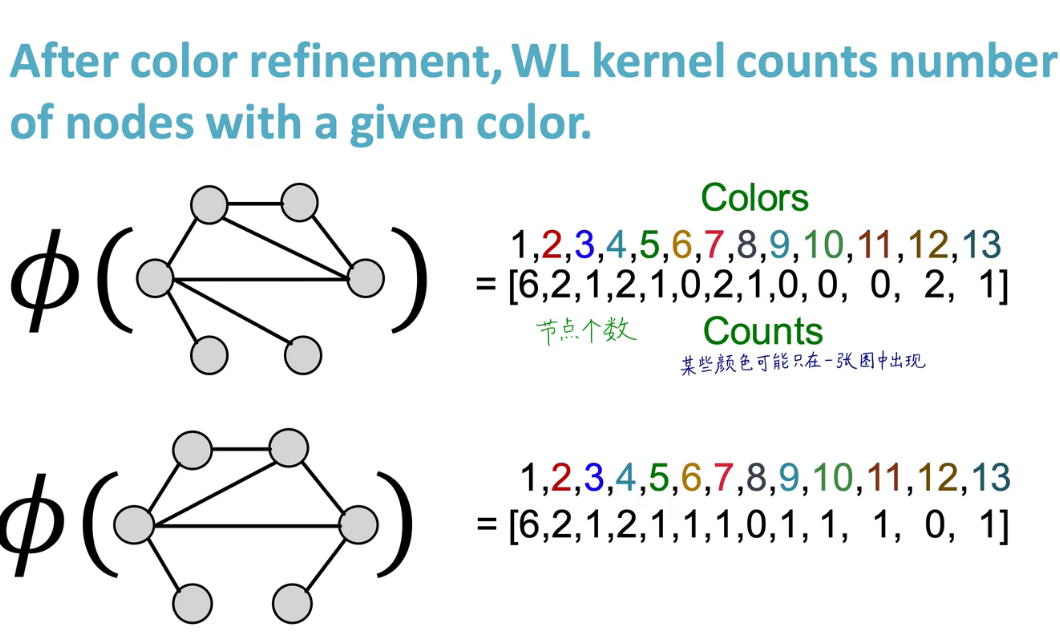
W e i s f e i l e r − L e h m a n Weisfeiler-Lehman Weisfeiler−Lehman核
W-L核是一种迭代邻域聚合的策略,通过提取包含更多信息的节点层面特征来聚合成图层面的表示。W-L算法的基本思想是首先为每个节点分配一个初始标签l0,一般选择节点的度作为标签。
然后,通过散列该节点邻域内当前标签构成的多重集,迭代地给每个节点分配新的标签。迭代K次重标记后每个节点的标签聚合了K-hop邻域结构,用这些标签计算直方图或者其他概要统计来作为图的特征表示。WL算法可以有效的判断图是否同构。

换一种话说, W e i s f e i l e r − L e h m a n Weisfeiler-Lehman Weisfeiler−Lehman核相当于对不同的节点进行赋予不同的颜色
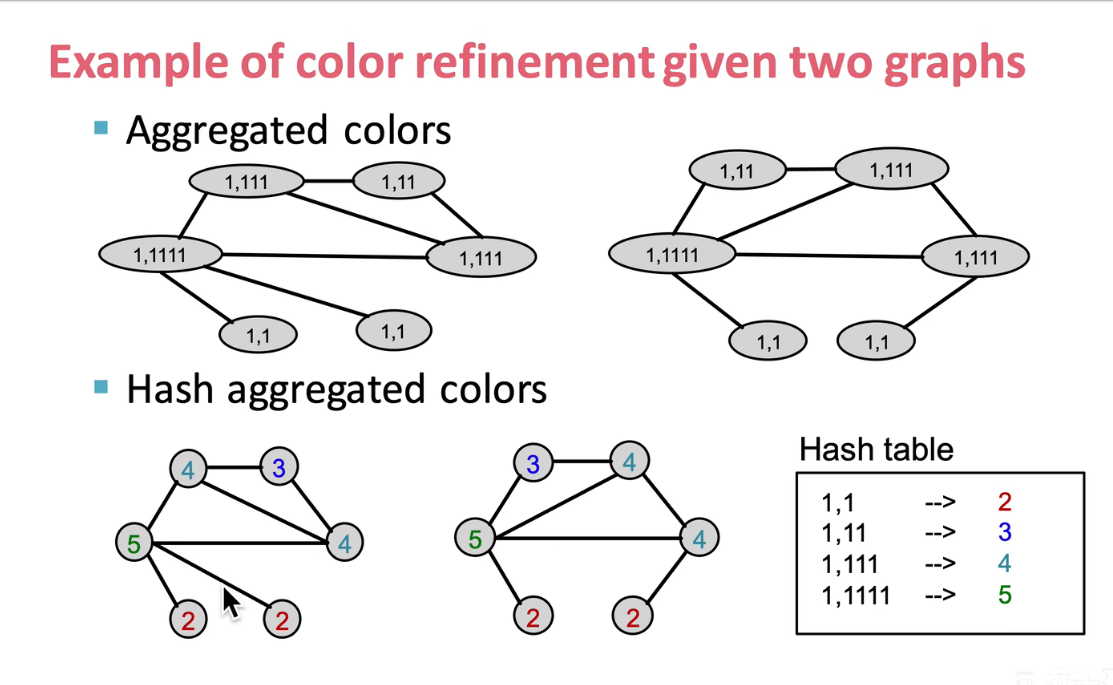
重复上两个流程
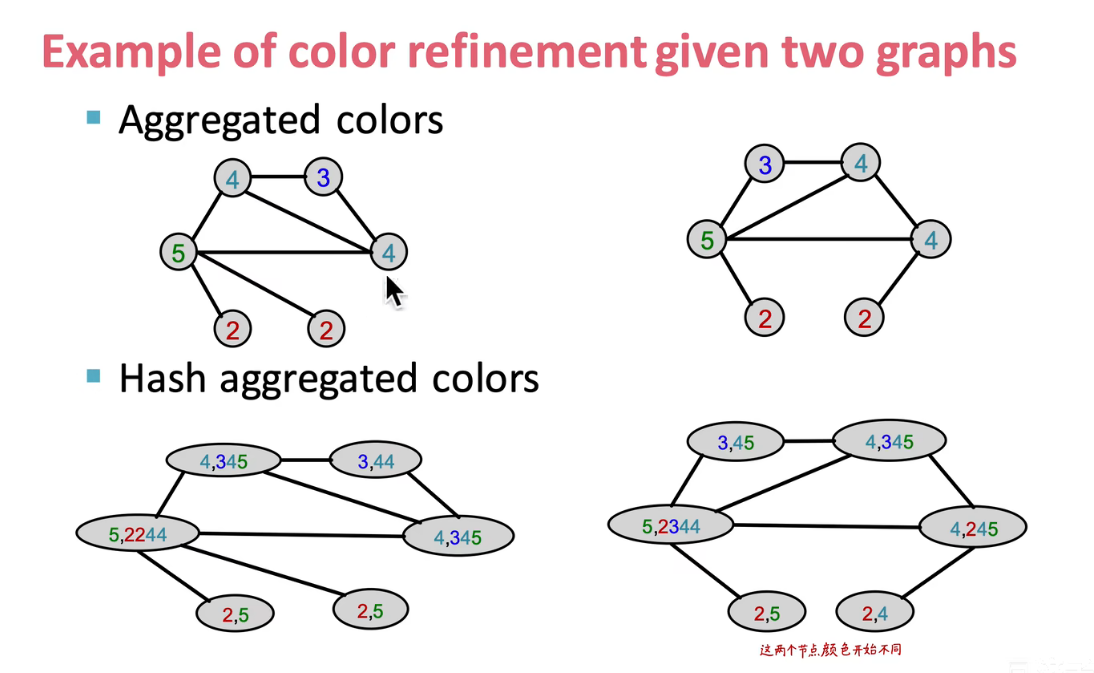

理论上来说上述过程可进行多次,此处只进行两次,后对颜色进行编码。
3.4 节点袋
图层面特征最简单的方式是聚合节点层面的特征,作为图层面的表示。但是这种方法完全基于局部节点信息,可能错失图中重要的整体特性。
参考文献
[1] cs224w(图机器学习)2021冬季课程学习笔记2: Traditional Methods for ML on Graphs
[2] 图机器学习(一)–图数据挖掘传统方法
[3] 斯坦福CS224W图机器学习、图神经网络、知识图谱【同济子豪兄】