PhysioNet2017数据集介绍可参考文章:https://wendy.blog.csdn.net/article/details/128686196。本文主要介绍利用PhysioNet2017数据集对其进行分类的代码实现。
目录
- 一、数据集预处理
- 二、训练
- 2.1 导入数据集并进行数据裁剪
- 2.2 划分训练集、验证集和测试集
- 2.3 设置训练网络和结构
- 2.4 开始训练
- 2.5 查看训练结果
- 三、测试
一、数据集预处理
首先需要进行数据集预处理。
train2017文件夹中存放相应的训练集,其中REFERENCE.csv文件存放分类结果。分类结果有四种,分别是:N(Normal,正常),A(AF,心房颤动),O(Other,其他节律),~(Noisy,噪声记录)。
首先需要划分训练集、验证集和测试集:
# 加载数据集,默认80%训练集和20%测试集
def load_physionet(dir_path, test=0.2,vali=0, shuffle=True):
"return train_X, train_y, test_X, test_y, valid_X, valid_y"
if dir_path[-1]!='/': dir_path = dir_path+'/'
ref = pd.read_csv(dir_path+'REFERENCE.csv',header=None) # 分类结果
label_id = {'N':0, 'A':1, 'O':2, '~':3 }#Normal, AF, Other, Noisy
X = []
y = []
test_X = None
test_y = None
valid_X = None
valid_y = None
for index, row in ref.iterrows():
file_prefix = row[0]
mat_file = dir_path+file_prefix+'.mat'
hea_file = dir_path+file_prefix+'.hea'
data = loadmat(mat_file)['val']
data = data.squeeze()
data = np.nan_to_num(data)
data = data-np.mean(data)
data = data/np.std(data)
X.append( data )
y.append( label_id[row[1]] )
data_n = len(y)
print(data_n)
X = np.array(X)
y = np.array(y)
if shuffle:
shuffle_idx = list(range(data_n))
random.shuffle(shuffle_idx)
X = X[shuffle_idx]
y = y[shuffle_idx]
valid_n = int(vali*data_n)
test_n = int(test*data_n)
assert (valid_n+test_n <= data_n) , "Dataset has no enough samples!"
if vali>0:
valid_X = X[0:valid_n]
valid_y = y[0:valid_n]
if test>0:
test_X = X[valid_n: valid_n+test_n]
test_y = y[valid_n: valid_n+test_n]
if vali>0 or test>0:
X = X[valid_n+test_n: ]
y = y[valid_n+test_n: ]
#print('Train: %d, Test: %d, Validation: %d (%s)'%((data_n-valid_n-test_n), test_n, valid_n, 'shuffled' if shuffle else 'unshuffled'))
return np.squeeze(X), np.squeeze(y), np.squeeze(test_X), np.squeeze(test_y), np.squeeze(valid_X), np.squeeze(valid_y)
加载数据集并将其保存为mat文件:
def merge_data(dir_path, test=0.2, train_file='train',test_file='test',shuffle=True):
train_X, train_y, test_X, test_y, _, _ = load_physionet(dir_path=dir_path, test=test, vali=0, shuffle=True) # 划分训练集、验证集和测试集
# 数据集8528个记录 8528*0.8=6823,8528*0.2=1705
train_data = {'data': train_X, 'label':train_y} # 6823
test_data = {'data': test_X, 'label':test_y} # 1705
# 保存训练集和测试集为mat文件
savemat(train_file,train_data)
savemat(test_file, test_data)
print("[!] Train set saved as %s"%(train_file))
print("[!] Test set saved as %s"%(test_file))
def main():
parser = argparse.ArgumentParser()
parser.add_argument('--dir',type=str,default='training2017',help='the directory of dataset')
parser.add_argument('--test_set',type=float,default=0.2,help='The percentage of test set')
args = parser.parse_args()
merge_data(args.dir, test=args.test_set)
if __name__=='__main__':
main()
运行之后将PhysioNet2017心电图数据集保存为train.mat和test.mat。

二、训练
2.1 导入数据集并进行数据裁剪
时序数据都需要进行相应的数据裁剪。裁剪函数如下:
def cut_and_pad(X, cut_size):
n = len(X)
X_cut = np.zeros(shape=(n, cut_size)) # (6823,300*30)
for i in range(n):
data_len = X[i].squeeze().shape[0] # 每个数据的长度
# cut if too long / padd if too short
X_cut[i, :min(cut_size, data_len)] = X[i][0, :min(cut_size, data_len)] # 每个长度裁剪为cut_size=9000个
return X_cut
首先需要将处理后的数据集导入并进行数据裁剪。
训练集的数据尺寸为:(1, 6823);训练集的标签尺寸为:(1, 6823);【总数据量为8528个数据,训练集数据占比80%,即8528*80%=6823】
加载训练集train.mat,进行数据裁剪,裁剪长度为300x30=9000,即前9000个数据。代码如下:
training_set = loadmat('train.mat') # 加载训练集
X = training_set['data'][0]
y = training_set['label'][0].astype('int32')
#cut_size_start = 300 * 3
cut_size = 300 * 30
X = cut_and_pad(X, cut_size)
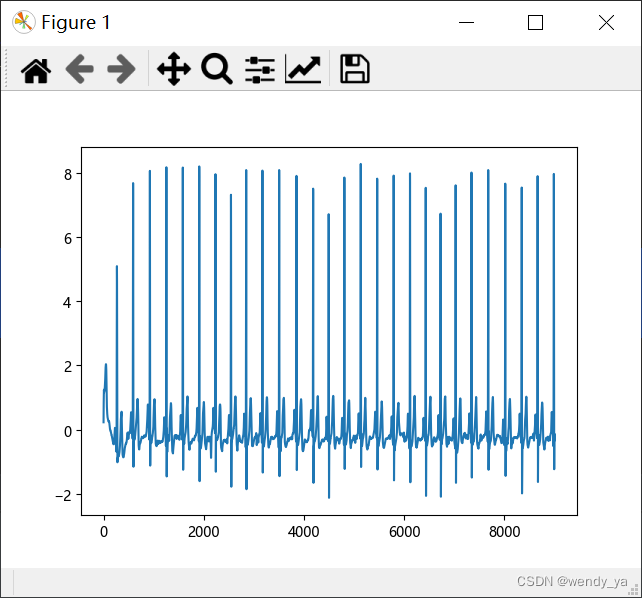
裁剪后可以查看第一个数据的图像:
代码如下:
import matplotlib.pyplot as plt
plt.plot(range(cut_size),X[0])
plt.show()
效果图如下:
2.2 划分训练集、验证集和测试集
首先需要判断是否进行k折交叉验证,若进行k折交叉验证,下界为0上界为5(5折);若不进行k折交叉验证则下界为0上界为1(默认不进行交叉验证)。
# k-fold / train
if args.k_folder:
low_border = 0
high_border = 5
F1_valid = np.zeros(5)
else:
low_border = 0
high_border = 1
然后利用get_sub_set函数根据是否进行交叉验证划分训练集和验证集,90%为训练集,10%为验证集。
# 划分训练集和验证集
def get_sub_set(X, y, k, K_folder_or_not):
if not K_folder_or_not: # False
k_dataset_len = int(len(X) * 0.9) # 6823*0.9=6140
train_X = X[ : k_dataset_len] # 6140
train_y = y[ : k_dataset_len]
valid_X = X[ k_dataset_len:] # 683
valid_y = y[ k_dataset_len:]
else:
k_dataset_len = int(len(X) / 5)
if k == 0:
valid_X = X[ : k_dataset_len ]
valid_y = y[ : k_dataset_len ]
train_X = X[ k_dataset_len :]
train_y = y[ k_dataset_len :]
else:
print(k*k_dataset_len)
valid_X = X[ k*k_dataset_len : (k+1)*k_dataset_len ]
valid_y = y[ k*k_dataset_len : (k+1)*k_dataset_len ]
train_X = np.concatenate((X[ : k*k_dataset_len] , X[(k+1)*k_dataset_len: ]), axis=0)
train_y = np.concatenate((y[ : k*k_dataset_len] , y[(k+1)*k_dataset_len: ]), axis=0)
return train_X, train_y, valid_X, valid_y
输出训练集长度和验证集长度查看信息。

2.3 设置训练网络和结构
网络架构利用ResNet实现,损失函数使用交叉熵损失函数softmax_cross_entropy,优化器利用Adam优化器实现。
加载模型时,如果有已经训练好的模型,则恢复模型:Model restored from checkpoints;否则,重新训练模型:Restore failed, training new model!
2.4 开始训练
开始训练代码如下:
# 开始训练
while True:
total_loss = []
ep = ep + 1
for itr in range(0,len(train_X),batch_size):
# prepare data batch
if itr+batch_size>=len(train_X):
cat_n = itr+batch_size-len(train_X)
cat_idx = random.sample(range(len(train_X)),cat_n)
batch_inputs = np.concatenate((train_X[itr:],train_X[cat_idx]),axis=0)
batch_labels = np.concatenate((y_onehot[itr:],y_onehot[cat_idx]),axis=0)
else:
batch_inputs = train_X[itr:itr+batch_size]
batch_labels = y_onehot[itr:itr+batch_size]
_, summary, cur_loss = sess.run([opt, merge, loss], {data_input: batch_inputs, label_input: batch_labels})
total_loss.append(cur_loss)
#if itr % 10==0:
# print(' iter %d, loss = %f'%(itr, cur_loss))
# saver.save(sess, args.ckpt)
# 将所有日志写入文件
summary_writer.add_summary(summary, global_step=ep) # 将训练过程数据保存在summary中[train_loss]
print('[*] epoch %d, average loss = %f'%(ep, np.mean(total_loss)))
if not args.k_folder:
saver.save(sess, 'checkpoints/model')
# validation
if ep % 5 ==0: #and ep!=0:
err = 0
n = np.zeros(class_num)
N = np.zeros(class_num)
correct = np.zeros(class_num)
valid_n = len(valid_X)
for i in range(valid_n):
res = sess.run([logits], {data_input: valid_X[i].reshape(-1, cut_size,1)})
# print(valid_y[i])
# print(res)
predicts = np.argmax(res[0],axis=1)
n[predicts] = n[predicts] + 1
N[valid_y[i]] = N[valid_y[i]] + 1
if predicts[0]!= valid_y[i]:
err+=1
else:
correct[predicts] = correct[predicts] + 1
print("[!] %d validation data, accuracy = %f"%(valid_n, 1.0 * (valid_n - err)/valid_n))
res = 2.0 * correct / (N + n)
print("[!] Normal = %f, Af = %f, Other = %f, Noisy = %f" % (res[0], res[1], res[2], res[3]))
print("[!] F1 accuracy = %f" % np.mean(2.0 * correct / (N + n)))
if args.k_folder:
F1_valid[k] = np.mean(res)
if np.mean(total_loss) < 0.2 and ep % 5 == 0:
# 保存内容
summary_writer.close()
# 将total_loss保存为csv
tl = pd.DataFrame(data=total_loss)
tl.to_csv('loss.csv')
break
2.5 查看训练结果
利用tensorboard可以查看训练的loss损失,损失图像如下:
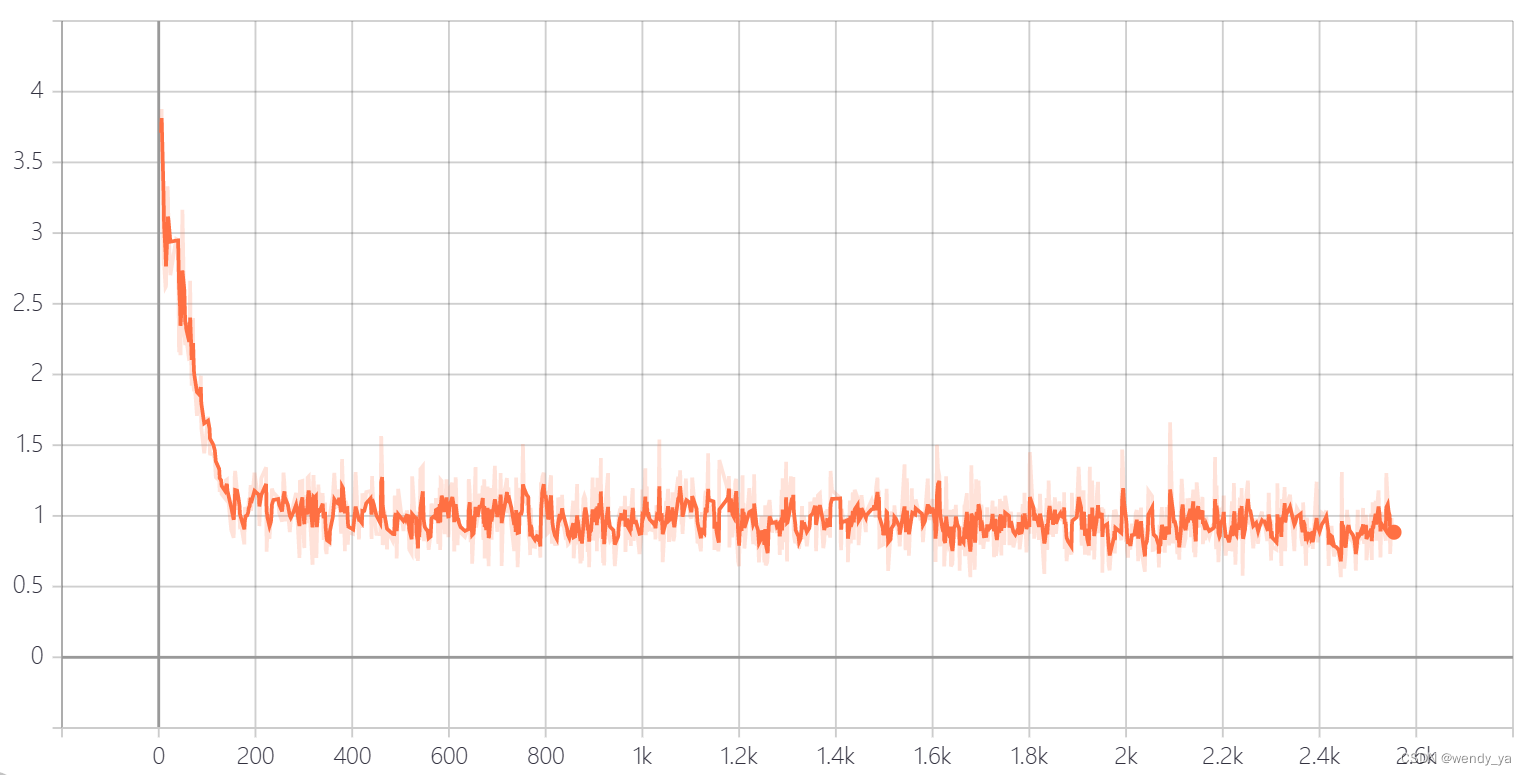
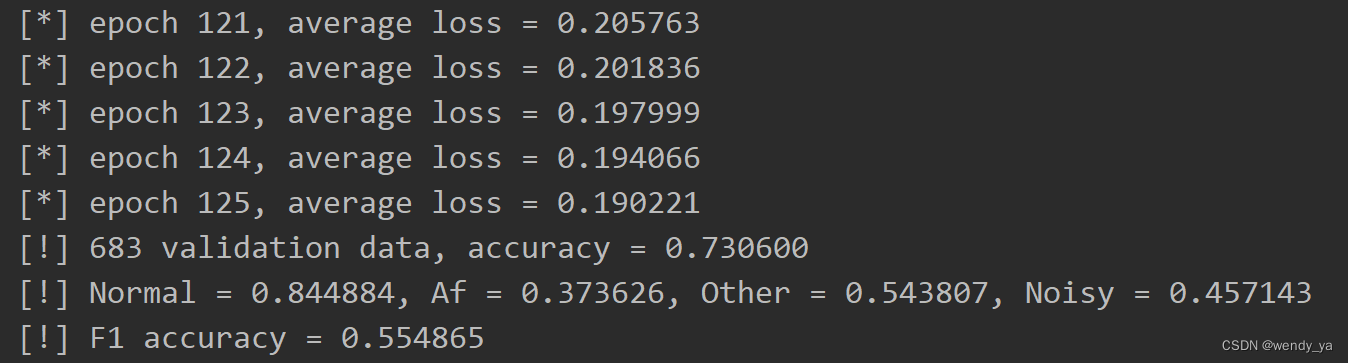
loss阈值设置为0.2,最后的准确率如下:
三、测试
训练完成后,开始测试。
首先需要将处理后的测试集导入并进行数据裁剪。
测试集的数据尺寸为:(1, 1705);测试集的标签尺寸为:(1, 1705);【总数据量为8528个数据,测试集数据占比20%,即8528*20%=1705】
加载测试集test.mat,进行数据裁剪,裁剪长度为300x30=9000,即前9000个数据。代码如下:
training_set = loadmat('test.mat')
X = training_set['data'][0] # (1705,)
y = training_set['label'][0].astype('int32') # (1705,)
cut_size = 300 * 30
n = len(X)
X_cut = np.zeros(shape=(n, cut_size))
for i in range(n):
data_len = X[i].squeeze().shape[0]
X_cut[i, :min(cut_size, data_len)] = X[i][0, :min(cut_size, data_len)]
X = X_cut
然后将数据输入训练好的网络进行测试:
# reconstruct model
test_input = tf.placeholder(dtype='float32',shape=(None,cut_size,1))
res_net = ResNet(test_input, class_num=class_num)
tf_config = tf.ConfigProto()
tf_config.gpu_options.allow_growth = True
sess = tf.Session(config=tf_config)
sess.run(tf.global_variables_initializer())
saver = tf.train.Saver(tf.global_variables())
# restore model
if os.path.exists(args.check_point_folder + '/'):
saver.restore(sess, args.check_point_folder + '/model')
print('Model successfully restore from ' + args.check_point_folder + '/model')
else: print('Restore failed. No model found!')
测试结束后,需要查看测试准确率,F1-score等诸多指标,这里首先需要定义三个变量:
PreCount = np.zeros(class_num) # 每种类型的预测数量
RealCount = np.zeros(class_num) # 每种类型的数量
CorrectCount = np.zeros(class_num) # 每种类型预测正确数量
PreCount用于存放每种类型的预测结果,RealCount用于存放每种类型的数量,CorrectCount用于存放每种类型预测正确的数量。
最后查看所有结果,F1-score、Accuracy,Precision,Recall,Time结果如下:(这是loss为0.2时的结果)
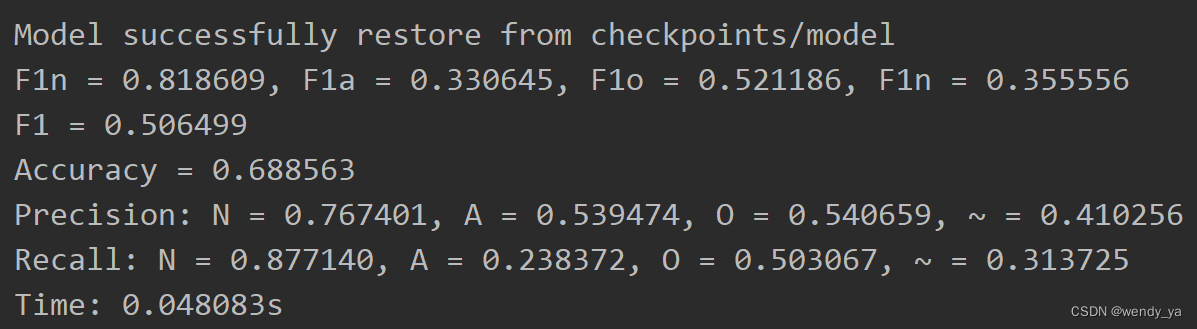
ok,以上便是本文的全部内容了,如果想要获取完整代码,可以参考资源:https://download.csdn.net/download/didi_ya/87444631
;
如果想重新训练,请删除checkpoints文件夹内所有文件和logs文件夹内所有文件(不要删除logs文件夹)并重新运行train.py程序,若不删除,则继续使用之前模型训练,logs文件夹主要用于存放tensorboard可视化图像,若不删除重新运行程序,可能会重新生成可视化图像,影响效果。188行可以指定最终的loss,如果想精确度高,请将loss尽量调小。tensorflow版本:1.x。(我使用的是tensorflow1.15)
遇到任何问题欢迎私信咨询~