7 Set集合
7.1 Set集合的概述和特点
- Set集合的特点
- 不包含重复元素的集合
- 没有带索引的方法,所以不能使用普通for循环
- Set集合是接口通过实现类实例化(多态的形式)
HashSet:添加的元素是无序,不重复,无索引的LinkedHashSet: 添加的元素是有序,不重复,无索引的TreeSet: 不重复,无索引,按照大小默认升序排列
package ceshi;
import java.util.HashSet;
import java.util.Iterator;
import java.util.Set;
public class SetDemo {
public static void main(String[] args) {
//创建Set集合对象
Set<String> set = new HashSet<>();
//添加元素
set.add("java");
set.add("python");
set.add("scala");
//不包含重复元素
set.add("java");
//两种遍历方式
for(String s:set) {
System.out.println(s);
/*python
java
scala*/
}
System.out.println("--------");
Iterator<String> it = set.iterator();
while(it.hasNext()) {
String s = it.next();
System.out.println(s);
/*python
java
scala*/
}
}
}
7.2 哈希值
- 哈希值:是JDK根据对象的地址或者字符串或者数字算出来的int类型的数值
- Object类中有一个方法可以获取对象的哈希值
public int hashCode():返回对象的哈希码值 - 对象的哈希值特点
- 同一个对象多次调用hashCode()方法返回的哈希值是相同的
- 默认情况下,不同对象的哈希值是不同的。而重写hashCode0方法,可以实现让不同对象的哈希值相同
package ceshi;
public class HashDemo {
public static void main(String[] args) {
//创建学生对象
Student s1 = new Student("y1",10);
//同一个对象多次调用hashCode()方法哈希值相同
System.out.println(s1.hashCode()); //460141958
System.out.println(s1.hashCode()); //460141958
System.out.println("---------");
//默认情况下,不同对象哈希值不同;重写hashCode()方法就可以使哈希值相同
Student s2 = new Student("y2",20);
System.out.println(s2.hashCode()); //1163157884
System.out.println("---------");
System.out.println("java".hashCode()); //3254818
System.out.println("python".hashCode()); //-973197092
System.out.println("scala".hashCode()); //109250886
System.out.println("---------");
System.out.println("无".hashCode()); //26080
System.out.println("敌".hashCode()); //25932
}
}
7.3 数据结构之哈希表
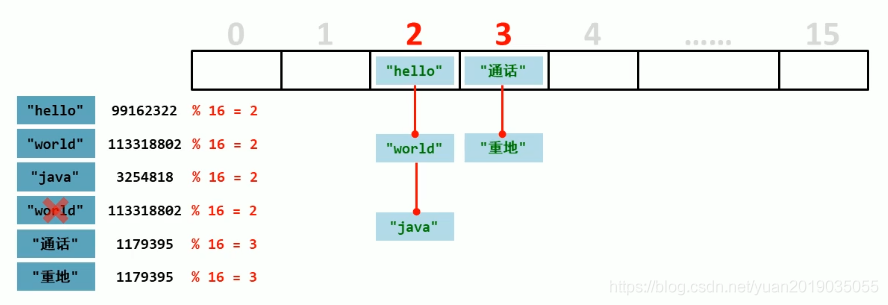
- JDK8之前,底层采用数组+链表实现,可以说是一个元索为链表的数组(哈希表 = 数组 + 链表 + (哈希算法))
- JDK8以后,在长度比较长的时候,底层实现了优化(哈希表 = 数组 + 链表 + 红黑树 + (哈希算法))
- 当链表长度超过 8 时,将链表转换为红黑树,这样大大减少了查找时间
7.4 HashSet集合概述和特点
- HashSet集合特点
- 底层数据结构是哈希表
- 对集合的迭代顺序不作任何保证 ,也就是说不保证存储和取出的元素顺序一致
- 没有带索引的方法,所以不能使用普通for循环遍历
- 由于是Set集合, 所以是不包含重复元素的集合
package ceshi;
import java.util.HashSet;
public class HashSetDemo {
public static void main(String[] args) {
HashSet<String> hs = new HashSet<>();
hs.add("java");
hs.add("python");
hs.add("scala");
hs.add("scala");
for(String s:hs) {
System.out.println(s);
/*python
java
scala*/
}
}
}
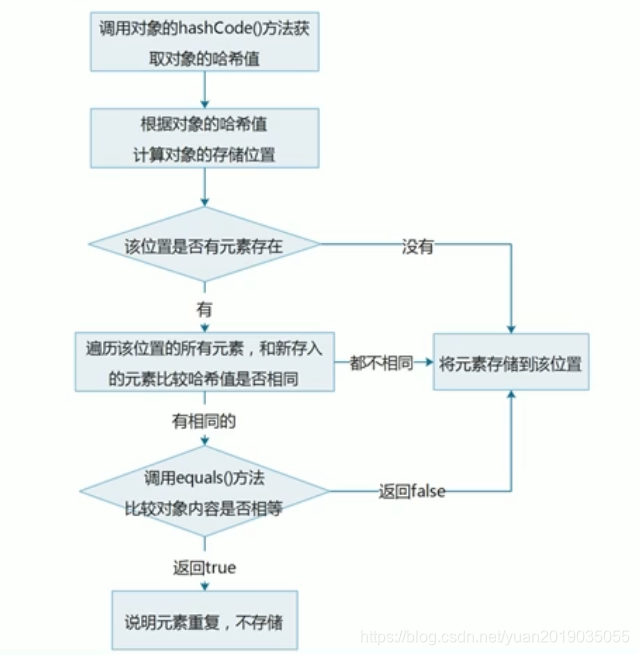
7.5 HashSet集合保证元素唯一性源码分析(重点面试常考)
HashSet<String> hs = new HashSet<>();
hs.add("java");
hs.add("python");
hs.add("scala");
hs.add("scala");
for(String s:hs) {
System.out.println(s);
/*python
java
scala*/
}
-----------------------------------
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true); //上个方法的返回的值是hash(key)的值
}
//hash值和元素的hashCode()方法
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
//如果哈希表未初始化就对其初始化
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
//根据对象的哈希值计算对象的存储位置,
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null); //如果该位置没有元素,就存储新元素
//有元素就走else
else {
Node<K,V> e; K k;
//存入的元素和以前的元素比哈希值
if (p.hash == hash &&
//二、如果哈希值相同,调用对象的equals()比较内容是否相同
//1、如果内容不同equals()返回false,就走一把元素添加到集合
//2、如果内容相同返回true,说明元素重复,走e = p;不存储
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
//一、如果哈希值不同,就走else存储元素到集合
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null); //新元素添加到集合
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
-
HashSet集合存储元素:要保证元素唯一性需要重写
hashCode()和equals()方法 -
案例

-
Student类
package ceshi;
public class Student {
private String name;
private int age;
public Student() {
}
public Student(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
//重写快捷键:Fn+Alt+insert,选择equals() and hashCode()
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Student student = (Student) o;
if (age != student.age) return false;
return name != null ? name.equals(student.name) : student.name == null;
}
@Override
public int hashCode() {
int result = name != null ? name.hashCode() : 0;
result = 31 * result + age;
return result;
}
}
- 测试类
package ceshi;
import java.util.HashSet;
public class HashSetDemo {
public static void main(String[] args) {
HashSet<Student> hs = new HashSet<>();
Student s1 = new Student("y1",10);
Student s2 = new Student("y2",20);
Student s3 = new Student("y3",30);
Student s4 = new Student("y3",30);
hs.add(s1);
hs.add(s2);
hs.add(s3);
hs.add(s4);
for(Student s: hs) {
System.out.println(s.getName()+","+s.getAge());
/*y3,30
y2,20
y1,10
y3,30;s4内容和s3重复并存入了,需要重写hashCode()和equals()
*/
//重写后
/*
y1,10
y3,30
y2,20*/
}
}
}
7.6 LinkedHashSet集合概述和特点
- LinkedHashSet集合特点
- 哈希表和链表实现的Set接口, 具有可预测的迭代次序
- 由链表保证元素有序, 也就是说元索的存储和取出顺序是一致的
- 由哈希表保证元索唯一, 也就是说没有重复的元素
package ceshi;
import java.util.LinkedHashSet;
public class LinkedHashSetDemo {
public static void main(String[] args) {
LinkedHashSet<String> linkedHashSet = new LinkedHashSet<>();
linkedHashSet.add("java");
linkedHashSet.add("python");
linkedHashSet.add("scala");
linkedHashSet.add("scala");
for(String s:linkedHashSet) {
System.out.println(s);
/*java
python
scala*/
}
}
}
7.7 TreeSet集合概述和特点
-
TreeSet集合特点
- 元素有序, 这里的顺序不是指存储和取出的顺序,而是按照一定的规则进行排序,具体排序方式取决于构造方法
TreeSet():根据其元素的自然排序进行排序
TreeSet(Comparator comparator):根据指定的比较器进行排序 - 没有带索引的方法,所以不能使用普通for循环遍历
- 由于是Set集合,所以不包含重复元素的集合
- 元素有序, 这里的顺序不是指存储和取出的顺序,而是按照一定的规则进行排序,具体排序方式取决于构造方法
package ceshi;
import java.util.TreeSet;
public class TreeSetDemo {
public static void main(String[] args) {
TreeSet<Integer> ts = new TreeSet<>();
//jdk5以后添加元素自动装箱int》integer
ts.add(10);
ts.add(40);
ts.add(30);
ts.add(50);
ts.add(20);
ts.add(30);
for(Integer i:ts) {
System.out.println(i);
/*
10
20
30
40
50*/
}
}
}
7.8 自然排序Comarable的使用
-
存储学生对象并遍历,创建TreeSet集合使用无参构造方法
-
要求:按照年龄从小到大排序,年龄相同时,按照姓名的字母顺序排序
-
结论:
- 用TreeSet集合存储自定义对象,无参构造方法使用的是自然排序对元素进行排序的
- 自然排序,就是让元素所属的类实现Comparable接口,重写compareTo(T o)方法
- 重写方法时,一定要注意排序规则必须按照要求的主要条件和次要条件来写
-
Student类
package ceshi;
public class Student implements Comparable<Student>{ //实现接口
private String name;
private int age;
public Student() {
}
public Student(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public int compareTo(Student s) {
// return 0; //返回0说明元素是重复的,只能存一个元素
// return 1; //整数是升序排序
// return -1; //负数是倒叙排序
//按照年龄排序
int num = this.age-s.age; //this是s2,s是s1
//年龄相同时,按照名字字母排序
int num2 = num==0 ? this.name.compareTo(s.name):num;
return num2;
}
}
- 测试
package ceshi;
import java.util.TreeSet;
public class TreeSetDemo {
public static void main(String[] args) {
TreeSet<Student> ts = new TreeSet<>();
Student s1 = new Student("y1",10);
Student s2 = new Student("y3",30);
Student s3 = new Student("y2",20);
Student s4 = new Student("y4",40);
Student s5 = new Student("a4",40); //判断按字母排序
Student s6 = new Student("y4",40); //判断会存储重复值吗
ts.add(s1);
ts.add(s2);
ts.add(s3);
ts.add(s4);
ts.add(s5);
ts.add(s6);
for(Student s:ts) {
System.out.println(s.getName()+","+s.getAge());
/*y1,10
y2,20
y3,30
a4,40
y4,40*/
}
}
}
7.9 比较器排序Comparator[kəmˈpɜrətər]的使用
- 存储学生对象并遍历,创建TreeSet集合使用带参构造方法
- 要求:按照年龄从小到大排序,年龄相同时,按照姓名的字母顺序排序
- 结论
- 用TreeSet集合存储自定义对象,带参构造方法使用的是比较器排序对元索进行排序的
- 比较器排序,就是让集合构造方法接收Comparator的实现类对象,重写compare(To1,T o2)方法
- 重写方法时,一定要注意排序规则必须按照要求的主要条件和次要条件来写
package ceshi;
public class Student {
private String name;
private int age;
public Student() {
}
public Student(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}
- 测试
package ceshi;
import java.util.Comparator;
import java.util.TreeSet;
public class TreeSetDemo {
public static void main(String[] args) {
TreeSet<Student> ts = new TreeSet<>(new Comparator<Student>() {
@Override
public int compare(Student s1, Student s2) {
int num = s1.getAge() - s2.getAge();
int num2 = num==0? s1.getName().compareTo(s2.getName()):num;
return num2;
}
});
Student s1 = new Student("y2",20);
Student s2 = new Student("y1",10);
Student s3 = new Student("y3",30);
Student s4 = new Student("y4",40);
ts.add(s1);
ts.add(s2);
ts.add(s3);
ts.add(s4);
for(Student s:ts) {
System.out.println(s.getName()+","+s.getAge());
}
}
}
7.10 案例:不重复随机数

package ceshi;
import java.util.HashSet;
import java.util.Random;
import java.util.Set;
import java.util.TreeSet;
public class SetDemo {
public static void main(String[] args) {
// Set<Integer> set = new HashSet<>();
Set<Integer> set = new TreeSet<>();
Random r = new Random();
//判断集合是否《10
while(set.size()<10) {
int number = r.nextInt(20)+1;
set.add(number); //把随机数添加到集合
}
for (Integer i:set) {
System.out.print(i+" "); //1(哈希set集合):16 17 2 20 8 9 10 11 14 15
//2(TreeSet集合):1 3 4 5 6 7 8 10 16 19
}
}
}