文章目录
- 现象引入
- 进程地址空间
- 进程地址空间的描述
- 进程地址空间是怎么产生的
- 进程地址空间的好处
- 对开篇问题的解释
现象引入
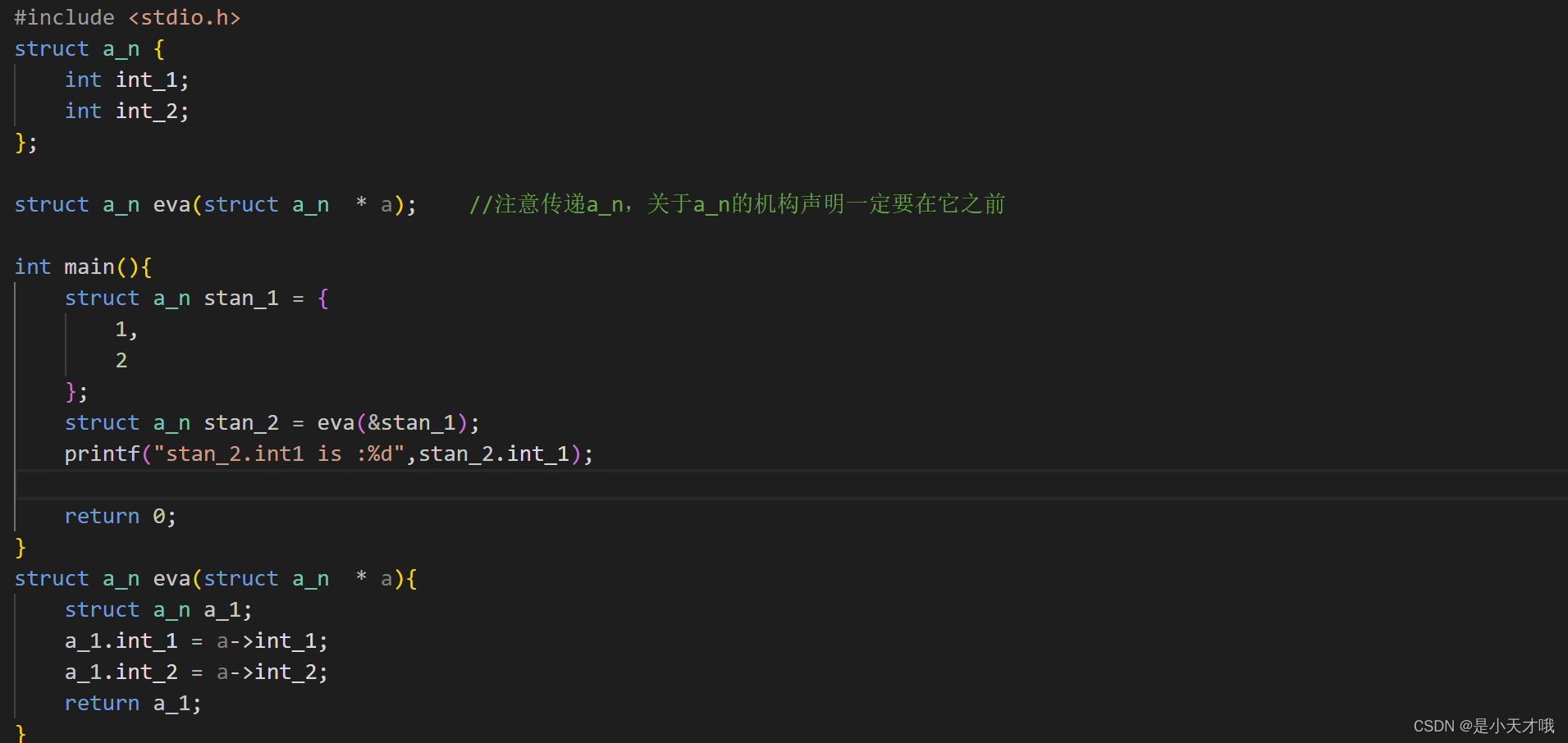
我们运行下面一段代码:
#include <stdio.h>
#include <unistd.h>
int global_val = 100;
int main()
{
pid_t id = fork();
int count = 0;
if (id == 0)
{
while (1)
{
printf("我是子进程, global_val=%d, &global_val=%p\n", global_val, &global_val);
sleep(1);
count++;
if (count == 6)
{
global_val = 200;
printf("global_val已修改\n");
}
}
}
else if (id < 0)
{
perror("fork");
return 1;
}
else
{
while (1)
{
printf("我是父进程, global_val=%d, &global_val=%p\n", global_val, &global_val);
sleep(2);
}
}
}
代码设置了一个全局变量 global_val = 100,
并设置了一个子进程,
子进程运行一段时间后会修改全局变量 global_val = 200,
子进程和父进程都会打印 global_val 和它的地址,
那么修改前后父子进程的打印内容有什么变化呢?
看下面的运行结果:

可以看到,全局变量被子进程修改后,
子进程后续打印的 global_val 就是修改后的值,
而父进程却没有发生变化!
最诡异的是,它们的地址都还一样!
所以由此可见,
这里所谓的地址并不是实实在在的物理地址,即给内存的存储地址编的地址,
而是虚拟地址!
那什么是虚拟地址,为什么要有虚拟地址,虚拟地址和物理地址有什么关系,又有所谓线性地址、逻辑地址,它们又是什么?
下面就对这几个问题进行探讨。
进程地址空间
通过上述现象可以看出,
打印出来的地址是虚拟地址,
实际上,在学习C语言的过程中我们可能有了解过内存分区,
栈区、堆区、静态区、代码区等等…

仔细想一下,如果是采用32位编址方式,
那么能编址的大小范围就是0 ~ 232byte = 4GB,
如果是采用64位编址方式,
那么能编制的大小范围就是0 ~ 264byte = 2147483648GB,
而实际上,我们电脑的内存并不是固定的4GB或2147483648GB(太夸张了)。
同时,因为像声明定义变量、调用函数开辟栈帧、动态内存分配是在进程运行的过程中执行的,
所以像堆区和栈区实际上是在进程运行的过程中才有的,
所以这个所谓的内存分区实际上就是进程地址空间,并且是虚拟的进程地址空间。
并且每个进程都有自己一套独立的地址空间。
进程地址空间的描述
我们知道进程地址空间有代码区、初始化和未初始化数据区、以及栈区堆区什么的…
我们也知道操作系统用进程控制块(PCB)去描述和维护进程,
那进程的地址空间应该也要维护起来,
所以进程控制块中应该还有描述进程地址空间的结构。
而怎样以一种较为简单的方式描述进程地址空间呢?
小时候上学的时候书桌都是两个人用一张的那种,
调皮的同桌经常会在桌上画一个线说不能越过这根线,
所以这根线就将空间分成了两块,
一块是我的,一块是他的。
假设桌子长一米,分割线在桌子中间,
那么就可以规定[0, 50cm]是我的空间,[50, 100cm]是同桌的空间,
如此便完成了课桌空间的规划。
所以对于一块4GB的空间,
我们同样可以用begin和end来划分空间:
struct mm_struct
{
//uint_32_t就是32位无符号整型,正好符合32位编址,本质就是unsigned_int
uint_32_t code_start, code_end; //用来记录代码区的开始和结束
uint_32_t data_start, data_end; //用来记录数据区的开始和结束
uint_32_t heap_start, heap_end;
uint_32_t stack_start, stack_end;
//...
}
实际上mm_struct是linux内核中实实在在的一个结构类型,
是进程控制块task_struct的一个成员。
进程地址空间是怎么产生的
我们写了一份C语言代码,
然后预编译、编译、链接形成可执行程序,
可执行程序加载到内存中成为进程,
从而有了一份进程地址空间。
但是进程地址空间是凭空产生的吗?
思考一下,
C语言代码在链接的过程中会有函数调用、第三方库调用等一系列操作,
那在调库或调用函数的时候编译器是怎么找到目标对象在哪呢?
实际上,我们的代码在编译的过程中就已经有了一套地址,
而这套地址就是所谓的逻辑的地址。
所以在硬盘里存放的可执行程序已经自带了一套地址,
在可执行程序加载到内存中成为进程的时候,
这套自带的地址就变成了一套进程的虚拟地址,
在linux下经过算法处理最终在mm_struct中存放。
最终通过一种名为页表的数据结构实现由虚拟地址到物理地址的映射。
进程地址空间的好处
让每个进程拥有了相同的、独立内存空间,相互之间不会干扰。
就比如一开始的那个例子,
一个地址看似存放了两个值,
实际上是父子进程两套不同的虚拟地址,
只不过是一个相同的地址值映射到了不同的物理地址。
另外,想象一下(以下纯属个人瞎扯),
如果每个进程都有一套虚拟地址,
那么每个进程都不需要考虑占用其他进程的空间,
在进程看来,内存空间的空间全部都是自己的,
内存地址都是连续的,使用起来更加方便,
至于映射不连续的物理地址的事情就都交给页表去做就好了。
读写内存更安全。由于系统和页表的限制,使得进程无法操作到其他进程的数据。
很好理解,如果一个进程能随意去访问物理地址,
会是一件很危险的事情。
比如有一个进程会存放我们登陆时输入的账号密码信息,
这时另一个进程突然来访问,
我们的信息不就被盗走了嘛。
对于逻辑地址或虚拟地址有32位或64位的编址方式,
不止是操作系统在管理进程或进程空间的时候会遵守这个规则,
实际上编译器在编译代码的时候也遵循这个规则,
而且是通用的规则,
所以程序中已经存在的逻辑地址可以很方便地转化为进程虚拟,
这样使得整个过程更加方便统一。
对开篇问题的解释
32位编址方式下每个进程都能拿到4GB的虚拟空间,
其中0~3GB是用户空间,存放代码、数据等等,
因为要保证进程的独立性,所以各个进程的映射是独立的;
3~4GB是内核空间,由于只有一个操作系统,
内核空间主要是共用的机器指令、操作系统内核的各个模块等,
因此每个进程的映射方式一样。
当fork创建子进程时,
在创建阶段由于父子进程的代码和数据都是一样的,
所以对子进程只需要给它分配新的内存块和内核数据结构,
将父进程的部分数据拷贝给它,包括父进程的页表数据!
所以在创建完子进程之后,
它的所有代码和数据都是和父进程共享的!
这也解释了为什么同一个变量在父子进程中有相同的地址,
本质是子进程继承了父进程的虚拟地址空间。
但是一旦父子进程要对数据进行写入,
为了保证进程的独立性,
你对你的旧数据写入不能影响我的旧数据,
此时就会发生写时拷贝,
在物理内存上分配一小块空间拷贝旧数据,
然后对新空间上的旧数据进行写入,
页表修改对应的映射关系,
此时两个进程中两个相同的虚拟地址就映射到了两个不同的物理地址。
修改前:

修改后: