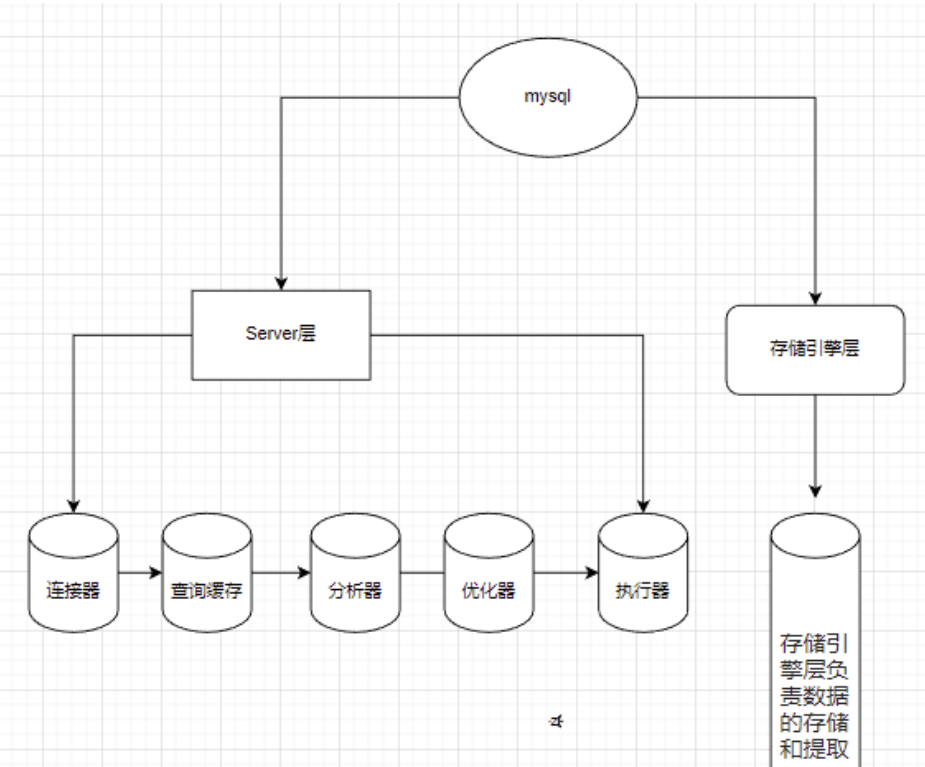
2.2.2、Join Type
2.2.2.1、Broadcast Hash Join (Not Shuffled)
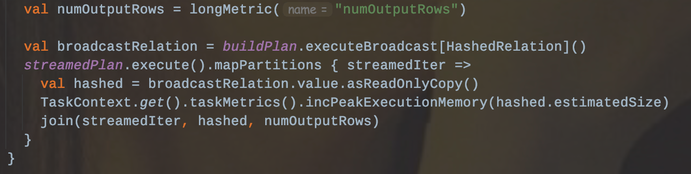
就是常说的MapJoin,join操作在map端进行的。
场景:join的其中一张表要很小,可以放到Driver或者Executor端的内存中。
原理:
1、将小表的数据广播到所有的Executor端,利用collect算子将小表数据从Executor端拉到Driver端,然后在Driver端使用广播到Executor端
2、Executor端将大表和这个广播数据进行Join,这样就避免了Shuffle.
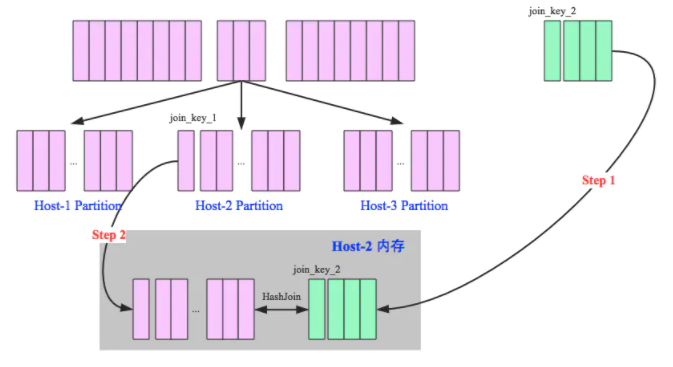
条件:
1、小表必须足够小,可以通过spark.sql.autoBroadcastJoinThreshold参数来设置,默认是10MB。如果设置为-1,则关闭Broadcast Hash Join
2、只能用于等值Join,不要求参与Join的keys排序
3、除了full outer join,支持其他所有Join
4、人为添加Hint(MAPJOIN、BROADCASTJOIN、BROADCAST) (Option)
2.2.2.2、Broadcast Nested Loop Join (Fallback option)
该Join策略是在没有合适的Join机制可以选择的时候,最后选择的一种。在Cartesian和Broadcast Nested Loop Join之间,如果是内连接,或者是非等值连接,那么会优先选择Broadcast Nested Loop策略。该类型Join会根据相关条件对小表进行广播,以减少表的扫描次数。触发条件:
1、Rigth Outer Join是会广播左表
2、Left Outer,Left semi ,Left Anti或者existence Join会广播右表
3、inner join的时候两张表都会广播
条件:
支持等值和非等值Join。
2.2.2.3、Shuffle Hash Join(Single Partition is small engough to build a hash table)
当Join一张小表的时候,可以使用Broadcast Hash Join,但是如果小表逐渐变大,那么广播所需要的内存、网络IO资源也相应变大,所以如果小表的数据量超过了10M的限制,那么可以使用Shuffle Hash Join策略。
原理:(Key相同,分区必然相同)
1、Shuffle:大表和小表按照相同分区算法和分区数进行分区(根据参与join的keys进行分区),这样保证了hash值一样的数据都被分发到了同一个分区中,然后在同一个Executor中两个表hash值一样的分区就可以进行本地hash join了。
2、单机Hash Join:在进行join之前,还会对小表hash完的分区构建hash map。shuffle hash join采用了分治思想,把大问题拆解成小问题去解决
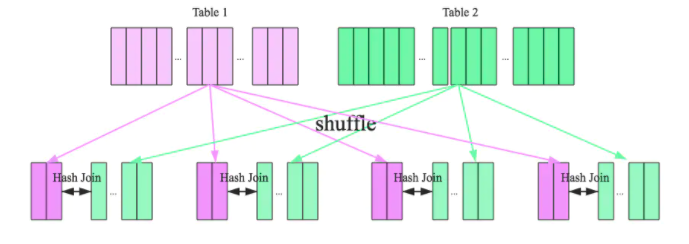
条件:
1、仅支持等值join,不要求参与join的keys排序
2、spark.sql.join.preferSortMergeJoin 参数必须设置为 false,参数是从 Spark 2.0.0 版本引入的,默认值为 true,也就是默认情况下选择 Sort Merge Join
3、小表的大小(plan.stats.sizeInBytes)必须小于 spark.sql.autoBroadcastJoinThreshold * spark.sql.shuffle.partitions;而且小表大小(stats.sizeInBytes)的三倍必须小于等于大表的大小(stats.sizeInBytes),也就是 a.stats.sizeInBytes * 3 < = b.stats.sizeInBytes

2.2.2.4、Shuffle Sort Merge Join (Matching join keys are sortable)
Hash Join通常适用于存在至少一个小表的情况,但如果都是大表的话,那么就需要考虑Sort Merge Join了。该Join策略是Spark默认的,可以通过spark.sql.join.preferSortMergeJoin进行配置(默认就是true)
原理:
1、Shuffle阶段:对两个表参与Join的keys使用相同的分区算法和分区数进行分区,目的就是为了保障相同的key都分配到相同的分区里面
2、Sort阶段:分区之后再对每个分区按照参与keys进行排序
3、Merge阶段:最后reducer端获取两张表相同分区的数据基于顺序查找的方式进行Merge Join,如果keys相同就说明join上了。如果流表的迭代遍历器得到的Key值比构建表迭代得到的Key值小,那么就移动流表的迭代器;如果流表的迭代遍历器比构建表迭代得到的Key值要大,那么则移动构建表的迭代器;如果二者相同,则说明满足Join条件。
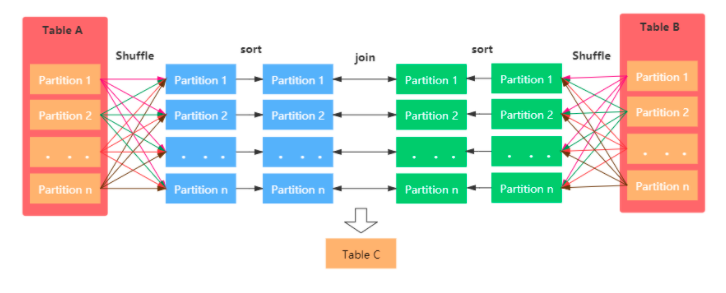
条件:
仅支持等值join,而且要求参与join的keys是可排序的
2.2.2.5、Cartesian Product Nested Loop Join
如果Spark中多个表参与Join而且没有指定Key,那么就会产生Cartesian Product Join。
产生的数据行数是两表的乘积,当Join的表很大的时候,效率是非常低的。尽量不使用
条件:
1、必须是inner join,支持等值和不等值Join
2、参数spark.sql.crossJoin.enabled=true
2.2.2.6、Conclusion
Spark2.4 + 引入了Join Hint,来优化spark的计算引擎,从而选择正确的Join策略。当然用户也可以手动选择策。用户指定的Join Hint优先级是最高的。逻辑如下:
1、先判断是不是等值Join
1.1、判断用户是否指定了BroadCast Hint(Broadcast、BroadcastJoin以及MapJoin中的一个),如果指定了则用Broadcast Hash Join。
1.2、判断用户是否指定了Shuffle Merge Hint(Shuffle_Merge,Merge以及MergeJoin中的一个),如果指定了则用Shuffle Sort Merge。
1.3、判断用户是否指定了Shuffle Hash Join Hint(SHUFFLE_HASH),如果指定了则用Shuffle Hash Join。
1.4、判断用户是否指定了Shuffle-and-replicate Nested Loop Join(SHUFFLE_REPLICATE_NL),如果指定了则用Cartesian Product Join。
1.5、如果用户没有指定任何Join Hint,那么就根据Join的策略Broadcast Hash Join ---> Shuffle Hash Join --> Sort Merge Join ---> Cartesian Product Join --> Broadcast Nested Loop Join顺序选择Join策略。
2、如果不是等值Join,则按照下面的顺序选择Join策略
2.1、判断用户是不是指定了 BROADCAST hint (BROADCAST、BROADCASTJOIN 以及 MAPJOIN 中的一个),如果指定了,那就广播对应的表,并选择 Broadcast Nested Loop Join;
2.2、用户是不是指定了 shuffle-and-replicate nested loop join hint (SHUFFLE_REPLICATE_NL),如果指定了,那就用 Cartesian product join;
2.3、如果用户没有指定任何 Join hint,那根据 Join 的适用条件按照 Broadcast Nested Loop Join--->Cartesian Product Join 顺序选择 Join 策略