BERT for Joint Intent Classification and Slot Filling代码复现【下】
链接直达:JointBERT代码复现详解【上】
四、模型训练与评估
Trainer
- training:梯度更新
- evaluate:评估序列标注任务如何得到预测结果、评估函数
1.初始化准备
def __init__(self, args, train_dataset=None, dev_dataset=None, test_dataset=None):
self.args = args
self.train_dataset = train_dataset
self.dev_dataset = dev_dataset
self.test_dataset = test_dataset
self.intent_label_lst = get_intent_labels(args)
self.slot_label_lst = get_slot_labels(args)
# Use cross entropy ignore index as padding label id so that only real label ids contribute to the loss later
self.pad_token_label_id = args.ignore_index
self.config_class, self.model_class, _ = MODEL_CLASSES[args.model_type]
self.config = self.config_class.from_pretrained(args.model_name_or_path, finetuning_task=args.task)
self.model = self.model_class.from_pretrained(args.model_name_or_path,
config=self.config,
args=args,
intent_label_lst=self.intent_label_lst,
slot_label_lst=self.slot_label_lst)
# GPU or CPU
self.device = "cuda" if torch.cuda.is_available() and not args.no_cuda else "cpu"
self.model.to(self.device)
2.模型训练
def train(self):
train_sampler = RandomSampler(self.train_dataset)
train_dataloader = DataLoader(self.train_dataset, sampler=train_sampler, batch_size=self.args.train_batch_size)
if self.args.max_steps > 0:
t_total = self.args.max_steps
self.args.num_train_epochs = self.args.max_steps // (len(train_dataloader) // self.args.gradient_accumulation_steps) + 1
else:
t_total = len(train_dataloader) // self.args.gradient_accumulation_steps * self.args.num_train_epochs
# Prepare optimizer and schedule (linear warmup and decay)
no_decay = ['bias', 'LayerNorm.weight']
optimizer_grouped_parameters = [
{'params': [p for n, p in self.model.named_parameters() if not any(nd in n for nd in no_decay)],
'weight_decay': self.args.weight_decay},
{'params': [p for n, p in self.model.named_parameters() if any(nd in n for nd in no_decay)], 'weight_decay': 0.0}
]
optimizer = AdamW(optimizer_grouped_parameters, lr=self.args.learning_rate, eps=self.args.adam_epsilon)
scheduler = get_linear_schedule_with_warmup(optimizer, num_warmup_steps=self.args.warmup_steps, num_training_steps=t_total)
# Train!
logger.info("***** Running training *****")
logger.info(" Num examples = %d", len(self.train_dataset))
logger.info(" Num Epochs = %d", self.args.num_train_epochs)
logger.info(" Total train batch size = %d", self.args.train_batch_size)
logger.info(" Gradient Accumulation steps = %d", self.args.gradient_accumulation_steps)
logger.info(" Total optimization steps = %d", t_total)
logger.info(" Logging steps = %d", self.args.logging_steps)
logger.info(" Save steps = %d", self.args.save_steps)
global_step = 0
tr_loss = 0.0
self.model.zero_grad()
train_iterator = trange(int(self.args.num_train_epochs), desc="Epoch")
for _ in train_iterator:
epoch_iterator = tqdm(train_dataloader, desc="Iteration")
for step, batch in enumerate(epoch_iterator):
self.model.train()
batch = tuple(t.to(self.device) for t in batch) # GPU or CPU
inputs = {'input_ids': batch[0],
'attention_mask': batch[1],
'intent_label_ids': batch[3],
'slot_labels_ids': batch[4]}
if self.args.model_type != 'distilbert':
inputs['token_type_ids'] = batch[2]
outputs = self.model(**inputs)
loss = outputs[0]
if self.args.gradient_accumulation_steps > 1:
loss = loss / self.args.gradient_accumulation_steps
loss.backward()
tr_loss += loss.item()
if (step + 1) % self.args.gradient_accumulation_steps == 0:
torch.nn.utils.clip_grad_norm_(self.model.parameters(), self.args.max_grad_norm)
optimizer.step()
scheduler.step() # Update learning rate schedule
self.model.zero_grad()
global_step += 1
if self.args.logging_steps > 0 and global_step % self.args.logging_steps == 0:
self.evaluate("dev")
if self.args.save_steps > 0 and global_step % self.args.save_steps == 0:
self.save_model()
if 0 < self.args.max_steps < global_step:
epoch_iterator.close()
break
if 0 < self.args.max_steps < global_step:
train_iterator.close()
break
return global_step, tr_loss / global_step
3.模型评估
def evaluate(self, mode):
if mode == 'test':
dataset = self.test_dataset
elif mode == 'dev':
dataset = self.dev_dataset
else:
raise Exception("Only dev and test dataset available")
eval_sampler = SequentialSampler(dataset)
eval_dataloader = DataLoader(dataset, sampler=eval_sampler, batch_size=self.args.eval_batch_size)
# Eval!
logger.info("***** Running evaluation on %s dataset *****", mode)
logger.info(" Num examples = %d", len(dataset))
logger.info(" Batch size = %d", self.args.eval_batch_size)
eval_loss = 0.0
nb_eval_steps = 0
intent_preds = None
slot_preds = None
out_intent_label_ids = None
out_slot_labels_ids = None
self.model.eval()
for batch in tqdm(eval_dataloader, desc="Evaluating"):
batch = tuple(t.to(self.device) for t in batch)
with torch.no_grad():
inputs = {'input_ids': batch[0],
'attention_mask': batch[1],
'intent_label_ids': batch[3],
'slot_labels_ids': batch[4]}
if self.args.model_type != 'distilbert':
inputs['token_type_ids'] = batch[2]
outputs = self.model(**inputs)
tmp_eval_loss, (intent_logits, slot_logits) = outputs[:2]
eval_loss += tmp_eval_loss.mean().item()
nb_eval_steps += 1
# Intent prediction
if intent_preds is None:
intent_preds = intent_logits.detach().cpu().numpy()
out_intent_label_ids = inputs['intent_label_ids'].detach().cpu().numpy()
else:
intent_preds = np.append(intent_preds, intent_logits.detach().cpu().numpy(), axis=0)
out_intent_label_ids = np.append(
out_intent_label_ids, inputs['intent_label_ids'].detach().cpu().numpy(), axis=0)
# Slot prediction
if slot_preds is None:
if self.args.use_crf:
# decode() in `torchcrf` returns list with best index directly
slot_preds = np.array(self.model.crf.decode(slot_logits))
else:
slot_preds = slot_logits.detach().cpu().numpy()
out_slot_labels_ids = inputs["slot_labels_ids"].detach().cpu().numpy()
else:
if self.args.use_crf:
slot_preds = np.append(slot_preds, np.array(self.model.crf.decode(slot_logits)), axis=0)
else:
slot_preds = np.append(slot_preds, slot_logits.detach().cpu().numpy(), axis=0)
out_slot_labels_ids = np.append(out_slot_labels_ids, inputs["slot_labels_ids"].detach().cpu().numpy(), axis=0)
eval_loss = eval_loss / nb_eval_steps
results = {
"loss": eval_loss
}
# Intent result
intent_preds = np.argmax(intent_preds, axis=1)
# Slot result
if not self.args.use_crf:
slot_preds = np.argmax(slot_preds, axis=2)
slot_label_map = {i: label for i, label in enumerate(self.slot_label_lst)}
out_slot_label_list = [[] for _ in range(out_slot_labels_ids.shape[0])]
slot_preds_list = [[] for _ in range(out_slot_labels_ids.shape[0])]
for i in range(out_slot_labels_ids.shape[0]):
for j in range(out_slot_labels_ids.shape[1]):
if out_slot_labels_ids[i, j] != self.pad_token_label_id:
out_slot_label_list[i].append(slot_label_map[out_slot_labels_ids[i][j]])
slot_preds_list[i].append(slot_label_map[slot_preds[i][j]])
total_result = compute_metrics(intent_preds, out_intent_label_ids, slot_preds_list, out_slot_label_list)
results.update(total_result)
logger.info("***** Eval results *****")
for key in sorted(results.keys()):
logger.info(" %s = %s", key, str(results[key]))
return results
4.保存模型
def save_model(self):
# Save model checkpoint (Overwrite)
if not os.path.exists(self.args.model_dir):
os.makedirs(self.args.model_dir)
model_to_save = self.model.module if hasattr(self.model, 'module') else self.model
model_to_save.save_pretrained(self.args.model_dir)
# Save training arguments together with the trained model
torch.save(self.args, os.path.join(self.args.model_dir, 'training_args.bin'))
logger.info("Saving model checkpoint to %s", self.args.model_dir)
5.加载模型
def load_model(self):
# Check whether model exists
if not os.path.exists(self.args.model_dir):
raise Exception("Model doesn't exists! Train first!")
try:
self.model = self.model_class.from_pretrained(self.args.model_dir,
args=self.args,
intent_label_lst=self.intent_label_lst,
slot_label_lst=self.slot_label_lst)
self.model.to(self.device)
logger.info("***** Model Loaded *****")
except:
raise Exception("Some model files might be missing...")
五、主函数
import argparse
from trainer import Trainer
from utils import init_logger, load_tokenizer, read_prediction_text, set_seed, MODEL_CLASSES, MODEL_PATH_MAP
from data_loader import load_and_cache_examples
def main(args):
init_logger()
set_seed(args)
tokenizer = load_tokenizer(args)
train_dataset = load_and_cache_examples(args, tokenizer, mode="train")
dev_dataset = load_and_cache_examples(args, tokenizer, mode="dev")
test_dataset = load_and_cache_examples(args, tokenizer, mode="test")
trainer = Trainer(args, train_dataset, dev_dataset, test_dataset)
if args.do_train:
trainer.train()
if args.do_eval:
trainer.load_model()
trainer.evaluate("test")
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument("--task", default=None, required=True, type=str, help="The name of the task to train")
parser.add_argument("--model_dir", default=None, required=True, type=str, help="Path to save, load model")
parser.add_argument("--data_dir", default="./data", type=str, help="The input data dir")
parser.add_argument("--intent_label_file", default="intent_label.txt", type=str, help="Intent Label file")
parser.add_argument("--slot_label_file", default="slot_label.txt", type=str, help="Slot Label file")
parser.add_argument("--model_type", default="bert", type=str, help="Model type selected in the list: " + ", ".join(MODEL_CLASSES.keys()))
parser.add_argument('--seed', type=int, default=1234, help="random seed for initialization")
parser.add_argument("--train_batch_size", default=32, type=int, help="Batch size for training.")
parser.add_argument("--eval_batch_size", default=64, type=int, help="Batch size for evaluation.")
parser.add_argument("--max_seq_len", default=50, type=int, help="The maximum total input sequence length after tokenization.")
parser.add_argument("--learning_rate", default=5e-5, type=float, help="The initial learning rate for Adam.")
parser.add_argument("--num_train_epochs", default=10.0, type=float, help="Total number of training epochs to perform.")
parser.add_argument("--weight_decay", default=0.0, type=float, help="Weight decay if we apply some.")
parser.add_argument('--gradient_accumulation_steps', type=int, default=1,
help="Number of updates steps to accumulate before performing a backward/update pass.")
parser.add_argument("--adam_epsilon", default=1e-8, type=float, help="Epsilon for Adam optimizer.")
parser.add_argument("--max_grad_norm", default=1.0, type=float, help="Max gradient norm.")
parser.add_argument("--max_steps", default=-1, type=int, help="If > 0: set total number of training steps to perform. Override num_train_epochs.")
parser.add_argument("--warmup_steps", default=0, type=int, help="Linear warmup over warmup_steps.")
parser.add_argument("--dropout_rate", default=0.1, type=float, help="Dropout for fully-connected layers")
parser.add_argument('--logging_steps', type=int, default=200, help="Log every X updates steps.")
parser.add_argument('--save_steps', type=int, default=200, help="Save checkpoint every X updates steps.")
parser.add_argument("--do_train", action="store_true", help="Whether to run training.")
parser.add_argument("--do_eval", action="store_true", help="Whether to run eval on the test set.")
parser.add_argument("--no_cuda", action="store_true", help="Avoid using CUDA when available")
parser.add_argument("--ignore_index", default=0, type=int,
help='Specifies a target value that is ignored and does not contribute to the input gradient')
parser.add_argument('--slot_loss_coef', type=float, default=1.0, help='Coefficient for the slot loss.')
# CRF option
parser.add_argument("--use_crf", action="store_true", help="Whether to use CRF")
parser.add_argument("--slot_pad_label", default="PAD", type=str, help="Pad token for slot label pad (to be ignore when calculate loss)")
args = parser.parse_args()
args.model_name_or_path = MODEL_PATH_MAP[args.model_type]
main(args)
六、训练参数设置
1.基础参数
--task atis
--model_type bert
--model_dir experiments/jointbert_0
--do_train --do_eval
--train_batch_size 8
--learning_rate 5e-5
intent_acc = 0.92721164613
slot_f1 = 0.8046902345
sementic_frame_acc = 0.58566629339
2.设置线性层学习率
--task atis
--model_type bert
--model_dir experiments/jointbert_0
--do_train --do_eval
--train_batch_size 8
--learning_rate 5e-5
--linear_learning_rate 5e-4
intent_acc = 0.95744680851
slot_f1 = 0.9156920928
sementic_frame_acc = 0.77939529675
3.加上CRF,设置CRF学习率
--task atis
--model_type bert
--model_dir experiments/jointbert_0
--do_train --do_eval
--train_batch_size 8
--learning_rate 5e-5
--linear_learning_rate 5e-4
--use_crf
--crf_learning_rate 5e-5
intent_acc = 0.93281075
slot_f1 = 0.9227542817
sementic_frame_acc = 0.78275475923
4.增加CRF学习率数量级
--task atis
--model_type bert
--model_dir experiments/jointbert_0
--do_train
--do_eval
--train_batch_size 8
--learning_rate 5e-5
--linear_learning_rate 5e-4
--use_crf
--crf_learning_rate 5e-3
intent_acc = 0.94736842
slot_f1 = 0.93968253
sementic_frame_acc = 0.812989921
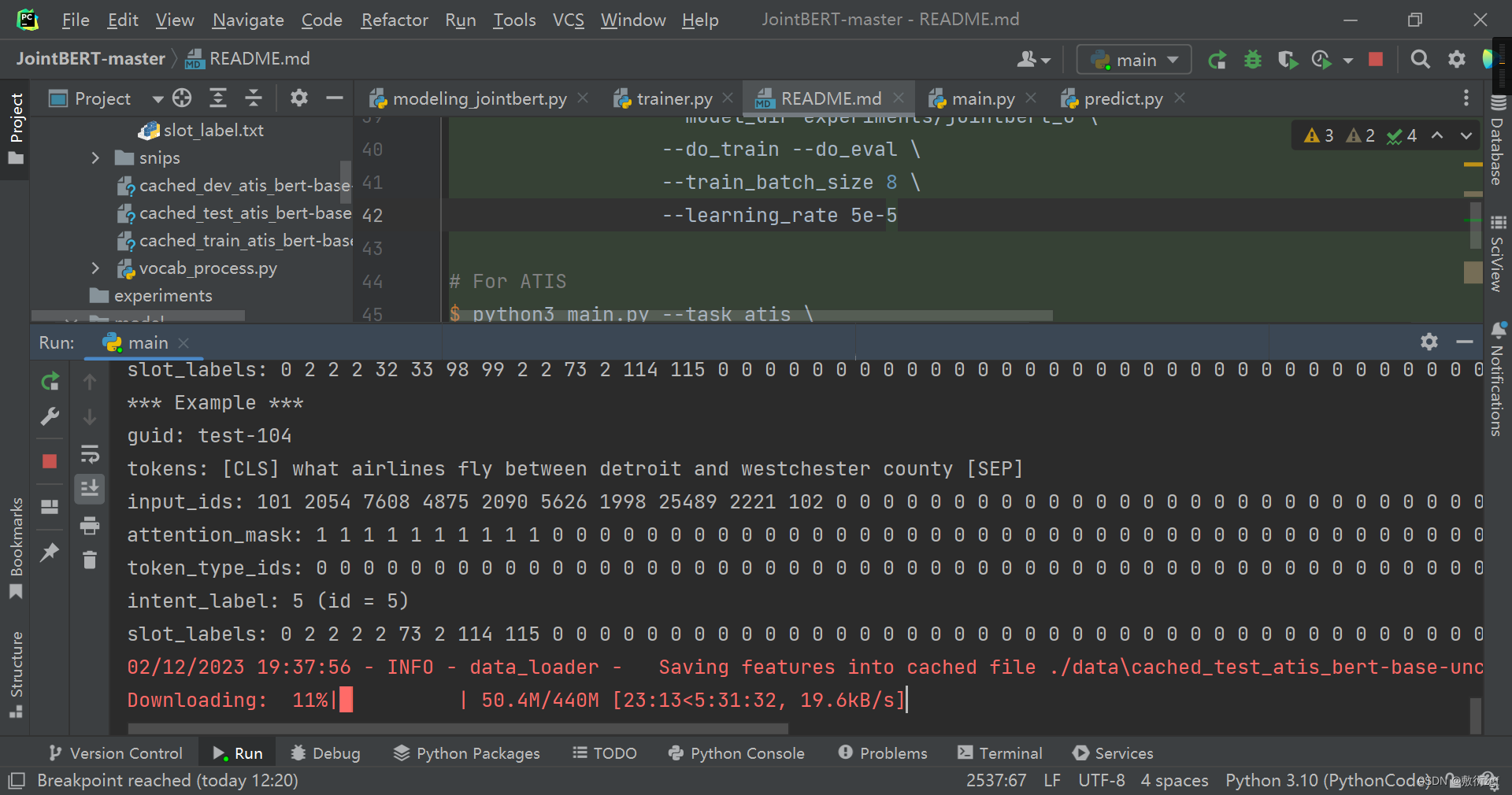
针对不同学习率训练模型,效果随着学习率数量级的增加有显著提升。