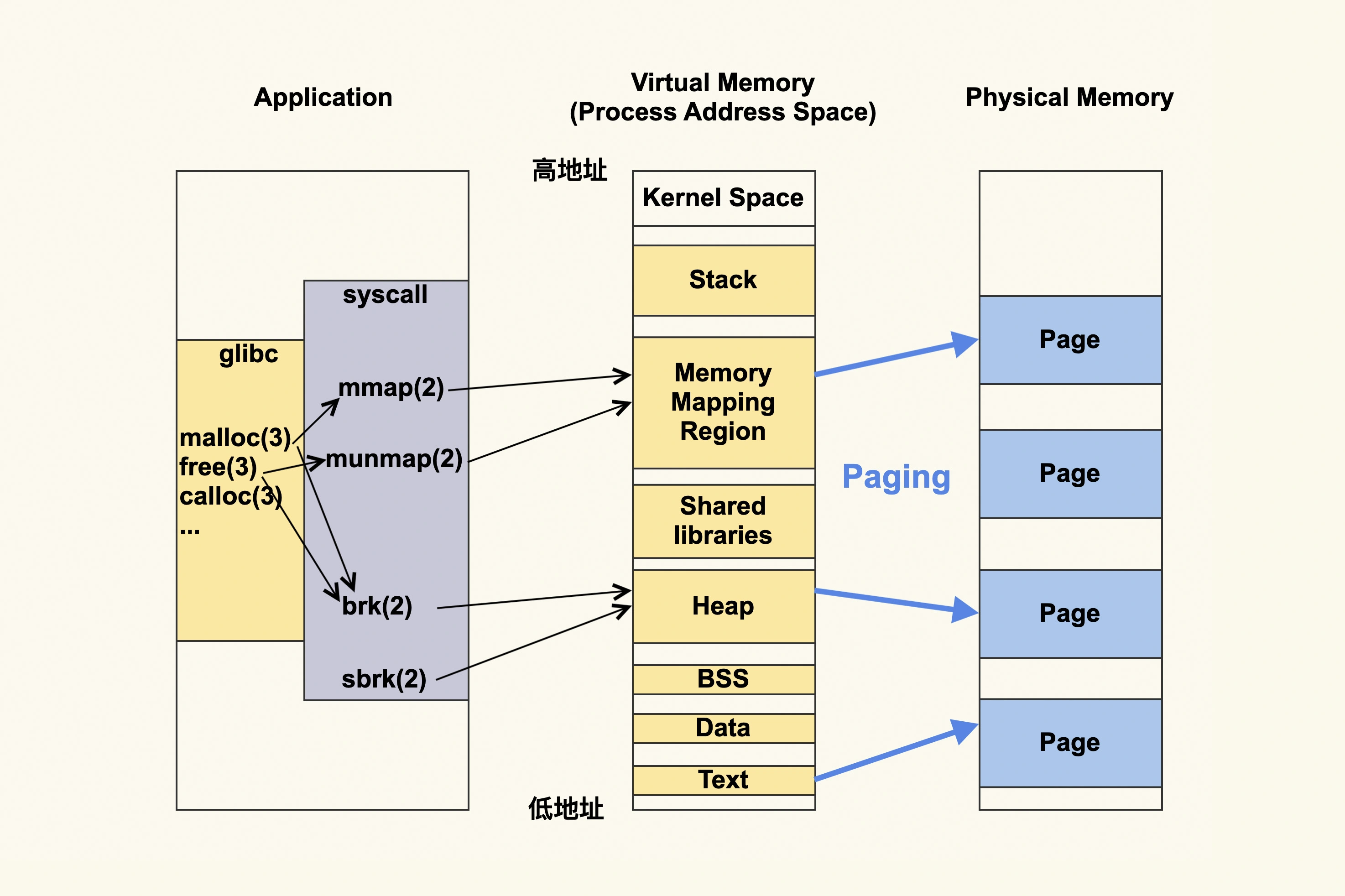
向量(vector)
R 语言最基本的数据结构是向量。类似于数学上的集合的概念,由一个或多个元素构成。向量其实是用于存储数值型、字符型、或逻辑型数据的一维数组。
创建向量
c()函数
> a <- 1 #给a赋值1
> a #显示a的值
[1] 1
> int_vec <- c (1L, 2L, 3L) #用c()创建向量,L表示整数常数
> int_vec
[1] 1 2 3
> 2:5
[1] 2 3 4 5
- R中不存在标量类型的数据,一个整数或字符也被看成长度为1的向量。
- 用赋值的方式可以创建向量。
- 用c()函数也可以创建向量。 c()可将参数中的多个元素组合成一个向量,在整数后面加上L创建整数类型值,否则,R会将数字自动处理为浮点型(double),使用 typeof (对象)判断对象的类型。
- 还可以用符号“:”函数创建向量
✨如何创建一个向量1 2 3 4 5 8 0 6 7 8 9 ?
> x <- c(1:9)
> x
[1] 1 2 3 4 5 6 7 8 9
✨如何创建下图所示向量?

> x <- c(2:5,letters,6:9)
> x
[1] "2" "3" "4" "5" "a" "b" "c" "d" "e" "f" "g" "h" "i" "j" "k"
[16] "l" "m" "n" "o" "p" "q" "r" "s" "t" "u" "v" "w" "x" "y" "z"
[31] "6" "7" "8" "9"
> a<-c(1, 3, 5, 7, 9) #数值型向量
> a<-c(“one”,“two”,“three”) #字符型向量
> a<-c(TRUE,FALSE,TURE,TRUE) #逻辑型向量
> a<-c(T,F,T)
> f<-3 #标量
> g<-”HGU” #标量
> h<-TURE #标量
> x<-c(1,2,"one")
> x
[1] "1" "2" "one"
- 单个向量中的数据必须拥有相同的类型或模式。
- 标量是只含一个元素的向量
- 向量中包含数值型和字符型,向量的类型为字符型
✨c()不但能对数量进行连接,也能对向量进行连接
> y<-c(2,5,8,9,0)
> x<-c(y,-1,y)
> x
[1] 2 5 8 9 0 -1 2 5 8 9 0
✨对向量做逻辑运算,构造逻辑向量
> y<-c(2,5,8,9,0)
> Flag<-y>5
> Flag
[1] FALSE FALSE TRUE TRUE FALSE
seq()函数
提问:如果创建1-100的奇数列,如何进行?依然使用c函数吗?这里我们引入seq()函数
seq() 函数常见用法:
seq(from, to)
seq(from, to, by= )
seq(from, to, length.out= )
seq(along.with= )
seq(from)
seq(length.out= )
参数说明:
| 参数 | 说明 |
|---|---|
| from, to | 序列的起始值和(最大)结束值。长度为1,除非只是from作为未命名参数提供。 |
| by | 序列的增量。也就是步长。 |
| length.out | 序列长度。 |
通过下面的实例我们来学习一下:
#生成1-10
x1 <- seq(1,10)
#创建一个包含值0 3 6 9 12 15 18 21 24 27 30 33 36 39 42 45 48的向量
x2 <- seq(0,48,by=3)
#在1-100之间产生等间距的13个数
x3 <-seq(1,100,length.out = 13)
#生成包含1~5的向量,
x4 <- seq(5)
x5 <- seq(length.out=5)
print(x1)
print(x2)
print(x3)
print(x4)
print(x5)
输出结果:

rep()函数
重复向量常数,replicates,或者repeat
x2<-rep(1:4,c(1,2,3,4)) 省略了参数 times, times=c(1,2,3,4)更多示例请查看rep帮助信息rep()可以更方便的把同一常数放在长向量中情况1的times是一个标量,情况2的times是一个向量情况2:用来分别控制每个向量重复出现的次数,1:4有4个向量,则times需要提供一个向量并且长度为4https://zhuanlan.zhihu.com/p/246524031
x<-c("a","b","c")
y<-rep(x[c(3,2,1)],times=3)
[1] "c" "b" "a" "c" "b" "a" "c" "b" "a“
✨情况1:向量中所有元素重复相同次数
> x1<-rep(1:4,times=2)
> x1
[1] 1 2 3 4 1 2 3 4
✨情况2:与向量x等长times模式
> x2<-rep(1:4,times=c(1,2,3,4))
> x2
[1] 1 2 2 3 3 3 4 4 4 4
这里的times是一个向量,用来分别控制每个向量重复出现的次数
✨情况3:与向量x非等长times模式,出现错误
> x3<-rep(1:4,times=c(1,2,3))
Error in rep(1:4, c(1, 2, 3)) : 'times'参数不对
✨情况4: each 参数控制每个元素重复次数
> x4<-rep(1:4,each=2)
> x4
[1] 1 1 2 2 3 3 4 4
✨情况5: times是单值,整个向量重复times次
> x5<-rep(1:4,each=2,times=2)
> x5
[1] 1 1 2 2 3 3 4 4 1 1 2 2 3 3 4 4
既有times又有each,先执行each。
✨情况6:
> x6<-rep(1:4,each=2,times=1:8)
> x6
[1] 1 1 1 2 2 2 2 2 2 2 3 3 3 3 3 3 3 3 3 3 3 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4
先应用each生成基本向量,即先应用each完成向量中每个元素的相同重复,在应用times重复1+2+3+…+8=36个向量
✨情况7:控制生成向量长度
> rep(1:4, each = 2, len = 4) # first 4 only.
[1] 1 1 2 2
✨情况8:长度超过重复后的向量
> rep(1:4, each = 2, len = 10)
[1] 1 1 2 2 3 3 4 4 1 1
总结:
- each指的是向量x中元素交替重复的次数
- times指的是向量x整体重复的次数
- 先each后times
R语言基本数据集中的向量
向量:
- euro #欧元汇率,长度为11,每个元素都有命名
- landmasses #48个陆地的面积,每个都有命名
- precip #长度为70的命名向量
- rivers #北美141条河流长度
- state.abb #美国50个州的双字母缩写
- state.area #美国50个州的面积
- state.name #美国50个州的全称
示例如下:
> euro #欧元汇率,长度为11,每个元素都有命名
ATS BEF DEM ESP FIM FRF IEP ITL LUF
13.760300 40.339900 1.955830 166.386000 5.945730 6.559570 0.787564 1936.270000 40.339900
NLG PTE
2.203710 200.482000
> state.abb #美国50个州的双字母缩写
[1] "AL" "AK" "AZ" "AR" "CA" "CO" "CT" "DE" "FL" "GA" "HI" "ID" "IL" "IN" "IA" "KS" "KY" "LA" "ME"
[20] "MD" "MA" "MI" "MN" "MS" "MO" "MT" "NE" "NV" "NH" "NJ" "NM" "NY" "NC" "ND" "OH" "OK" "OR" "PA"
[39] "RI" "SC" "SD" "TN" "TX" "UT" "VT" "VA" "WA" "WV" "WI" "WY"
向量命名
可以用names()函数为向量中的元素命名
> score <- c(90,82,78,64)
> stu <- c("Linda","Lili","James","Mark")
> names(score) <- stu
> score
Linda Lili James Mark
90 82 78 64
查询向量元素的名称
> x<-c(1,3,5)
> names(x)
NULL
> names(x)<-c("a1","a2","a3")
> x
a1 a2 a3
1 3 5
> x["a2"]
a2
3
向量的索引
a <- c(1, 3, 5, 7, 9);a[2]
[1] 3
> x<-10:20;x[c(1,3,5)]
[1] 10 12 14
> x[1:5]
[1] 10 11 12 13 14
> x[c(1,2,1)]
[1] 10 11 10
- 如果x为向量,x[i]表示向量x的第i个分量
- 如果x是长度为n的向量,v为取值在1-n之间的数(允许重复)的向量,则x[v]是向量x中由v所表示的分量构成的向量。
- 可以多次访问向量中的同一个元素
不同于C语言和Python语言,R中向量索引从1开始
> x<-10:20;x[-(1:5)]
[1] 15 16 17 18 19 20
> x<-c(1,4,7);x[x<5]
[1] 1 4
> ages<-c(zhao=20,qian=23,sun=24)
> ages
zhao qian sun
20 23 24
- 如果x是长度为n的向量,v为取值在[-n,-1]之间的向量,则x[v]是向量x中去掉v所表示的分量构成的向量。
- 如果x是向量,v为与它等长的逻辑向量,则x[v]表示取出所有v为真值的元素。使用逻辑向量访问向量的值是R语言的特色,第二个实例 x<5 返回一个逻辑向量 TRUE TRUE FALSE,根据逻辑向量选出1和4.
- 在定义向量时,可以同时给元素加上名字,这个名字就称为字符下标。
#如果x中的向量是逻辑向量,只输出逻辑值为真的元素。
> x<-1:6;x[c(T,F,T,F,T,T)]
[1] 1 3 5 6
> x<-1:6;x[c(T)]
[1] 1 2 3 4 5 6
> x<-1:6;x[c(F)]
> integer(0)
> x<-1:6;x[c(T,F)]
[1] 1 3 5
> x<-1:6;x[c(F,T)]
[1] 2,4,6
> x<-1:10;x[c(T,F,T)]
[1] 1 3 4 6 7 9 10
#向量索引中,索引值的个数多于向量元素个数,会产生缺失值
> x<-1:6;x[c(T,T,T,F,F,F,T)]
[1] 1 2 3 NA
📙自动循环补长
R语言中的向量可以自动循环补长:
- x[c(T)]实际上是补长为六个T;
- x[c(F)]补长为六个F;
- x[c(T,F)]则补齐为T F T F T F;
- x[c(F,T)]补长为 F T F T F T
添加向量元素
R中向量是连续存储的,向量的大小在创建时就已经确定,因此,想要添加或者删除元素,需要重新给向量赋值。
c()函数
已知:向量x<-c(1,5,8,0),将一个元素39添加到向量x的中间
x<-c(x[1:2],39,x[3:4])
> x
[1] 1 5 39 8 0
这个过程似乎改变了x中存储的向量,实际上创建了新的向量并把它存储于x中。获取向量的长度length(x)也可以按照如下方式创建向量
> x<-vector(length=2)
> x[1]<-3
> x[2]<-4
> x
[1] 3 4
append()函数
利用append函数在向量的中间位置添加元素值
语法如下:
append(x, values, after = length(x))
参数说明:
| 参数 | 说明 |
|---|---|
| x | 要添加值的向量。 |
| values | 要添加的内容 |
| after | 下标,值要在其后面添加。 |
下面我们来看一个实例:
> x<-1:6
> append(x,99,3)
[1] 1 2 3 99 4 5 6
删除向量元素
rm()函数
rm()函数用于删除整个向量
> rm(x)
> x
Error: object 'x' not found
负号
有时我们只需要删除部分元素,可以使用下面这种方法:
> x<-1:6
> x
[1] 1 2 3 4 5 6
> x<-x[-c(1:3)]#去除前三个元素
> x
[1] 4 5 6
向量判断
any()函数
any()报告其参数是否至少一个为TRUE
> x<-1:10
> any(x>8)
[1] TRUE
x中存在大于8的,返回TRUE
> x<-1:10
> any(x>88)
[1] FALSE
x中不存在大于88的,返回FALSE
向量化的含义,意味着应用到向量上的函数实际上应用到每一个元素上
all()函数
all()报告其参数是否全部为TRUE.
> x<-1:10
> all(x>0)
[1] TRUE
x中的元素全部都大于0,返回TRUE
> x<-1:10
> all(x>1)
[1] FALSE
x中的元素并不全部都大于0,返回FALSE
测量向量是否相等
✨方法1:使用**==**号进行判断,逐元素进行判断
> x<-1:3
> y<-c(1,3,4)
> x==y
[1] TRUE FALSE FALSE
✨方法2:使用 identical() 函数进行判断
> x<-1:3
y<-c(1,2,3)
> identical(x,y)
[1] FALSE
> z<-c(1L,2L,3L)
> identical(x,z)
[1] TRUE
结论:
- 使用:创建的向量为整型向量
- 使用C创建的向量为double型向量
- identical()判断两个对象是否完全一致
向量计算
向量加法
✨情况1:向量与数相加
> x<-c(1:6)
> x
[1] 1 2 3 4 5 6
> x+1
[1] 2 3 4 5 6 7
向量与数相加等于向量中的每个元素与这个数相加
✨情况2:向量与向量相加(长度相等)
> x<-c(1:10)
> y<-seq(1,100,length.out = 10)
> x
[1] 1 2 3 4 5 6 7 8 9 10
> y
[1] 1 12 23 34 45 56 67 78 89 100
> x+y
[1] 2 14 26 38 50 62 74 86 98 110
向量与向量相加(长度相等)等于向量中对应的元素相加
循环补齐
在对两个向量使用运算符时,如果要求两个向量具有相同的长度,R会自动循环补齐。即重复较短的向量,直到它与另一个向量长度相匹配。
✨例题1
> c(1:3)+c(1:4)
[1] 2 4 6 5
Warning message:
In c(1:3) + c(1:4) :
longer object length is not a multiple of shorter object length
长的对象长度不是短的对象长度的整倍数
因为两个向量的长度不同,所以将第一个向量补齐为 1 2 3 1
✨例题2
> x<-matrix(1:6,nrow=3)
> x
[,1] [,2]
[1,] 1 4
[2,] 2 5
[3,] 3 6
> x + c(1:2)
[,1] [,2]
[1,] 2 6
[2,] 4 6
[3,] 4 8
>
矩阵实际上是一个长向量,3*2的矩阵本质上是一个6个元素的向量,在R中逐列存储。换句话说,矩阵x 与向量c(1,2,3,4,5,6)相同。
which函数
which函数返回符合要求元素的下标。
✨例题1
#返回单个下标
> x<-c(1,5,7,9,0,8)
> which.max(x)
[1] 4
> which.min(x)
[1] 5
> which(x==5)
[1] 2
✨例题2
#返回多个下标
> which(x>5)
[1] 3 4 6
#利用下标返回符合要求的元素
> x[which(x>5)]
[1] 7 9 8
ple of shorter object length
长的对象长度不是短的对象长度的整倍数
因为两个向量的长度不同,所以将第一个向量补齐为 1 2 3 1
✨例题2
```R
> x<-matrix(1:6,nrow=3)
> x
[,1] [,2]
[1,] 1 4
[2,] 2 5
[3,] 3 6
> x + c(1:2)
[,1] [,2]
[1,] 2 6
[2,] 4 6
[3,] 4 8
>
矩阵实际上是一个长向量,3*2的矩阵本质上是一个6个元素的向量,在R中逐列存储。换句话说,矩阵x 与向量c(1,2,3,4,5,6)相同。
which函数
which函数返回符合要求元素的下标。
✨例题1
#返回单个下标
> x<-c(1,5,7,9,0,8)
> which.max(x)
[1] 4
> which.min(x)
[1] 5
> which(x==5)
[1] 2
✨例题2
#返回多个下标
> which(x>5)
[1] 3 4 6
#利用下标返回符合要求的元素
> x[which(x>5)]
[1] 7 9 8