一、存储结构
1.1 表引擎语法结构
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2],
...
INDEX index_name1 expr1 TYPE type1(...) GRANULARITY value1,
INDEX index_name2 expr2 TYPE type2(...) GRANULARITY value2
) ENGINE = MergeTree() -- 表引擎
[PARTITION BY expr] -- 分区键
[ORDER BY expr] -- 排序键
[PRIMARY KEY expr] -- 主键
[SAMPLE BY expr] -- 抽样表达式
[SETTINGS name=value, ...] -- 索引配置项- 分区键,可以是某个列、也可以是多个列组成的元组,也可以是一个表达式。如果不声明分区键,则ClickHouse会生成一个名为all的分区
- 排序键,可以是某个列、也可以是多个列组成的元组
- 主键,默认与排序键相同,可以不声明,依照主键会生成一级索引
- 抽样表达式,声明数据以何种标准进行采样,如果配置此配置项,则需要在主键中声明相同的表达式,即按照主键进行抽样
- SETTINGS:
- index_granularity - 索引粒度,默认值8192,该值通常不需要修改,即每隔8192行数据生成一条索引
- index_granularity_bytes - 索引间隔,默认为10M,索引大小间隔,设置为0则不开启自适应功能
- enable_mixed_granularity_parts - 设置是否开启自适应索引间隔功能,默认开启
- merge_with_ttl_timeout - TTL功能
- storage_policy - 多路径存储策略
1.2 数据物理存储结构
MergeTree表引擎中的数据拥有物理存储,数据按照分区目录的形式保存在磁盘上,存储结构如下图:
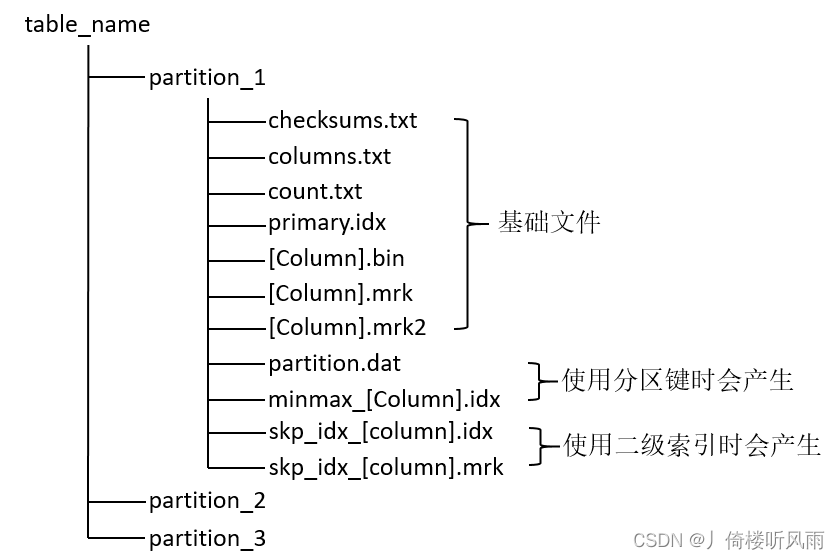
- parition:分区目录,相同分区的数据会被合并到同一分区目录,不同分区的数据永远不会被合并到一起
- checksums.txt:校验文件,二进制格式存储。包含primary.idx、count.txt等文件的大小(size)和size的哈希值,用于快速校验文件的完整性和正确性
- columns.txt:列信息文件,明文格式存储,用于保存此数据分区下的列字段信息
- count.txt:技术文件,明文格式存储,用于记录当前分区数据目录下的数据总行数
- primary.idx:一级索引文件,二进制格式存储。用于存放稀疏索引
- [Column].bin:数据文件,使用压缩格式存储,默认为LZ4压缩格式,用于存储某一列的数据
- [Column].mrk:列字段标记文件,二进制格式存储,保存了.bin文件中的数据偏移量信息。标记文件与稀疏索引对其,与.bin文件一一对应,MergeTree通过其建立primary.idx稀疏索引与.bin数据文件之间的映射关系
- [Column].mrk2:如果使用了自适应大小的索引间隔,则标记文件会以.mrk2命名,原理与.mrk类似
- partition.dat:二进制格式存储,保存当前分区下分区表达式最终生成的值
- minmax_[Column].idx:二进制格式存储,记录当前分区下分区字段对应原始数据的最小最大值
二、数据分区
2.1 数据分区规则
MergeTree数据分区规则由分区ID决定,每个分区ID是由分区键的取值决定,分区ID的生成逻辑规则有:
- 不指定分区键,如果不使用PARTITION BY声明任何分区表达式,则分区ID命名为all
- 整型:兼容UInt64,包括有符号整型和无符号整型
- 日期类型:分区键值属于日期类型,或能够转换为YYYYMMDD格式的整型,则按照YYYYMMDD进行格式化后的字符形式输出
- 其他类型:如果不是整型、日期类型,则通过128位Hash算法取Hash值作为分区ID值
2.2 分区目录的命名规则
分区目录命名公式:
PartitionID_MinBlockNum_MaxBlockNum_Level
- PartitionID:分区ID
- MinBlockNum/MaxBlockNum:最小数据块编号和最大数据块编号
- Level:合并的层级,及某个分区被合并过的次数,初始值为0
2.3 分区目录的合并过程
分区目录合并过程见下图:

三、索引
3.1 一级索引
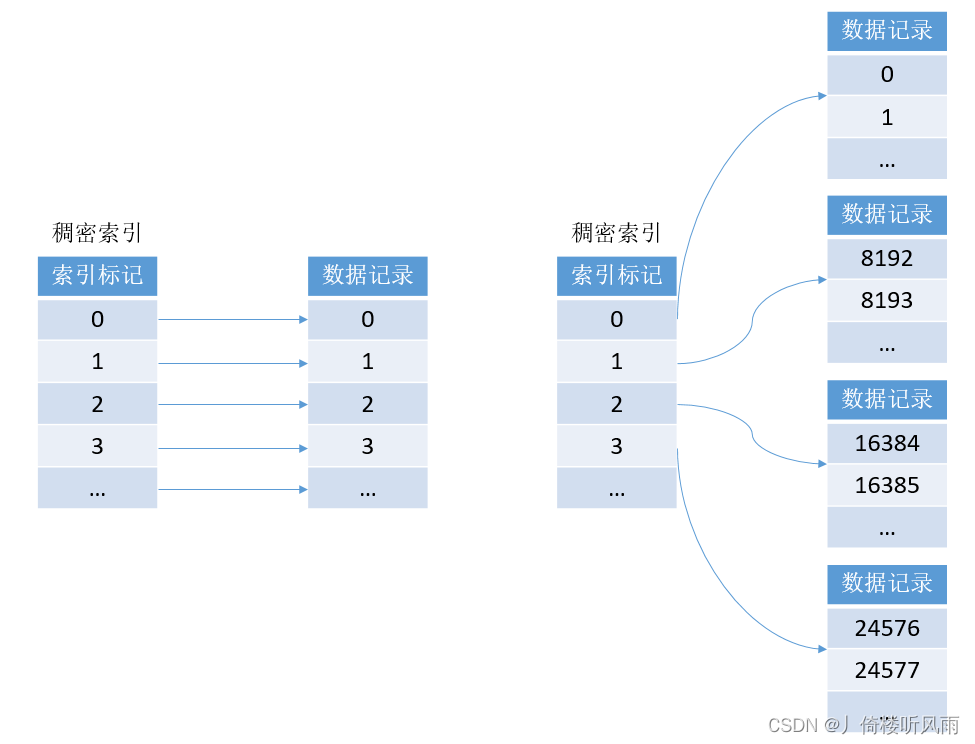
MergeTree的定义主键后,会依据index_granularity间隔(默认为8192行),为数据表生成一级索引并保存至primary.idx文件内,索引数据按照主键排序。
索引文件:primary.idx
索引实现:稀疏索引
优势:使用少量的索引标记能够记录大量数据的区间位置信息,数据量越大优势越明显
特点:以默认的索引粒度8192为例,MergeTree只需要12208行索引标记就能为1亿行数据记录提供索引。由于洗漱索引占用空间小,所以primary.idx内的索引数据常驻内存,读取速度很快。
3.2 二级索引
二级索引又称为跳数索引,由数据聚合信息构建而成。
关键参数:granularity
参数含义:按照index_granularity将数据划分为n个区间,再将granularity个区间聚合汇总生成一行minmax索引
索引类型:
- minmax:minmax索引记录一段数据内的最小和最大极值,能够快速跳过无用的数据区间
- set:set索引记录了声明字段或表达式的取值(唯一值、无重复),完整形式为set(max_rows),表示在index_granularity内,索引最多记录的数据行数,如果max_rows=0,则表示无限制
- ngrambf_v1:ngrambf_v1索引记录的是数据短语的布隆过滤器,只支持String和FixedString数据类型。只能够提升in、notIn、like、equals和notEquals查询的性能,完整形式为ngrambf_v1(n, size_of_bloom_filter_in_bytes, number_of_hash_functions, random_seed)
- n - 短语长度
- size_of_bloom_filter_in_bytes - 布隆过滤器大小
- number_of_hash_functions - 布隆过滤器使用Hash函数的个数
- random_seed:Hash函数的随机种子
- tokenbf_v1:tokenbf_v1索引是ngrambf_v1的变种,会自动按照非字符、数字的字符串分割token
五、数据存储
5.1 按列存储
MergeTree中,数据按列存储,每个列字段都拥有一个与之对应的.bin数据文件,数据目录以分区目录的形式存放,所以在.bin文件中只会保存当前分区片段内的这一部分数据。
写入前的处理:
- 数据需要经过压缩,默认使用LZ4算法
- 数据会事先依照order by 的声明排序
- 数据以压缩数据块的形式被组织并写入.bin文件
5.2 压缩数据块
压缩数据块由两部分组成:
- 头文件 —— 压缩算法、数据压缩后大小、数据压缩前大小
- 压缩数据
每个压缩数据块的体积,按照其压缩前的数据字节大小,都被严格控制在64kb~1MB之间,由min_compress_block_size(默认64k) 和max_compress_block_size(默认1M)限制其上下限。
写入过程,按照索引粒度,按批次获取数据并进行处理,其过程如下:
- 单个批次数据size < 64kb:如果单个批次数据小于64kb,则继续获取下一批次数据,直到累积size >= 64kb,生成下一个压缩数据块
- 单个批次数据64kb < size <= 1MB:则直接生成下一个压缩数据块
- 单个批次数据size > 1MB:首先按照1MB大小截断并生成下一个压缩数据块。剩余数据继续依据上述规则执行。此时一个批次数据会生成多个压缩数据块。
六、数据标记
数据标记就是记录了一级索引与压缩数据块的关联关系,基于此,能够很快地找到数据块中需要的数据。
工作方式:
- 读取解压数据块 —— 在查询某一列数据的时候,MergeTree无须一次性加载整个.bin文件,可以根据偏移量区间,获取指定的压缩数据块。如读取.bin文件中的[0, 10816]字节数据,就能获取第0个压缩数据块
- 读取数据 —— 在读取解压后的数据时,MergeTree并不需要一次性扫描整段解压数据,它可以根据偏移量按需读取数据。如通过[0, 8192]能够读取压缩数据块0中的第一个数据片段