GPDB中的HASH JOIN机制
Hash Join是利用hash函数来实现和加速数据库中JOIN操作的一类算法。主要优势是hash函数可以只通过一次运算就将键值映射到固定大小的hash值,仅用作等值join中。由于HASH JOIN的算法复杂度在平均情况下是O(n),所以通常在大规模数据时做HASH JOIN是不错的选择。
下面我们看下GPDB是如何实现HASH JOIN的。
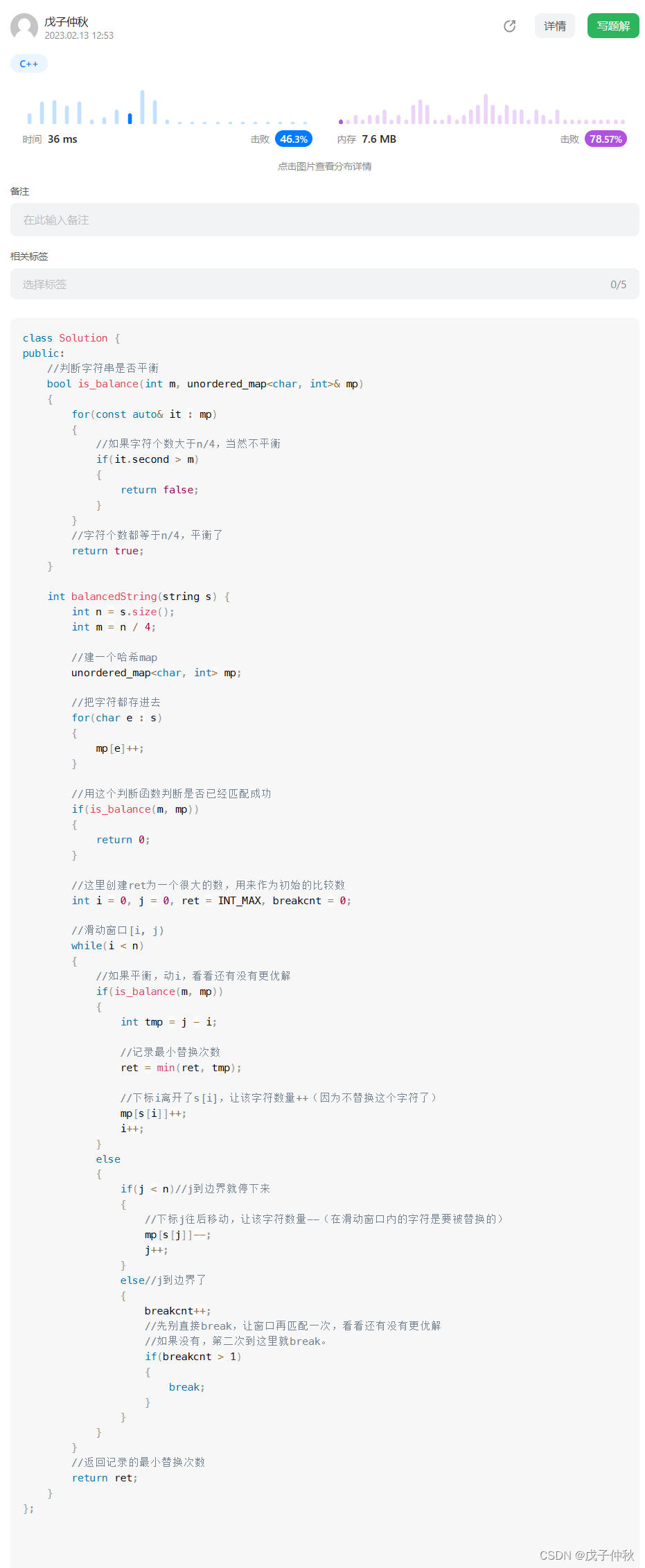
1、Hash join相关结构体关系
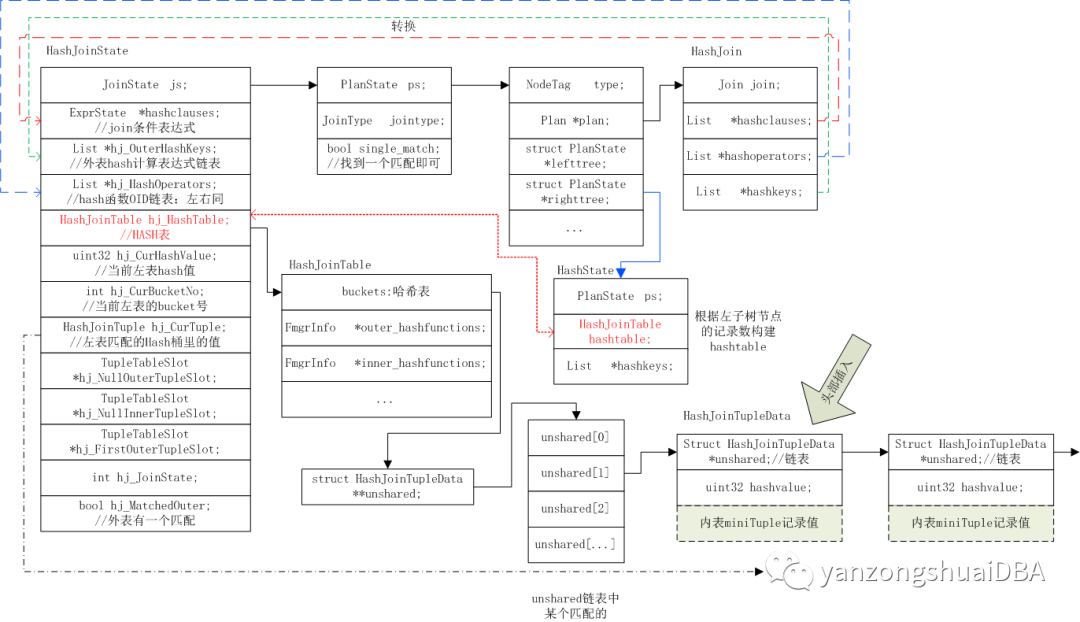
HashJoin操作通过HashJoinState结构体管理执行状态及需要的一些结构。下面是HashJoinState结构体说明:
1)JoinState js
执行计划树节点,该结构主要包括PlanState ps、jointype和single_match。他的左右子节点由PlanState进行管理。如上图中,hash表的构建需要知道大小,这个大小值就是通过右节点也就是内表的执行计划节点预估表行数计算得到。右节点即HashState节点,比如简单inner join情况下:右节点是HashState,HashState的左节点是SeqScan即顺序扫描,表示内表扫描的数据构建hash表。
2)HashJoinTable hj_HashTable
Hash join需要的hash表,和HashState中的hashtable相同。
3)ExprState *hashclauses
Join条件的表达式。通过该表达式完成JOIN条件匹配。该表达式由HashJoin中的hashclauses链表初始化生成。
4)List *hj_OuterHashKeys
外表hash计算表达式链表。通过HashJoin中的hashkeys链表生成。
5)List *hj_HashOperators
Hash函数的OID链表,内外表相同
6)hj_CurHashValue
当前外表的hash值,用于探测阶段进行匹配。
7)hj_CurTuple
外表匹配的hash桶里的值。8)hj_JoinState
Join操作状态机。执行过程中,通过该状态机进行处理。
2、以inner join为例说明
理解上面的结构体关系后,对hash join处理机制的理解就方便多了。下面我们以inner join为例进行简单说明。
1)HASH join的执行入口函数为ExecHashJoin,调用ExecHashJoinImpl通过状态机进行操作
2)首先进入HJ_BUILD_HASHTABLE阶段,即构建HASH表阶段
(1)先扫描外表,若外表是空,则无需继续,直接返回NULL
(2)调用函数ExecHashTableCreate创建hash表,该函数会通过HashJoinState中的左子树的Hash Plan得到其左子树也就是SeqScan内表的Plan节点,利用plan_width和预估的plan_rows计算hash表大小,并创建hash表。
(3)创建hash表过程中根据hj_HashOperators链表即OID链表,对每个hash key需要的hash函数进行初始化。内外表的hash函数相同,即hashtable->outer_hashfunctions[]和hashtable->inner_hashfunctions[]相同
(4)创建了hash表,接着就需要执行MultiExecProcNode->MultiExecHash-> MultiExecPrivateHash扫描内表,将扫描出的内表行通过ExecHashTableInsert函数计算出hash值并构建HashJoinTuple,将其插入hash表中
3)然后进入HJ_NEED_NEW_OUTER状态
(1)通过函数ExecHashJoinOuterGetTuple获取外表一行数据outerTupleSlot并计算出hash值hashvalue
(2)通过函数ExecHashGetBucketAndBatch根据获取的hashvalue得到哈希桶号及batch号:hj_CurBucketNo和batchno
4)接着进入HJ_SCAN_BUCKET状态
(1)通过函数ExecScanHashBucket进行匹配探测:先判断外表值的hashvalue值是否对应,然后再判断join条件是否符合。将符合join条件的HashJoinTuple保存到hj_CurTuple中。
(2)调用函数ExecProject对符合join条件的记录进行投影并输出
(3)再次进入函数时,仍旧是HJ_SCAN_BUCKET状态,扫描外表下一条记录,并进行JOIN条件判断,直至外表数据join完。