目录
- 什么是HTTP协议?
- 协议格式
- 如何看到HTTP的报文格式?
- HTTP请求
- HTTP响应
- URL
- URL encode/decode
什么是HTTP协议?
计算机网络,核心概念,网络协议
网络协议种类非常多,其中一些耳熟能详的,IP,TCP,UDP…其中还有一个应用非常广泛的协议,HTTP
HTTP 处于 TCP/IP五层协议栈的应用层~
HTTP在传输层是基于TCP的~( 不够严谨,HTTP/1 HTTP/2 是基于TCP,最新版本HTTP/3是基于UDP的,但是当下互联网绝大部分使用的HTTP都是HTTP/1.1 )
传输层协议,主要关注的是 端对端 之间的数据传输,TCP,重点关注的是可靠传输
应用层协议,则是站在程序应用的角度,要对传输的数据,来进行具体的使用~
HTTP ( 全称为 " 超文本传输协议 ") 是一种应用非常广泛的 **应用层协议**。
所谓 "超文本" 的含义, 就是传输的内容不仅仅是文本(比如 html, css 这个就是文本), 还可以是一些
其他的资源, 比如图片, 视频, 音频等二进制的数据。
HTTP虽然是已经设计好的,自身的扩展性非常强,可以根据实际需要,让程序员传输各种自定义的数据信息~
HTTP具体的应用场景:天天都在用~
只要你打开浏览器,随便打开一个网站,这个时候就用到了HTTP,或者打开一个手机APP,随便加载一些数据,这个时候其实大概率就用到了HTTP。
协议格式
协议格式:数据具体是怎么组织的。
之前学习过UDP:报头(源端口,目的端口,长度,校验和)+载荷。
UDP/TCP/IP这些协议都是属于“二进制”的协议,经常要理解到二进制的bit位~
HTTP 则是一个文本格式的协议。(不需要去理解具体的二进制位,而只是理解文本的格式即可)
如何看到HTTP的报文格式?
其实可以借助一些“抓包工具”来获取具体的HTTP交互过程中,请求和响应。
抓包工具,其实就是一个第三方的程序,在网络通信的过程中,类似于一个”代理“一样。
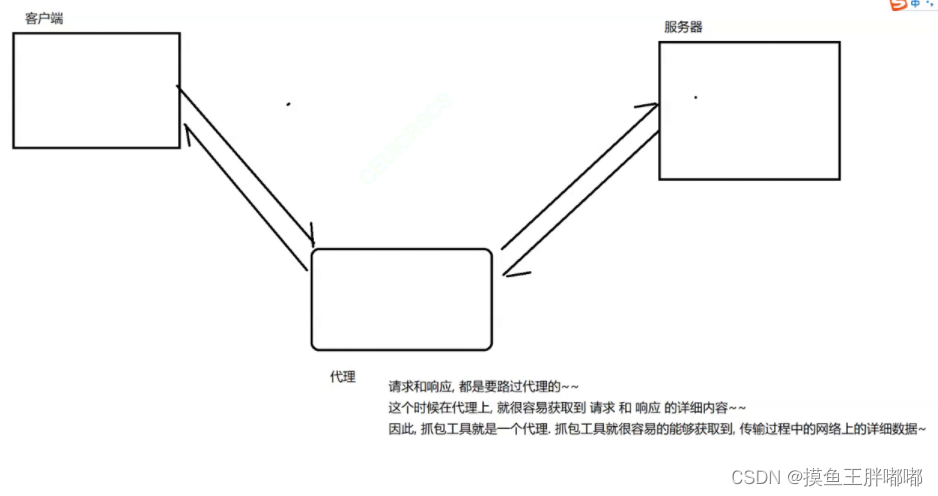
我们使用Fiddler 抓包 下载地址:Fiddler下载链接


安装下载之后的界面就是这样的

Fiddler左侧,是一个列表,显示了当前抓到的HTTP/HTTPS的数据报。
当选中左侧列表某个条目,并双击的时候,右侧就会显示详细信息。
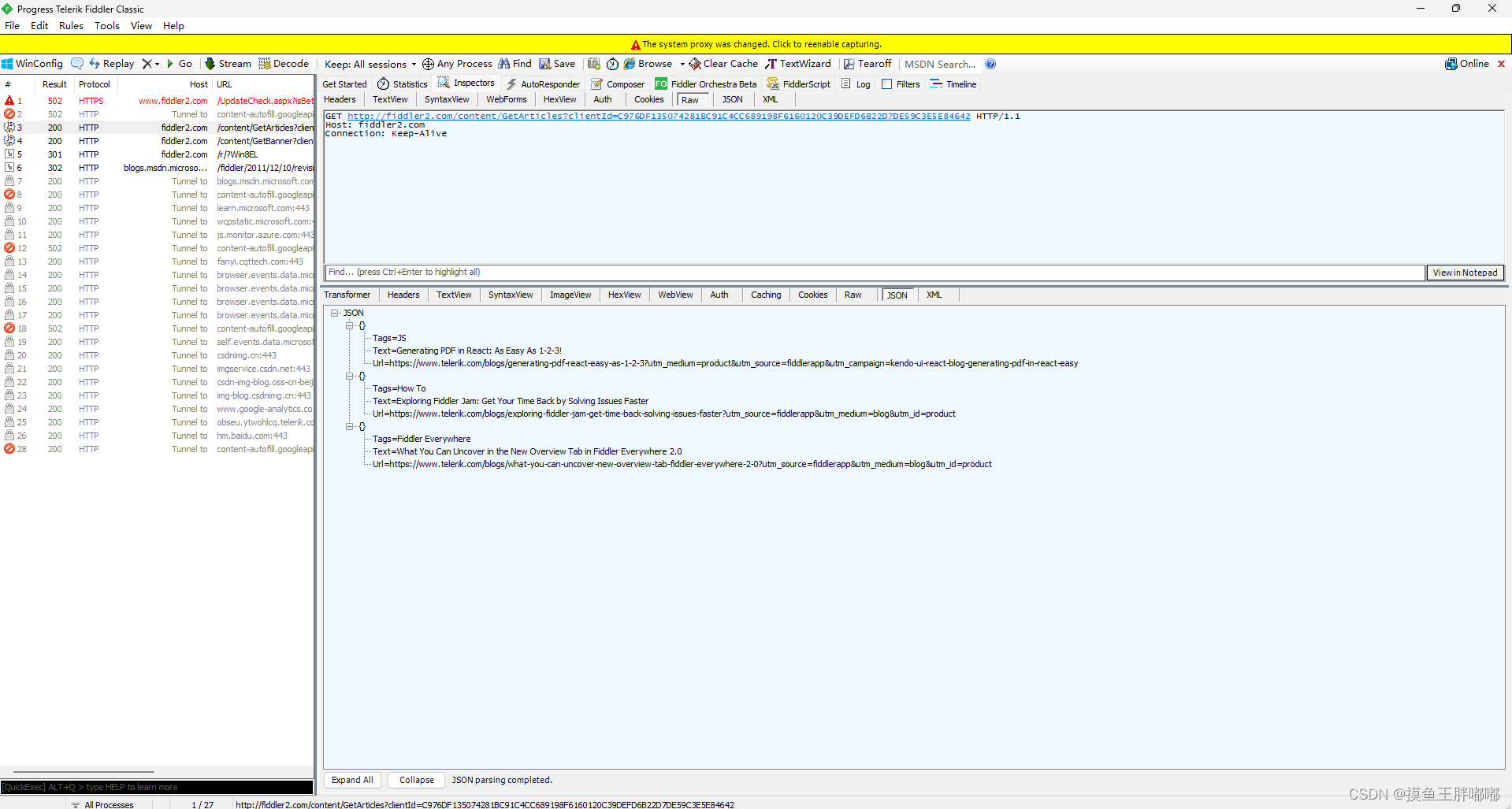
这个标签页的选项,就表示了当前使用啥样的格式来显示 HTTP 请求;咱们用的最多的就是 Raw 这个选项;
选择 Raw 看到的就是 HTTP 请求数据的本体;选择其他的选项相当于 Fiddler 对数据进行了一些加工 调整了格式;
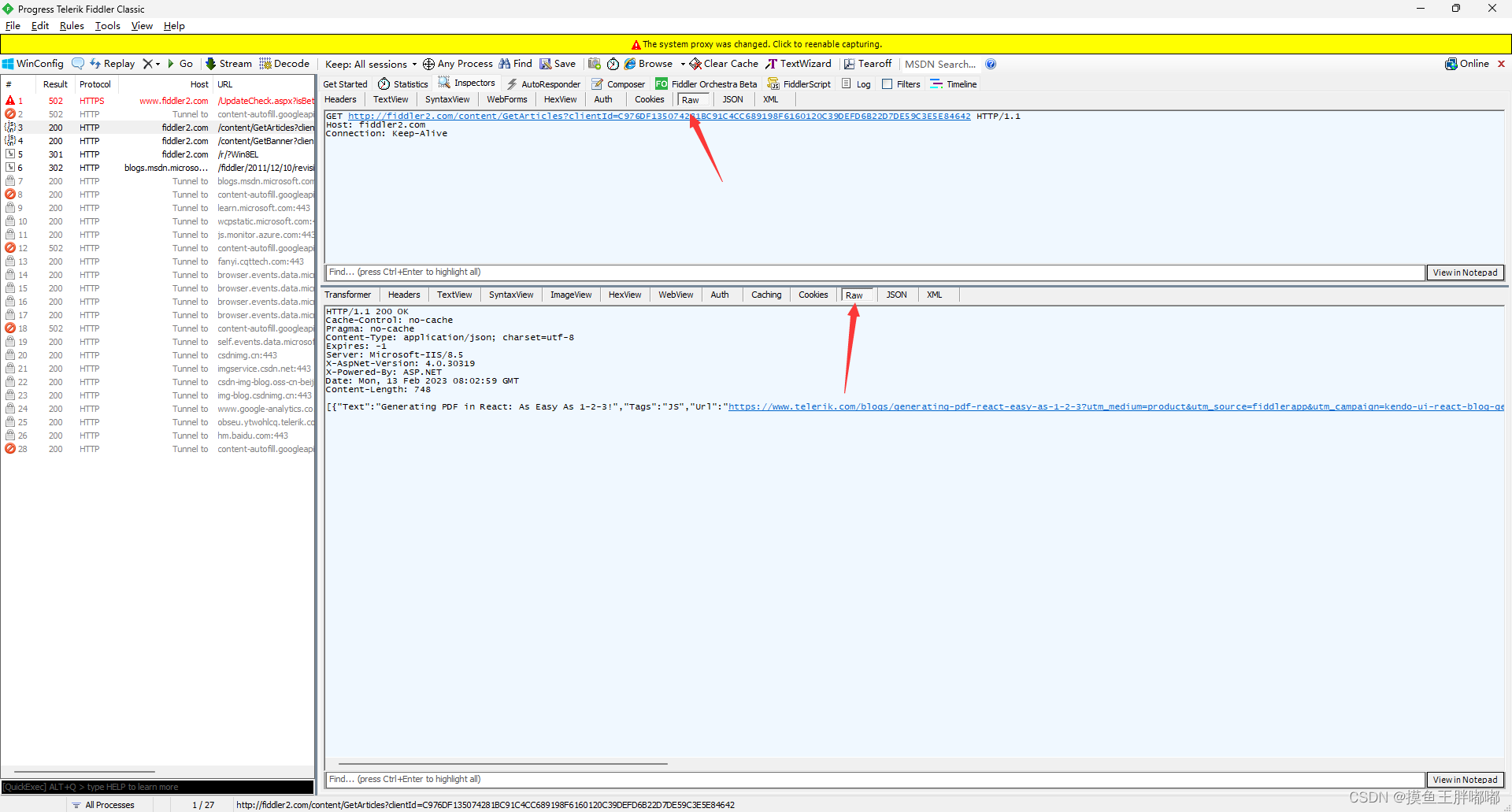
我们可以点击这里的view in notepad查看原始数据;

如果出现下列情况:

这是因为Fiddler 刚安装好的时候,默认没有启用 HTTPS;如果你抓到了 HTTPS 的包,就会出现类似的情况;当下网络上的大部分的网站都是 HTTPS;如果不开启 HTTPS,其实就基本没啥可抓的,所以我们可以允许fiddler启动https;
首先我们打开fiddler,按照下图的箭头依次勾选,然后点击OK;
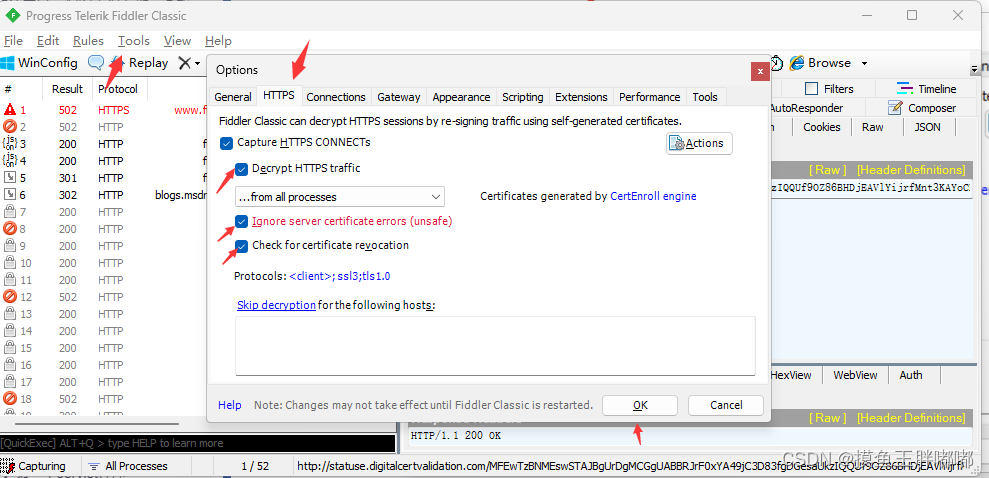
可能会出现fiddler要求安装xx证书,一定要点是!!
Fiddler作为一个代理,是和其他的代理程序冲突的,如果也安装了其他的代理程序/插件,就可能导致Fiddler失效
HTTP请求


请求分成4个部分:
- 请求行(首行),包括三个部分
a)HTTP的方法,方法大概描述了这个请求想干啥~~ GET 意思是想从服务器获取到某个东西
b)URL 描述了要访问的网络上的资源具体在哪~
c)版本号,HTTP/1.1表示当前使用的HTTP版本是1.1 - 请求头(head) 包含了很多行
每一行都是一个键值对
键和值之间使用:空格来分割~
这里的键值对的数目是不固定的,不同的键值对表示不同的含义; - 空行
相当于请求头结束的标记!类似于链表的null一样。 - 请求正文(body)不一定有,可选;
Fiddler使用技巧;
我们在使用fiddler的时候,经常看到左侧会抓取很多的包,我们不知道如何选择哪一个是我们需要的,这里教大家一个技巧,我们可以选中左侧的某一行,然后Ctrl+A全选,点电脑上的Del键,把抓包信息全部删除,再去进行我们需要的操作,然后再点击到fiddler这里,即可观察到我们一个操作对应的fiddler抓包信息;
HTTP响应


注意响应分成四个部分;
- 首行,包含了3个部分
a)版本号——http1.1
b)200 状态码,描述了这个响应表示一个成功的还是失败的;这里200表示成功;
c)OK状态码的描述,通过一个/组简单的单词,来描述当前状态码的含义; - 响应头(header)
也是键值对结构,依然是每个键值对占一行,每个键和值之间使用空格来分割; - 空行
表示响应头结束的标记; - 响应正文(body)
服务器返回给客户端的数据,这里的数据可能是不同的格式,最常见的是html形式。
URL
含义就是“网络上唯一资源地址符”,既要明确哪个主机,又要明确主机上哪个资源;
https://www.baidu.com/s?ie=utf-8&tn=85070231_18_hao_pg&wd=fiddler
这串也就是URL,通过浏览器打开网页的时候,地址栏填写的网址就是URL。

这是一个总结,URL都要遵守这样一个基本模板。
协议方案名:描述了当前这个URL是给哪个协议来使用的~~
http://给HTTP用的
https:// 给HTTPS用的
jdbc:mysql:// 给jdbc:mysql用的
登录信息:这个部分现在很少会用到,上古时期上网,会在这里体现用户名密码~
服务器地址: 当前要访问的主机是啥~ 这里可以是一个IP地址,也可以是域名~
服务器端口号 :端口号,表示当前要访问的主机上的哪个应用程序.(这里的端口号大部分情况下是省略的,省略的时候,不是说没有,而是浏览器会给一个默认端口号,对于HTTP开头的URL,就会使用80端口号作为默认值,对于HTTPS开头的URL,就会使用443端口号作为默认值)
带层次的文件路径:描述了当前要访问的服务器资源是啥~虽然请求的URL中,写的是一个文件路径,但是不一定服务器上就真存在一个对应的文件,这个文件可能是一个真实的,在磁盘上存在的文件,也可能是虚拟的,由服务器代码,构造出的一个动态数据
查询字符串:本质上是浏览器/客户端,给服务器传递的自定义信息~相当于对获取到的资源提出了进一步的要求
片段标识符:描述了要访问当前html页面中哪个具体的子部分,能够控制浏览器滚动到相应位置
上述的IP地址+端口+带层次的文件路径其实就描述了一个网络上具体的资源
但是在这个基础上,还可以携带一些其他的要求,也就是后面的参数
URL 总结:
对于 URL 来说,里面的结构看起来比较复杂,其实最重要的,和开发最关系紧密的,主要就是四个部分:
1、ip 地址/域名;
2、端口号(常省略);
3、带层次结构的路径;
4、query string 查询字符串;
URL encode/decode
当query string 中如果包含了特殊字符,就需要对特殊字符进行转义~
这个转义的过程,就叫做 url encode 反之,把转义的内容还原回来,就叫做url decode
url里面有很多特殊含义的符号的
/ : ? $ = …这些符号都在URL中具有特殊含义的~万一,query string里也包含这类特殊符号,就可以导致URL被解析失败!!

这个%2B%2B的在干嘛?骂人嘛?那肯定不是!
这个键值对 %2B%2B 其实就是通过URL encode转义之后得到的结果;字符 + 的ASCII的十六进制的表示就是2B,按照URL encode转义的规则在这个字符前加上%,就是现在这样的 %2B%2B;





![[carla]关于odometry坐标中的角度坐标系 以及 到地图的映射问题](https://img-blog.csdnimg.cn/37dc4120f1f34e61a77e6a6c130a8c73.png)
![替换子串得到平衡字符串[map计数+滑动窗口]](https://img-blog.csdnimg.cn/3ff74f1b456b4a1897bc22d34bec6da0.png)