接 https://blog.csdn.net/oracle8090/article/details/129013345?spm=1001.2014.3001.5502
通过上一节知道 总字节数为7 每个分区字节数为3
代码
val conf: SparkConf = new SparkConf().setMaster("local").setAppName("wordcount")
val sc: SparkContext = new SparkContext(conf)
val rdd: RDD[String] = sc.textFile("datas/1.txt",2)
rdd.saveAsTextFile("output")

通过运营最终得到的输出文件为:
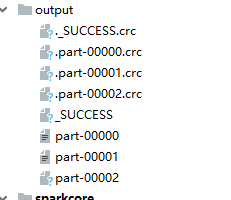
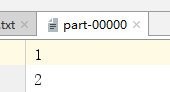
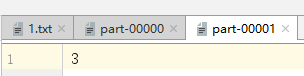
part-00002为空文件
1.spark读取文件采用的是Hadoop方式读取,所以一行一行读取,跟字节数没有关系
2.数据读取时以偏移量为单位,偏移量不会被重新读取
/*数据(回车占两字符)=》偏移量
1@@ =>0 1 2
2@@ =>3 4 5
3 =>6
*/
3 数据分区的偏移量范围
0号分区 =>[0,3]=>1 2 偏移量是0-3 读取1@@ 2,但是以行为单位读取最终读取的为1@@,2@@,因此第一个分区文件分配的数字为1 2
1号分区 =>[3,6] => 3 偏移量是3-6 但是3 4 5 偏移量已经被0号分区读取过了,因此第二个分区文件分配的数字为3
2号分区 =>[6,7]