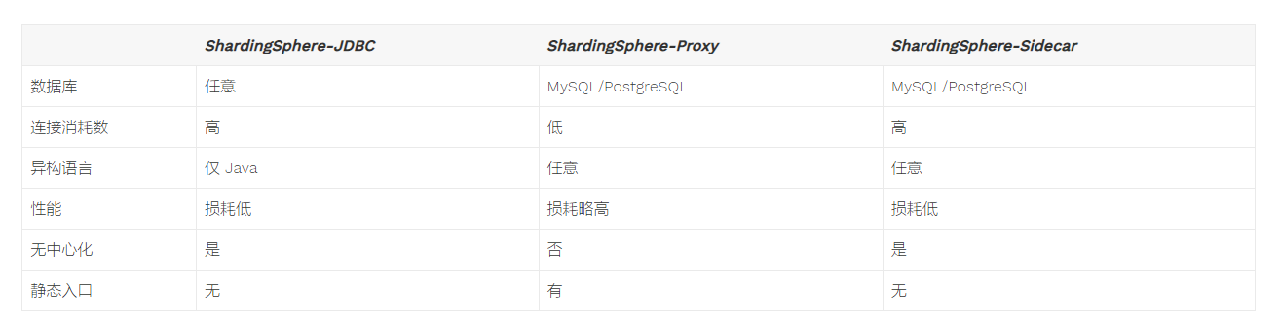
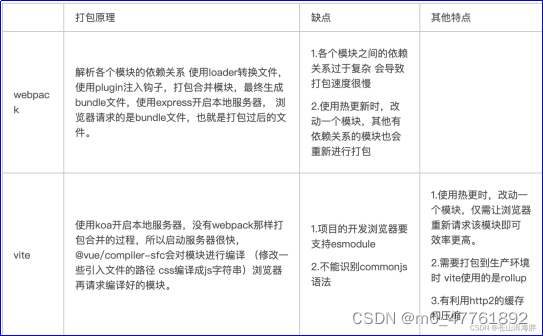
原始代码如下:
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("wordcount")
val sc=new SparkContext(conf)
val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4)
//将处理的数据保存分区文件
rdd.saveAsTextFile("output2")
sc.stop()makeRDD方法可以传第二个参数,这个参数表是分区的数量
第二个参数可以不传递有默认值:defaultParallelism(默认的并行度)
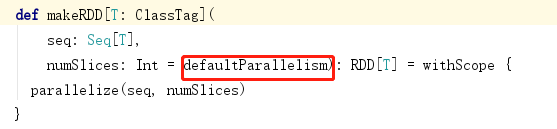
默认的并行度调用的是backend.defaultParallelis()方法

TaskSchedulerImpl.scala

SchedulerBackend.scala

spark在默认情况下,从配置对象中获取配置参数 spark.default.parallelism

// 如果获取不到,那么使用totalCores属性,这个属性是当前运行环境的最大可用核数
按照代码举例,当没有设置parallelism参数时最后执行的结果如图
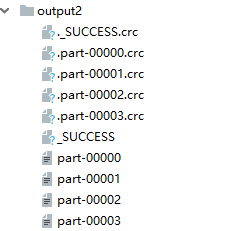
本人处理器

有个问题需要注意一下:
setMaster("local[*]") 使用的是所有的核数
setMaster("local")使用的是单核
总结:
//makeRDD方法可以传第二个参数,这个参数表是分区的数量
//第二个参数可以不传递有默认值:defaultParallelism(默认的并行度)
//默认的并行度调用的是backend.defaultParallelis()方法
// 最后调用scheduler.conf.getInt("spark.default.parallelism", totalCores)
// spark在默认情况下,从配置对象中获取配置参数 spark.default.parallelism
// 如果获取不到,那么使用totalCores属性,这个属性是当前运行环境的最大可用核数