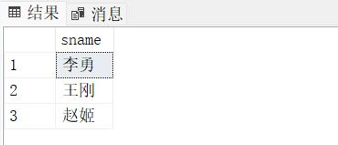
链表是一种物理存储结构上非连续,非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的
链表可分为:单链表和双链表,带头结点的链表和不带头结点的链表,循环链表和非循环链表
为了表示每个元素与其后一个元素直接的逻辑关系,每个元素除了存储本身的信息外,还需要存储一个其指向直接后继的信息,这两部分信息组成数据元素,称为结点,其包括两个域,存储数据元素信息的域我们称为数据域,存储直接后继存储位置的域称为指针域。
下图为一个单链表的结构
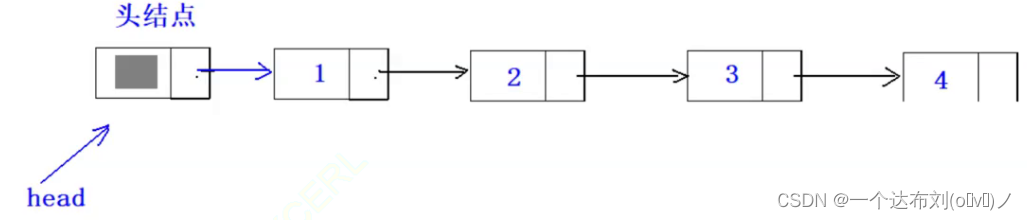
带头结点:
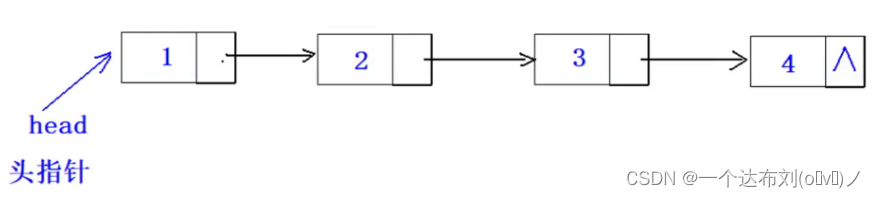
不带头结点:
头结点:在第一个链表之前附设的一个结点,该结点一般不存数据,next指向第一个结点,head指向第一个不存数据的结点
那么其有什么作用呢
假设我们用1-10来创建一个单链表,分别带头结点和不带头结点
创建一个带头结点的链表,头插法(示例)
void CreateList_Head(SList* phead)
{
//申请第一个结点
*phead = (SListNode*)malloc(sizeof(SListNode));
(*phead)->data = 1;
(*phead)->next = NULL;
for (int i = 2; i <= 10; i++)
{
SListNode* s = (SListNode*)malloc(sizeof(SListNode));
s->data = i;
s->next = *phead;
*phead = s;
}
}创建一个不带头结点的链表(示例)
void CreateList_Head(List phead)
{
for (int i = 1; i <= 10; i++)
{
ListNode* s = (ListNode*)malloc(sizeof(ListNode));
s->data = i;
s->next = phead->next;
phead->next = s;
}
}我们可以看到:不带头结点链表创建时需要特殊处理第一个结点,因为当我们头插法插入数据时,我们要时时修改头指针。
在现实中我们经常会用不带头结点的单链表




](https://img-blog.csdnimg.cn/img_convert/914a48b3530bdee084a8a9f3fe95c50a.png)