🔥Go for it!🔥
📝个人主页:按键难防
📫 如果文章知识点有错误的地方,请指正!和大家一起学习,一起进步👀📖系列专栏:数据结构与算法
🔥 如果感觉博主的文章还不错的话,还请 点赞👍🏻收藏⭐️ + 留言📝支持 一下博主哦
目录
树
二叉树:
二叉树定义方法(链式存储):
层次建树实战:
①辅助队列(链式存储实现):
②建树(源码):
二叉树的遍历:
①前序遍历
②中序遍历
③后序遍历
④层次遍历
汇总:

树
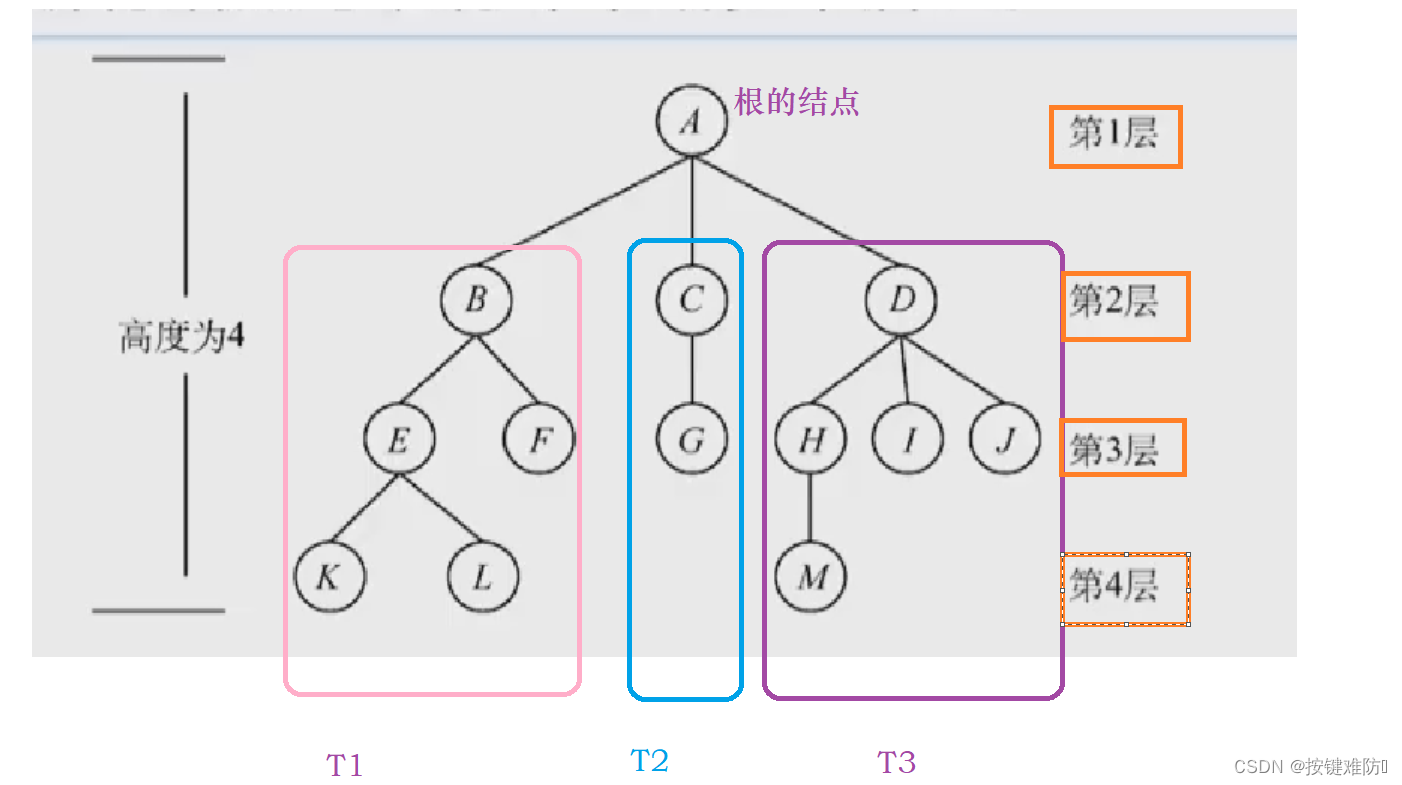
树是n(n ≥ 0)个节点的有限集。当n = 0时,称为空树。在任意一棵非空树中应满足:
1)有且仅有一个特定的结点的称为根的结点。
2)当n > 1时,其余节点可分为m(m > 0)个 互不相交的有限集T1, T2,…, Tm,其中每个集合 本身又是一棵树,并且称为根的子树。
特点:
树作为一种逻辑结构,同时也是一种分层结构,具 有以下两个特点:
1)树的根结点没有前驱,除根结点外的所有结点有且只有一个前驱。
2)树中所有结点可以有零个或多个后继。
二叉树:
二叉树是另一种树形结构,其特点是每个结点至多只有两棵子树 (即二叉树中不存在度大于2的结点),并且二叉树的子树有左右之分,其次序不能任意颠倒。 与树相似,二叉树也以递归的形式定义。二叉树是n(n ≥ 0)个 结点的有限集合:
① 或者为空二叉树,即n = 0。
② 或者由一个根结点和两个互不相交的被称为根的左子树和右子树组成。左子树和右子树又分别是一棵二叉树。
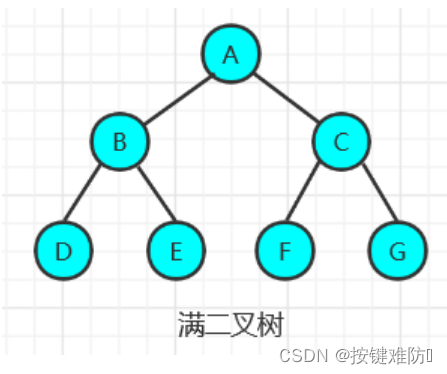
满二叉树:
在一颗二叉树中,如果所有分支结点都有左子结点和右子结点,并且叶结点都集中在二叉树的最底层,这样的二叉树称为满二叉树。
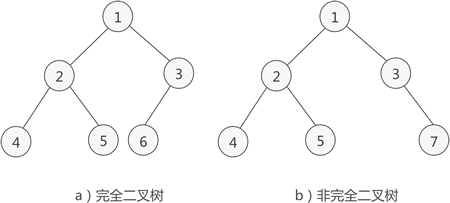
完全二叉树:
完全二叉树是由满二叉树引出的。满二叉树要求每一层的节点数都达到最大值,完全二叉树仅要求除最后一层外的节点数达到最大值,也就是说最后一层可以不满。但是最后一层从左往右不能有中断。
二叉树定义方法(链式存储):
typedef char BiElemType;
typedef struct BiTNode{
BiElemType c;//c就是书籍上的data
struct BiTNode *lchild;//该二叉树的左孩子
struct BiTNode *rchild;//该二叉树的右孩子
}BiTNode, *BiTree;
解释:typedef重命名了两个数据类型,
分别是将struct BiTNode重命名为BiTNode,将struct BiTNode*重命名为BiTree
前者是个结构体,后者是个指向该结构体的指针
用BiTNode创建变量,就是创建一个结构体(树的结点)
用BiTree创建变量,就是指向这个结构体的指针,用于接受动态内存开辟返回的指针层次建树实战:
将"abcdefghij"用二叉树的方式存起来。
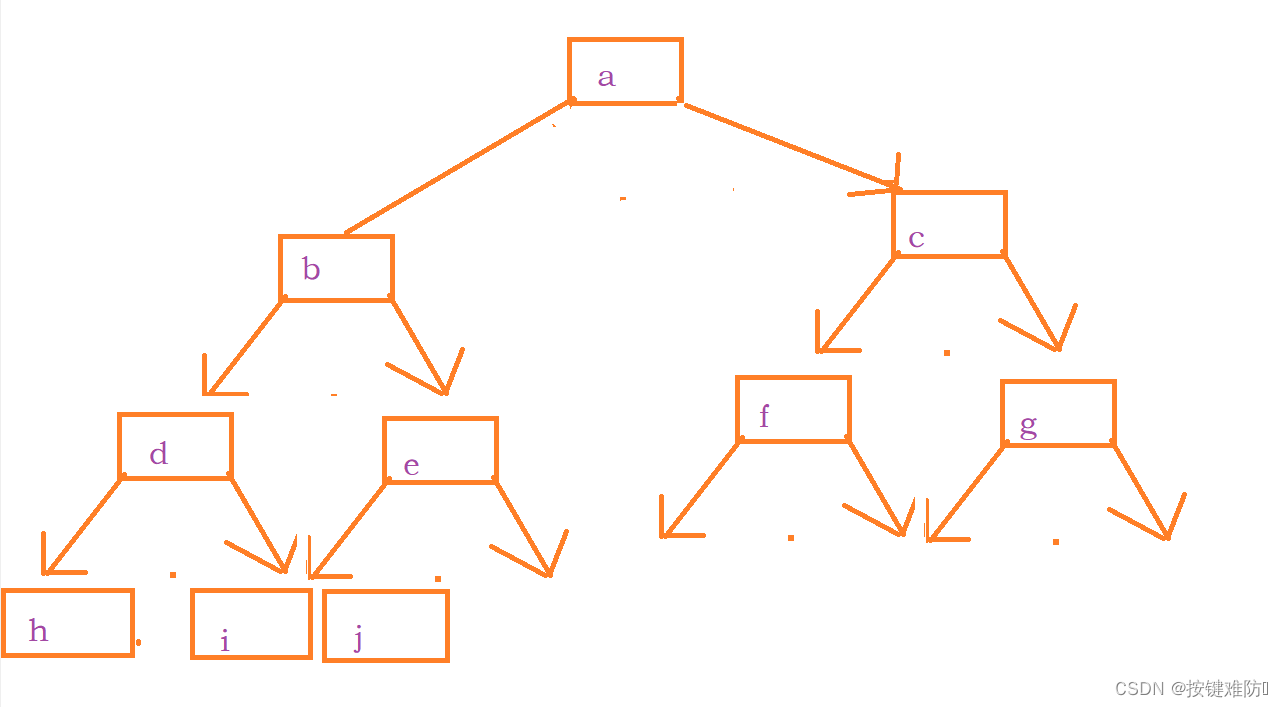
①辅助队列(链式存储实现):
每多一个分支就当做一个元素入队,每当一个结点都有左右孩子,出队该节点。
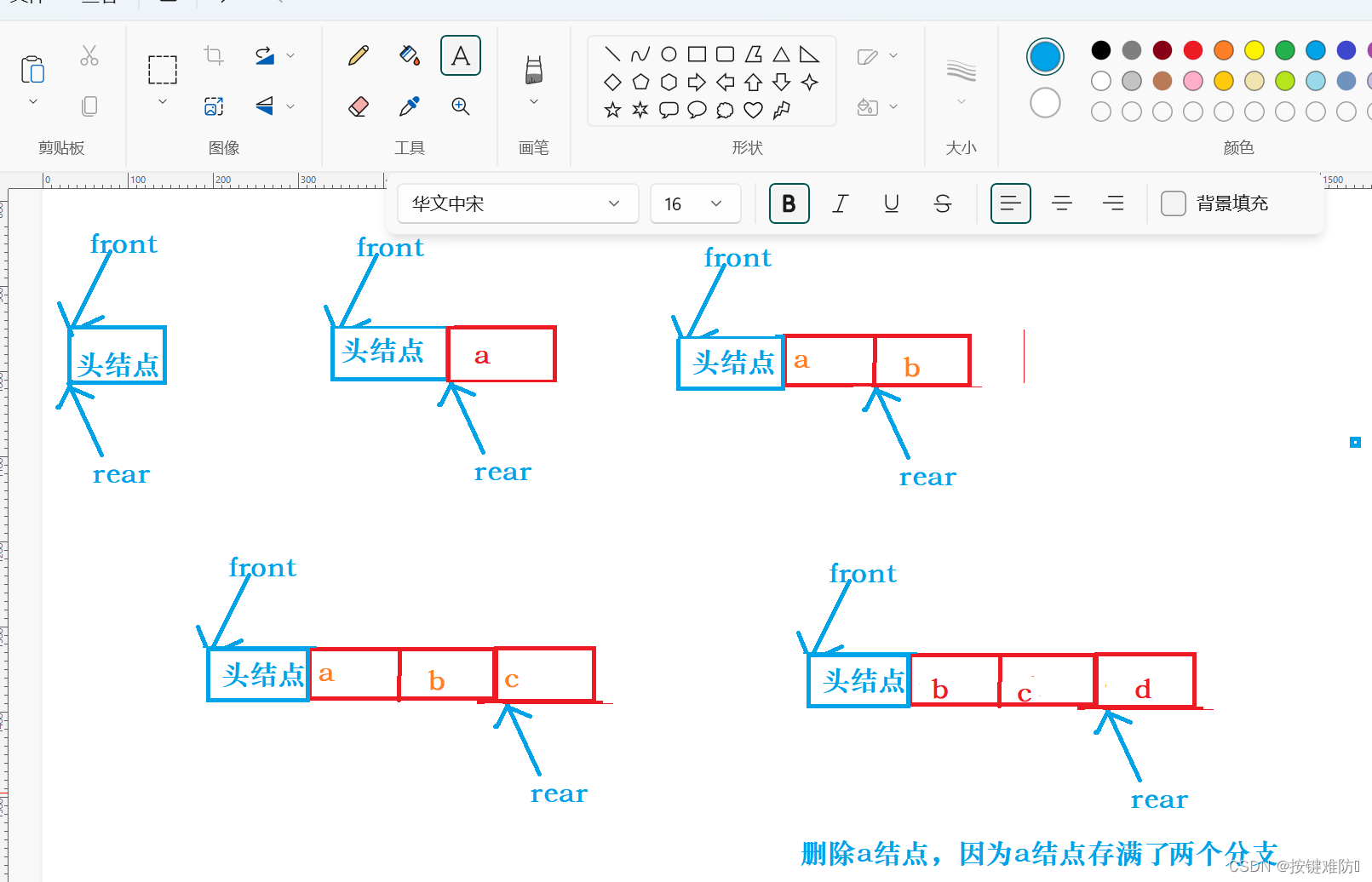
所以只要满3个结点,就说明有一个树的结点存满两个分支,这样就需要删除第一个结点。
保证第一个结点始终不满两个分支。
实现:
typedef struct LinkNode//LinkNode结构体是辅助队列的结点
{
BiTree p;//数据域,存放树的结点的地址值
struct LinkNode *next;//指针域,辅助队列中下一个结点
}LinkNode;
typedef struct//结构体,用于存放辅助队列头结点和队列尾结点的指针
{
LinkNode* front, *rear;
}LinkQueue;
void InitQueue(LinkQueue &Q) //初始化头尾指针,就是创建头结点,然后头尾指针都指向这一头结点
{
Q.front = Q.rear = (LinkNode*)malloc(sizeof(LinkNode));
//为辅助队列头结点申请空间
//初始化时头尾指针都指向这一头结点
Q.front->next = NULL;//头结点的next指针为NULL
}
void EnQueue(LinkQueue&Q, BiTree x)//入队,尾部插入法
{
LinkNode *s = (LinkNode *)malloc(sizeof(LinkNode));//为入队的元素申请空间
s->p = x; s->next = NULL;//新申请的结点作为最后一个结点
Q.rear->next =s;//先让前一结点(Q.rear)的指针域指向新插入的结点
Q.rear = s;//然后再让Q.rear变为指向尾部的那个结点
}
//出队 头部删除法
bool DeQueueF(LinkQueue &Q)
{
//front始终指向头结点,但头结点什么都没存
LinkNode *q = Q.front->next;//将第一个节点存入q
Q.front->next = q->next;//断链,保留第一个结点的指针域,让头节点指向第二个结点
free(q);
return true;
}②建树(源码):
注释的很详细
#include <stdio.h>
#include <stdlib.h>
typedef char BiElemType;
typedef struct BiTNode{
BiElemType data;
struct BiTNode *lchild;
struct BiTNode *rchild;
}BiTNode, *BiTree;
typedef struct LinkNode//LinkNode结构体是辅助队列的结点
{
BiTree p;//树的某一个结点的地址值,不是数值
struct LinkNode *next;//辅助队列中下一个结点
}LinkNode;
typedef struct //结构体,用于存放辅助队列头结点和队列尾结点的指针
{
LinkNode* front, *rear;
}LinkQueue;
void InitQueue(LinkQueue &Q) //初始化头尾指针,就是创建头结点,然后头尾指针都指向这一头结点
{
Q.front = Q.rear = (LinkNode*)malloc(sizeof(LinkNode));
//为辅助队列头结点申请空间
//初始化时头尾指针都指向这一头结点
Q.front->next = NULL;//头结点的next指针为NULL
}
void EnQueue(LinkQueue&Q, BiTree x)//入队,尾部插入法
{
LinkNode *s = (LinkNode *)malloc(sizeof(LinkNode));//为入队的元素申请空间
s->p = x; s->next = NULL;//新申请的结点作为最后一个结点
Q.rear->next =s;//先让前一结点(Q.rear)的指针域指向新插入的结点
Q.rear = s;//然后再让Q.rear变为指向尾部的那个结点
}
//出队 头部删除法
bool DeQueueF(LinkQueue &Q)
{
//front始终指向头结点,但头结点什么都没存
LinkNode *q = Q.front->next;//将第一个节点存入q
Q.front->next = q->next;//断链,保留第一个结点的指针域,让头节点指向第二个结点
free(q);
return true;
}
int main()//二叉树的建树(层次建树)
{
LinkQueue Q;//创建辅助队列头尾指针
InitQueue(Q);//初始化头尾指针
BiTree pnew;//用来指向新申请的树结点的指针
BiTree tree = NULL;//树根的指针
char c;
//输入内容为 abcdefghij
while (scanf("%c", &c))
{
if (c == '\n')
{
break;
}
pnew = (BiTree)calloc(1, sizeof(BiTNode));//calloc申请空间并对空间进行初始化,赋值为0
pnew->data = c;//数据放进去
EnQueue(Q, pnew);//将新创建的树的结点的地址入队辅助队列
//下面是建树的过程
if (NULL == tree)//空树
{
tree = pnew; //tree指向树的根节点
continue;//该节点为树的第一个节点
//直接跳到循环的判断部分
}
else
{
if (NULL == Q.front->next->p->lchild)//如何把新结点放入树
{//Q.front->next为辅助队列第一个结点
Q.front->next->p->lchild = pnew;//把新结点放到要插入结点的左边
}
else if (NULL == Q.front->next->p->lchild)
{
Q.front->next->p->rchild = pnew;//把新结点放到要插入结点的右边
DeQueue(Q);//左右都放了结点后,辅助队列该删除第一个节点了
//该函数只用于出队,不保存出队结点的数据}
}
}
return 0;
}二叉树的遍历:
①前序遍历
首先前序遍历是先打印自身,再打印左子树,再打印右子树,我们通 过 PreOrder 函数来实现
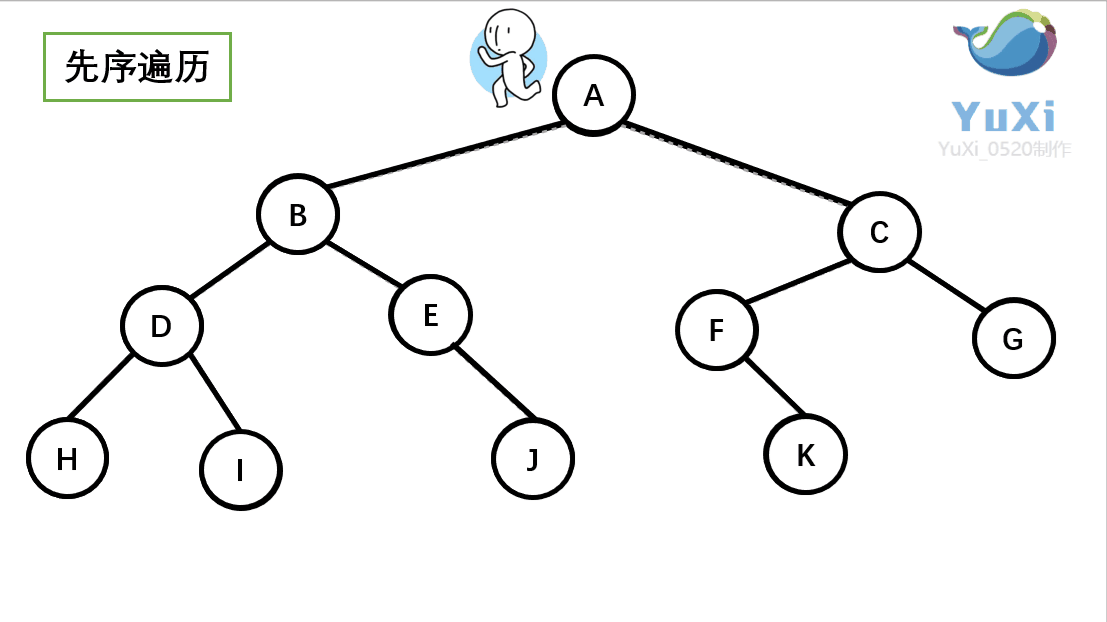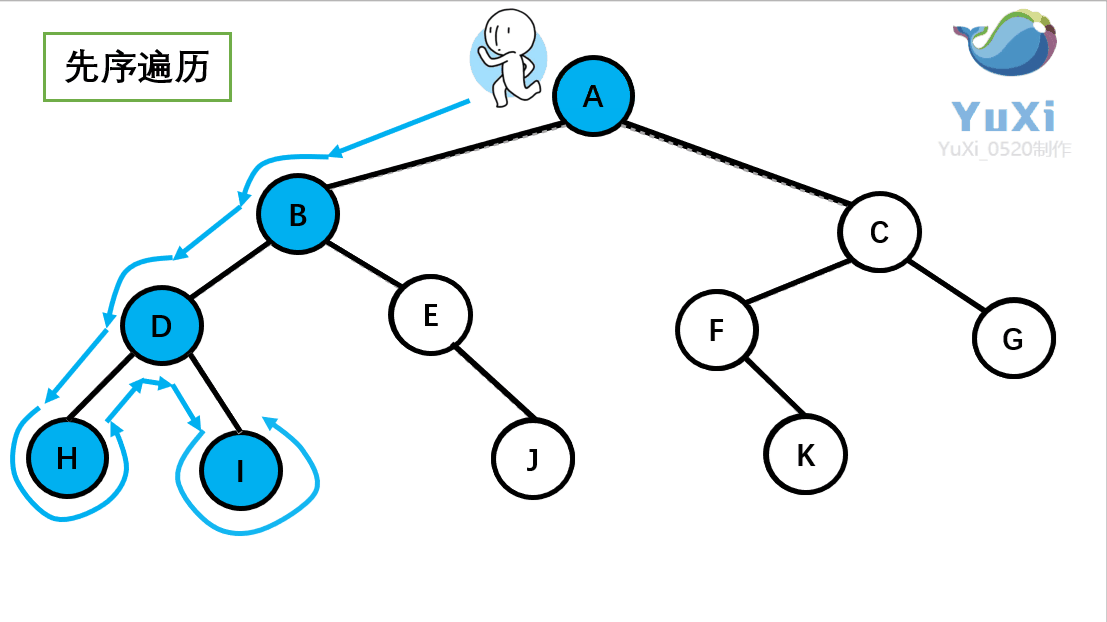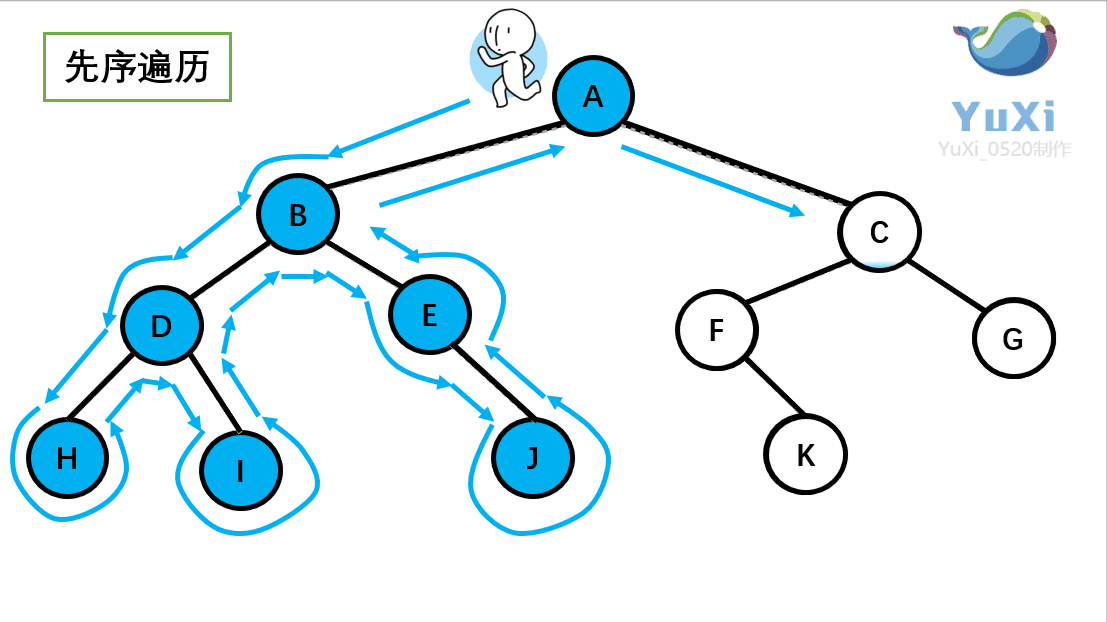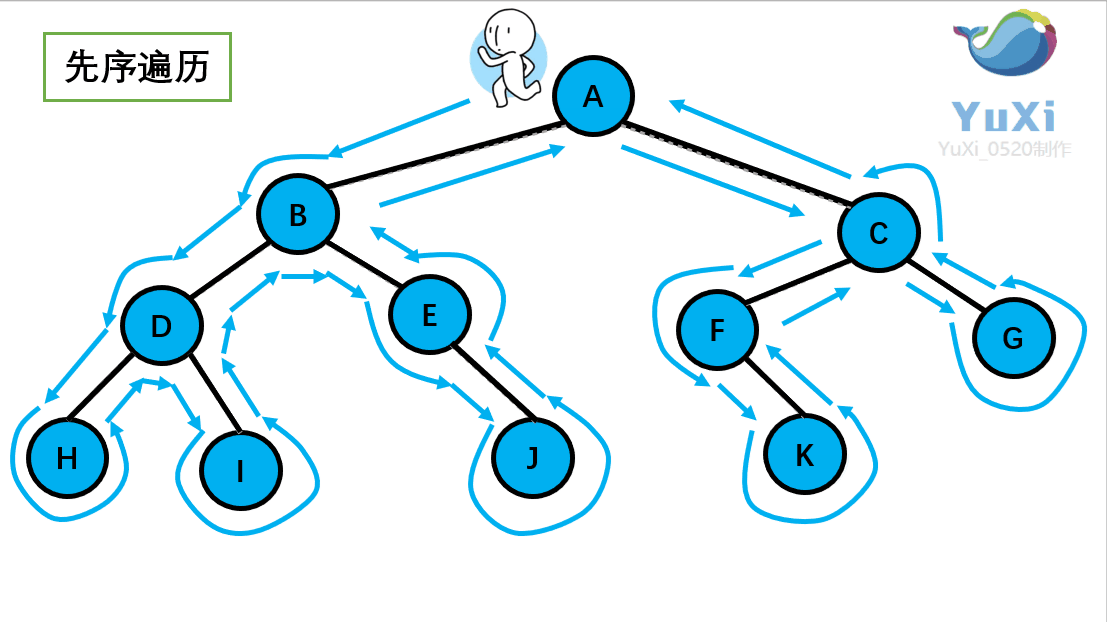
//递归实现
//abdhiejcfg 前序遍历,前序遍历就是深度优先遍历
void PreOrder(BiTree p)
{
if (p != NULL)
{
putchar(p->data);
PreOrder(p->lchild);
PreOrder(p->rchild);
}
}②中序遍历
中序遍历是先打印左子树,再打印当前结点,再打印右子树,我 们通过 InOrder 函数来实现。
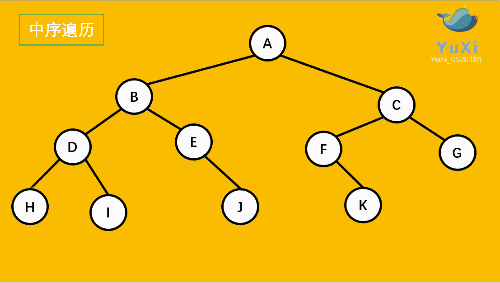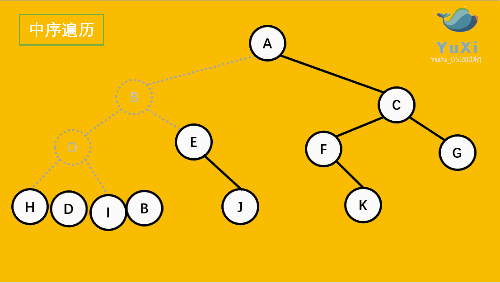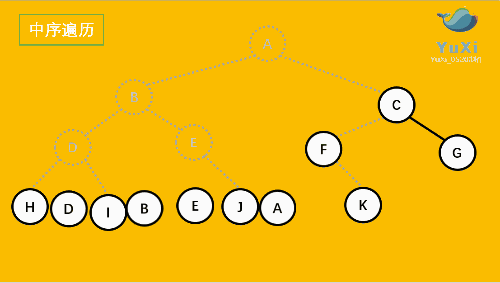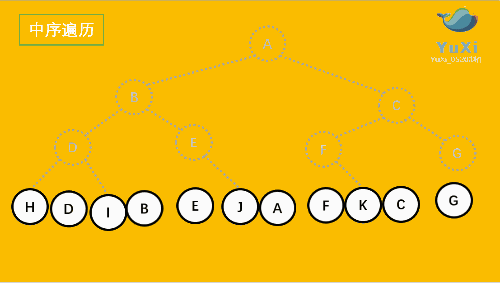
//中序遍历 hdibjeafcg
void InOrder(BiTree p)
{
if (p != NULL)
{
InOrder(p->lchild);
putchar(p->data);
InOrder(p->rchild);
}
}③后序遍历
后序遍历是先打印左子树,再打印右子树,最后打印当前结点, 我们通过 PostOrder 函数来实现。
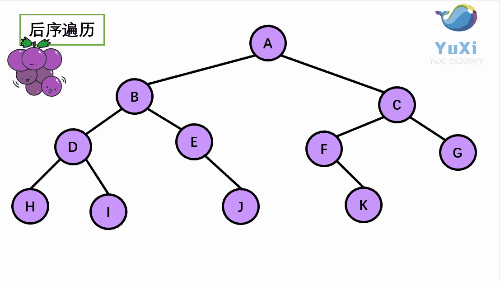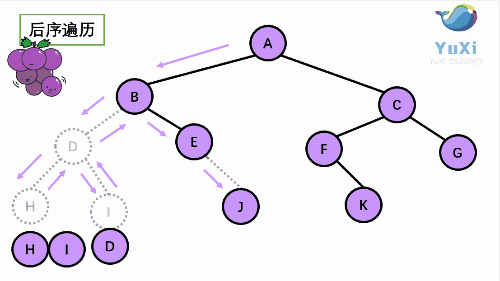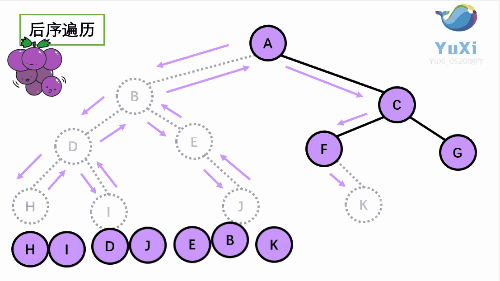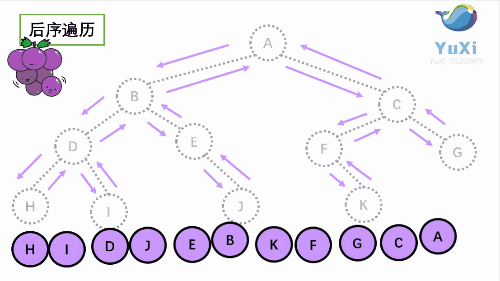
//hidjebfgca 后序遍历
void PostOrder(BiTree p)
{
if (p != NULL)
{
PostOrder(p->lchild);
PostOrder(p->rchild);
putchar(p->data);
}
}④层次遍历
二叉树的层次遍历 ,顾名思义就是指从二叉树的第一层(根节点)开始,从上至下逐层遍历,在同一层中,则按照从左到右的顺序对节点逐个访问。在逐层遍历过程中,按从顶层到底层的次序访问树中元素,在同一层中,从左到右进行访问。
树根的地址作为辅助队列的第一个结点的数据域,然后删除第一个结点,保留数据域,然后借助树根的地址让自己的左孩子(b)和右孩子(c)分别入队,然后打印左孩子数据域(b),再入队左孩子的两个分支(de),然后打印右孩子的数据域,入队右孩子的两个分支(fg),然后一直这样循环。就可以把树连根拔起。
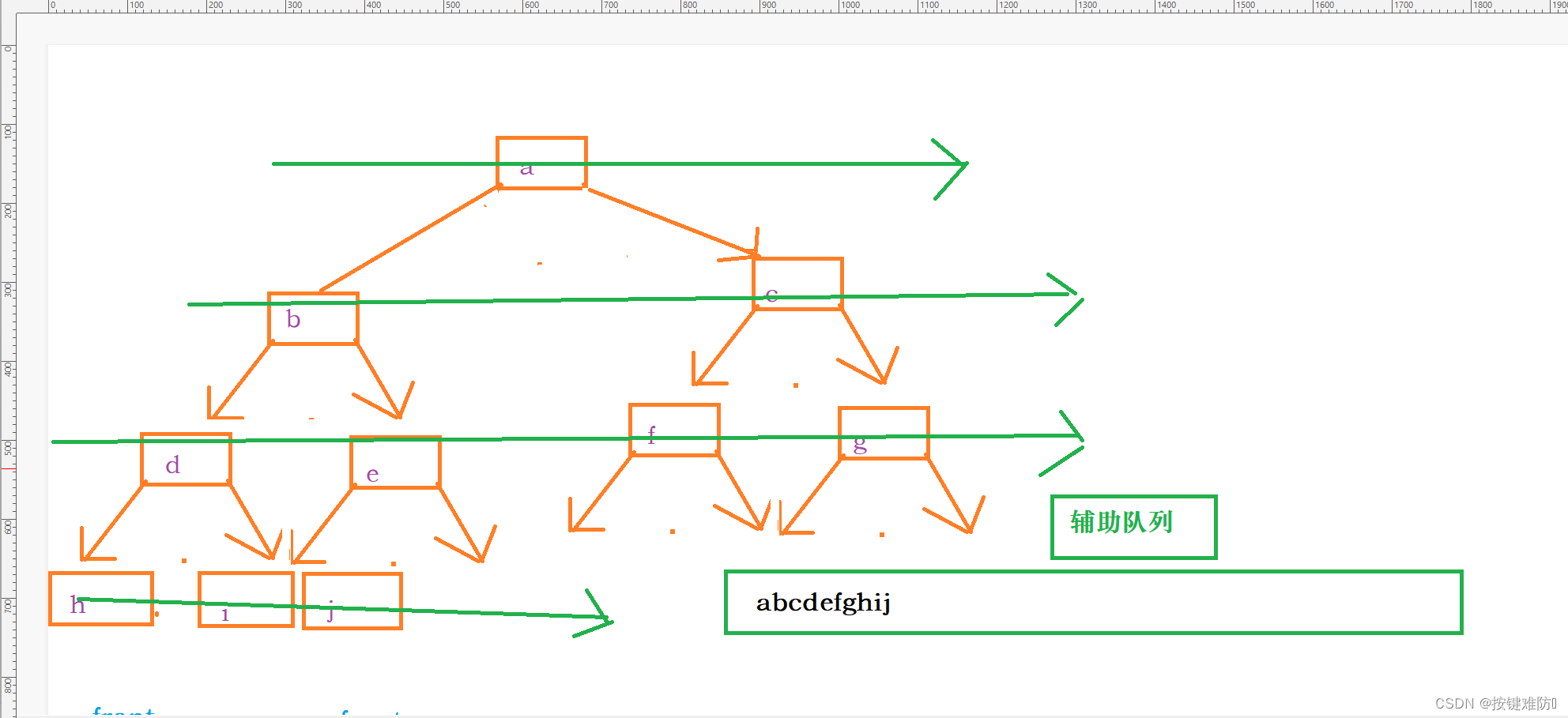
void LevelOrder(BiTree T)
{
LinkQueue Q1;//辅助队列
InitQueue(Q1);//初始化队列
BiTree p;//存储出队的结点
EnQueue(Q1, T);//树根入队
while (!IsEmpty(Q1))//!是逻辑反操作
{//队列不是空,循环继续
DeQueue(Q1,p);//出队当前结点
//p是出队结点的数据域,借助它找到出队结点指向的树的结点的左右孩子
putchar(p->data);//打印数据域
if (p->lchild != NULL) //入队左孩子
{
EnQueue(Q1, p->lchild);
}
if (p->rchild != NULL) //入队右孩子
{
EnQueue(Q1, p->rchild);
}
}
汇总:
#include <stdio.h>
#include <stdlib.h>
typedef char BiElemType;
typedef struct BiTNode{
BiElemType data;
struct BiTNode *lchild;
struct BiTNode *rchild;
}BiTNode, *BiTree;
typedef struct LinkNode//LinkNode结构体是辅助队列的结点
{
BiTree p;//树的某一个结点的地址值,不是数值
struct LinkNode *next;//辅助队列中下一个结点
}LinkNode;
typedef struct //结构体,用于存放辅助队列头结点和队列尾结点的指针
{
LinkNode* front, *rear;
}LinkQueue;
void InitQueue(LinkQueue &Q) //初始化头尾指针,就是创建头结点,然后头尾指针都指向这一头结点
{
Q.front = Q.rear = (LinkNode*)malloc(sizeof(LinkNode));
//为辅助队列头结点申请空间
//初始化时头尾指针都指向这一头结点
Q.front->next = NULL;//头结点的next指针为NULL
}
bool IsEmpty(LinkQueue Q)
{
if (Q.front == Q.rear)
return true;
else
return false;
}
void EnQueue(LinkQueue&Q, BiTree x)//入队,尾部插入法
{
LinkNode *s = (LinkNode *)malloc(sizeof(LinkNode));//为入队的元素申请空间
s->p = x; s->next = NULL;//新申请的结点作为最后一个结点
Q.rear->next =s;//先让前一结点(Q.rear)的指针域指向新插入的结点
Q.rear = s;//然后再让Q.rear变为指向尾部的那个结点
}
//出队 头部删除法
bool DeQueueF(LinkQueue &Q)
{//不保存删除结点数据域
//front始终指向头结点,但头结点什么都没存
LinkNode *q = Q.front->next;//将第一个节点存入q
Q.front->next = q->next;//断链,保留第一个结点的指针域,让头节点指向第二个结点
free(q);
return true;
}
bool DeQueue(LinkQueue &Q, BiTree &x)//出队
{//x用于保存删除结点的数据域
if (Q.front == Q.rear)
{
return false;
}//队列为空
//front始终指向头结点,但头结点什么都没存
LinkNode *q = Q.front->next;//将第一个节点存入q
x = q->p;//获取要出队结点存储的值
Q.front->next = q->next;//断链,保留第一个结点的指针域,让头节点指向第二个结点
if (Q.rear == q)//删除的是最后一个元素
{
Q.rear = Q.front;//队列置为空
}
free(q);
return true;
}
// 递归实现
//abdhiejcfg 前序遍历,前序遍历就是深度优先遍历
void PreOrder(BiTree p)
{
if (p != NULL)
{
putchar(p->data);
PreOrder(p->lchild);
PreOrder(p->rchild);
}
}
//中序遍历 hdibjeafcg
void InOrder(BiTree p)
{
if (p != NULL)
{
InOrder(p->lchild);
putchar(p->data);
InOrder(p->rchild);
}
}
//hidjebfgca 后序遍历
void PostOrder(BiTree p)
{
if (p != NULL)
{
PostOrder(p->lchild);
PostOrder(p->rchild);
putchar(p->data);
}
}
void LevelOrder(BiTree T)
{
LinkQueue Q1;//辅助队列
InitQueue(Q1);//初始化队列
BiTree p;//存储出队的结点
EnQueue(Q1, T);//树根入队
while (!IsEmpty(Q1))//!是逻辑反操作
{//队列不是空,循环继续
DeQueue(Q1,p);//出队当前结点
//p是出队结点的数据域,借助它找到出队结点指向的树的结点的左右孩子
putchar(p->data);//打印数据域
if (p->lchild != NULL) //入队左孩子
{
EnQueue(Q1, p->lchild);
}
if (p->rchild != NULL) //入队右孩子
{
EnQueue(Q1, p->rchild);
}
}
int main()//二叉树的建树(层次建树)
{
LinkQueue Q;//创建辅助队列头尾指针
InitQueue(Q);//初始化头尾指针
BiTree pnew;//用来指向新申请的树结点的指针
BiTree tree = NULL;//树根的指针
BiTree de;//
char c;
//输入内容为 abcdefghij
while (scanf("%c", &c))
{
if (c == '\n')
{
break;
}
pnew = (BiTree)calloc(1, sizeof(BiTNode));//calloc申请空间并对空间进行初始化,赋值为0
pnew->data = c;//数据放进去
EnQueue(Q, pnew);//将新创建的树的结点的地址入队辅助队列
//下面是建树的过程
if (NULL == tree)//空树
{
tree = pnew; //tree指向树的根节点
continue;//该节点为树的第一个节点
//直接跳到循环的判断部分
}
else
{
if (NULL == Q.front->next->p->lchild)//如何把新结点放入树
{//Q.front->next为辅助队列第一个结点
Q.front->next->p->lchild = pnew;//把新结点放到要插入结点的左边
}
else if (NULL == Q.front->next->p->rchild)
{
Q.front->next->p->rchild = pnew;//把新结点放到要插入结点的右边
DeQueueF(Q);//左右都放了结点后,辅助队列该删除第一个节点了
//该函数只用于出队,不保存出队结点的数据
}
}
}
printf("--------前序遍历----------\n");//也叫先序遍历,先打印当前结点,打印左孩子,打印右孩子
PreOrder(tree);
printf("\n--------中序遍历------------\n");//先打印左孩子,打印父亲,打印右孩子
InOrder(tree);
printf("\n--------后序遍历------------\n");//先打印左孩子,打印右孩子,最后打印父亲
PostOrder(tree);
printf("\n--------层次遍历-----------\n");
LevelOrder(tree);
printf("\n");
return 0;
}效果:

希望这篇文章📃能对你有所帮助😁😁

![windows本地开发Spark[不开虚拟机]](https://img-blog.csdnimg.cn/a75e70f97c4b41be9ca4e040f9bfa151.png)