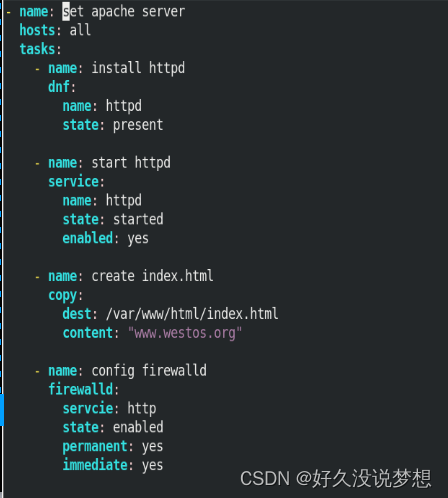
文章目录
- 【半监督医学图像分割 2021 CVPR】CVRL 论文翻译
- 摘要
- 1. 介绍
- 1.1 总览
- 1.2 无监督对比学习
- 2. 实验
- 3. 总结
【半监督医学图像分割 2021 CVPR】CVRL 论文翻译
论文题目:Momentum Contrastive Voxel-wise Representation Learning for Semi-supervised Volumetric Medical Image Segmentation
中文题目:基于动量对比体素表示学习的半监督医学图像分割
论文链接:https://arxiv.org/abs/2105.07059
论文代码:
发表时间:2021年5月
论文团队:耶鲁大学&德克萨斯大学奥斯汀分校
引用:You C, Zhao R, Staib L H, et al. Momentum contrastive voxel-wise representation learning for semi-supervised volumetric medical image segmentation[C]//Medical Image Computing and Computer Assisted Intervention–MICCAI 2022: 25th International Conference, Singapore, September 18–22, 2022, Proceedings, Part IV. Cham: Springer Nature Switzerland, 2022: 639-652.
引用数:50(截止时间 2023年2月13号)
摘要
对比学习(CL)的目的是在医学图像分割的背景下,在不依赖专家注释的情况下学习有用的表示。
现有的方法主要是通过简单地将所有输入特征映射到相同的常数向量中,将单个正向量(即同一图像的增强)与整个批处理剩余部分中的一组负向量进行对比。
尽管这些方法取得了显著的经验效果,但仍存在以下不足:
(1)防止问题崩溃为琐碎的解决方案仍然是一个艰巨的挑战;
(2)由于同一图像中存在着不同的解剖结构,因此并不是同一图像中的所有体素都具有相同的正性。
在这项工作中,我们提出了一种新的对比体素表示学习(CVRL)方法,通过捕捉三维空间上下文和丰富的解剖信息,在特征和批量维度上有效地学习低级和高级特征。
具体来说,我们首先引入了一种新的CL策略,以确保三维表示维之间的特征多样性提升。
我们通过对三维图像的两层对比优化(即低级和高级)来训练框架。
在两个基准数据集和不同标记设置上的实验证明了我们提出的框架的优越性。 更重要的是,我们还证明了我们的方法继承了标准CL方法的硬度感知特性的优点。
1. 介绍
在机器学习领域,利用大量未标记的数据,从少量有标记的例子中学习是一个长期的追求,这对于医学成像领域尤其重要。
在规模上生成可靠的三维成像数据手工注释是昂贵的,耗时的,并且可能需要特定领域的专业知识。
由于隐私问题,医学成像中的另一个挑战是相对较小的训练数据集。
在医学成像领域,由于有限的三维数据和注释,大量的努力[28,13,17,27,2,14,4,1]致力于合并未标记数据以改善网络性能。
最常见的训练技术是对抗学习和一致性损失作为正则化术语来鼓励无监督映射。
近年来,对比学习(CL)在没有专家指导的情况下学习有用的表示方法引起了广泛的关注,并在医学图像分析领域显示出了显著的效果[3,8,26]。 中心思想[6,25,16,5,22,3]是学习对数据扩充不变的强大表示,使来自相同图像的不同扩充的实例嵌入之间的一致性最大化。
随后的工作主要集中在不同配对的选择上,这些配对决定了习得表征的质量。
用于对比的损失函数是从几个选项中选择的,如Infonce[18],Triplet[24],等等。
然而,这些方法虽然显着,但假定负值的排斥效应可以通过在损失函数中显式地使用正负对来避免沿着所有维折叠到平凡解。
然而,经验上观察到,这种设计仍然可能沿着某些尺寸发生坍塌(即尺寸坍塌),如[9,23]中所指出的那样。 这样的场景可能发生在预定义的扩展中,由于实例间的约束,通常会导致更好的性能,而通常忽略转换中解剖学上的可行性。
本文提出了一种新的端到端半监督框架CVRL,用于从批量和特征方向学习高层上下文和局部特征,用于三维医学图像分割。 一个祝福来自最近在图像分类背景下的发现[10]。
作者指出,沿特征维数进行强增强可能会导致CL中的维数崩塌。 换句话说,增强图像不能很好地“标准化”,可能容易接受崩溃的解决方案(例如,为所有3D扫描生成相同的矢量),使其在现实世界的临床实践中具有挑战性甚至不可行。 三个关键方面区别于最近的成功[3]。
首先,标准CL鼓励批处理中的实例级表示多样性。
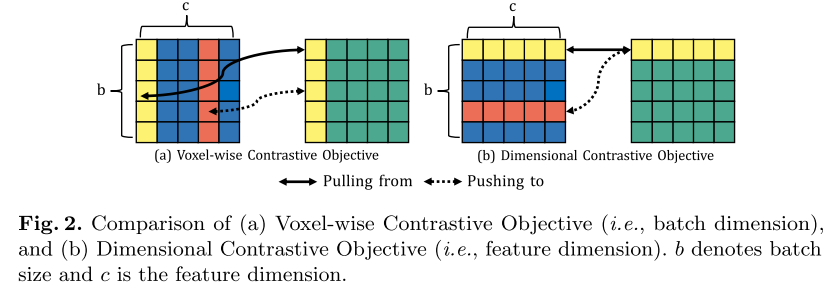
相比之下,我们在特征维度之间提出了一种解剖学信息的正则化,作为实例内约束,以鼓励特征多样性,以提高其鲁棒性,如图2所示。
这种设计很有吸引力:
(1)我们的想法是相当即插即用的,可以很容易地与现有的实例间约束兼容;
(2)继承了CL学习有用表示的优势,提高了特征空间的识别能力(见附录)。 其次,我们提出在一个较低维的3D子空间中进行低层对比度,以捕捉丰富的解剖学信息;
(3)现有的方法主要在图像级空间进行局部对比度,由于缺乏空间信息,通常会导致分割质量不佳。
相反,如果提出的方法能够从3D背景中学习更多的通用表示,它将在医学图像(即3D体积扫描)中打开3D自然的诱人前景。 通过设计一个新的三维投影头对三维特征进行编码,我们提出了一个额外的高层对比度来挖掘嵌入特征空间中的显著特征。 我们也在理论上展示我们的一角钱
1.1 总览
该体系结构的概述如图1所示。 我们的CVRL基于GCL[3],并遵循其最重要的组成部分,如数据增强。
我们的目标是学习更强的视觉表示,避免崩溃,以提高整体分割质量与有限的注释临床场景。
在有限的注释设置中,我们训练半监督CVRL与两个组成部分–监督和无监督学习目标。
具体来说,我们提出了一种新的基于体素的表示学习算法,通过正则化嵌入空间和探索训练体素的几何和空间上下文,从三维未标记数据中学习低级和高级表示。
在我们的问题设置中,我们考虑一组训练数据(三维图像),包括 N N N个标记数据和 M M M个未标记数据,其中 N < < M N<<M N<<M。 为便于说明,我们将有限标号数据表示为 D l = ( x i , y i ) i = 1 N D_l={(x_i,y_i)}^N_{i=1} Dl=(xi,yi)i=1N,将大量未标号数据表示为 D u = ( x i ) i = n + 1 N + M D_u={(x_i)}^{N+M}_{i=n+1} Du=(xi)i=n+1N+M,其中 x i ∈ R h × w × d xi\in R_{h×w×d} xi∈Rh×w×d为体积输入, y i ∈ { 0 , 1 } h × w × d yi\in\{0,1\}_{h×w×d} yi∈{0,1}h×w×d为标注。
具体来说,我们采用V-Net[27]作为网络骨干网F(·),它由一个编码器网络和一个解码器网络组成。
为了最大化潜在表示之间的互信息,我们设计了一个投影头,它包括一个编码网络,该编码网络与现有的编码网络有着相似的结构。
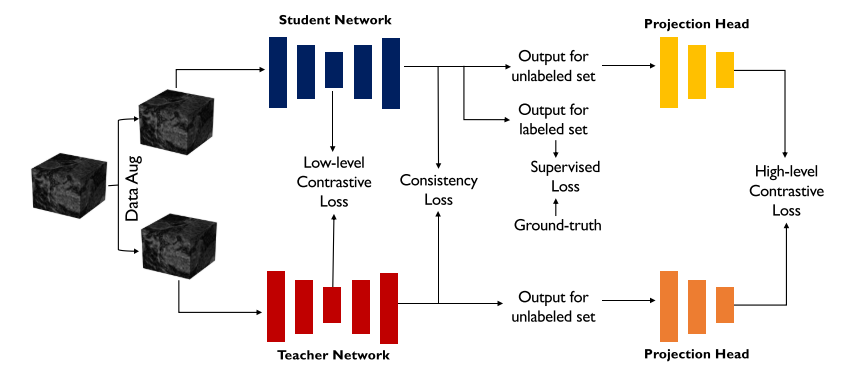
CVRL体系结构概述。 我们通过利用体素和体积区域之间的高层上下文以及批量和特征维的低层相关性,以半监督的方式学习丰富的稠密体素表示。
1.2 无监督对比学习
CVRL的一个关键组成部分是通过对比蒸馏捕捉高维数据丰富的体素表示的能力。
CVRL在批量更新期间作为辅助损失对对比目标进行训练。
我们使用了两个对比学习目标:
(一)体素对比目标(二)维度对比目标,
每一个分别应用于一个低层特征和一个高层特征。
由此产生的组合训练目标大大提高了所学表征的质量。
首先,我们建立一些符号,这将有助于解释我们的方法。
我们表示一批输入图像 x 1 , ⋯ , x b x_1,\cdots,x_b x1,⋯,xb、教师编码器网络 f f f、学生编码器网络 g g g和一组数据增强变换T(例如,随机翻转、随机旋转、随机亮度、随机对比度、随机缩放、立方体重排和立方体旋转)。
这里f和g使用1.1节中介绍的相同编码器体系结构E(·),但参数不同。
z f ∈ R h × w × d × c = f ( t ( x ) ) ) \left.z^{f} \in \mathbb{R}^{h \times w \times d \times c}=f(t(x))\right) zf∈Rh×w×d×c=f(t(x)))是由学生编码器产生的特征量,而ZG=G(t(x))是由教师编码器在不同的随机变换T=T下产生的相应特征量。
利用标准的对比学习,我们鼓励特征提取器产生在数据增加下不变的表示。
另一方面,特征仍然应该保持局部性:特征体中的不同体素应该包含其独特的信息。
具体地说,当学习到的特征体积被分成切片时,我们将来自同一图像的两个增强的体素对拉得更近; 不同位置或来自不同图像的体素被推开。 为了学习解锁所需属性的特征提取器,我们使用infonce loss[18]:
L
q
=
−
log
exp
(
q
⋅
k
+
/
τ
)
exp
(
q
⋅
k
+
/
τ
)
+
∑
k
∈
K
−
exp
(
q
⋅
k
/
τ
)
\mathcal{L}_{q}=-\log \frac{\exp \left(q \cdot k_{+} / \tau\right)}{\exp \left(q \cdot k_{+} / \tau\right)+\sum_{k \in \mathcal{K}_{-}} \exp (q \cdot k / \tau)}
Lq=−logexp(q⋅k+/τ)+∑k∈K−exp(q⋅k/τ)exp(q⋅k+/τ)
查询q∈RC是学生特征体ZF中的体素,键k∈RC来自教师特征体ZG。 特别地,正键K+是与查询Q在同一图像中的同一位置对应的教师特征体素。 集合k-包含迷你批处理中来自不同位置和不同输入的所有其他键。 τ是一个温度超参数。
为了获得体素方面的对比损失,我们对由学生特征量的小批量中的所有特征体素组成的查询体素集合QV取平均值:
L
v
=
1
∣
Q
v
∣
∑
q
∈
Q
v
L
q
\mathcal{L}_{v}=\frac{1}{|\mathcal{Q}_v|}\sum_{q\in \mathcal{Q}_v}\mathcal{L}_{q}
Lv=∣Qv∣1q∈Qv∑Lq
维度对比目标根据对比学习中维度崩溃的最新发现[10,9],我们提出了一个维度对比目标,以鼓励特征体素中的不同维度/通道包含不同的信息。
给定一批形状为B×H×W×D×C的学生特征体,我们将前4个维数分组,得到一组维数查询:Q∈QDTUR(B×H×W×D),其中QD=C,特征体中的通道数。 我们用同样的方法定义k={k+}@k-,但是使用来自教师编码器的相应批特征量。 在维度对比设置中,K+被定义为与查询Q对应的相同特征维度的关键向量。 维度对比损失是所有查询维度的平均值:
L
d
=
1
c
∑
q
∈
Q
d
L
q
\mathcal{L}_{d}=\frac{1}{c}\sum_{q\in \mathcal{Q}_{d}}\mathcal{L}_{q}
Ld=c1q∈Qd∑Lq
我们从理论上证明了我们的维度对比学习继承了附录中的HardnessAware特性。
一致性损失LC最近的工作[11,21]表明,在网络参数上使用指数移动平均(EMA)可以提高训练的稳定性和模型的最终性能。 在此基础上,我们引入了一个EMA教师模型,其中参数θ作为原始学生网络参数θ的移动平均数。 具体地说,EMA模型的体系结构沿袭了原始模型。 在训练步骤T中,更新规则遵循
θ
t
=
m
θ
t
−
1
+
(
1
−
m
)
θ
t
θ_t=mθ_t-1+(1-m)θ_t
θt=mθt−1+(1−m)θt,其中
m
∈
[
0
,
1
)
m\in[0,1)
m∈[0,1)是动量参数。在未标记集上,我们对未标记的输入体积样本
X
u
X_u
Xu执行不同的扰动操作,例如添加噪声。为了提高训练的稳定性和性能,我们定义一致性损失为:
L
c
o
n
=
L
m
s
e
(
g
(
x
u
;
θ
,
ϵ
)
,
f
(
x
u
;
θ
′
,
ϵ
′
)
)
\mathcal{L}^{con}=\mathcal{L}_{mse}(g(x^u;\theta,\epsilon),f(x^u;\theta^\prime,\epsilon^\prime))
Lcon=Lmse(g(xu;θ,ϵ),f(xu;θ′,ϵ′))
其中
L
m
s
e
\mathcal{L}_{mse}
Lmse是误差损失的均方。
总体训练目标我们的总体学习目标是最小化有监督和无监督损失的组合。 在标记数据上,监督训练目标是交叉熵损失和骰子损失的线性组合。 在无标记数据集上,无监督训练目标由一致性损失LC、高水平对比损失LHIGH(即LHIGH V和LHIGH D的线性组合)和低水平对比损失LLOW(即LLOW V和LLOW D的线性组合)组成。 总体损失函数为:
L
=
L
s
u
p
+
α
L
h
i
g
h
+
β
L
l
o
w
+
γ
L
c
o
n
\mathcal{L}=\mathcal{L}^{sup}+\alpha\mathcal{L}^{high}+\beta\mathcal{L}^{low}+\gamma\mathcal{L}^{con}
L=Lsup+αLhigh+βLlow+γLcon
其中
α
,
β
,
γ
\alpha,\beta,\gamma
α,β,γ是平衡每个项的超参数。
2. 实验
数据集和预处理我们在两个基准数据集上进行实验:来自心房分割挑战者3的左心房(LA)数据集和NIH胰腺CT数据集[19]。
- LA数据集包括100个带有注释的三维钆增强MR成像扫描。 扫描的各向同性分辨率为0.625×0.625×0.625mm3。 我们使用80次扫描进行训练,20次扫描进行评估。 为了进行预处理,我们对心脏区域的所有扫描图像进行裁剪,并将其归一化为零和单位方差,子体积大小为112×112×80mm3。
- 胰腺数据集由82例腹部CT增强扫描组成。 我们使用相同的实验设置[14],随机选择62个扫描进行训练,20个扫描进行评估。 为了进行预处理,我们首先将CT图像的强度重订到窗口[-125,275]Hu[30]中,然后将所有数据重新采样到1.0×1.0×1.0mm3的各向同性分辨率。 我们裁剪所有胰腺区的扫描,归一化为零和单位方差,子体积大小为96×96×96mm3。
在本研究中,我们在10%和20%标记率下对LA和胰腺数据集进行了所有实验。 在我们的框架中,我们使用V-NET作为两个网络的网络骨干。
对于数据增强,我们使用标准的数据增强技术[27,20]。 我们将超参数α,β,γ,τ分别设为0.1,0.1,0.1,1.0。 我们使用动量为0.9、权衰减为0.0005的SGD优化器对网络参数进行优化。
在我们的框架中,我们使用V-NET作为两个网络的网络骨干。
对于数据增强,我们使用标准的数据增强技术[27,20]。 我们将超参数α,β,γ,τ分别设为0.1,0.1,0.1,1.0。 我们使用动量为0.9、权衰减为0.0005的SGD优化器对网络参数进行优化。
初始化速率设置为0.01,每3000次迭代除以10。 对于均线更新,我们遵循[27]中的实验设置,其中均线衰减率α被设置为0.999。
我们使用时间相关的高斯预热函数ψcon(t)=exp-5(1-t/tmax)2-来增加参数,其中t和tmax分别表示当前和最大训练步长。
为了公平起见,所有评估的方法都在PyTorch中实现,并在批大小为6的NVIDIA 3090TI GPU上进行了10000次迭代训练。 在测试阶段,我们采用了四个指标来评价分割性能,包括DICE系数(DICE)、JACCARD指数(JACCAR)、95%Hausdorff距离(95HD)和平均对称面距离(ASD)。
为了进一步评估CVRL的有效性,我们在10%的注释率(8个标记和72个未标记)下将其与其他方法进行比较,如表1所示。 在DICE(88.56%)和JACCARD(78.89%)方面,我们观察到相对于State of thearts的持续性能改进。
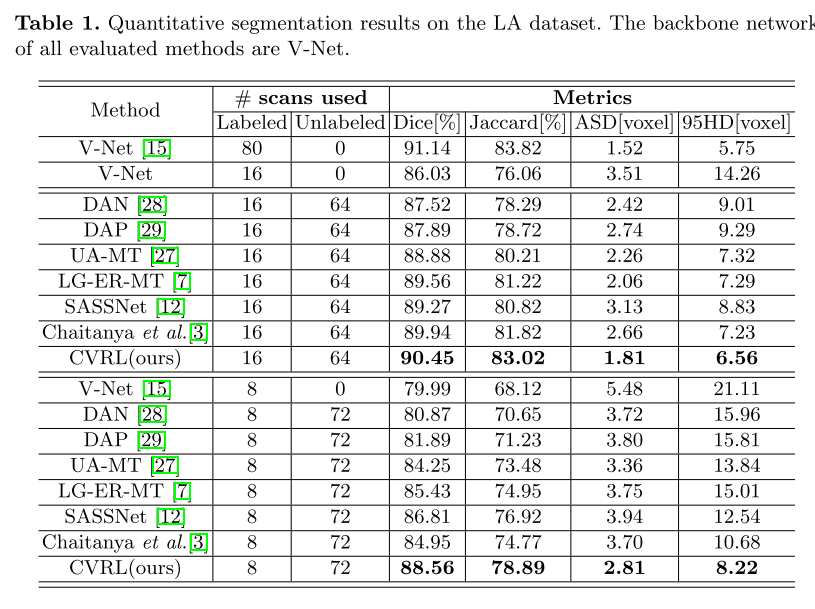
这个证据表明。
(i)用对比学习方法提取体素样本可以得到更好的体素嵌入;
(ii)在批量和特征维度上,高层和低级关系都是信息线索;
(iii)利用维对比度能够持续地帮助提高分割性能。
利用所有这些方面,它可以观察到一致的性能增益。
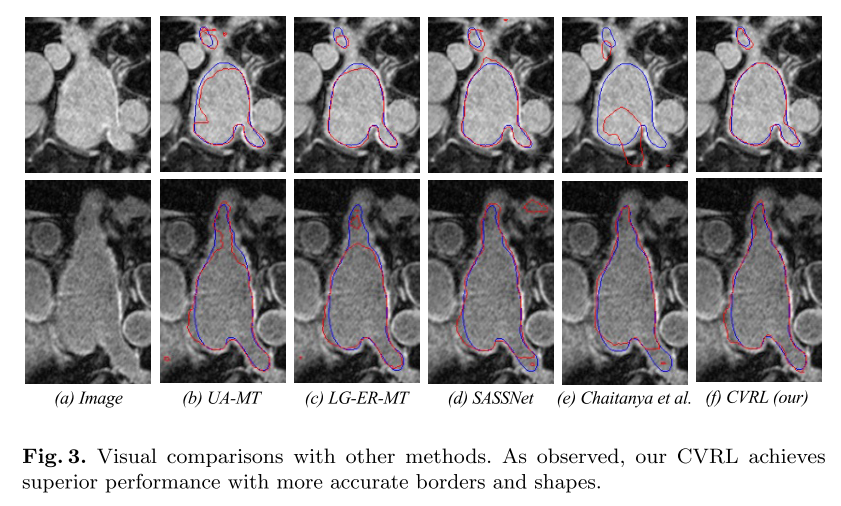
如图所示 3、考虑到在这种情况下的改进是困难的,我们的方法能够产生更准确的分割。 这说明了在批量和特征两个维度上综合考虑高层和低级对比的必要性; 和ii)实例间和实例内约束的有效性。 我们还评估了CVRL对胰腺的性能。 我们在附录表中提供关于胰腺的详细评估结果??。 我们发现CVRL显著地优于所有最先进的方法。 我们注意到,我们提出的CVRL可以改善结果一个特别显著的幅度,最多3.25-5.21%的骰子相对改善
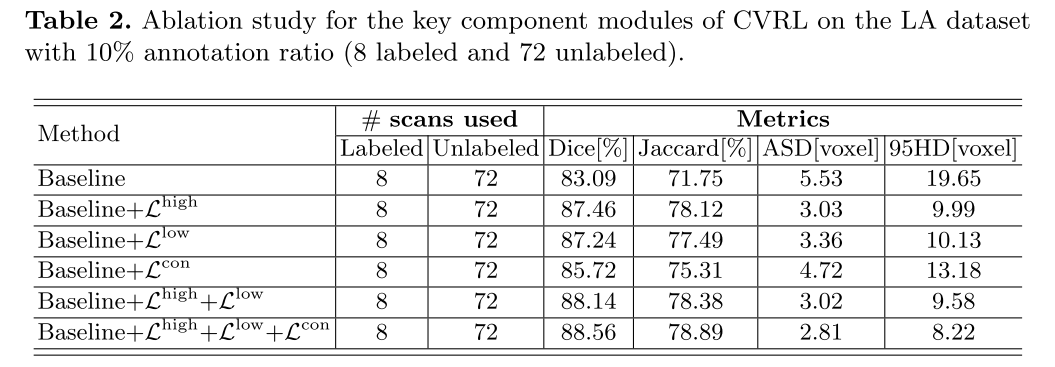
消融研究
我们通过消融实验来验证我们提出的方法中的主要组成部分的有效性,包括高水平和低水平对比策略,以及一致性损失。 定量结果在表2中报告。 在10%的注释率下,我们将CVRL与它的五个变体(8个标记,72个未标记)进行了比较。 特别地,基线模型参考了MT[21]。 我们逐渐合并LHIGH、LLOW、LCON,分别表示为基线+LLOW、基线+LHIGH、基线+LCON、基线+LLOW+LHIGH、基线+LLOW+LHIGH、基线+LLOW+LHIGH+LCON(CVRL)。 如表所示,基线网络在DICE,JACCAR,ASD和95HD方面分别达到83.09%,71.75%,5.53%,19.65%。 随着LHIGH、LLOW、LCON的不断引入,我们提出的算法在基线网络上有了持续的改进,DICE和JACCARD分别提高了5.47%和7.14%。 同时,ASD和95HD指标分别降低了2.72和11.43。 这进一步验证了每个关键组件的有效性。 我们在附录图中总结了超参数的影响??。
3. 总结
在这项工作中,我们提出了一个半监督的对比表示提取框架CVRL,通过利用低层和高层线索来学习体素表示,用于体积医学图像分割。 具体来说,我们建议使用体素对比和维度对比学习来确保多样性促进和开发训练体素之间的复杂关系。 我们还表明硬度感知特性是我们提出的尺寸对比学习成功的一个关键特性。 实验结果表明,我们的模型能够在有限的注释下生成更精确的边界,从而获得了最先进的性能。







![windows本地开发Spark[不开虚拟机]](https://img-blog.csdnimg.cn/a75e70f97c4b41be9ca4e040f9bfa151.png)