目录
一、合并与分割
1.1 tf.concat (合并)
1.2 tf.stack (增加新维度)
1.3 tf.unstack (一个一个拆分)
1.4 tf.split (均分拆分)
二、数据统计
2.1 tf.norm(默认二范数)
2.1.1 一范数
2.2 tf.reduce_min / max / mean(求最大、最小、平均值)
2.3 tf.argmax/argmin (求最大、最小值的索引)
2.4 tf.equal (比较)
2.5 tf.unquire(去除重复元素)
三、数据排序
3.1 tf.sort / tf.argsort(排序和返回索引)
3.2 tf.math.top_k(返回 values and indices)
四、填充与复制
4.1 tf.pad(填充)
4.2 tf.tile(数据复制)
五、张量限幅
5.1 tf.clip_by_value
5.2 tf.nn.relu
5.3 tf.clip_by_norm
5.4 tf.clip_by_global_norm
六、高阶操作
6.1 tf.where(查询 True 的坐标)
6.2 tf.scatter_nd
6.3 tf.meshgrid
一、合并与分割

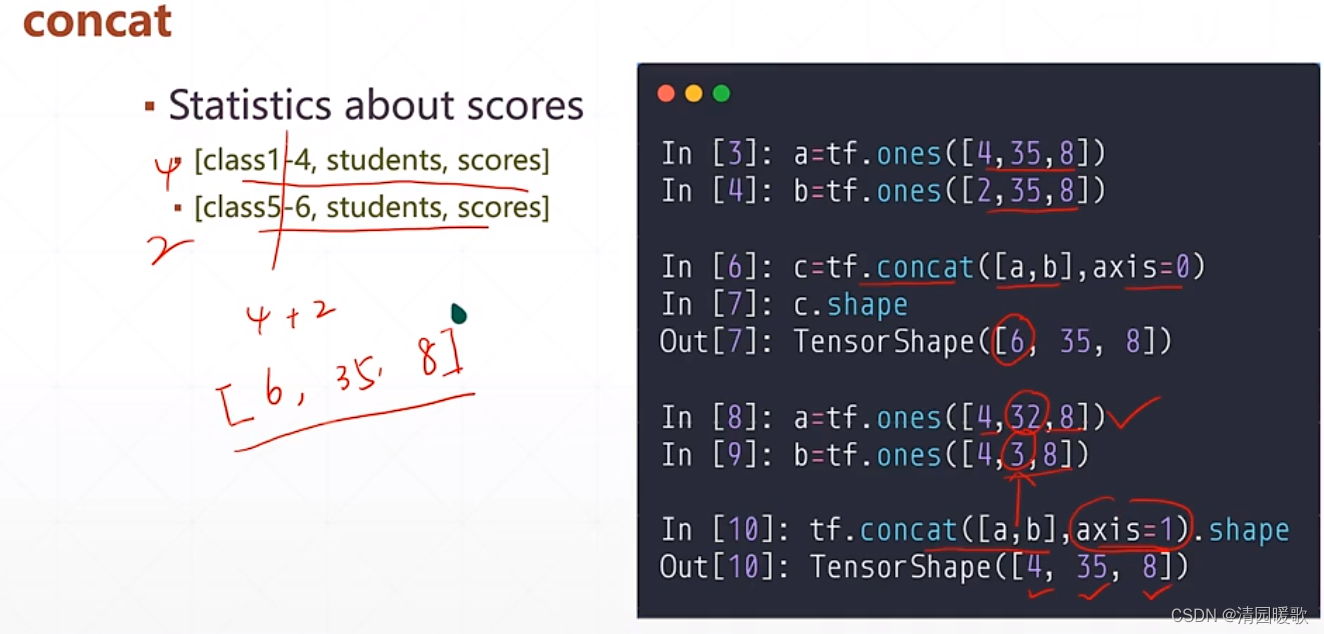
1.1 tf.concat (合并)
一个同学收集 1~4 班的成绩单
另一个同学收集 5~6 班的成绩单
1.2 tf.stack (增加新维度)
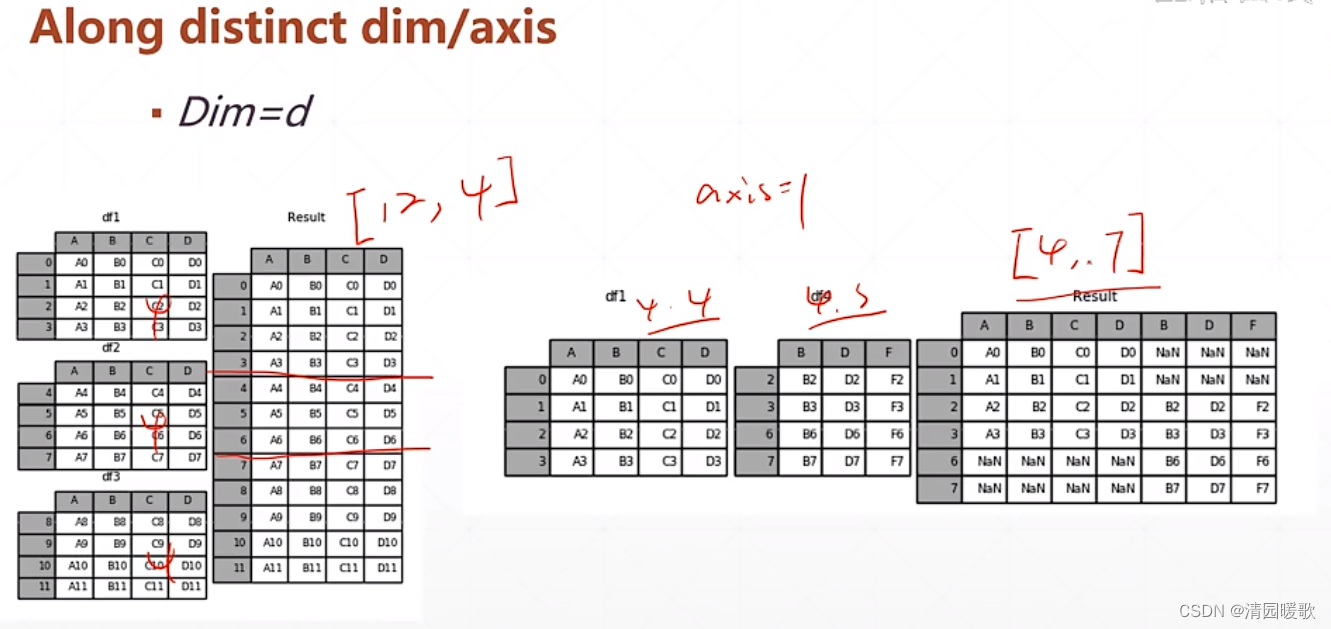
如要把两个学校的成绩合并,此时需要区分如前4个班级是A学校的,后4个是B学校,这就需要增加一个维度:学校
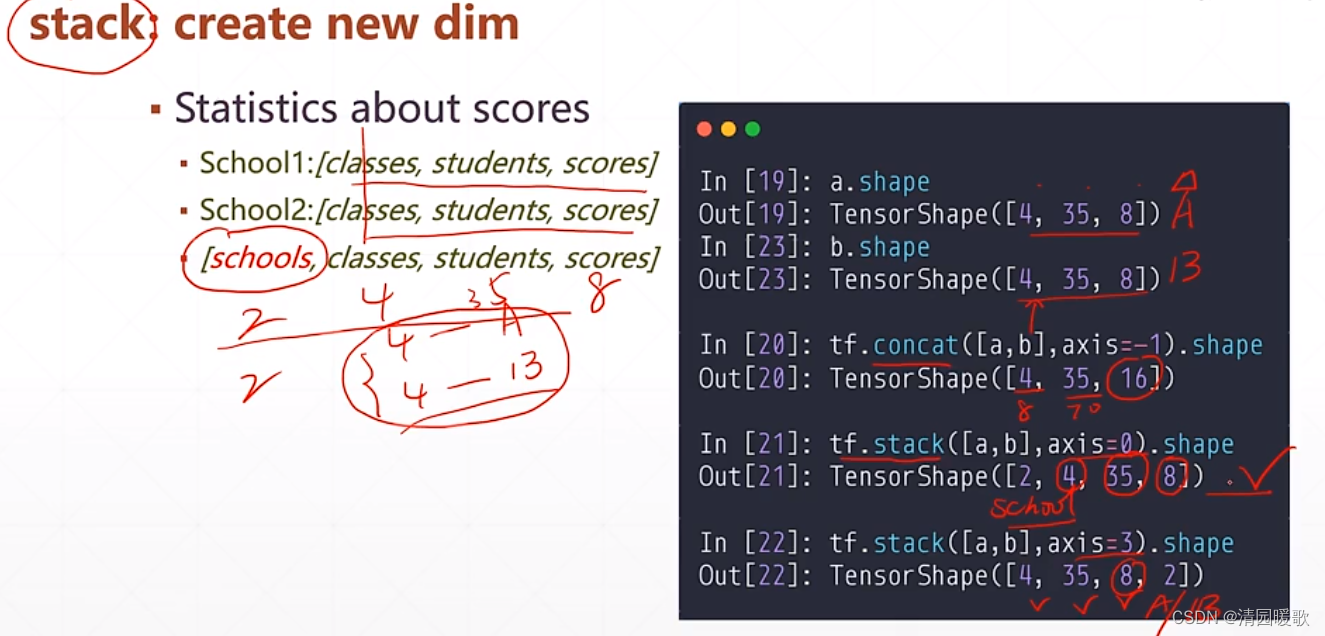
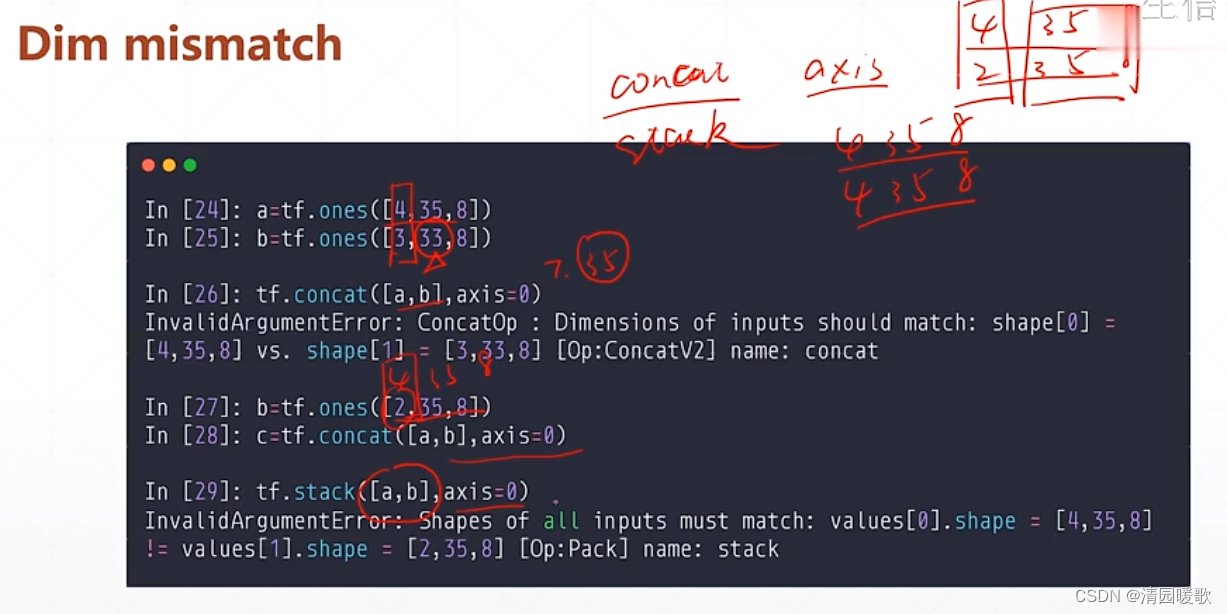
concat 和 stack 都要保证其他维度相等
1.3 tf.unstack (一个一个拆分)

如上,unstack 将 [2,4,35,8] 拆分成了 8个 [2,4,35],而如果要拆分成2个 [2,4,35,4] 就要用到 split 函数
1.4 tf.split (均分拆分)
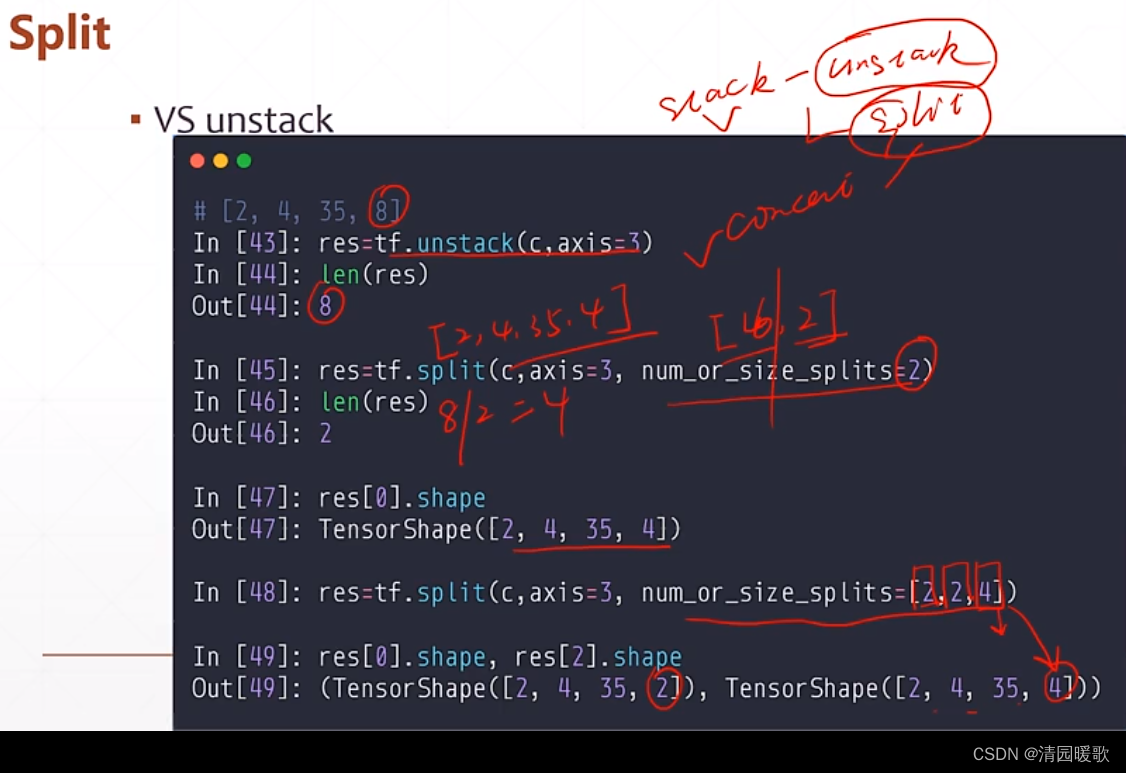
num_or_size_splits = 2 分成均等的两部分
num_or_size_splits = [2,2,4] 拆分成2,2,4的三部分
二、数据统计
张量的统计、二范数(Eukl)、一范数(L1)、无穷范数(Max)
都是向量的范数


2.1 tf.norm(默认二范数)
这里讨论 向量的范数,不讨论矩阵的范数
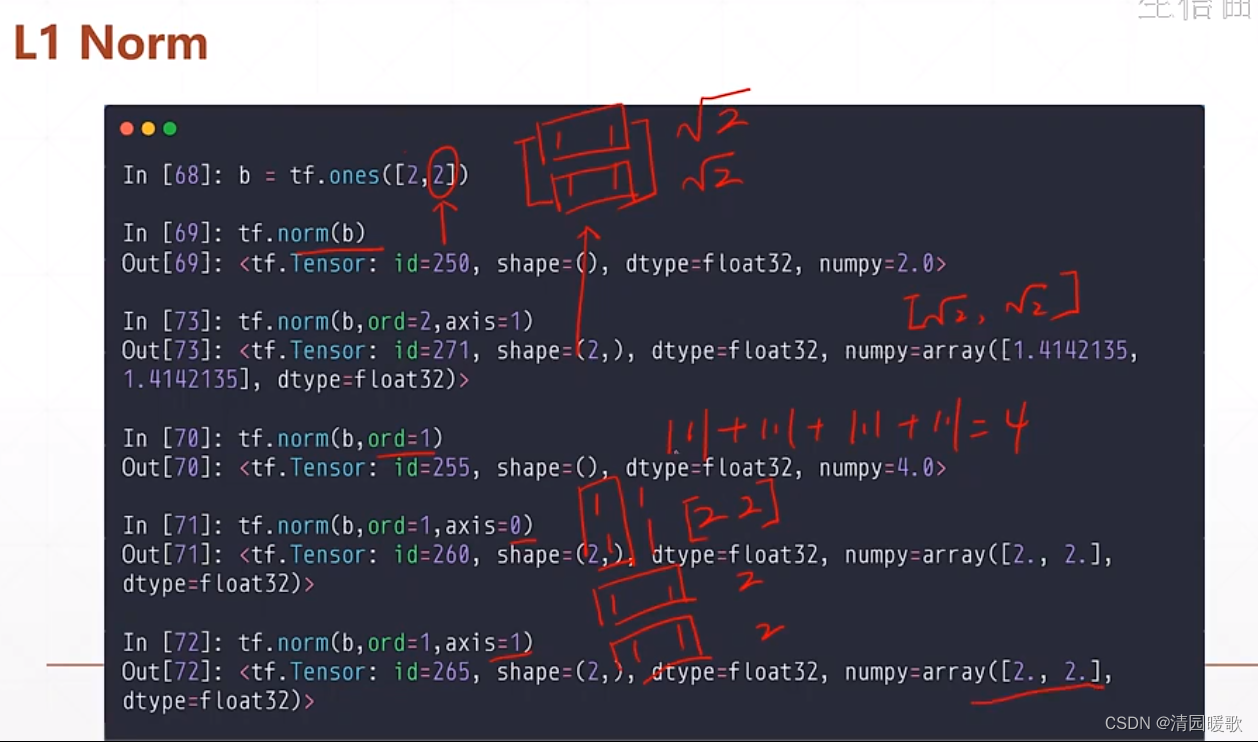
norm:所有元素平方和开根号

2.1.1 一范数
tf.norm(b, ord=2, axis=1) :ord=2是二范数,axis=1是一行算一个整体
tf.norm(b, ord=1, axis=0) :ord=1是一范数,axis=0是一列算一个整体
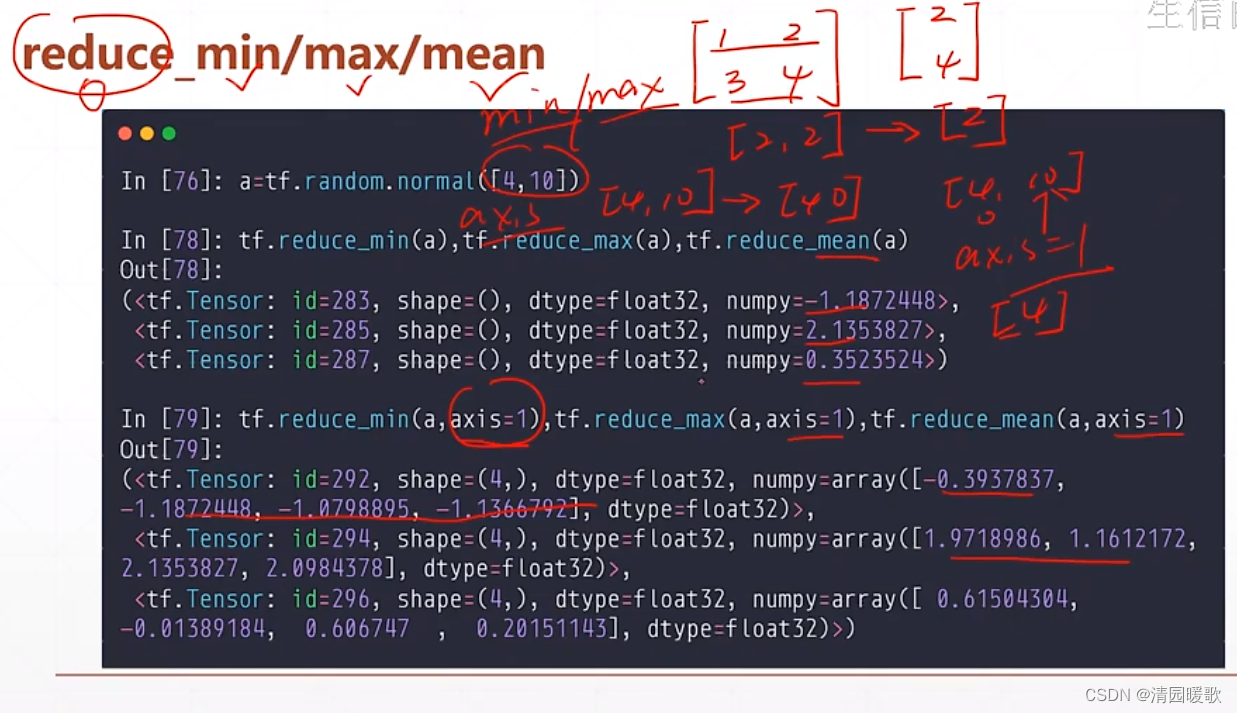
2.2 tf.reduce_min / max / mean(求最大、最小、平均值)
为什么是 reduce,是因为提醒你这是降维的过程
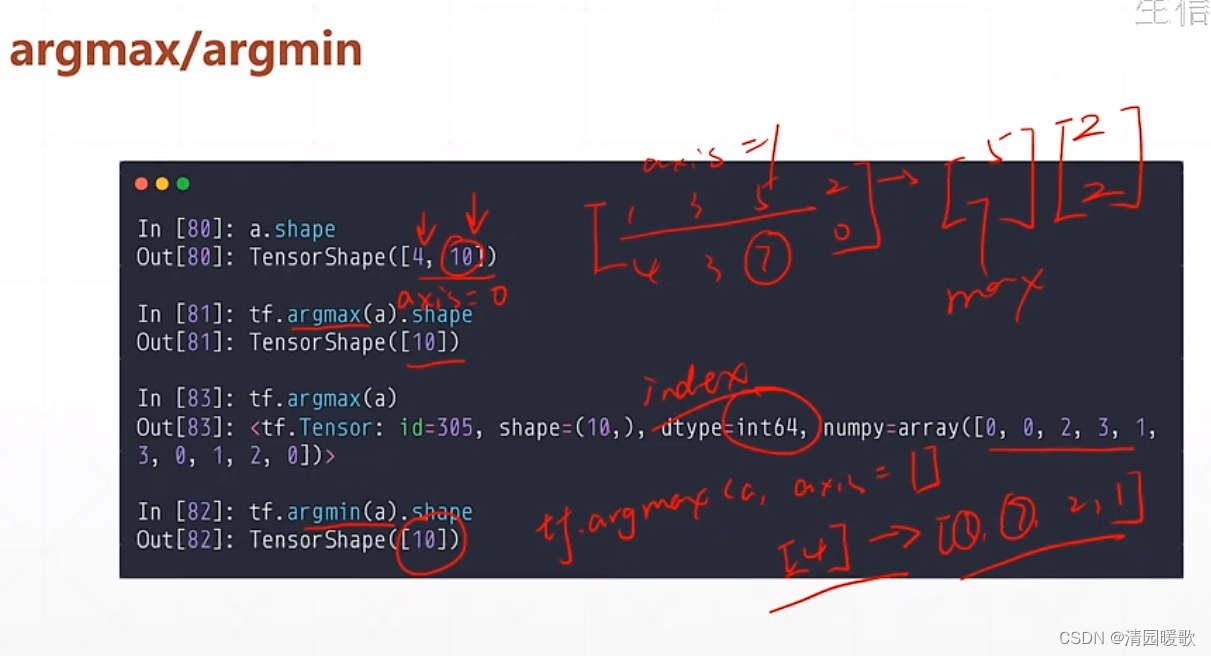
2.3 tf.argmax/argmin (求最大、最小值的索引)
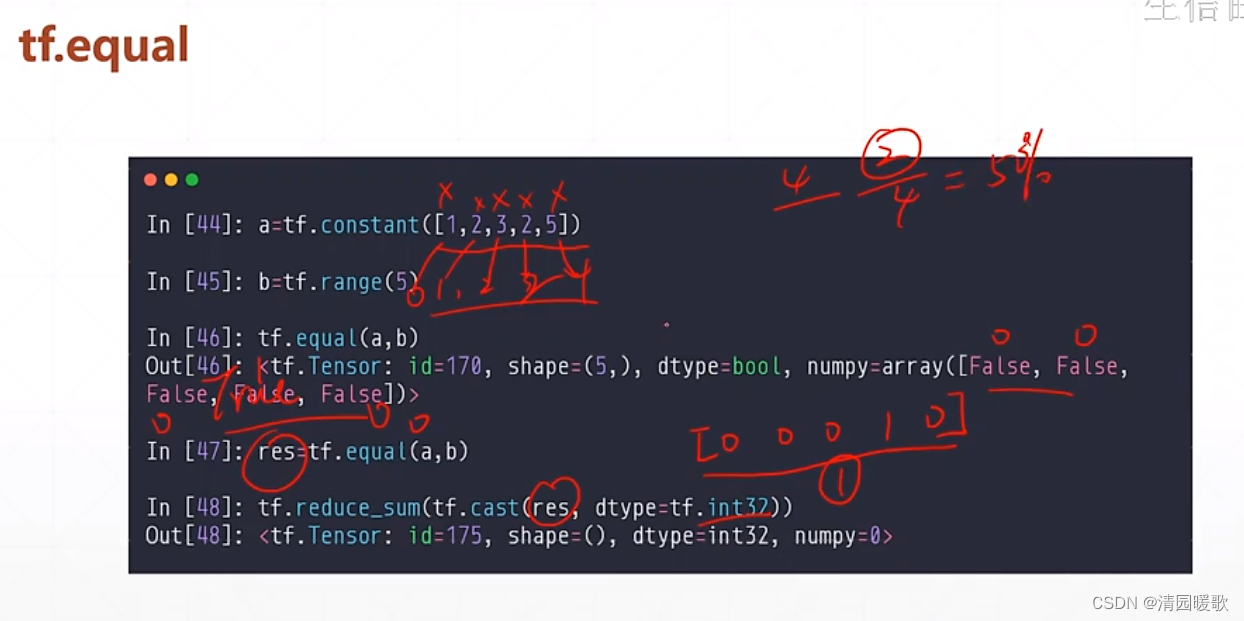
2.4 tf.equal (比较)
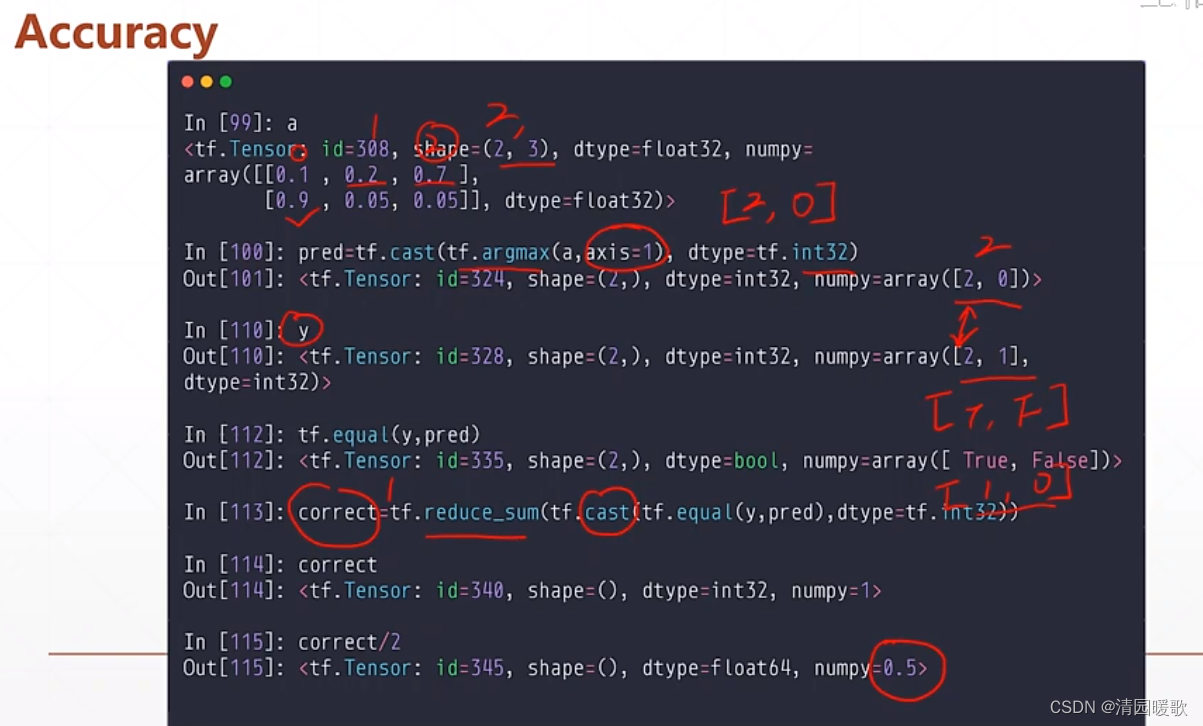
可用来求准确度 accuracy
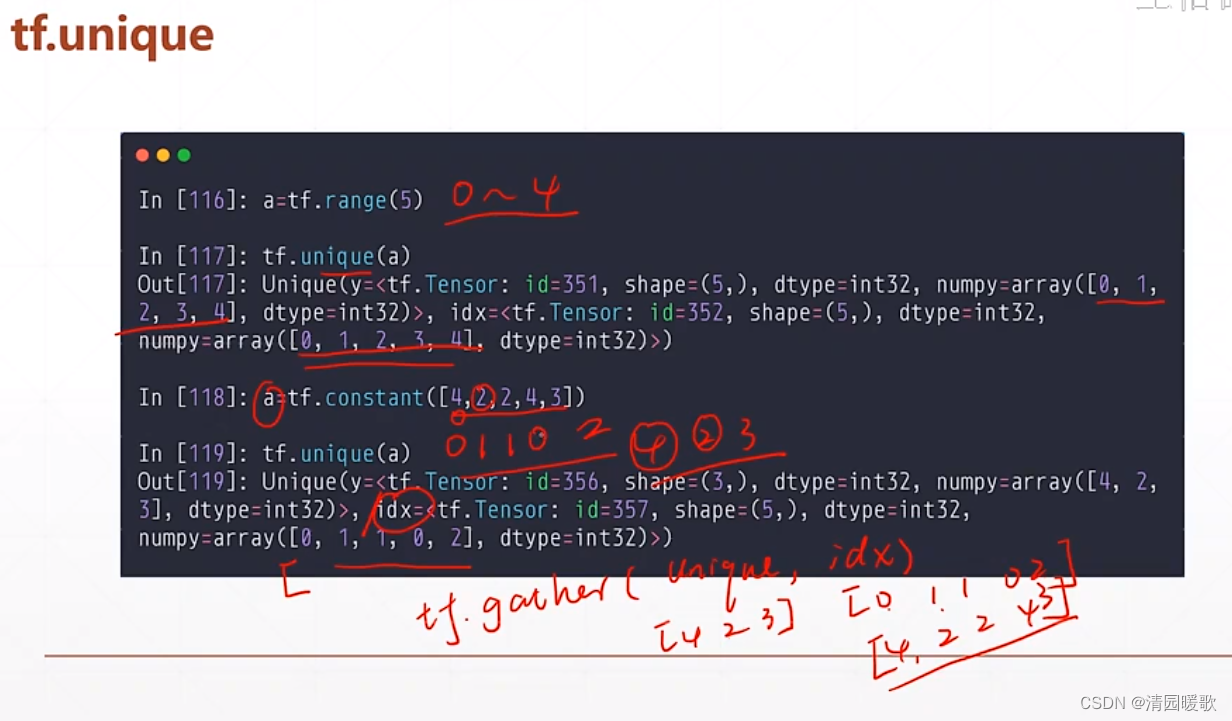
2.5 tf.unquire(去除重复元素)
返回两个,一个是去除重复的数组,另一个是原表中元素在去除后的表中的索引
三、数据排序

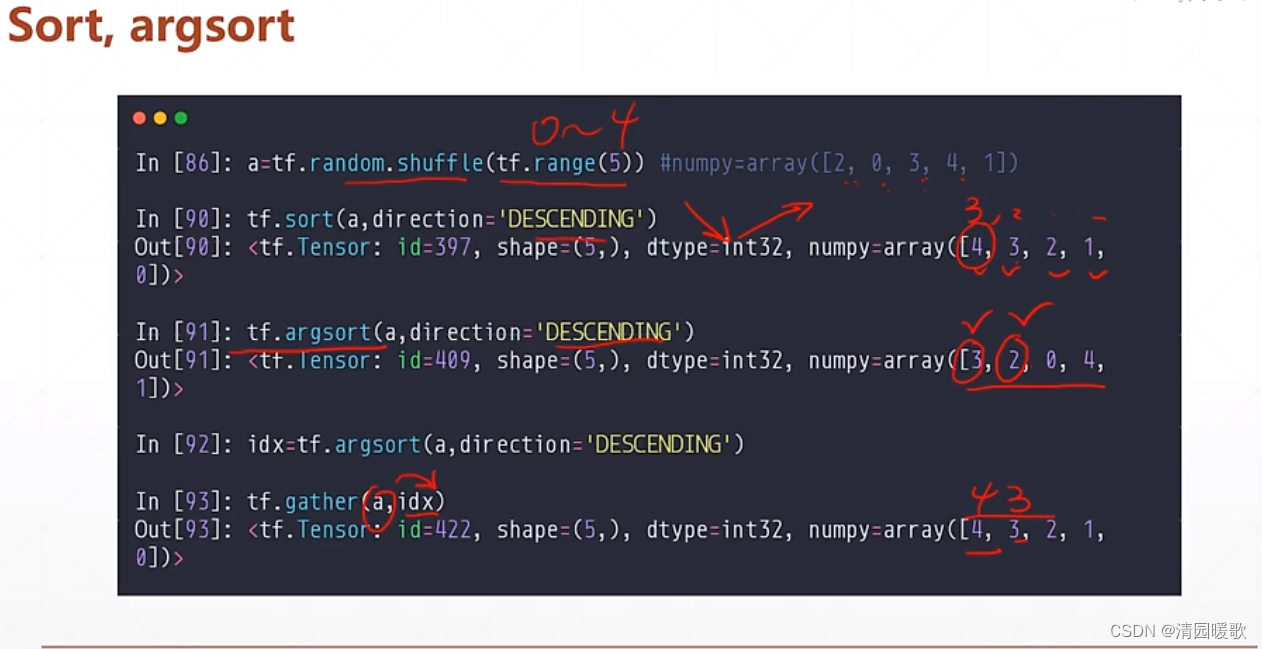
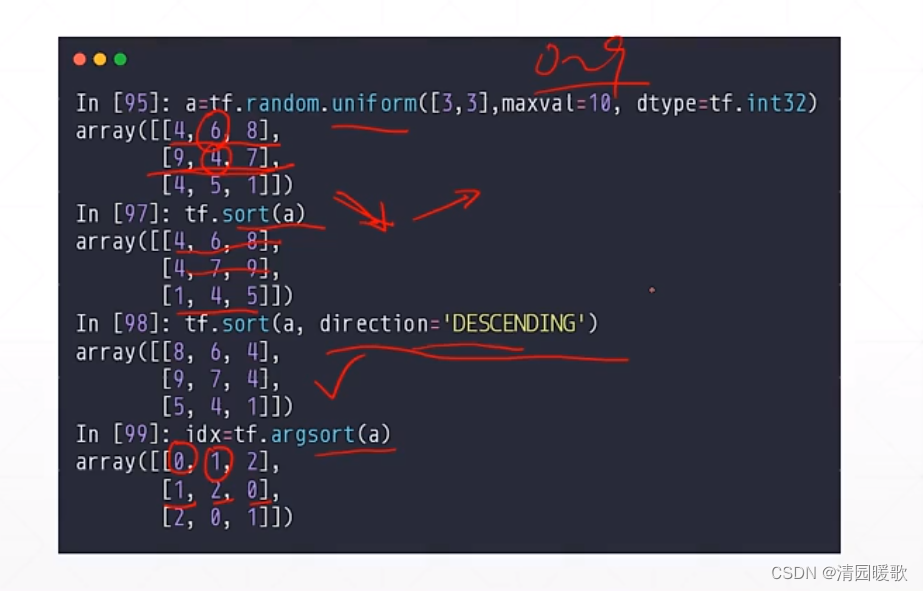
3.1 tf.sort / tf.argsort(排序和返回索引)
direction = 'DESCENDING' :sort中 降序;argsort中 返回最大值索引,次大值索引,依次下去
这是 argsort 和 gather 就能融合使用
argsort 默认返回最小值的索引
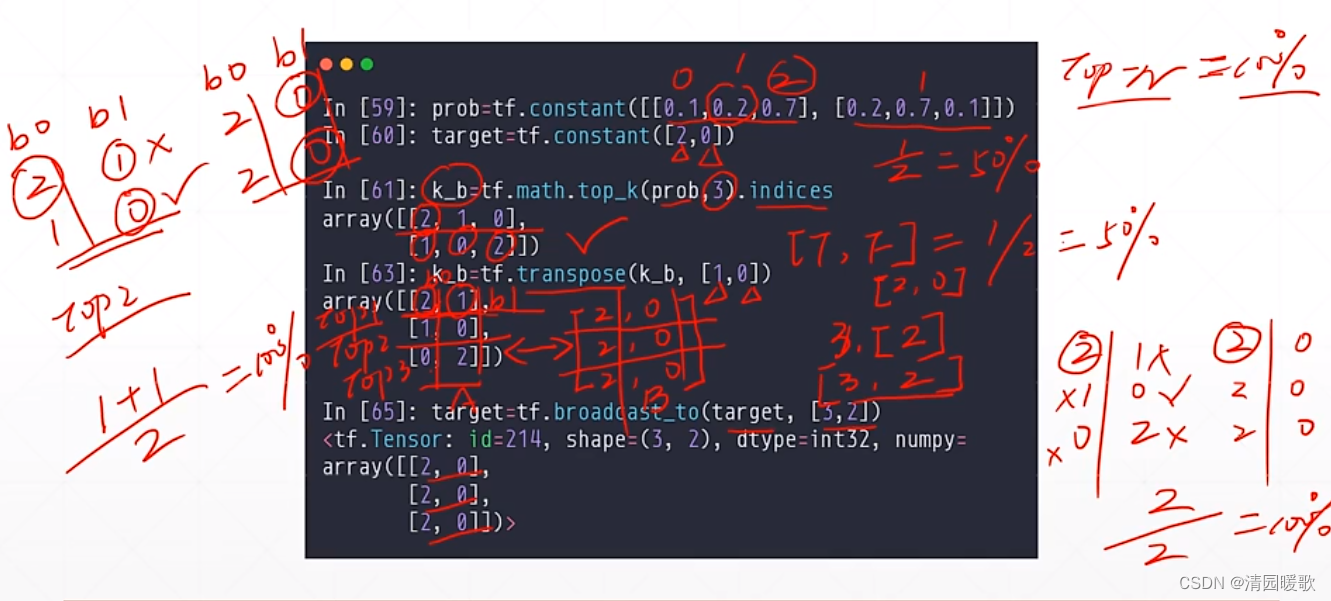
3.2 tf.math.top_k(返回 values and indices)
res = tf.math.top_k(a, 2):返回前2个最大值的索引和值,k=2
用 indices 返回索引,values返回值

可用来 top-k accuracy 预测

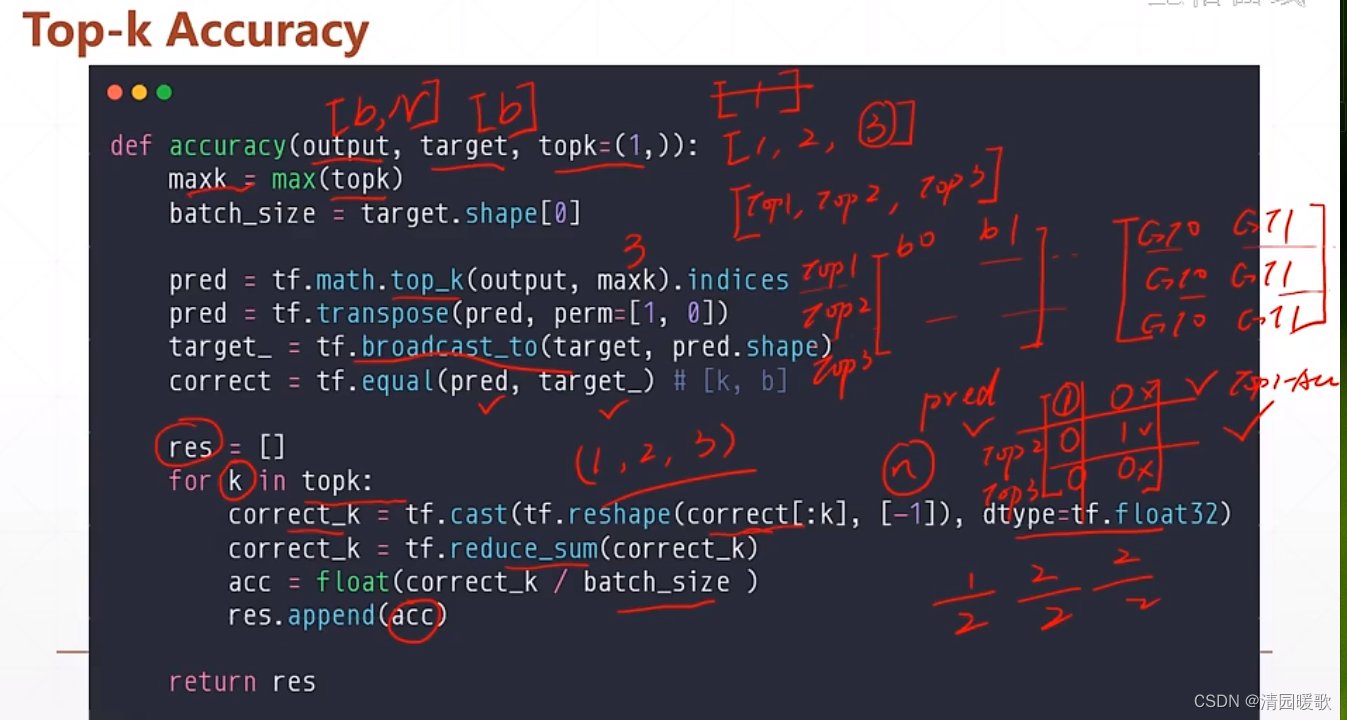
代码:topk.py
四、填充与复制

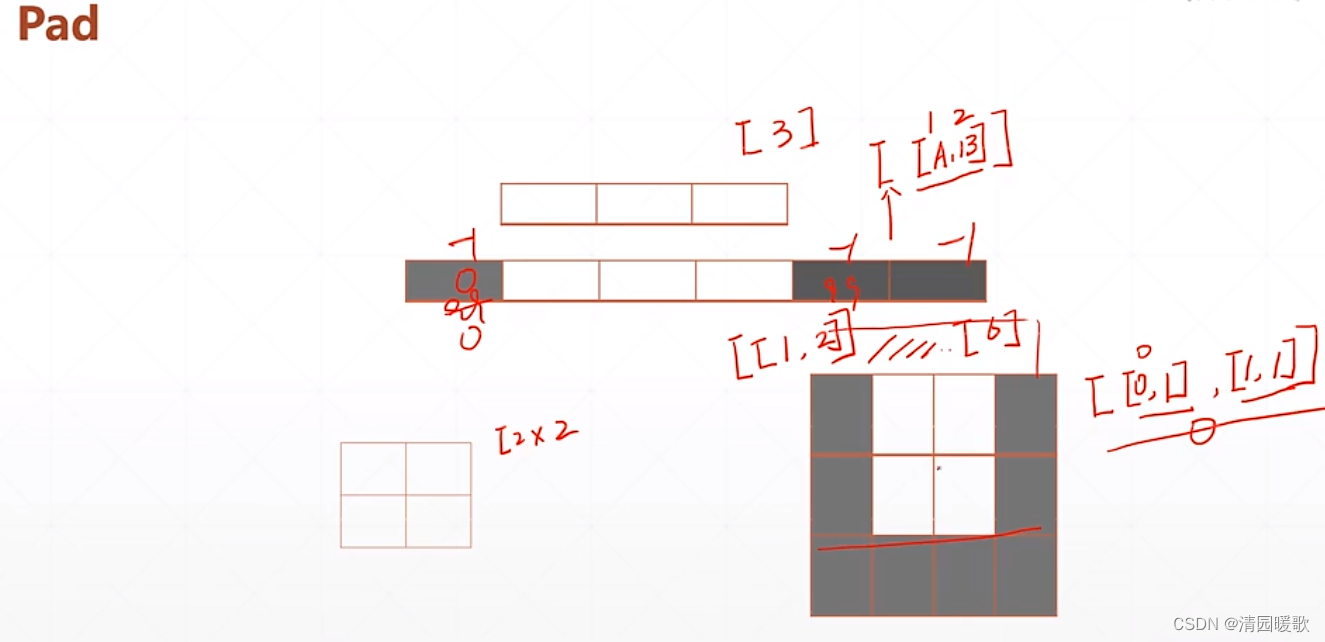
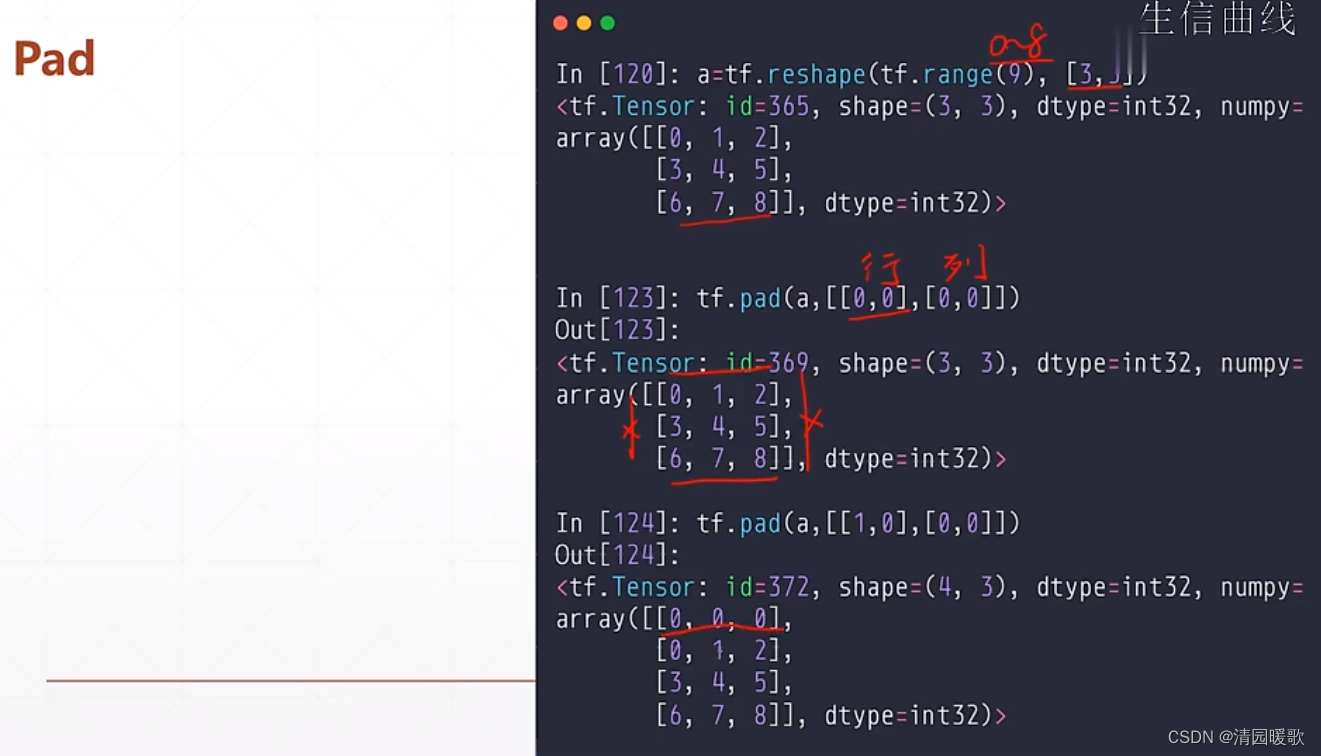
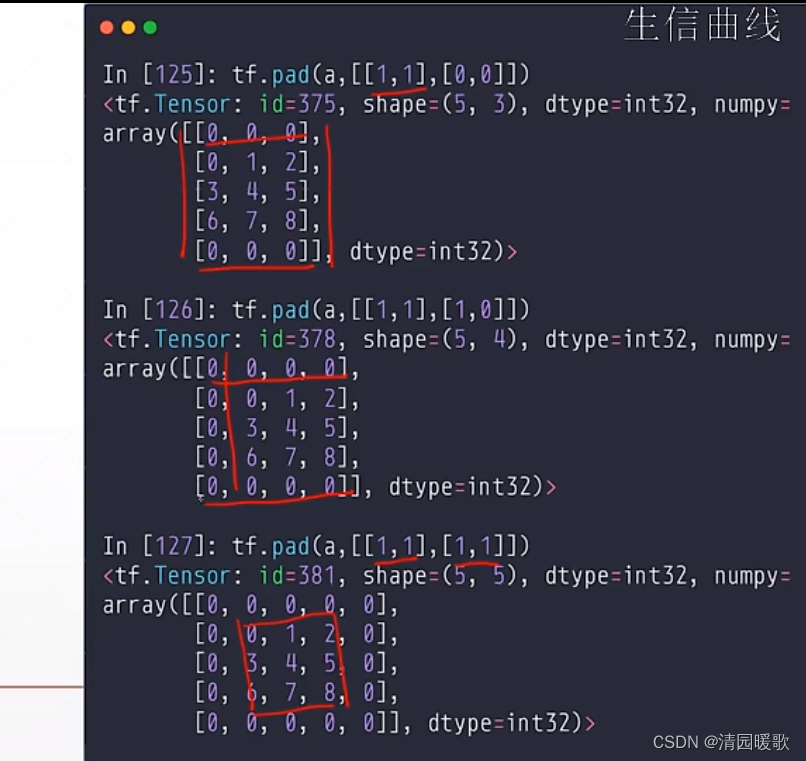
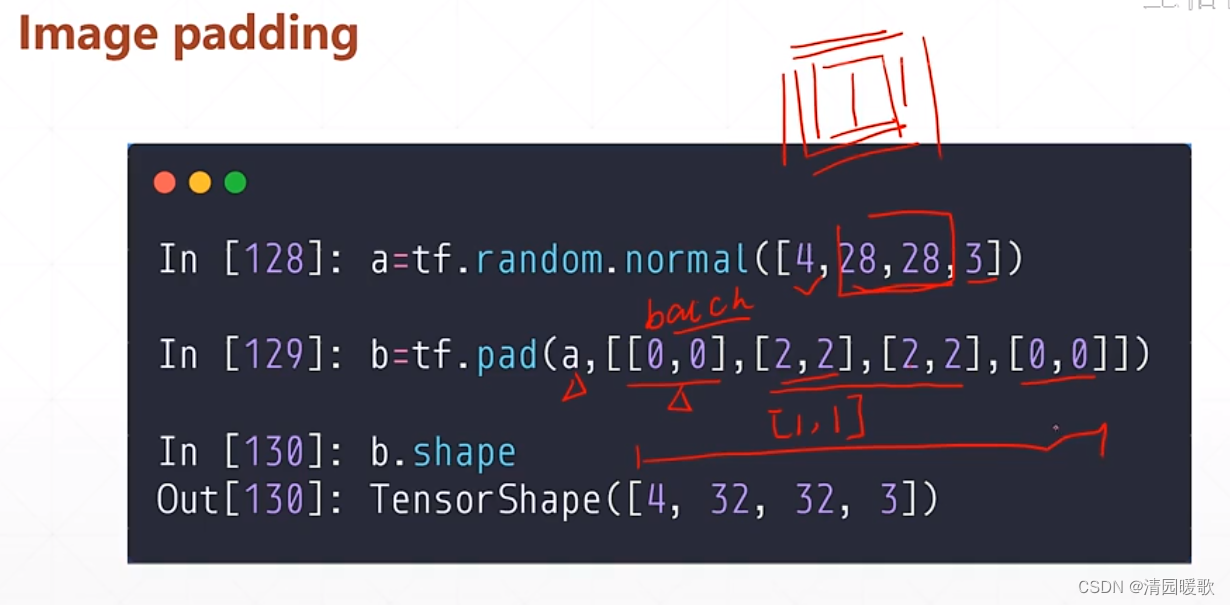
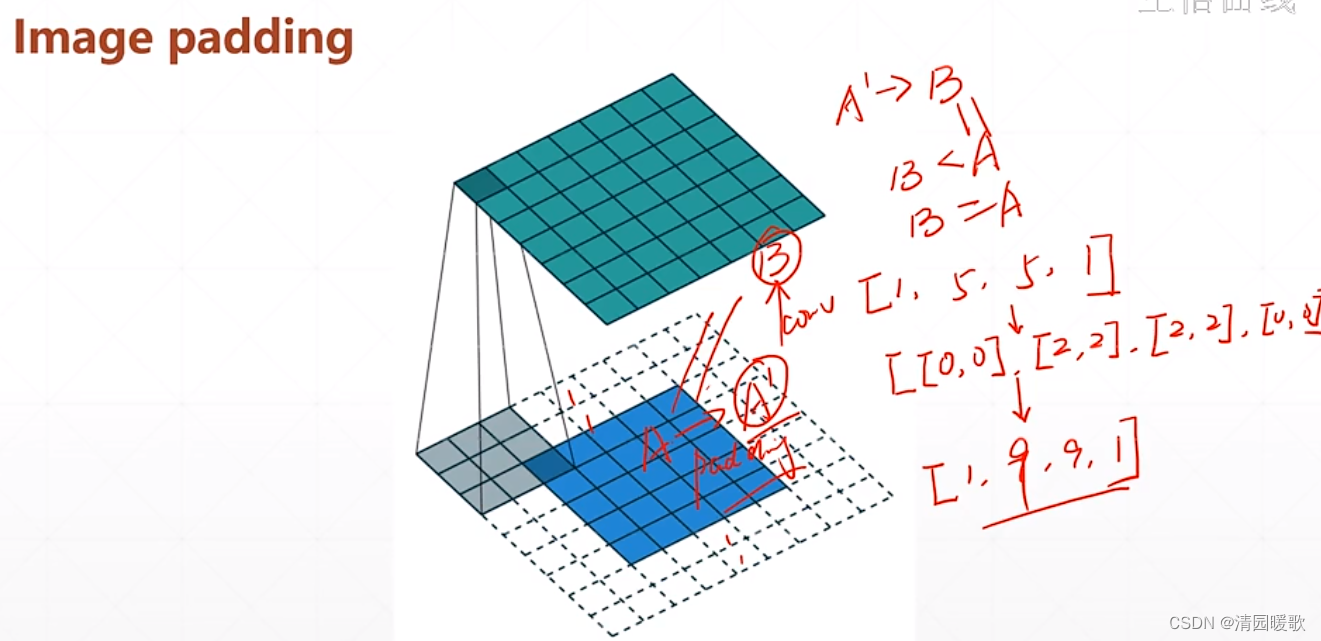
4.1 tf.pad(填充)
如一个维度的 [3],pad个 [ [A, B] ] 表示左边添加A 个,右边添加B个
[ [ 0, 1] , [1, 1] ] 表示行的上面不添加,下面添加1行;列的左边添加1行,右边添加1行
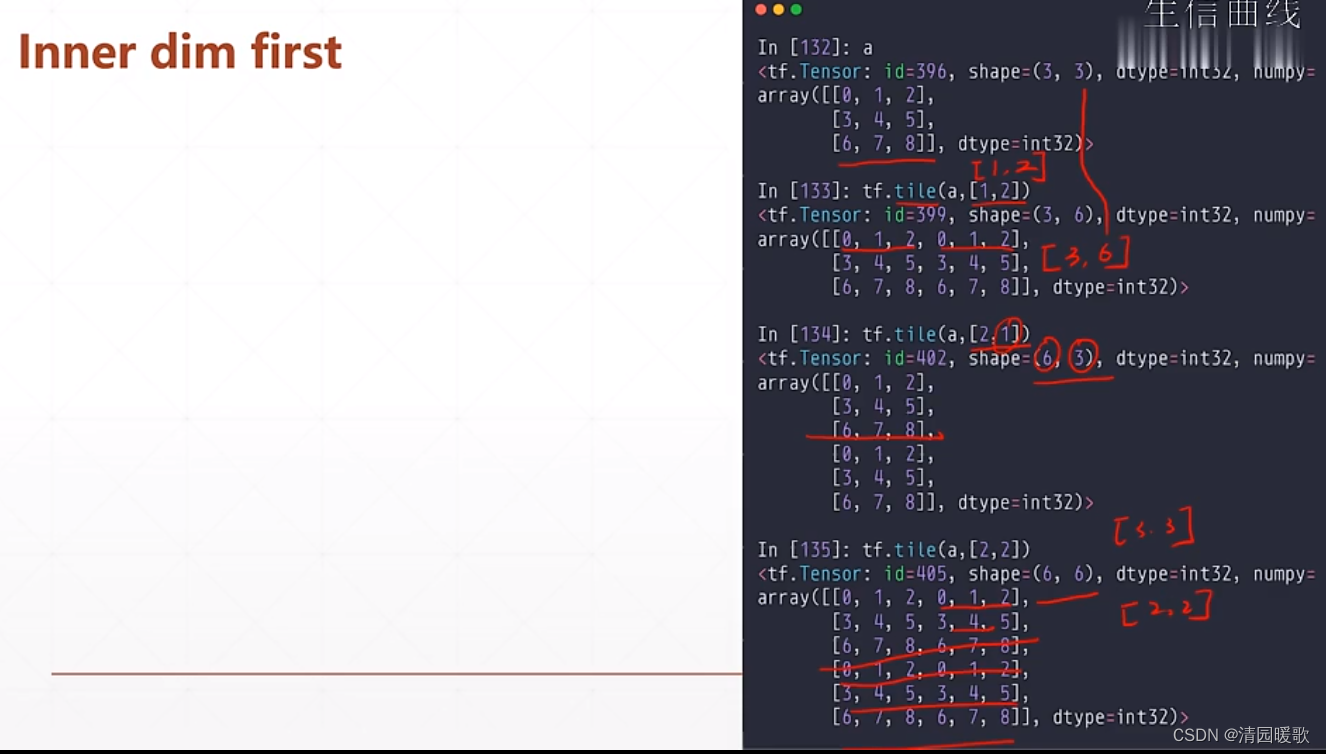
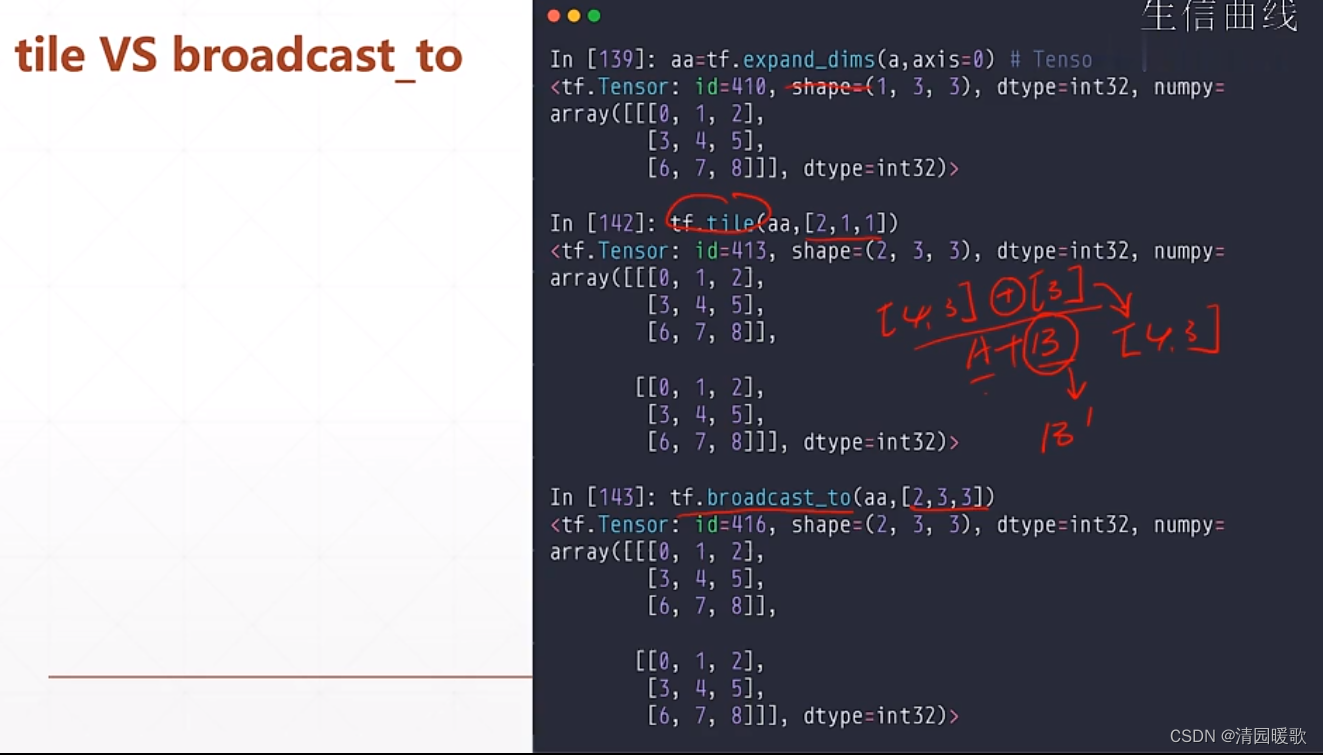
4.2 tf.tile(数据复制)
根据维度来复制

tf.tile (a, [1, 2]):1表示行这个维度不复制,2表示列这个维度复制1次
五、张量限幅

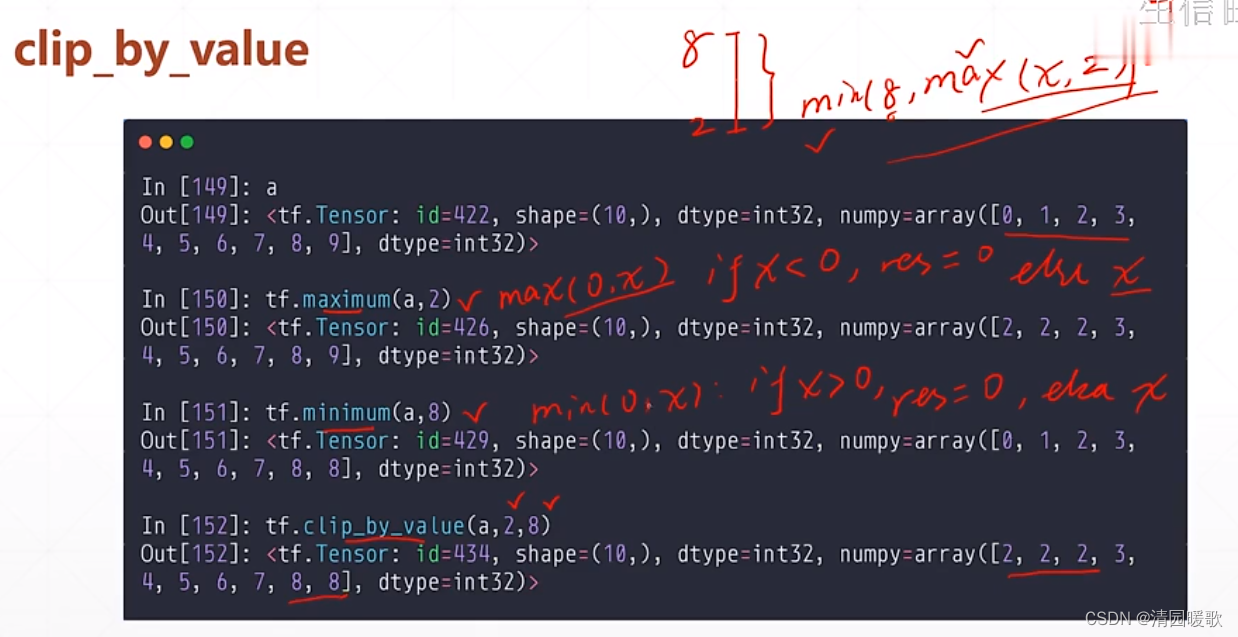
5.1 tf.clip_by_value
maximum, max, minimum, min:分别限幅最小和最大
要想限制在一个范围就要嵌套,如 min( 8, max(x, 2))
还可以直接使用 tf.clip_by_value = (a, 2, 8)
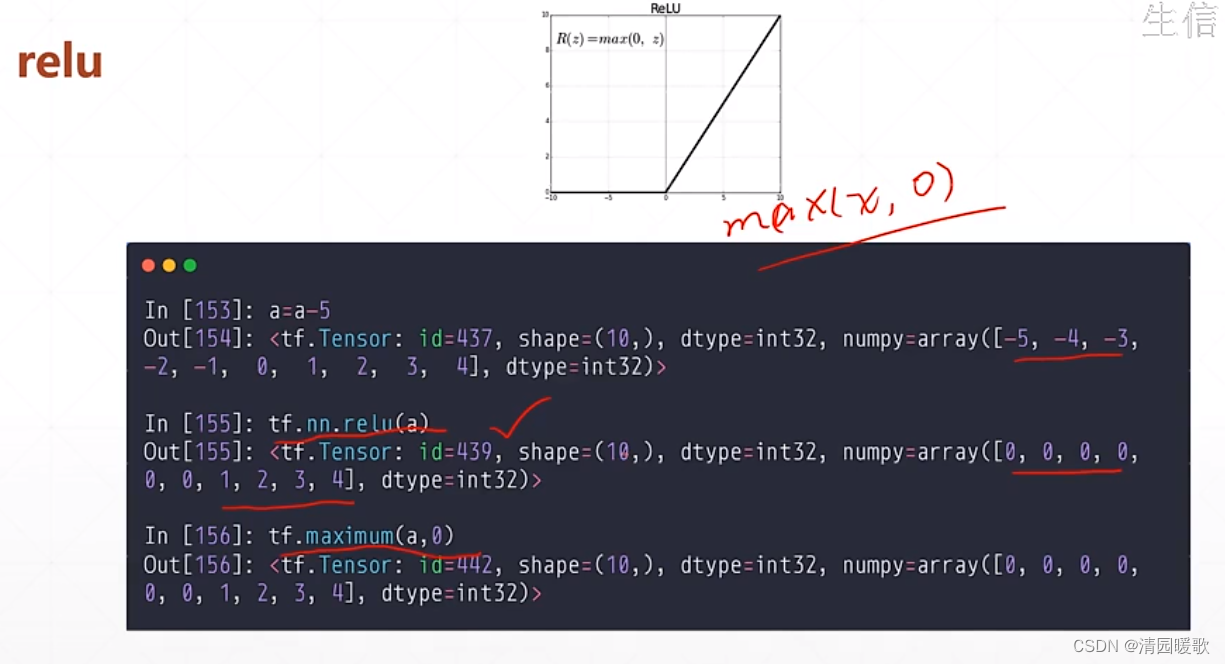
5.2 tf.nn.relu
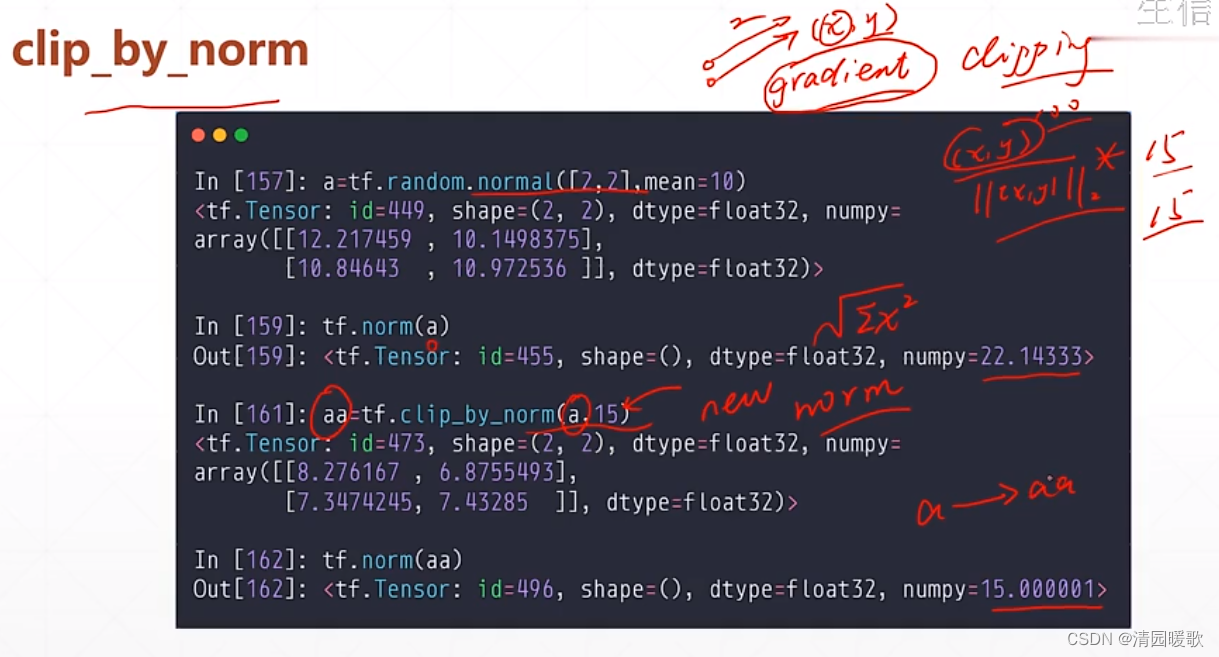
5.3 tf.clip_by_norm
根据范数来放缩限幅
相当于把原数 除以 模 归一化这种,在 乘 要放缩的数
5.4 tf.clip_by_global_norm
使得参数做一个整体的缩放

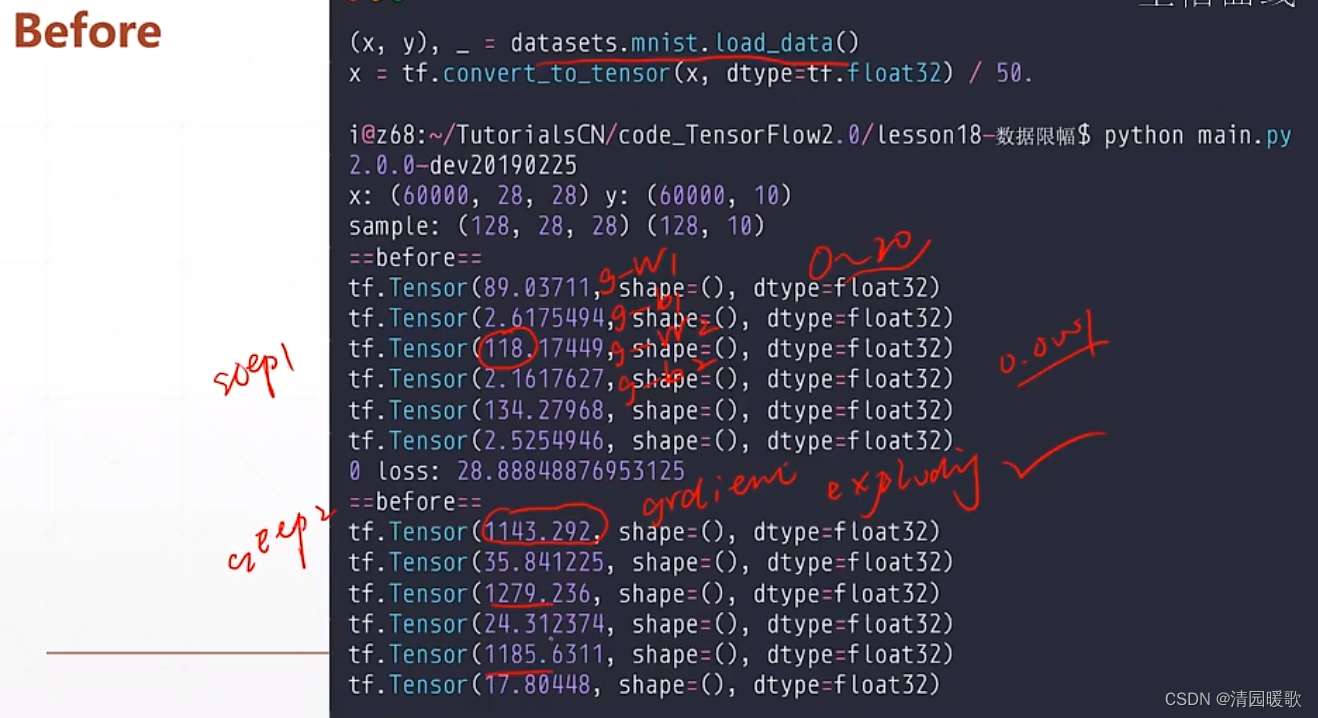

在训练时可帮助梯度更加稳定,不至于出现梯度爆炸
代码: chapter02 - clip.py
六、高阶操作


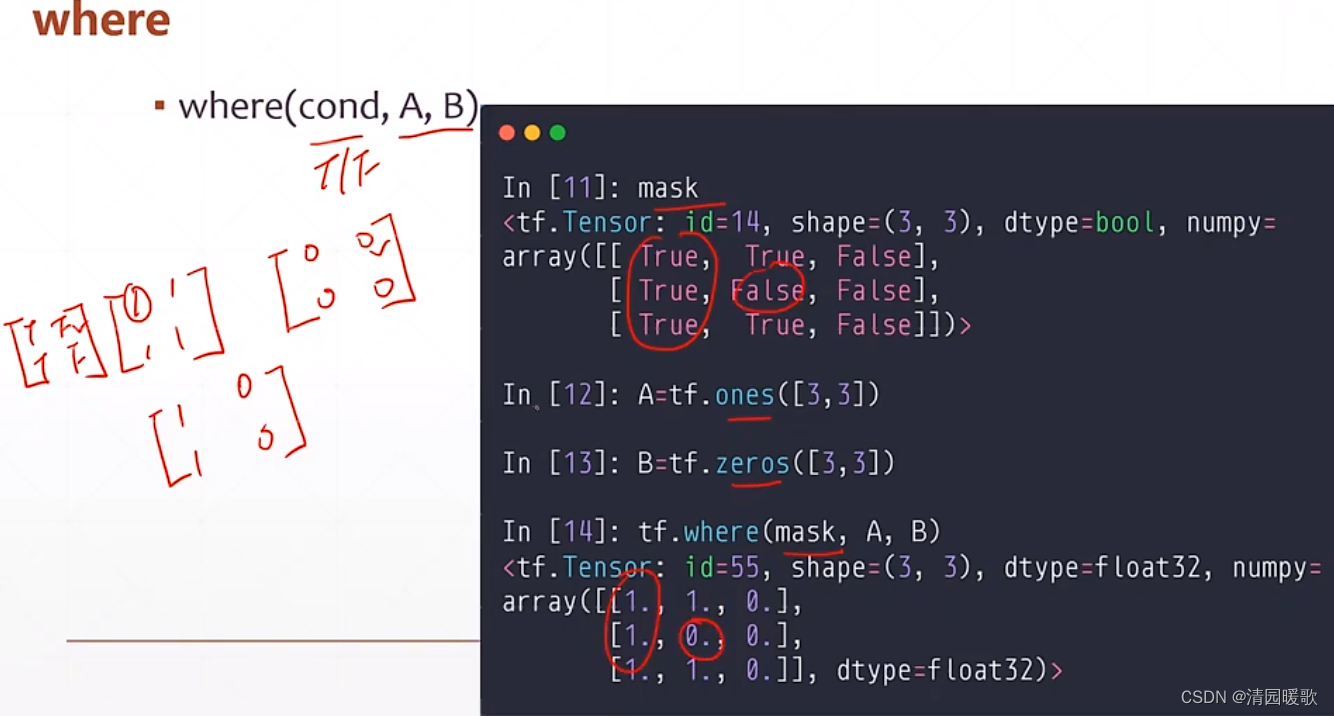
6.1 tf.where(查询 True 的坐标)
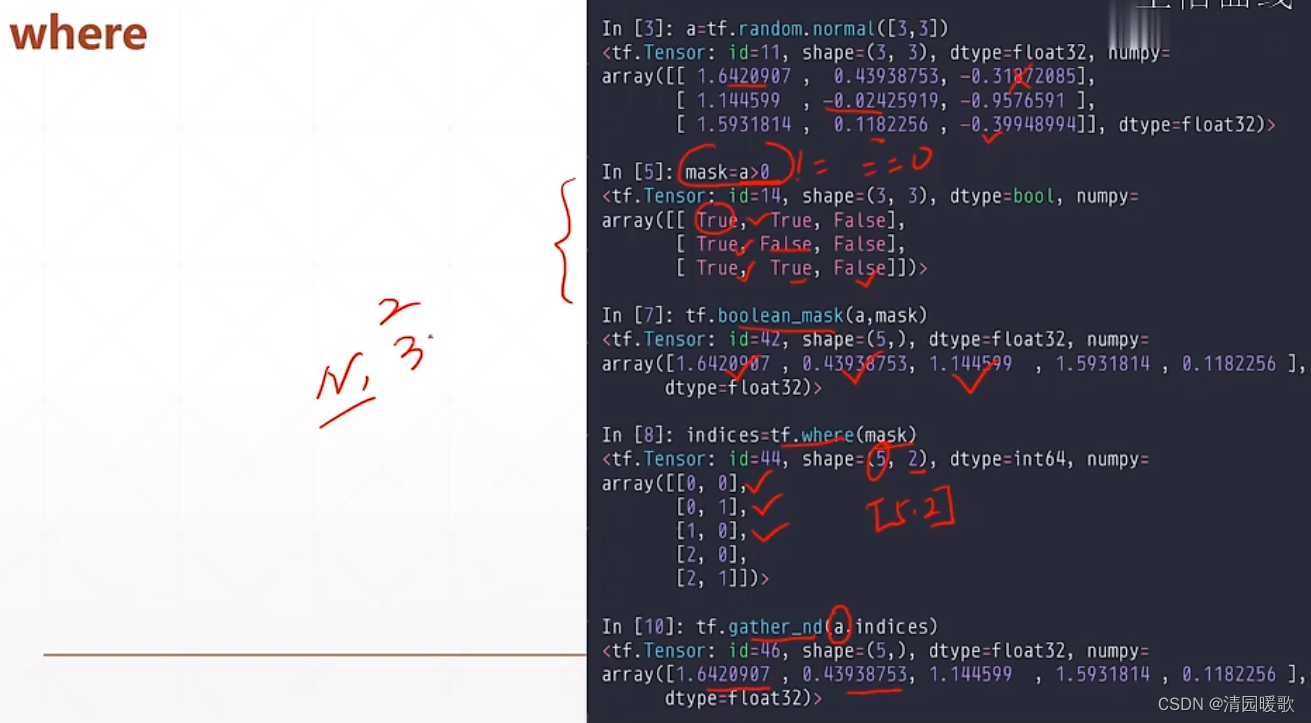
三个参数时,不一样
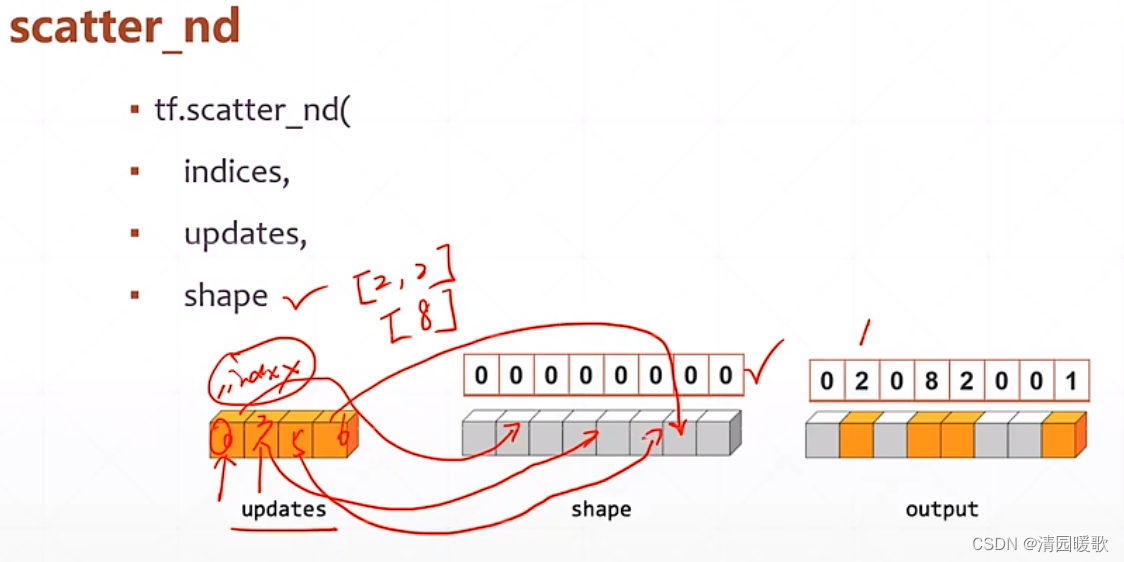
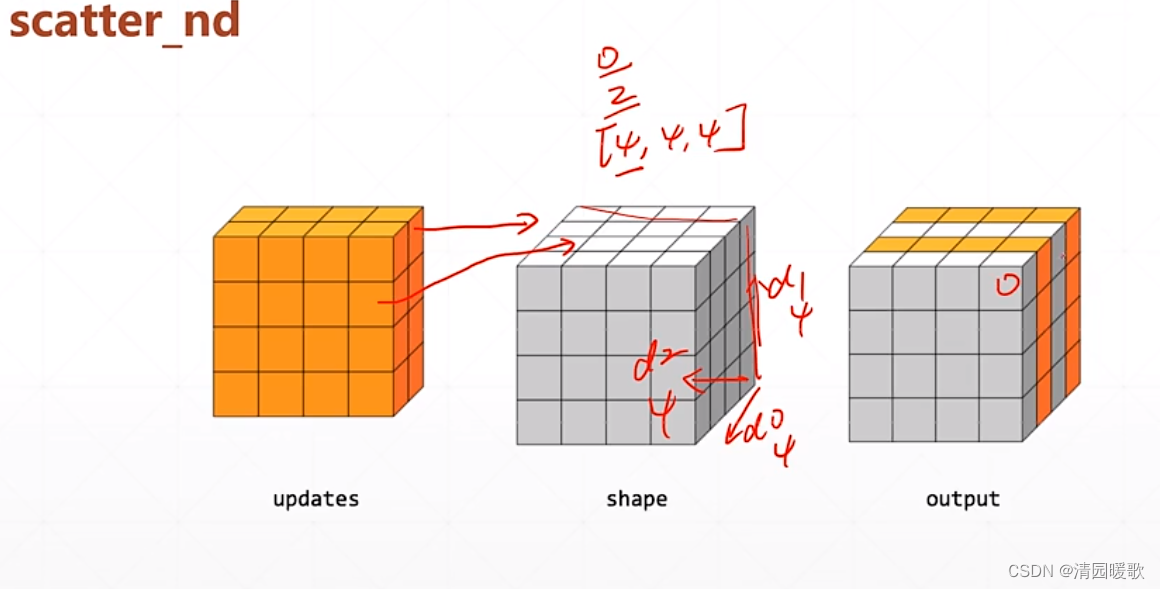
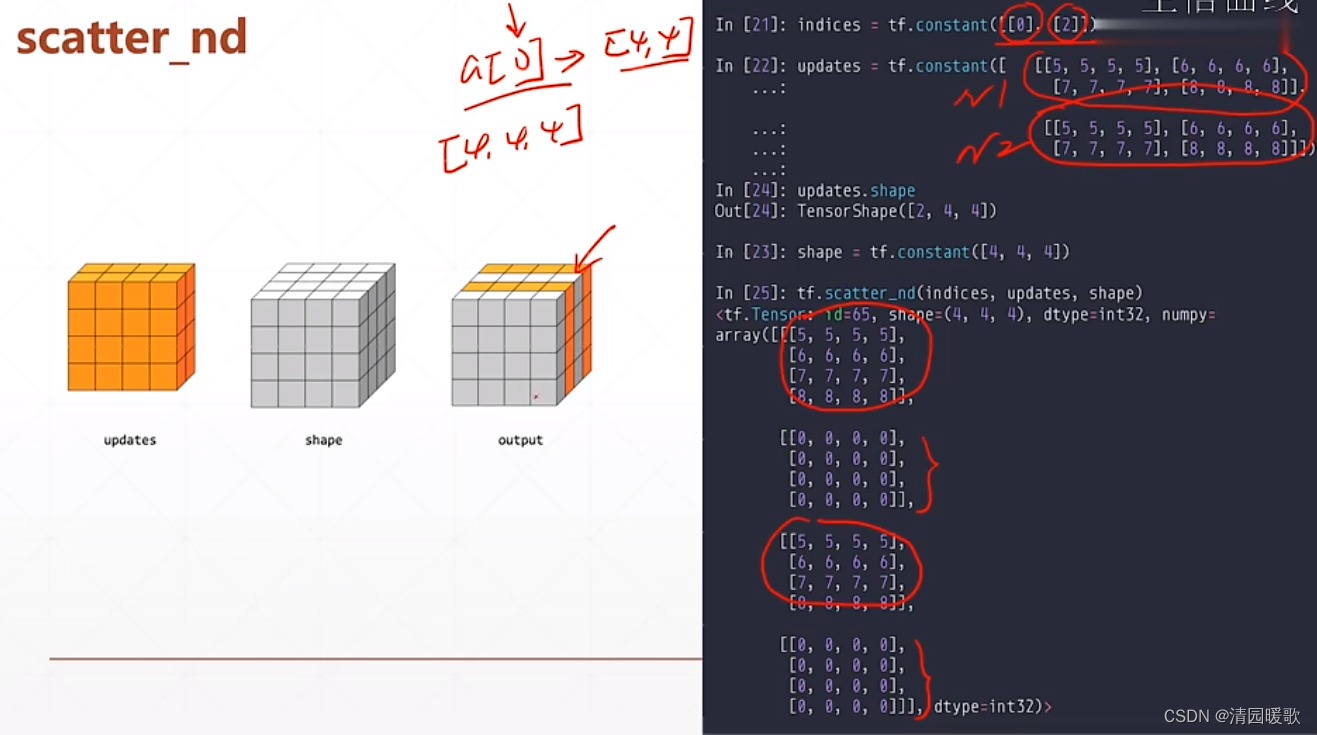
6.2 tf.scatter_nd
shape 是输出的底版
updates 是在shape中的更新的值
indices 是更新的索引
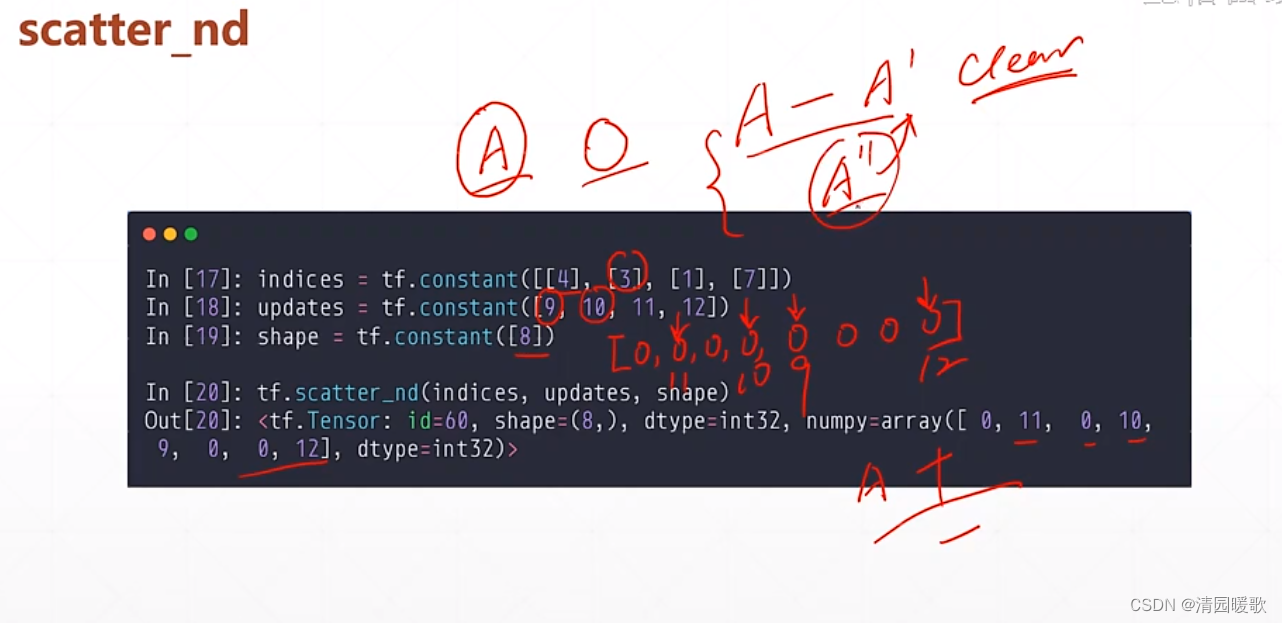
tf.scatter_nd 不能在现有的 tensor A上更新,只能在一个全 0 的底版上更新
要更新的话,首先要把要更新的一部分值取出来更新到底版上,得到A‘,A-A' 就会把要更新的一部分值清零,就是一个 clear 的操作
再把一个新的值写到底版上就是 A'',再把A'' 和清零后的累加最终得到
所以要更新的话就需要两个 scatter_nd 的操作
多维用法:
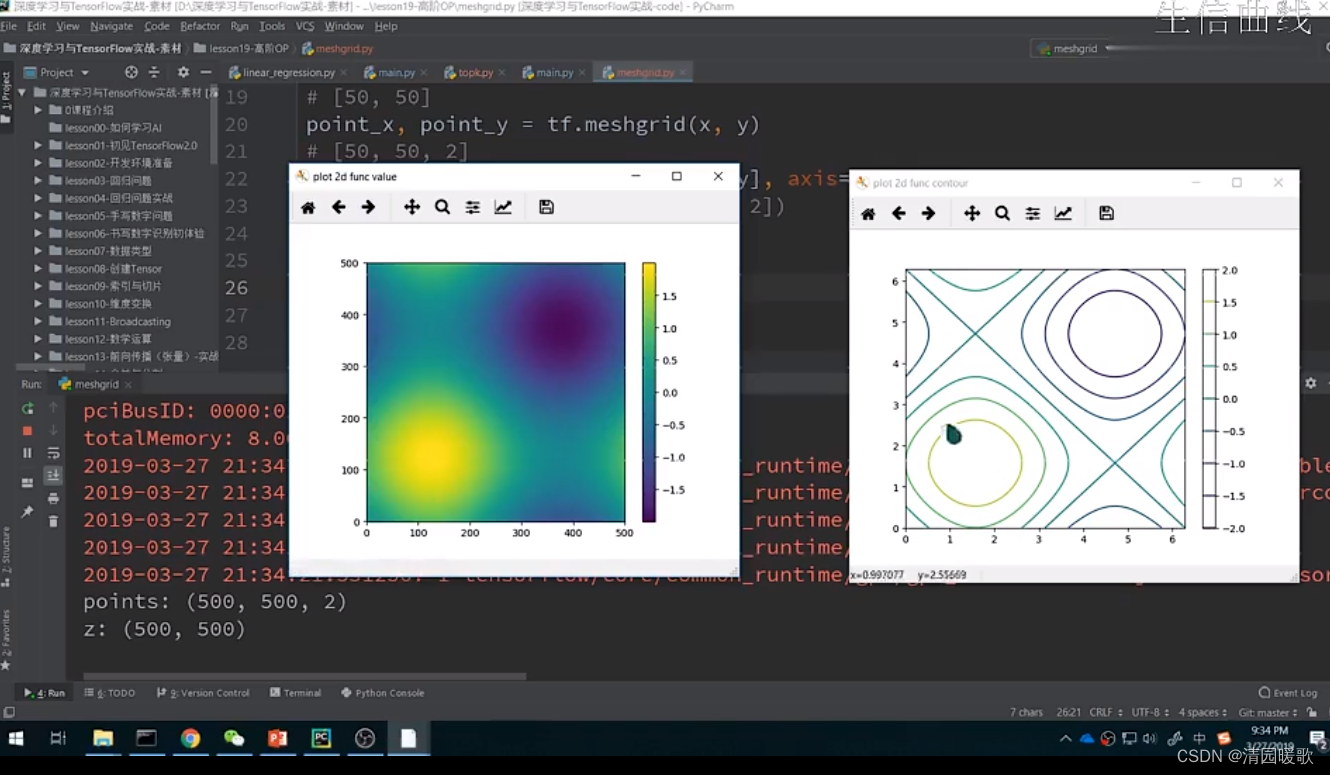
6.3 tf.meshgrid
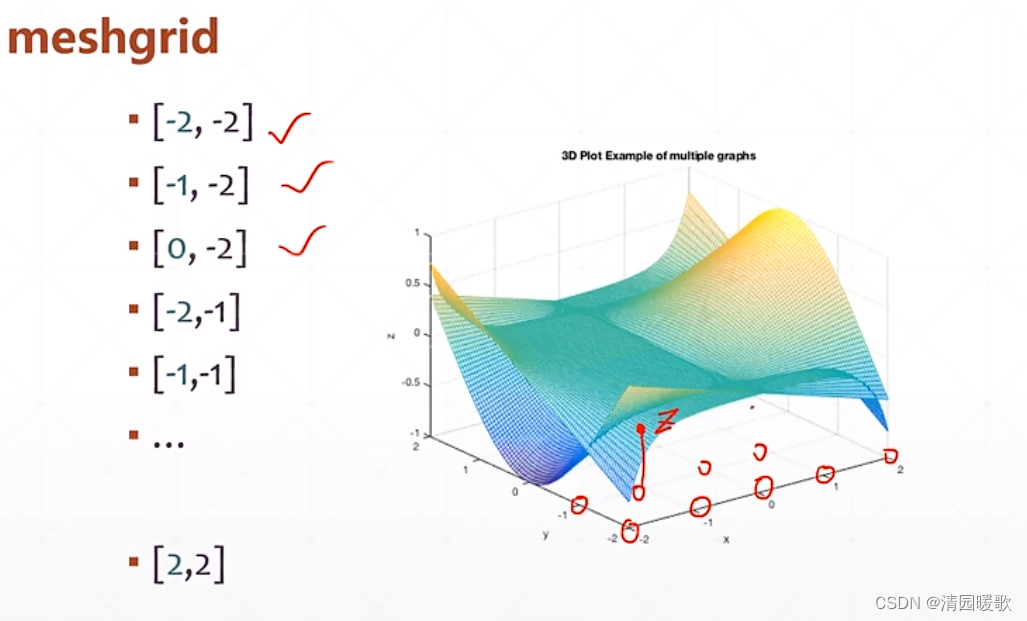
先规定 x,y 区间为 [-2, 2] ,在规定间隔 1,所以每个坐标都有2个值x和y,一共25个
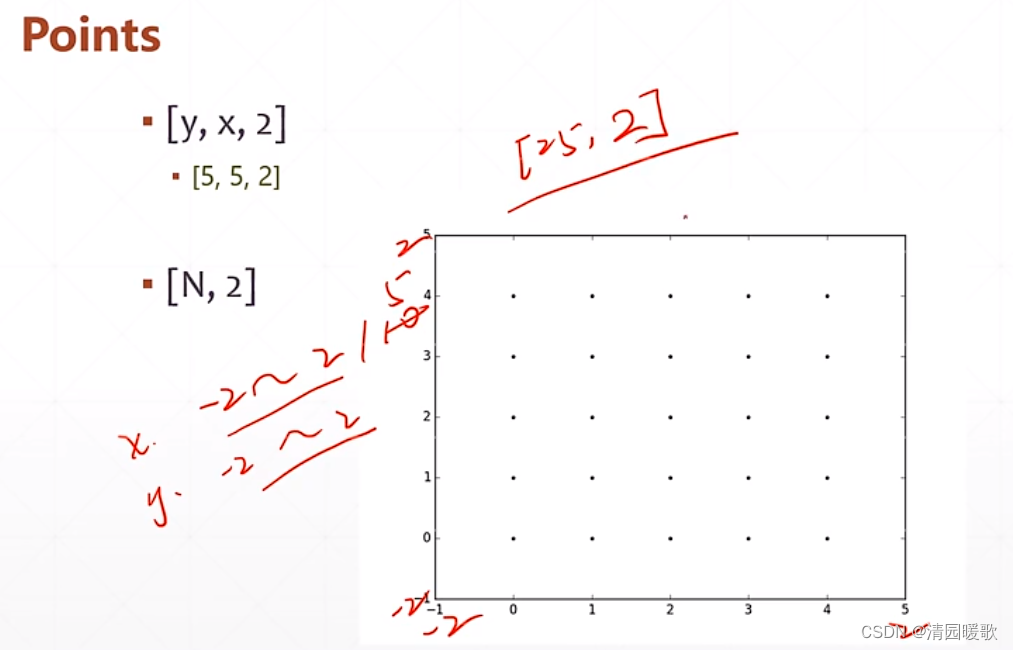
用一个嵌套来生成坐标,(-2,2,5):从-2到2,间隔5个点,保存到list中,再转换成array格式,但这是用 numpy 实现的,无法用 gpu 加速,无法和tensor深度结合一起
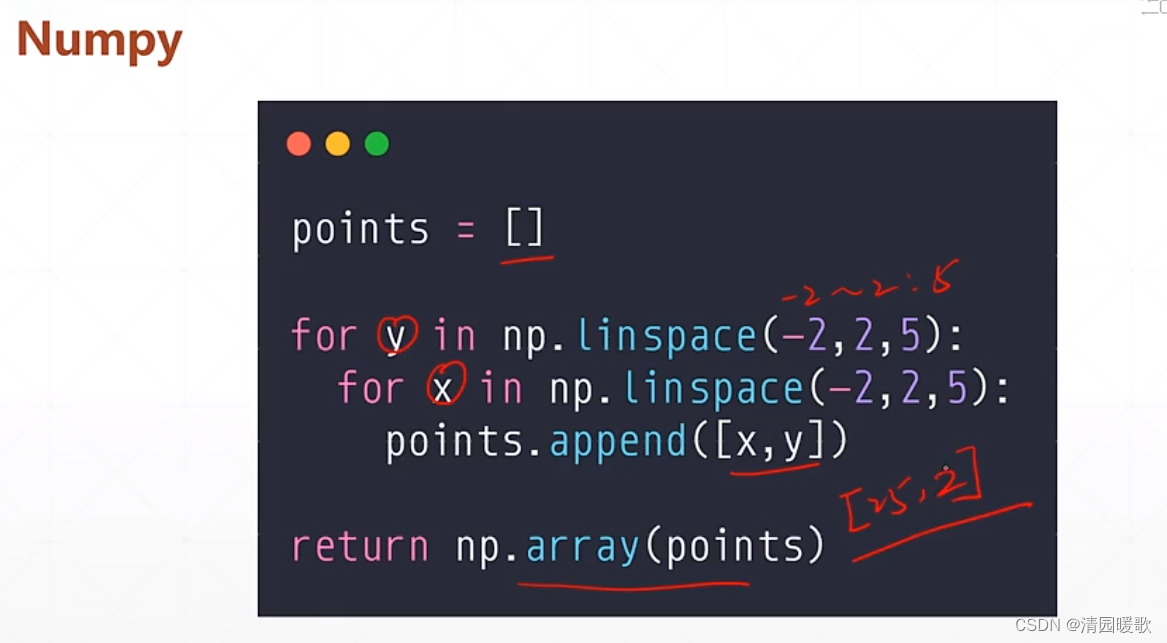
所以可以这样用

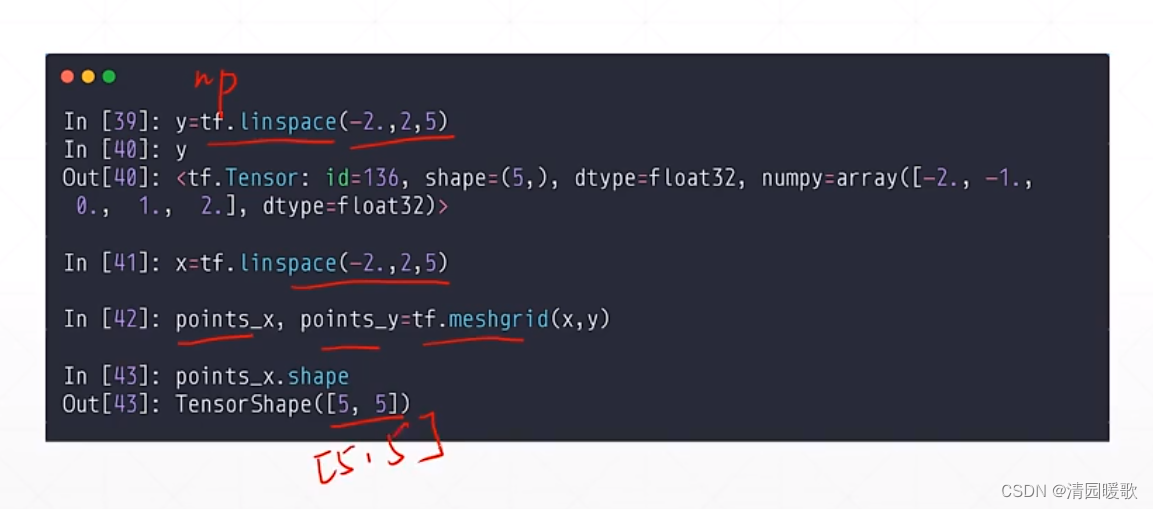
这个功能就叫做 meshgrid
先给一个范围 tf.linspace(-2.,2,5),用 tf.meshgrid 后返回的 x,y的shape都是 [5,5]
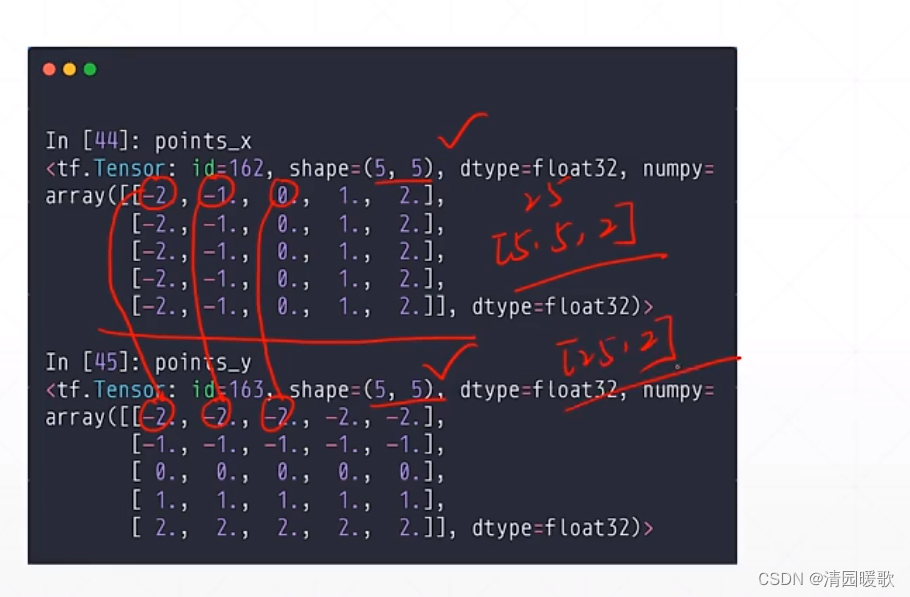
再 stack 一下
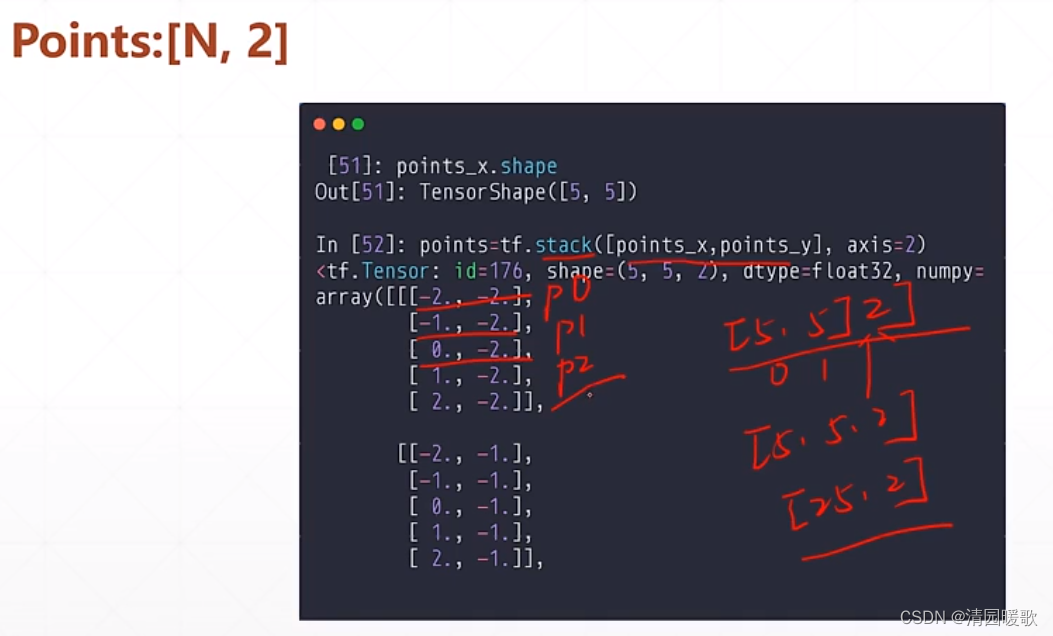
此时得到 [5,5,2] 的,再 reshape 一下就行
可以用来画出一个函数的 曲面,已知函数的等高线
代码: 高阶OP.py