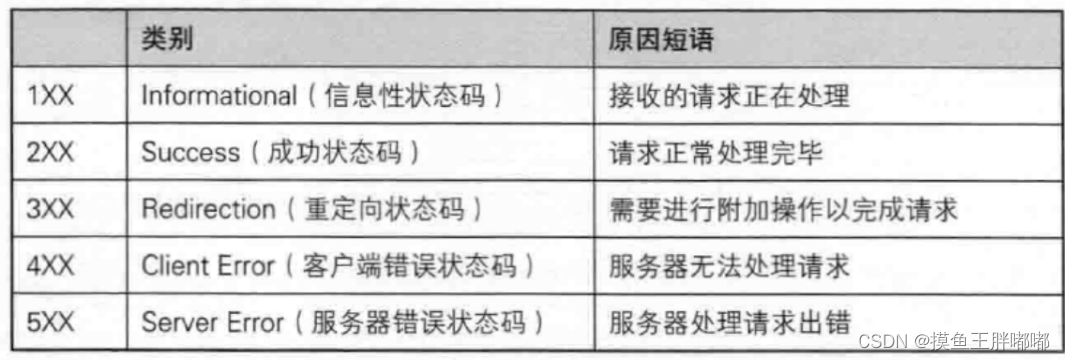
在工业领域, 生产、测试、运行阶段都可能会产生大量带有时间戳的传感器数据,这都属于典型的时序数据。时序数据主要由各类型实时监测、检查与分析设备所采集或产生,涉及制造、电力、化工、工程作业等多个行业,具备写多读少、量非常大等典型特性。如 Apache HBase、MySQL 等互联网公司常用的数据库在写入、存储、查询、运维等方面都暴露出了诸多问题。这种情况下,从业务发展的角度出发,数据架构改造成为了当务之急。
本文汇总了包括西门子、美的、拓斯达、和利时在内的四家比较具有代表性的工业企业的架构改造案例,一起来看看他们都是如何做的,改造效果是否达成了预期。
西门子 x TDengine
“从高性能、高可用、低成本、高度一体化几个目标出发,我们发现 TDengine 正好符合产品重构所有的要求,尤其是低成本和高度一体化这两个点,这是目前绝大部分数据平台或时序数据库都不具备的。在确定选择 TDengine 作为系统的数据库后,我们在 SIMICAS ® OEM 2.0 版本中移除了Flink、Kafka 以及 Redis,系统架构大大简化。”
业务背景
SIMICAS® OEM 设备远程运维套件是由 SIEMENS DE&DS DSM 团队开发的一套面向设备制造商的数字化解决方案。在其 1.0 版中,团队使用了 Flink + Kafka + PostgreSQL + Redis 的架构,因为引入了 Flink 和 Kafka,导致系统部署时非常繁琐,服务器开销巨大;同时为了满足大量数据的存储问题,PostgreSQL 中不得不做分库分表操作,应用程序较为复杂。这种情况下,如何降低系统复杂度、减少硬件资源开销,帮助客户减少成本,成为研发团队的核心任务。在调研过程中,TDengine 脱颖而出。
架构图
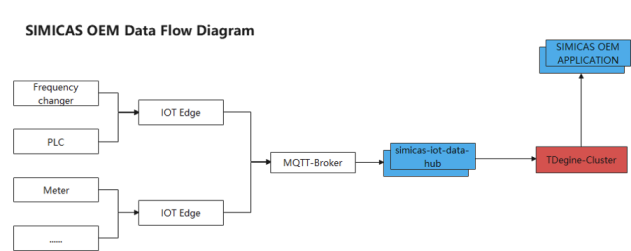
点击案例查看更多技术细节
美的 x TDengine
“当前,TDengine 主要被应用于中央空调制冷设备的监控业务中,作为先行试点,这一场景已经取得了不错的效果。在楼宇智能化方面,我们也有很多工作要做,从边缘侧的监控、到指令控制、再到边云协同的一体化服务,我们会在这些场景中继续探索和挖掘 TDengine 的潜力。”
业务背景
在 2021 楼宇科技 TRUE 大会上,美的暖通与楼宇事业部首次发布了数字化平台 iBuilding,以“软驱硬核”方式赋能建筑行业。作为一个全新的项目,iBuilding 在数据库选型上比较谨慎,分别对比了关系型数据库(Relational Database)以及主流的时序数据库(Time Series Database),包括 InfluxDB、TDengine、MySQL 等,因为在需求上更偏向于高效的存储和大范围时间的数据拉取,iBuilding 在综合评估了适配、查询、写入和存储等综合能力后,最终选择了 TDengine。
架构图
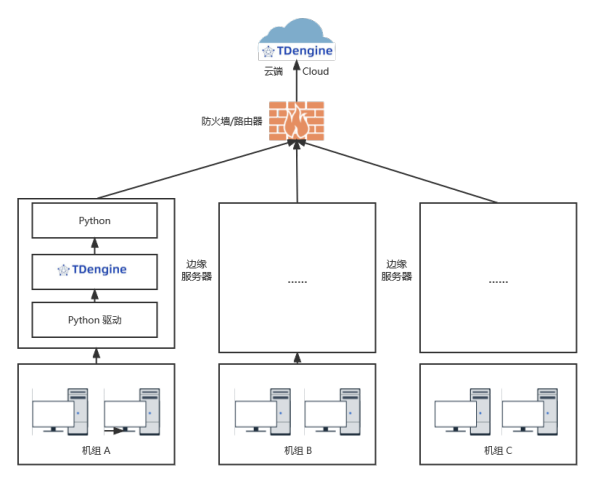
点击案例查看更多技术细节
拓斯达 x TDengine
“运行一段时间后,TDengine 的查询、写入速度完全可以满足我们目前的客户需求,最慢的分钟级,最快的能达到 1 秒一条;一个设备一天最多能写入近十万条数据,近千个设备同时写入也完全没有问题,相较于之前,写入速度提升了数十倍。查询数据在以月为单位的时间范围内也没有过于明显的延迟,整体的数据压缩比大概是 1/10,目前每天产生的数据量在数 G 左右。”
业务背景
在拓斯达的业务中,传统的关系型数据库已经无法高效处理时序数据,在加载、存储和查询等多个方面都遇到了挑战,主要问题包括写入吞吐低、存储成本大、维护成本高、查询性能差。为了更好地满足时序数据的处理需求,拓斯达开始进行数据库选型调研,他们发现,TDengine 专为时序数据库所打造和优化的写入、存储、查询等功能,非常匹配工业传感器数据的应用分析场景,最终其使用 TDengine 搭建了新的数据处理架构。
架构实现思路
通过网关采集设备数据推送到 MQTT,Java 后端监听到后会写入 TDengine,在后端按需求查询处理后再把数据返回给前端。具体来说,网关会先读取后台发布的上行规则,在采集到设备数据后,使用上行规则对数据进行处理计算后再将结果返回给下行规则模块,后台监听到后,会连接 TDengine 进行数据库表的创建修改和数据写入。之前在云平台拓斯达使用过 Kafka 进行数据的发布订阅,现在所有环境都改为 MQTT 了。
点击案例查看更多技术细节
和利时 x TDengine
“在测试阶段,我们发现,同等条件下,TDengine 的压缩率最高,数据占用的存储空间最小;在原始数据查询上,OpenTSDB 最慢,TDengine 与 HolliTSDB 在伯仲之间;在聚合查询操作上,TDengine 最快,HolliTSDB 的速度和 InfluxDB 相当,OpenTSDB 最慢。同时,InfluxDB 只能单机部署,集群版本并未开源,且查询性能存在瓶颈,其 QPS 约为 30-50。”
业务背景
在物联网场景下,面对庞大的时序数据处理需求,Oracle、PostgreSQL 等传统关系型数据库越来越吃力,因此和利时开始进行时序数据库的选型,对包括 InfluxDB、OpenTSDB、HolliTSDB(和利时自研时序数据库)和 TDengine 在内的四款时序数据库进行了选型调研及相关测试。测试结果显示,在同等条件下,TDengine 在查询、存储等方面均优于其他几款数据库,最终和利时决定接入 TDengine,以享受更多元的本地化支持和响应。
架构图
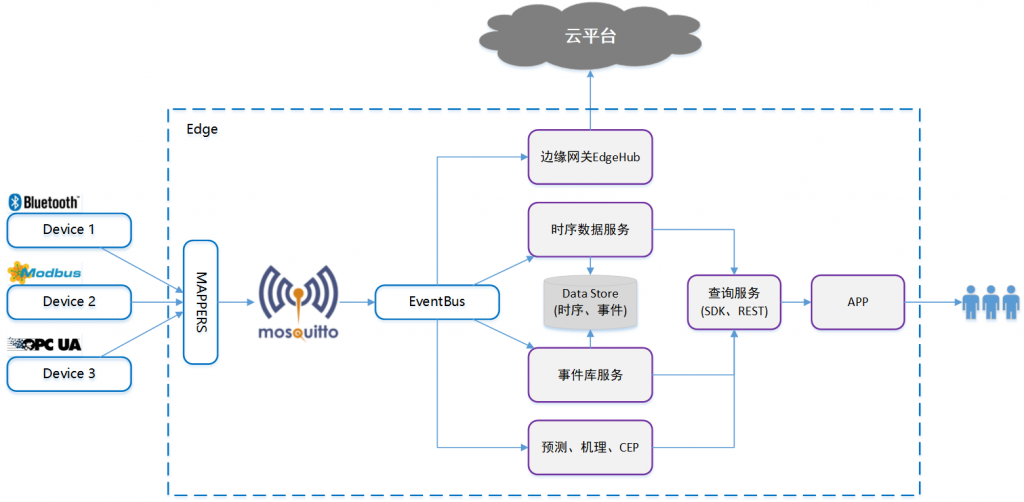
点击案例查看更多技术细节
结语
从以上案例中不难看出,在工业互联网场景下,面对庞大的时序数据处理需求,专业的时序数据库显然比传统的关系型数据库效果更加明显,上述企业案例在架构改造之后,确实达到了更高程度的降本增效。如果你有同样的困扰,欢迎添加小T微信,可以邀请你进入TDengine 用户交流群,和专业的解决方案架构师点对点沟通。
想了解更多TDengine Database的具体细节,欢迎大家在GitHub上查看相关源代码。