前言
在前一章时我们已经介绍了类与对象的基本知识,包括类的概念与定义,以及类的访问限定符,类的实例化,类的大小的计算,以及C语言必须传递的this指针(C++中不需要我们传递,编译器自动帮我们实现)
但是仅仅只有这些还是不够的,类是面向对象编程语言的重中之重,对于它的理解我们应该继续深入,下面介绍类中的类中的6个默认成员函数中的前三个。
类与对象 二
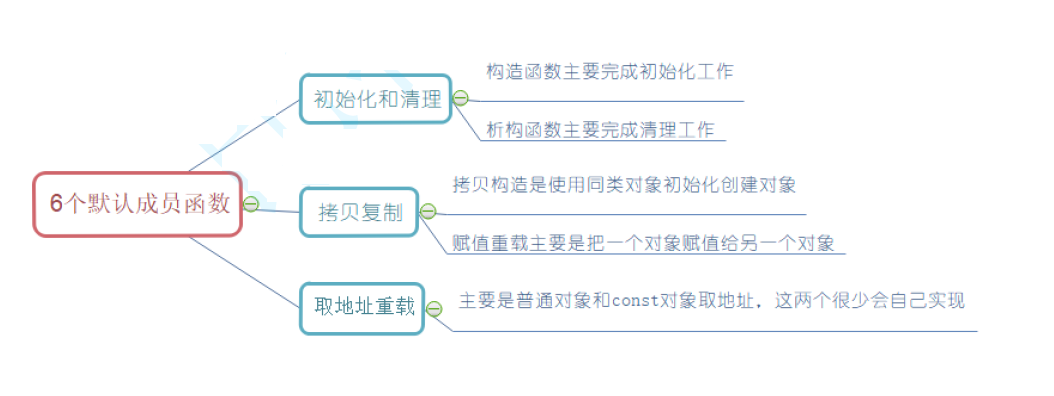
- 一、类的6个默认成员函数
- 二、构造函数
- 1、 引入
- 2、概念
- 3、特性
- 三、析构函数
- 1、概念
- 2、特性
- 四、拷贝构造函数
- 1、概念
- a.为什么需要拷贝构造?
- 2、特征
- 3.拷贝构造函数典型调用场景
- 五、结语
一、类的6个默认成员函数
如果一个类中什么成员都没有,简称为空类。
空类中真的什么都没有吗?并不是,任何类在什么都不写时,编译器会自动生成以下6个默认成员函数。
默认成员函数:用户没有显式实现,编译器会生成的成员函数称为默认成员函数。
空类:
class Date
{
};
二、构造函数
1、 引入
对于构造函数的使用场景我们先来看一段简单都代码:
#include<iostream>
#include<stdlib.h>
using namespace std;
typedef int DataType;
class Stack
{
public:
void Init(int _capacity = 4)//缺省参数
{
DataType* tmp = (DataType*)malloc(sizeof(DataType) * _capacity);
if (nullptr == tmp)
{
perror("malloc fail:");
exit(-1);
}
_a = tmp;
_Top = 0;
_capacity = _capacity;
}
void Push(int num)
{
//判断是否应该扩容
if (_Top - 1 == _capacity)
{
_capacity *= 2;
DataType* tmp = (DataType*)realloc(_a,sizeof(DataType) * _capacity);
if (nullptr == tmp)
{
perror("malloc fail:");
exit(-1);
}
_a = tmp;
}
_a[_Top] = num;
_Top++;
}
private:
DataType* _a;
int _Top;
int _capacity;
};
int main()
{
Stack s1;
s1.Push(1);
s1.Push(2);
s1.Push(3);
return 0;
}
运行之后崩了,思考为什么?
答案是:我们没有进行初始化我们的栈,我们没有给空间,自然而然就无法插入数据了!这是很正常的,对于这样没有初始化然后崩溃的例子有很多,我们每次都要使用栈时都要进行初始化,这让我们很不舒服,可不可以当我们创建对象时自动帮我们进行初始化呢?答案是可以的,那便是构造函数!
2、概念
构造函数是一个特殊的成员函数,名字与类名相同,创建类类型对象时由编译器自动调用,以保证每个数据成员都有 一个合适的初始值,并且在对象整个生命周期内只调用一次。
3、特性
构造函数是特殊的成员函数,需要注意的是,构造函数虽然名称叫构造,但是构造函数的主要任务并不是开空间创建对象,而是初始化对象。
其特征如下:
- 函数名与类名相同。
- 无返回值并且不允许我们写返回值。
- 对象实例化时编译器自动调用对应的构造函数。
- 构造函数可以重载。
- 如果类中没有显式定义构造函数(大白话:自己写构造函数),则C++编译器会自动生成一个无参的默认构造函数,一旦用户显式定义编译器将不再生成。
前面我们说了,当我们在类中在什么都不写时编译器会自动帮我们生成构造函数,当然编译器自动生成的构造函数未必是我们想要的,我们也可以自己写构造函数,当我们自己写了构造函数,那编译器就不会再为我们生成构造函数了。
那么我们来改造一下上面的这个代码吧
#include<iostream>
#include<stdlib.h>
using namespace std;
typedef int DataType;
class Stack
{
public:
Stack(int capacity = 4)//缺省参数,此类构造函数可以传也可以不传递形参
{
DataType* tmp = (DataType*)malloc(sizeof(DataType) * capacity);
if (nullptr == tmp)
{
perror("malloc fail:");
exit(-1);
}
_a = tmp;
_Top = 0;
_capacity = capacity;
}
void Push(int num)
{
//判断是否应该扩容
if (_Top - 1 == _capacity)
{
_capacity *= 2;
DataType* tmp = (DataType*)realloc(_a, sizeof(DataType) * _capacity);
if (nullptr == tmp)
{
perror("malloc fail:");
exit(-1);
}
_a = tmp;
}
_a[_Top] = num;
_Top++;
}
private:
DataType* _a;
int _Top;
int _capacity;
};
int main()
{
Stack s1(20);//此处不是函数调用,而是类的实例化顺便给构造函数传参数
//Stack s1; //如果是这样则会采用缺省值,即默认开辟4个int类型的空间大小。
s1.Push(1);
s1.Push(2);
s1.Push(3);
s1.Push(4);
s1.Push(5);
s1.Push(6);
s1.Push(7);
return 0;
}


代码运行成功了,说明编译器自动帮我们调用了我们写的Stack函数
我们再来看一个类的构造函数
#include<iostream>
using namespace std;
class Date
{
public:
Date()//无参数的构造函数
{
}
Date(int year, int month, int day)//函数重载
{
_year = year;
_month = month;
_day = day;
}
void Print()
{
cout << _year << "-" << _month << "-" << _day << endl;
}
private:
int _year;
int _month;
int _day;
};
int main()
{
Date d1();//报错,错误的调用无参构造函数,会被识别为函数声明!!!
//warning C4930: “Date d3(void)”: 未调用原型函数(是否是有意用变量定义的?)
Date d2;//正确的调用无参构造函数
Date d3(2023,2,10);//正确的调用必须传参的构造函数
};
注意:如果通过无参构造函数创建对象时,对象后面不用跟括号,否则就成了函数声明
看完了需要传递参数的构造函数与不需要传递参数的构造函数,我们再来看看编译器自己实现的构造函数
//不写构造函数
#include<iostream>
using namespace std;
class Date
{
public:
void Print()
{
cout << _year << "-" << _month << "-" << _day << endl;
}
private:
int _year;
int _month;
int _day;
};
int main()
{
Date d1;
d1.Print();
return 0;
};

答案很奇怪啊!不是说当我们不写构造函数时,编译器会自己生成一个构造函数吗?并且构造函数的作用就是给对象一个合理的初始化值啊?打印的结果为什么是一个随机值呢?系统生成的构造函数好像没有什么用啊???
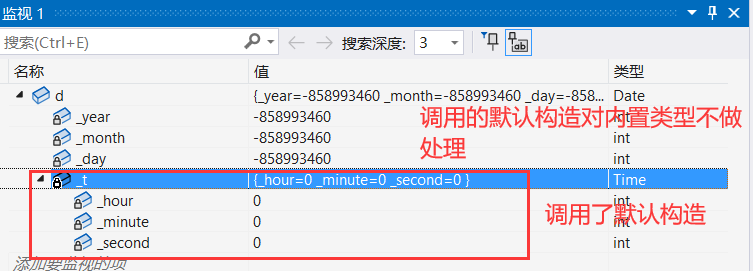
答案是:C++把类型分成内置类型(基本类型)和自定义类型。内置类型就是语言提供的数据类型,如:int/char…,指针,自定义类型就是我们使用class/struct/union等自己定义的类型。对于编译器生成的默认构造函数有以下规则:
对于默认生成的构造函数:
- 内置类型的成员不做处理
- 对于自定义类型的成员,会去调用它的默认构造函数。
(默认构造函数包含了:全缺省的构造函数,不用传递参数的构造函数,以及系统默认生成的构造函数)
对于上面的类由于类中的成员全是内置类型,根据以上规则编译器生成的默认构造函数对内置类型不做处理,于是我们看到的还是随机值。
我们看下面一个代码帮助你理解此条规则
#include<iostream>
using namespace std;
class Time
{
public:
Time()
{
cout << "Time()" << endl;
_hour = 0;
_minute = 0;
_second = 0;
}
private:
int _hour;
int _minute;
int _second;
};
class Date
{
private:
// 基本类型(内置类型)
int _year;
int _month;
int _day;
// 自定义类型
Time _t;
};
int main()
{
Date d;
return 0;
}
看完这个例子相信你对这条规则以及有所了解了,但是我们还有一个问题?我们就想让内置类型与自定义类型一起初始化该怎么办呢?
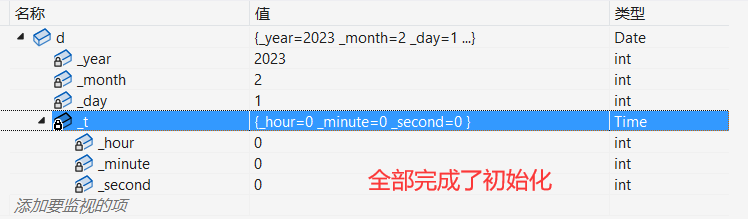
6 .C++11 中针对内置类型成员不初始化的缺陷,又打了补丁,即:内置类型成员变量在类中声明时可以给默认值。(类似缺省参数)
#include<iostream>
using namespace std;
class Time
{
public:
Time()
{
cout << "Time()" << endl;
_hour = 0;
_minute = 0;
_second = 0;
}
private:
int _hour;
int _minute;
int _second;
};
class Date
{
private:
// 基本类型(内置类型)
int _year = 2023; //给默认值
int _month = 2; //给默认值
int _day = 1; //给默认值
// 自定义类型
Time _t;
};
int main()
{
Date d;
return 0;
}
7.无参的构造函数和全缺省的构造函数都称为默认构造函数,并且默认构造函数只能有一个。
注意:无参构造函数、全缺省构造函数、我们没写编译器默认生成的构造函数,都可以认为是默认构造函数。
class Date
{
public:
Date()
{
_year = 1900;
_month = 1;
_day = 1;
}
Date(int year = 1900, int month = 1, int day = 1)
{
_year = year;
_month = month;
_day = day;
}
private:
int _year;
int _month;
int _day;
};
// 以下测试函数能通过编译吗?
int main()
{
Date d1;
return 0;
}
答案是不能,没有传递参数,函数不知道是应该调用无参的函数还是调用全缺省的函数
三、析构函数
1、概念
通过前面构造函数的学习,我们知道一个对象是怎么来的,那一个对象又是怎么没呢的?
析构函数:与构造函数功能相反,析构函数不是完成对对象本身的销毁,局部对象销毁工作是由编译器完成的。而对象在销毁时会自动调用析构函数,完成对象中资源的清理工作。
2、特性
析构函数是特殊的成员函数,其特征如下:
- 析构函数名是在类名前加上字符 ~。
- 无参数无返回值类型。
- 一个类只能有一个析构函数。若未显式定义,系统会自动生成默认的析构函数。注意:析构函数不能重载
- 对象生命周期结束时,C++编译系统系统自动调用析构函数。
实例代码:
#include<iostream>
using namespace std;
typedef int DataType;
class Stack
{
public:
Stack(int capacity = 3)
{
_array = (DataType*)malloc(sizeof(DataType) * capacity);
if (NULL == _array)
{
perror("malloc申请空间失败!!!");
return;
}
_capacity = capacity;
_size = 0;
}
void Push(DataType data)
{
// CheckCapacity();
_array[_size] = data;
_size++;
}
// 析构函数
~Stack()
{
if (_array)
{
free(_array);
_array = NULL;
_capacity = 0;
_size = 0;
}
cout << "~Stack()" << endl;
}
private:
DataType* _array;
int _capacity;
int _size;
};
int main()
{
Stack s;
s.Push(1);
s.Push(2);
}
5. 关于编译器自动生成的析构函数,是否会完成一些事情呢?下面的程序我们会看到,编译器生成的默认析构函数,对自定类型成员调用它的析构函数。
#include<iostream>
using namespace std;
class Time
{
public:
~Time()
{
cout << "~Time()" << endl;
}
private:
int _hour;
int _minute;
int _second;
};
class Date
{
private:
// 基本类型(内置类型)
int _year = 1970;
int _month = 1;
int _day = 1;
// 自定义类型
Time _t;
};
int main()
{
Date d;
return 0;
}
程序运行结束后输出:~Time()
在main方法中根本没有直接创建Time类的对象,为什么最后会调用Time类的析构函数?
因为:main方法中创建了Date对象d,而d中包含4个成员变量,其中 _year, month, day三个是内置类型成员,销毁时不需要资源清理,最后系统直接将其内存回收即可;
而_t是Time类对象,所以在d销毁时,要将其内部包含的Time类的 _t 对象销毁,所以要调用Time类的析构函数。
但是:main函数中不能直接调用Time类的析构函数,实际要释放的是Date类对象,所以编译器会调用Date类的析构函数,而Date没有显式提供,则编译器会给Date类生成一个默认的析构函数,目的是在其内部调用Time类的析构函数,即当Date对象销毁时,要保证其内部每个自定义对象都可以正确销毁。
main函数中并没有直接调用Time类析构函数,而是显式调用编译器为Date类生成的默认析构函数。
注意:创建哪个类的对象则调用该类的析构函数,销毁那个类的对象则调用该类的析构函数
四、拷贝构造函数
1、概念
在我们使用类创建对象时,难免会发生拷贝行为,例如创建对象时,可否创建一个与已存在对象一某一样的新对象呢?
拷贝构造函数:只有单个形参,该形参是对本类类型对象的引用(一般常用const修饰),在用已存在的类类型对象创建新对象时由编译器自动调用。
a.为什么需要拷贝构造?
C/C++编译器拷贝变量时,并不是一件简单的事情,对于内置类型来说C/C++编译器可以自己拷贝(按照一个字节一个字节拷贝),对于自定义类型C/C++编译器不能进行拷贝,只有通过拷贝函数来进行拷贝。

(栈的拷贝要使用拷贝函数进行深拷贝!!!)
2、特征
拷贝构造函数也是特殊的成员函数,其特征如下:
- 拷贝构造函数是构造函数的一个重载形式。
//拷贝构造函数
#include<iostream>
using namespace std;
class Date
{
public:
Date(int year = 1900, int month = 1, int day = 1)
{
_year = year;
_month = month;
_day = day;
}
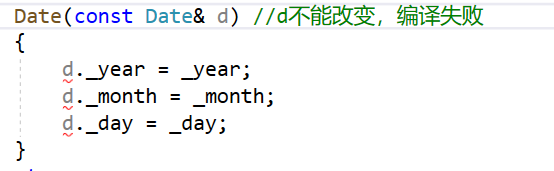
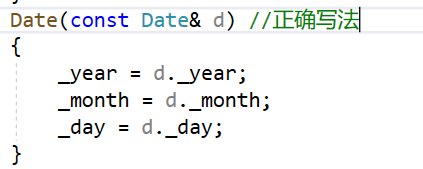
//Date(const Date d) // 错误写法:编译报错,会引发无穷递归
Date(const Date& d) // 正确写法
{
_year = d._year;
_month = d._month;
_day = d._day;
}
private:
int _year;
int _month;
int _day;
};
int main()
{
Date d1;
Date d2(d1);//利用拷贝构造创建一个与d1相同的d2
//Date d2 = d1;//与上一行的意思一致,要调用拷贝构造
return 0;
}
- 拷贝构造函数的参数只有一个且必须是类类型对象的引用,使用传值方式编译器直接报错,因为会引发无穷递归调用。
当我们想创建一个与d1相同数据的d2时要调用拷贝函数,
①调用拷贝函数要传递参数由于参数是形参,形参是实际参数的一份临时拷贝。
②于是我们又要调用拷贝函数,调用拷贝函数要传递参数由于参数是形参,形参是实际参数的一份临时拷贝。
③于是我们又又要调用拷贝函数,调用拷贝函数要传递参数由于参数是形参,形参是实际参数的一份临时拷贝。
④于是我们又又又要调用拷贝函数,调用拷贝函数要传递参数由于参数是形参,形参是实际参数的一份临时拷贝。
…
…
…
逻辑图:

还有一个问题就是拷贝构造的参数我们为什么要加const呢?
答案是:怕我们拷贝反了!

3.若未显式定义,编译器会生成默认的拷贝构造函数。 默认的拷贝构造函数对象按内存存储按字节序完成拷贝,这种拷贝叫做浅拷贝,或者值拷贝。
//默认生成的拷贝构造函数
#include<iostream>
using namespace std;
class Time
{
public:
Time()
{
_hour = 1;
_minute = 1;
_second = 1;
}
Time(const Time& t)
{
_hour = t._hour;
_minute = t._minute;
_second = t._second;
cout << "Time::Time(const Time&)" << endl;
}
private:
int _hour;
int _minute;
int _second;
};
class Date
{
private:
// 基本类型(内置类型)
int _year = 1970;
int _month = 1;
int _day = 1;
// 自定义类型
Time _t;
};
int main()
{
Date d1;
// 用已经存在的d1拷贝构造d2,此处会调用Date类的拷贝构造函数
// 但Date类并没有显式定义拷贝构造函数,则编译器会给Date类生成一个默认的拷贝构造函数
Date d2(d1);
return 0;
}
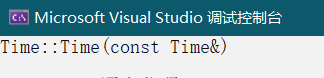
注意:在编译器生成的默认拷贝构造函数中,内置类型是按照字节方式直接拷贝的,而自定义类型是调用其拷贝构造函数完成拷贝的。
4.类中如果没有涉及资源申请时,拷贝构造函数是否写都可以;一旦涉及到资源申请时,则拷贝构造函数是一定要写的,否则就是浅拷贝。
思考一个问题:编译器生成的默认拷贝构造函数已经可以完成字节序的值拷贝了,对于内置类型我们还又必要写拷贝构造吗?答案是要不要写拷贝构造,我们还是要参考拷贝构造的特性4,有没有涉及支援申请!!!
我们看下面一段代码:
#include<iostream>
using namespace std;
typedef int DataType;
class Stack
{
public:
Stack(size_t capacity = 10)
{
_array = (DataType*)malloc(capacity * sizeof(DataType));
if (nullptr == _array)
{
perror("malloc申请空间失败");
return;
}
_size = 0;
_capacity = capacity;
}
void Push(const DataType& data)
{
// CheckCapacity();
_array[_size] = data;
_size++;
}
~Stack()
{
if (_array)
{
free(_array);
_array = nullptr;
_capacity = 0;
_size = 0;
}
}
private:
DataType* _array;
size_t _size;
size_t _capacity;
};
int main()
{
Stack s1;
s1.Push(1);
s1.Push(2);
s1.Push(3);
s1.Push(4);
return 0;
}

上面的代码需要拷贝构造,不然两个栈会相互影响!可以看到拷贝构造的特性4就是我们写不写拷贝构造的依据!
3.拷贝构造函数典型调用场景
- 使用已存在对象创建新对象
- 函数参数类型为类类型对象
- 函数返回值类型为类类型对象
提醒:为了提高程序效率,一般对象传参时,尽量使用引用类型,返回时根据实际场景,能用引用尽量使用引用。
五、结语
本章的内容对于初学者来说挺难的,但是这些成员函数非常重要,务必要好好理解!学会它们后相信你的水平会有进一步提高!