Exemplars 简介
Exemplar 是用一个特定的 trace,代表在给定时间间隔内的度量。Metrics 擅长给你一个系统的综合视图,而 traces 给你一个单一请求的细粒度视图;Exemplar 是连接这两者的一种方式。
假设你的公司网站正经历着流量的激增。虽然超过百分之八十的用户能够在两秒内访问网站,但有些用户的响应时间超过了正常水平,导致用户体验不佳。
为了确定造成延迟的因素,你必须将快速响应的 trace 与缓慢响应的 trace 进行比较。鉴于典型生产环境中的大量数据,这将是非常费力和耗时的工作。
使用 Exemplar 来帮助隔离你的数据分布中的问题,方法是在一个时间间隔内找出表现出高延迟的查询痕迹。一旦你把延迟问题定位到几个示范跟踪,你就可以把它与其他基于系统的信息或位置属性结合起来,更快地进行根本原因分析,从而快速解决性能问题。
对 Exemplar 的支持仅适用于 Prometheus数据源。一旦你启用该功能,Exemplar 数据默认是可用的。
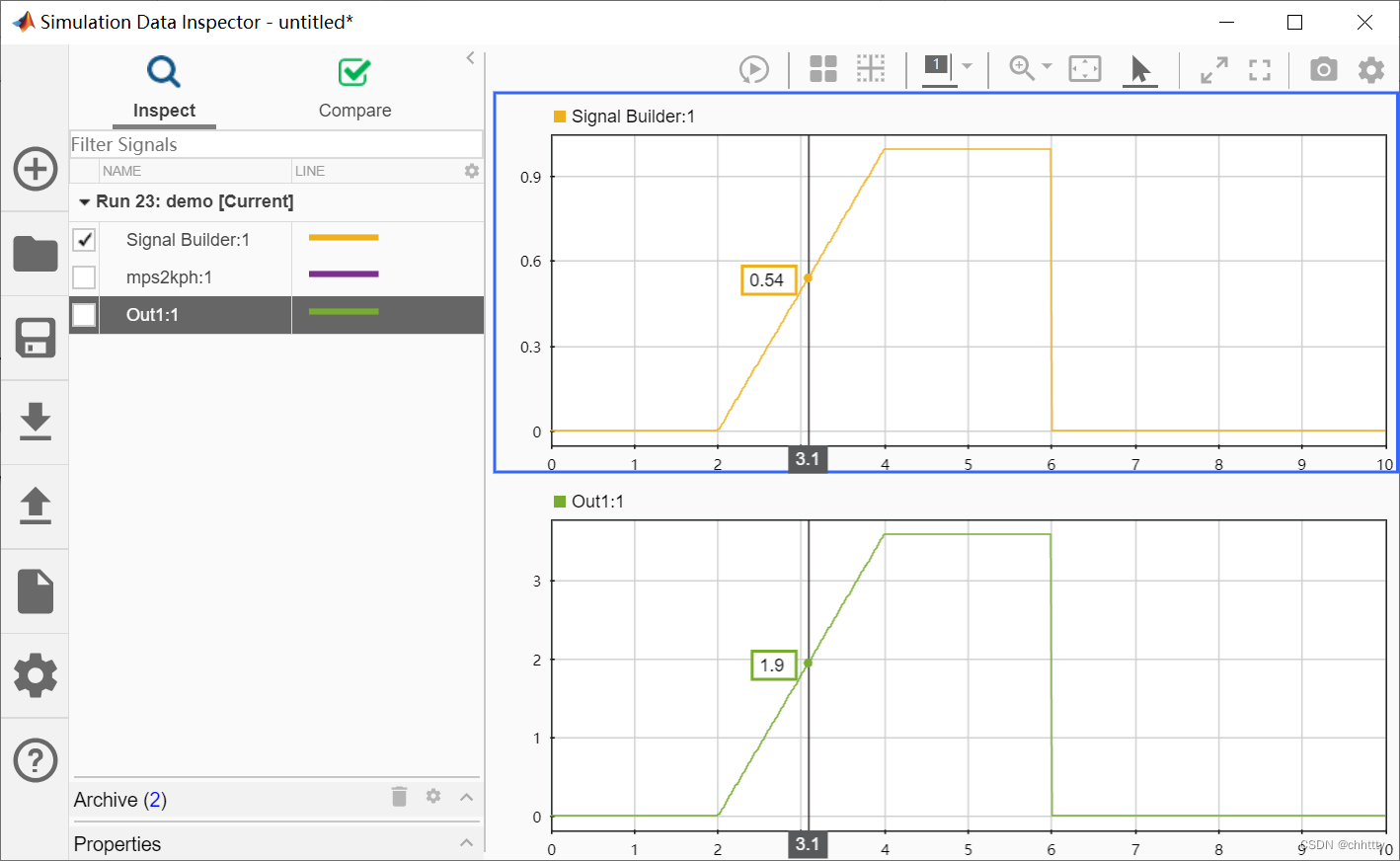
Grafana 在 "Explore" 视图和仪表盘中与指标一起显示 Exemplar 。每个 Exemplar 显示为高亮的星星。你可以将光标悬停在 Exemplar 上,查看唯一的 traceID,它是一个键值对的组合。要进一步分析,请点击 "traceID "属性旁边的蓝色按钮。示例如下:
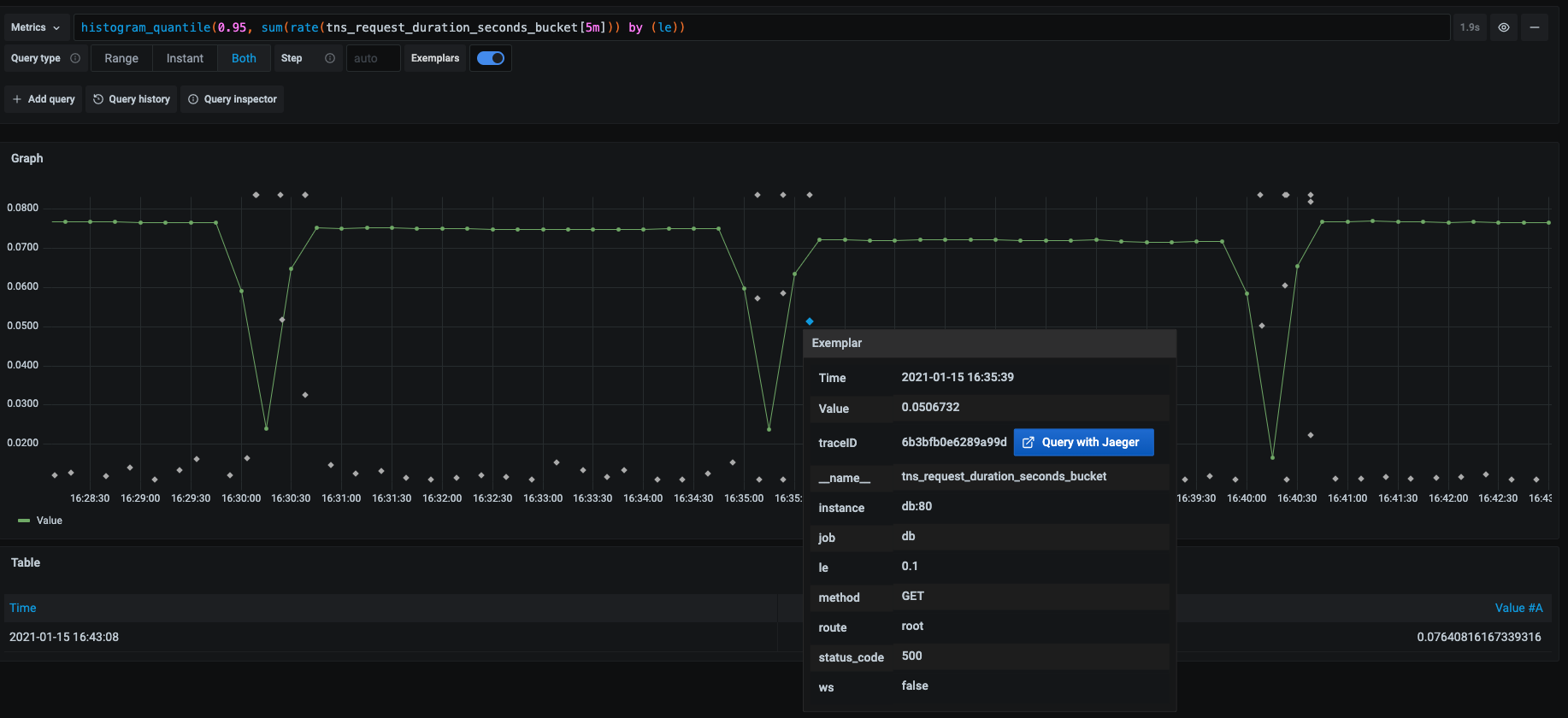
背景
Exemplars 是最近可观察性领域的一个热门话题,这是有原因的。
与 Prometheus 如何在 2012 年开始破而后立了大规模存储指标的成本结构,并在 2015 年真正实现,以及 Grafana Loki 如何在 2018 年破而后立了大规模存储日志的成本结构类似,Exemplar 也在对 trace 做同样的事情。为了了解原因,让我们看看云原生生态系统中可观察性的历史,以及 Exemplar 能够实现哪些优化。
核心是,Exemplar 是一种通过 ID 从有意义的指标和日志跳到追踪的方式。Grafana Tempo,Grafana Labs 的 开源、大规模分布式跟踪后端,就是围绕这个想法建立的,因为 Exemplar 使分布式跟踪的成本和性能特征变得好了。理想情况下,你永远不需要对你的追踪进行采样,而 Tempo 让这成为现实。
Prometheus
暂时忽略 Prometheus 出色的可扩展性、压缩性和性能,让我们把注意力放在标签集上。它们是关于你的时间序列的元数据。是什么集群、什么服务、哪个客户、什么部署级别等等都可以用非层次的键值对来编码。如果你正在读这篇文章,我很可能不需要说服你这个行业的变化有多大的颠覆性、影响力和持久性;我只是想提醒你,因为它与文本的其余部分有关。
这在几年前是革命性的:
acme_http_router_request_seconds_sum{path="/api/v1",method="GET"} 9036.32
acme_http_router_request_seconds_count{path="/api/v1",method="GET"} 807283.0
acme_http_router_request_seconds_sum{path="/api/v2",method="POST"} 479.3
acme_http_router_request_seconds_count{path="/api/v2",method="POST"} 34.0OpenMetrics
早在 2015-2016 年,相关开发者就计划同样的标签集也应用于日志和追踪。这就是为什么 OpenMetrics 自 2017 年以来一直处在一个叫做 OpenObservability 的 GitHub 组织中,而不是 "仅仅 "一个叫做 OpenMetrics 的组织。
Grafana Loki
有了 Loki,这个梦想在 2018 年实现了。在你的指标和日志之间无缝移动,没有问题。这就是 "Like Prometheus but for logs"的标语的由来。
这让我们不得不将标签集应用于 trace,对吗?
OpenMetrics & OpenCensus
2017 年,OpenMetrics 和 OpenCensus 开会,试图看看这两个项目是否可以合并。虽然由于设计目标、运营模式和数据模型的不兼容而没有成功,但这次会议还是改变了 OpenMetrics 和 Prometheus 的命运,也是引出了 Grafana Tempo 的核心设计。
Exemplars 设计思路
本质上,Exemplar 就是以下三个想法:
- 将 trace 与其他可观察性数据紧密结合。
- 只通过 ID 跳入 trace。
- 只有当你知道对哪个 trace 感兴趣,以及为什么感兴趣的时候,才跳入该 trace。避免 "频繁跳入跳出"。
紧密结合
通过 exemplars 将 trace ID 附加到指标上是非常简单的。在你的度量值(可能还有时间戳)后面加一个 "#",表示有一个 exemplars 存在,然后添加你的数据。
借用 OpenMetrics 规范 中的例子:
# TYPE foo histogram
foo_bucket{le="0.01"} 0
foo_bucket{le="0.1"} 8 # {} 0.054
foo_bucket{le="1"} 11 # {trace_id="KOO5S4vxi0o"} 0.67
foo_bucket{le="10"} 17 # {trace_id="oHg5SJYRHA0"} 9.8 1520879607.789
foo_bucket{le="+Inf"} 17
foo_count 17
foo_sum 324789.3
foo_created 1520430000.123如果trace_id标签的名称和值让你想起 W3C 分布式跟踪工作组 提出的规范,那就不是巧合了。我们特意采纳了 W3C 的规范,同时没有强制要求它。这使我们能够在现有的规范工作的基础上,同时在分布式跟踪领域稳定下来之前不把 OpenMetrics 捆绑起来。
让我们看看里面的实际范例:
显示延迟小于 1 秒的直方图桶有一个运行时间为 0.67 秒、ID 为KOO5S4vxi0o的 trace。
显示 10 秒以下延迟的直方图桶有一个运行时间为 9.8 秒的 trace,时间为1520879607.789,ID 为oHg5SJYRHA0。
就是这样!
仅限 ID
索引是昂贵的。把完整的上下文和元数据放在 trace 上意味着你需要通过它们来搜索 trace,这就意味着对它们进行索引。但是你想在你的指标、日志和 trace(以及 conprof、crashdumps 等)上有相同的标签。但是,由于你在其他数据上已经有了这些元数据,重用相同的索引以节省成本和时间如何?
通过在一个特定的时间点上将 trace 附在一个特定的时间序列或日志上,你就可以做到这一点。对于 trace 本身,你只需对 ID 进行索引,就可以了。
仅限感兴趣的 traces
自动跟踪分析是一个广泛的领域;大量精湛的工程力量被用于使这个干草堆可被搜索。
如果有一个更便宜、更有效的方法呢?
日志已经可以告诉你一个错误状态或类似的情况。你不需要分析 trace 来找到那个错误。
指标中的计数器、直方图等已经是一种高度浓缩和优化的数据形式,被提炼成在这种情况下重要的东西。你不需要分析所有的 trace 来找到那个显示高延迟的 trace。
你的日志和你的指标已经告诉你为什么一个 trace 是需要深入调查的。你的标签给了你如何和在哪里产生 trace 的背景。在跳入 trace 的时候,你已经知道你在寻找什么和为什么。这就大大加快了发现的速度。
Prometheus 启用 Exemplar storage Feature
📚️ Reference: Exemplars storage | Prometheus Doc
--enable-feature=exemplar-storageOpenMetrics 介绍了刮削目标为某些度量标准添加 Exemplars 的能力。典型应用场景是对 MetricSet 之外的数据的引用。一个常见的用例是 trace ID。
Exemplar 存储是作为一个固定大小的圆形缓冲区实现的,它将所有系列的 exemplar 存储在内存中。启用此功能将使 Prometheus 刮削来的 exemplar 的存储成为可能。配置文件块 storage/exemplars 可以用来控制循环缓冲区的大小。一个只有traceID=<jaeger-trace-id>的 exemplar 通过内存中的 exemplar 存储大约使用 100 字节的内存。如果 exemplar 存储被启用,我们也会将 exemplar 追加到 WAL 中进行本地持久化(在 WAL 持续时间内)。
在 Prometheus 数据源中配置 Exemplar
📚️ Reference:
有关 Exemplar 配置和如何启用 Exemplar 的更多信息,请参阅 在 Prometheus 数据源中配置 Exemplar
📝 Notes:
该功能在 Prometheus 2.26+ 和 Grafana 7.4+ 上可用。
Grafana 7.4 及以后的版本能够在 Explore 和仪表盘中显示与指标相关的 Exemplar 数据。Exemplar 数据是一种将特定事件中的高权重元数据与传统时间序列数据联系起来的方式。
通过添加外部或内部链接,在数据源设置中配置 Exemplars。
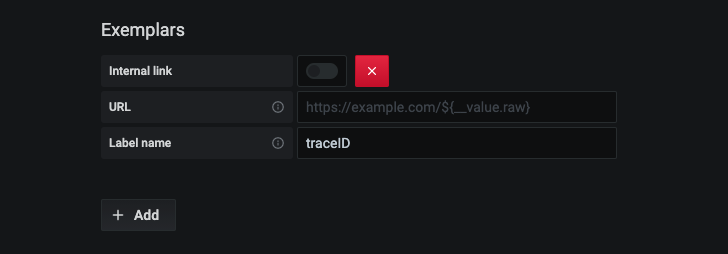
查看 Exemplar 数据
📚️ Reference:
请参考 查看 exemplar 数据, 了解如何从指标和日志中钻取和查看 Exemplar trace 细节。
当 prometheus 数据源启用对 exemplar 支持时,你可以在 Explore 视图或从 Loki 日志细节中查看 exemplar 数据。
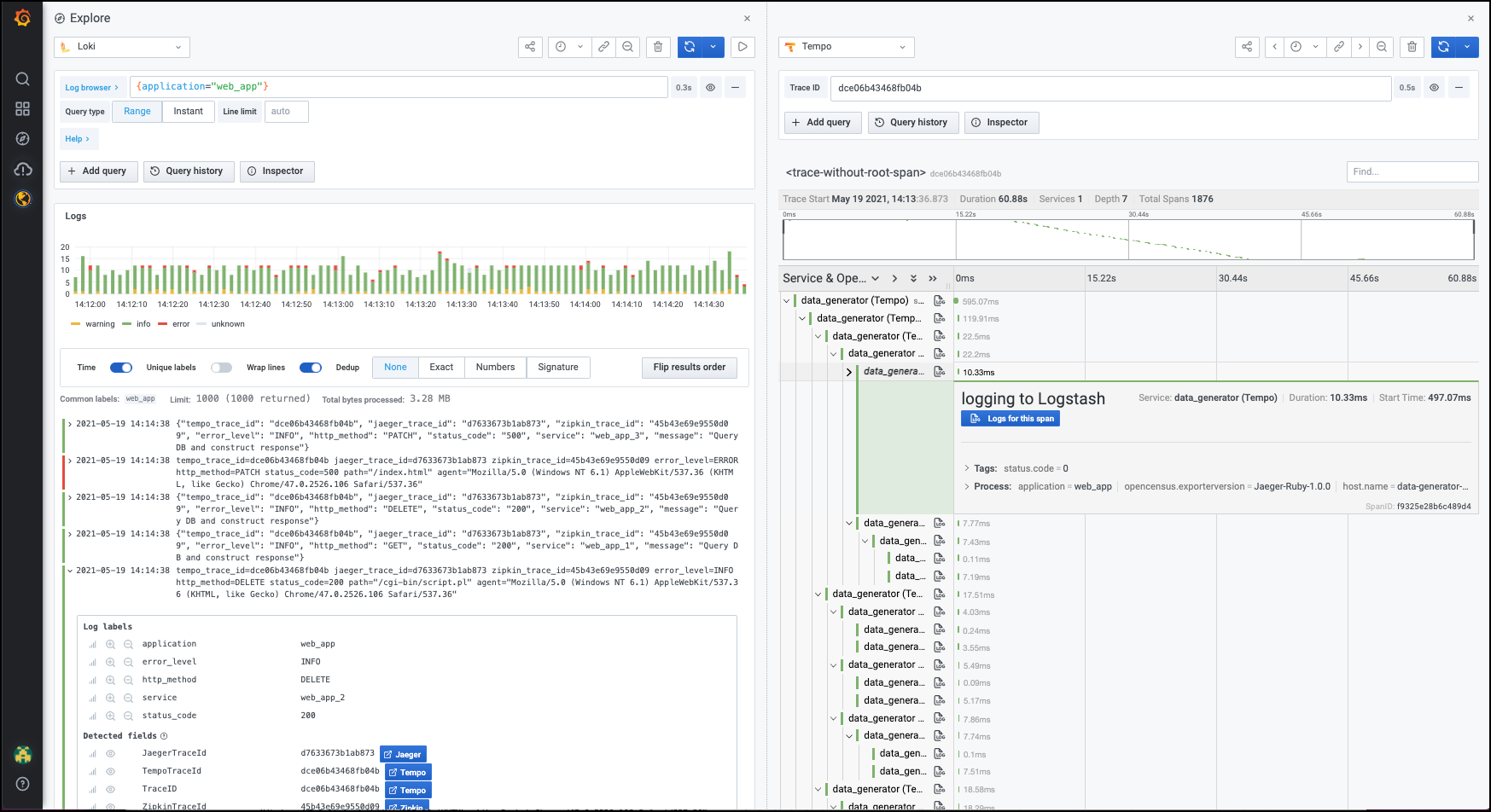
Explore
Explore 将 exemplar 的跟踪数据可视化为高亮的星星和指标数据。关于 Explore 如何将跟踪数据可视化的更多信息,请参考 Explore 中的跟踪。
要检查 exemplar 跟踪的细节。
将你的光标放在一个 exemplar (突出显示的星星)上。根据你的后端 trace 数据源,你会看到一个蓝色的按钮,标签是
Query with <DataSource Name>。在下面的例子中,Trace 的数据源是 Tempo。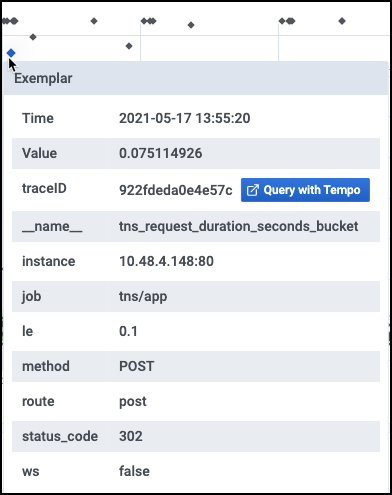
点击 traceID 属性旁边的 Query with Tempo 选项。Trace 的细节,包括 trace 中的 span 都列在右边的独立面板中。
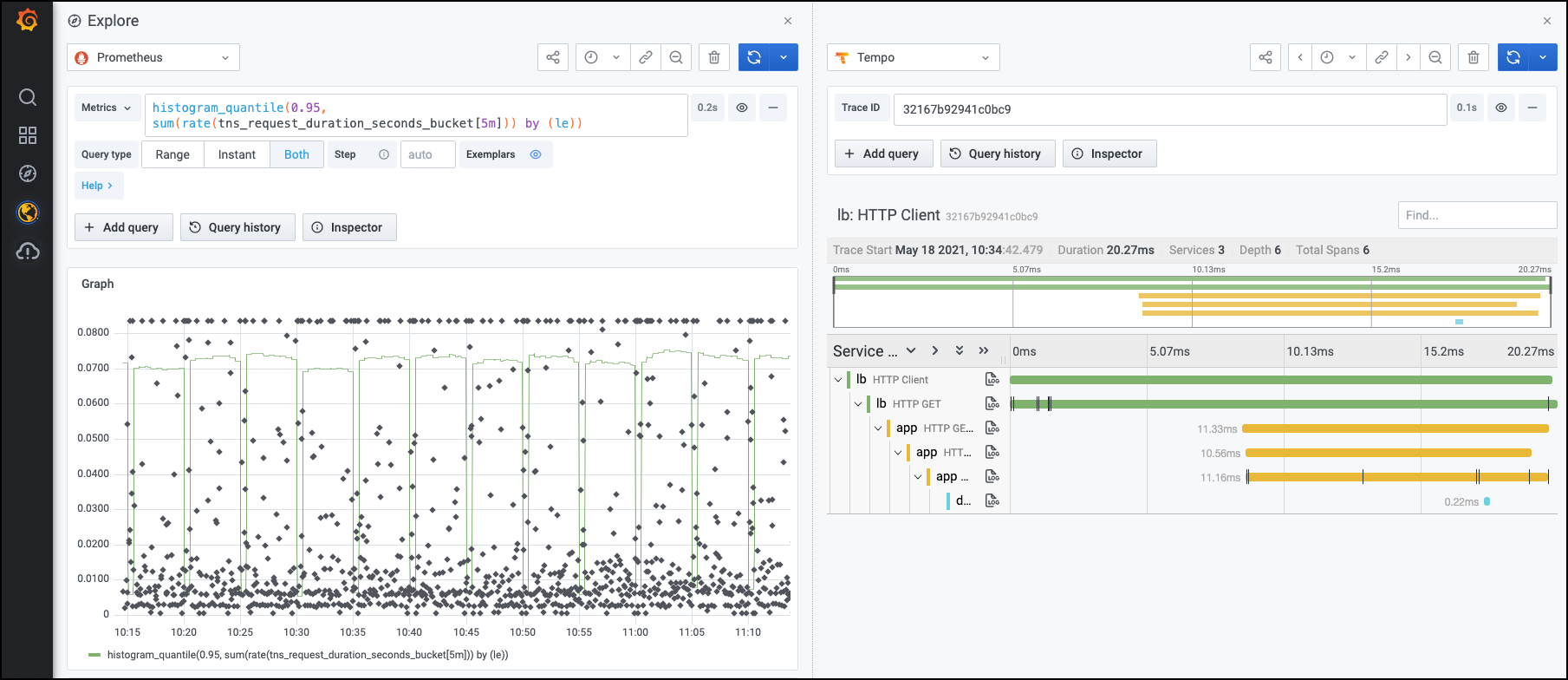
Logs
你也可以在 Explore 中查看 Loki 日志中的 exemplar 跟踪细节。在 Loki 的 Derived fields 链接中使用 regex 来提取 traceID 信息。现在当你展开 Loki 日志时,你可以在检测字段部分看到 traceID 属性。要了解更多关于如何将日志信息的一部分提取到内部或外部链接中,请参考 在 Loki 中使用衍生字段。
要查看 exemplar 跟踪的细节:
展开一个日志行,向下滚动到 "检测到的字段 "部分。根据你的后端跟踪数据源,你会看到一个蓝色的按钮,标签是
<数据源名称>。点击
traceID属性旁边的蓝色按钮。通常情况下,它将有后端数据源的名称。在下面的例子中,追踪的数据源是 Tempo。追踪的细节,包括追踪中的 span 都列在右边的独立面板中。
总结
Exemplars 就是这样的。工程设计始终是为了适应设计目标和约束条件而进行的权衡。
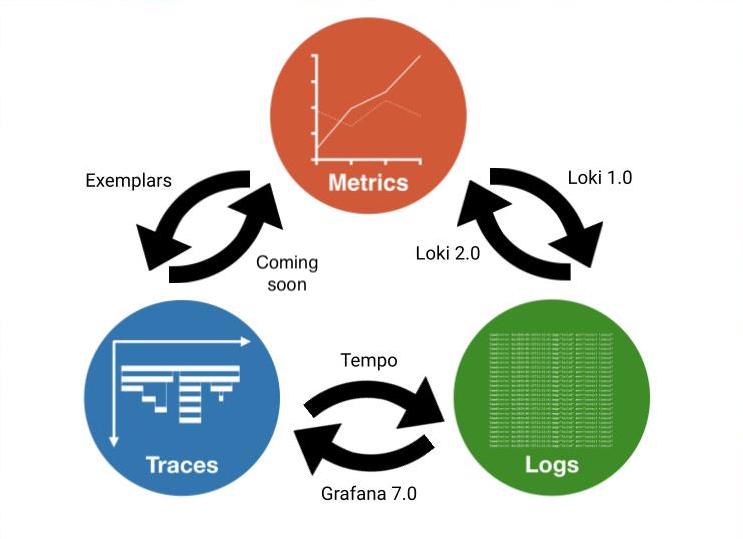
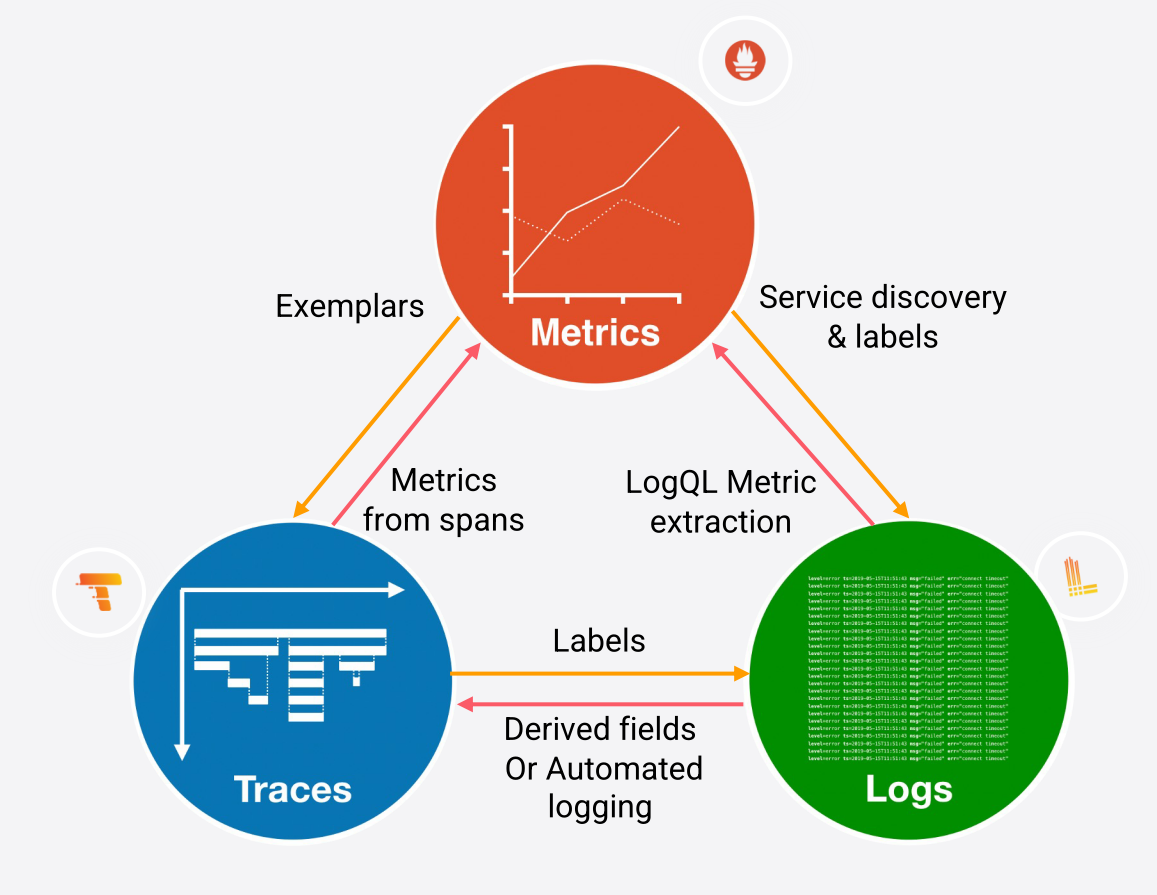
Prometheus 将整个行业转移到一套新的权衡标准,创造了云原生观察能力的基石。Grafana Loki 也在做同样的日志工作。Grafana Tempo 正在通过 exemplars 的力量为分布式追踪做这件事。
Tempo 的工作是存储大量的跟踪,把它们放在对象存储中,并通过 ID 来检索它们。由于所有这些都遵循一个整体设计,在指标、日志和追踪之间的无缝移动已经成为可能,而且是真正的云原生规模。
Exemplars 已经 从 7.4 开始在 Grafana 中得到支持。
参考文档
- Exemplars 介绍,实现 Grafana Tempo 的大规模分布式追踪
三人行, 必有我师; 知识共享, 天下为公. 本文由东风微鸣技术博客 EWhisper.cn 编写.