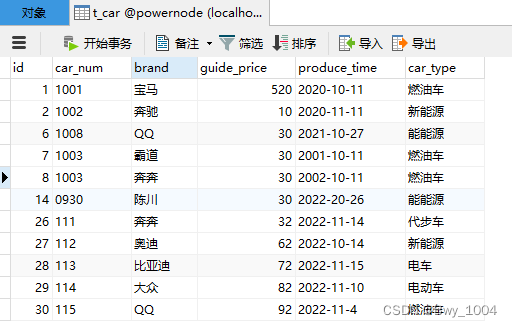
今天在写业务需要对数据库重复字段进行去重时,因为是去重,首先想到的是distinct关键字。于是一小时过去了。。。。(菜鸟一个,大家轻点骂)
我把问题的过程用sql语句演示给大家演示一下
首先我使用的是mybatis-plus,代码如下
QueryWrapper<ProjectCompany> wrapper = new QueryWrapper<>();
wrapper.select("DISTINCT project_id,company_id,company_name,is_delete").eq("project_id",projectId).eq("is_delete","0");
即 "DISTINCT project_id,company_id,company_name,is_delete"
查出的结果

id=null。这是我不希望看到的。没有id的话,下面的业务就不好走了。
于是我在distinct后面加上了id,distinct查出来的数据就是全部数据了,相当于distinct没起作用。冥思苦想一小时。。。。
后来想到了group by分组,于是用了一下
LambdaQueryWrapper<ProjectCompany> wrapper = new LambdaQueryWrapper<>();
wrapper.eq(ProjectCompany::getProjectId,projectId).eq(ProjectCompany::getIsDelete,"0").groupBy(ProjectCompany::getProjectId);
LambdaQueryWrapper<ProjectCompany> wrapper = new LambdaQueryWrapper<>();
wrapper.eq(ProjectCompany::getProjectId,projectId).eq(ProjectCompany::getIsDelete,"0").groupBy(ProjectCompany::getProjectId);
发现查出来的数据也进行去重了,id也有值
所以就很好奇 distinct和group by有啥区别,大概总结以下几点:
distinct适合查单个字段去重,支持单列、多列的去重方式。 单列去重的方式简明易懂,即相同值只保留1个。
多列的去重则是根据指定的去重的列信息来进行,即只有所有指定的列信息都相同,才会被认为是重复的信息。
而 group by 可以针对要查询的全部字段中的部分字段去重,它的作用主要是:获取数据表中以分组字段为依据的其他统计数据。