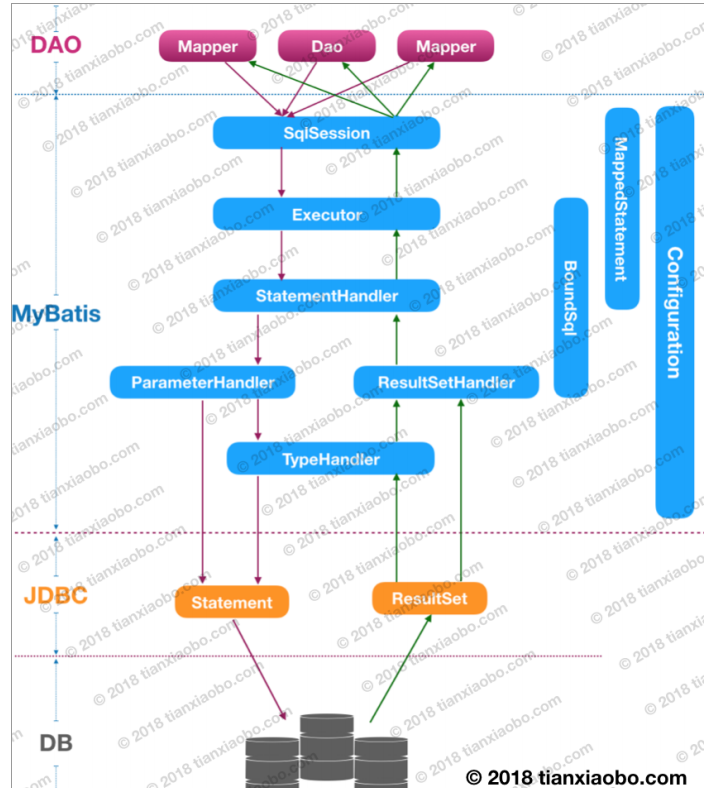
讲解顺序
先说 Mysql InnoDB 内存结构
- Buffer Pool
- Page 管理机制
- Change Buffer
- Log Buffer
Buffer Pool
接上回 说到了 LRU 算法对内存的数据 进行淘汰
LRU 算法本身是 最近最少使用的,但是这样就会出现 分不清楚 哪些是真正多次使用的数据
LRU缺点:
- 如果发生全表扫描,会把表中的所有页加载到内存,会将真正需要缓存的热数据 淘汰掉
- Mysql 中存在预读机制,很多预读的页放到LRU的头部,如果这些预读没有得到应用,就会导致真正的热数据被淘汰了 所以需要对LRU 算法进行改进

看到这里 我有几个疑问

思考:为什么 热/冷数据 占比是 63%,37%呢? 不能每个一半么?为什么这么设计啊?ist
肯定从官网下手了,
刚开始查询 “innoD lru” 本来以为 能有类似的吧。。。结果很尴尬,不给力啊,看来要换个方向 查询了, 这个 63 37 是配置出来的,对应参数是什么呢?
热数据部分(young区域)和冷数据部分(old区域)。每个部分所占的比例可以通过innodb_old_blocks_pct参数来指定,默认为37,意思是冷数据占比37%。实际上数据第一次被加载到缓存的时候是放在冷数据区链表的头部。当被加载到冷数据区的头部之后经过指定的时间后被访问了的数据就会被移动到热数据区的链表头部。这个指定时间是通过innodb_old_blocks_time指定的,默认为1000ms也就是1秒。
什么? 你问我 是不是百度出来的,没错,我是百度的,但是你也可以自己去找啊。。。
毕竟还是本地查找比较快,我一般是 本地查找
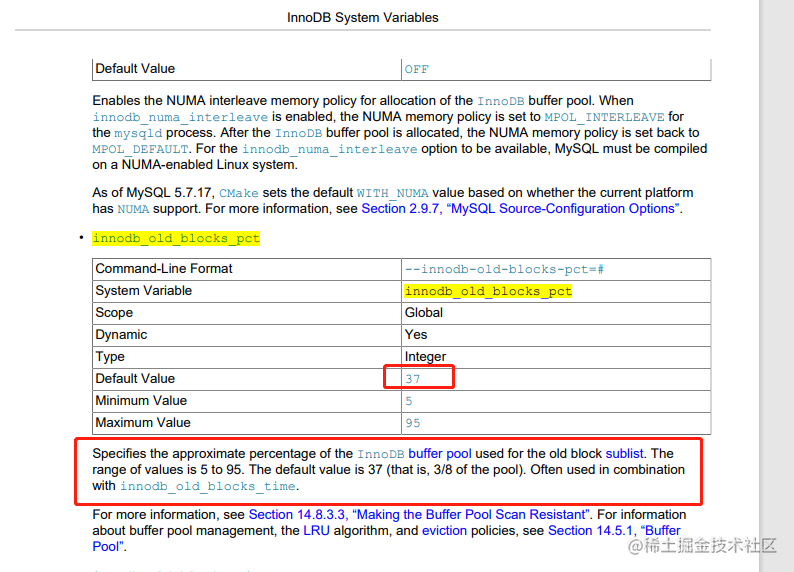
简单来说就是 innodb_old_blocks_pct 指定用于old的InnoDB缓冲池的大约百分比,代表着 冷数据默认是 37%。取值范围为5 ~ 95。默认值为37(即池的3/8)。常和 innodb_old_blocks_time 一起使用。
看到这,又想想 innodb_old_blocks_time 干什么的啊。。。
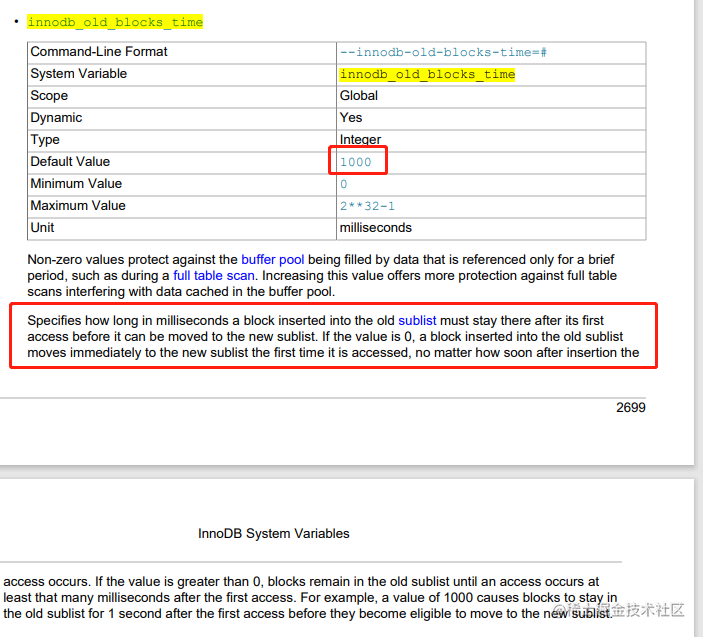
innodb_old_blocks_time 就是 多长时间的数据 能从 冷数据区 转移到 热数据区,默认值 1000ms 1s
你说这么说,还是没有说明白,为什么冷数据 37% 啊,嗯嗯,是的,其实这个问题,一想就知道 肯定是官方当时 做的基准测试,得出的结论,而且也给我们留了口子,行吧 不细研究了。
自己想想也是,热数据肯定要大点,然后冷数据每次淘汰到 只剩5% 才能进入热数据,具体为什么,看了github 、 官网 是没有找到,先放放
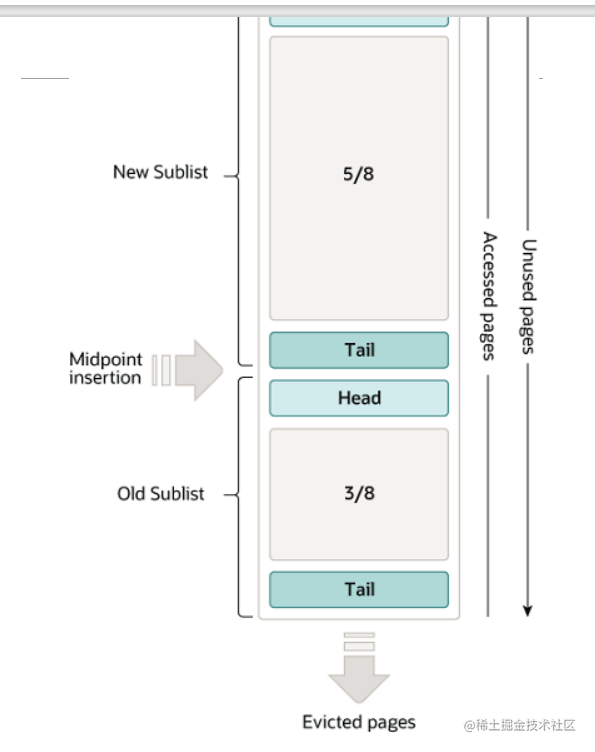
冷数据区的数据页什么时候被转到热数据区?
- 该页在LRU链表中 存在时间超过1s,就被移动到链表的头部,如果没到1s,保持其位置不动
innodb_old_blocks_time 就是那个时间限制,
说实话 其实 我看到 young、old的定义的时候 ,我最开始想到的是jvm的 年轻代和 老年代old区,我本来以为是 先放到 young 区 然后通过几次刷,才会到old。但是mysql 这块是反的,从磁盘查询上来的数据 优先放在了old区,后面真正被访问到时才将其挪入到young区链表头部,将young区数据页淘汰的放入old区头部。预读的数据后面如果一直没有被访问,优先淘汰old区的数据页,因此不会影响young区的热点数据。
jvm 和 mysql
其实 jvm 和 mysql 都一样,只是叫法不一样
jvm 和 mysql的区别在于,jvm 是希望把经常使用的数据 放到 old区,之后 old区实在放不下才会gc,一般不gc,而mysql 希望把经常使用的数据 放到 young 热数据区,但是热数据区也有正常的淘汰机制,每次希望old区有 5%的数据进入到 young区 进行替换,让young 一直保持 热数据。。。概念一样,场景不同而已
思考:超过1s了 冷数据就被 移动到热数据的头部了?
首先想想 如果放到头部,会有什么后果?
属于 新来的和尚会念经?你刚从冷数据区 过来,可能 我本身是 元老了(真正的经常使用的数据)
这不行啊,只能让你 从冷数据区,慢慢的往热数据的头 移动,属于排名了,按照访问量
这块你可能想说,那不对啊,你说按照访问量 排序,那可能我先调用一个数据页(A数据页)的查询 1000次,但是过期了,后面来一个真正的查询数据页(B数据页),怎么我也到不到老大的位置啊。。。。坑
但是 请注意 这是 lru,经常用的数据 会移动到头部的,所以上面说的情况不存在,哈哈,皮
热数据区 难道每次访问我都需要移动point 么?
不,我不想,能省一步 是一步啊,不要瞎搞
- 如果热数据链表前25%(1/4)的缓存页被访问,他们是不会被移动的
- 只有在后75%(3/4)中的缓存页被访问,才会移动到表头,这样就能尽可能的减少链表中节点的移动,从而减小性能的损耗
LRU列表中有一个Midpoint的位置,新读取到的数据页并不是直接放入到LRU列表的首部,而是放入到LRU列表的Midpoint位置,这个操作称之为Midpoint insertion stategy,也叫中间点插入策略。
这就涉及 热数据的淘汰是怎么做的?
MySQL的预读机制
每16kb为一页,连续64个页就是一个区,默认占用1MB,每256个区被划分成一个组。
上面LRU 缺点第二点说到了 预读机制,有两点
- 如果内存中 有同一个区中的多个数据页,默认是56个,就会把下一个区中所有的数据页都加载到缓存页里,通过参数innodb_read_ahead_threshold控制,默认是56。
- 如果 缓存了一个区的13个连续数据页,就会触发预读机制,把这个区里的页全都加载到缓存页里。通过参数innodb_random_read_ahead控制,默认是off
思考: 这两个参数怎么看,我现在默认是什么啊?
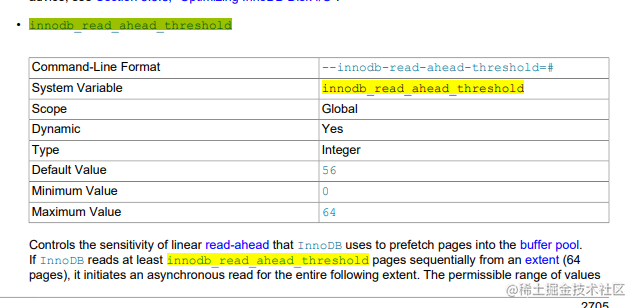
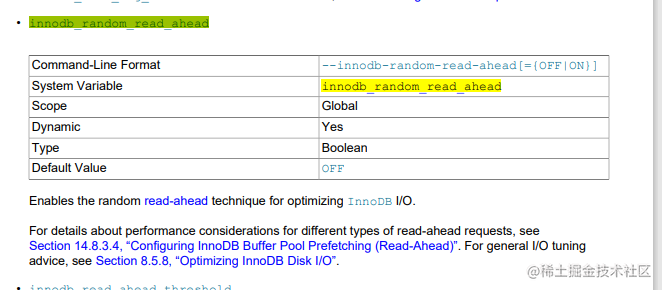
思考: mysql 那么多默认参数,默认值是放在哪里的啊?

在 my.cnf 或者 my.ini中
实际开发中的联想
说了这么多理论,没什么用。这些东西在实际开发中能用上什么呢?
我主要是 写中间件的时候 关于内存的时候 用上了,其实之前学mysql的时候 模仿这个 结构自己写过一个demo ,后面直接用的 哈哈
还有wal 想保证数据落到磁盘,不过实际开发中 还是用文件 bak 比较多 哈哈
总结
mysql InnoDB buffer Pool 到这就简单结束了