Contents
- 混合精度训练 (Mixed Precision Training)
- 单精度浮点数 (FP32) 和半精度浮点数 (FP16)
- 为什么要用 FP16
- 为什么只用 FP16 会有问题
- 解决方案
- 损失缩放 (Loss Scaling)
- FP32 权重备份
- 黑名单
- Tensor Core
- NVIDIA apex 库代码解读
- opt-level (o1, o2, o3, o4)
- apex 的 o1 实现
- apex 的 o2 实现
- 在 PyTorch 中使用混合精度训练
- Automatic Mixed Precision (AMP)
- Typical Mixed Precision Training
- Saving/Resuming
- Working with Unscaled Gradients (Gradient Clipping)
- Working with Scaled Gradients
- Gradient accumulation
- Gradient penalty
- Working with Multiple GPUs
- 其他注意事项
- References
PyTorch 1.6 之前,大家都是用 NVIDIA 的 apex 库来实现 AMP 训练。1.6 版本之后,PyTorch 出厂自带 AMP,仅需几行代码,就能让显存占用减半,训练速度加倍
混合精度训练 (Mixed Precision Training)
单精度浮点数 (FP32) 和半精度浮点数 (FP16)
- PyTorch 默认使用单精度浮点数 (FP32) 来进行网络模型的计算和权重存储,表示范围为
[
−
3
e
38
,
−
1
e
−
38
]
∪
[
1
e
−
38
,
3
e
38
]
\left[-3 e^{38},-1 e^{-38}\right] \cup\left[1 e^{-38}, 3 e^{38}\right]
[−3e38,−1e−38]∪[1e−38,3e38]. 而半精度浮点数 (FP16) 表示范围只有
[
−
6.5
e
4
,
−
5.9
e
−
8
]
∪
[
5.9
e
−
8
,
6.5
e
4
]
\left[-6.5 e^{4},-5.9 e^{-8}\right] \cup\left[5.9 e^{-8}, 6.5 e^{4}\right]
[−6.5e4,−5.9e−8]∪[5.9e−8,6.5e4],可以看到 FP32 能够表示的范围要比 FP16 大的多得多
 其中
其中sign位表示正负,exponent位表示指数,fraction 位表示分数 - 此外浮点数还存在舍入误差,当两个数字相差太大时,相加是无效的。例如 2 − 3 + 2 − 14 2^{-3}+2^{-14} 2−3+2−14 在 FP32 中就不会有问题,但在 FP16 中,由于 FP16 表示的固定间隔为 2 − 13 2^{-13} 2−13,因此 2 − 14 2^{-14} 2−14 加了跟没加一样
# FP32
>>> torch.tensor(2**-3) + torch.tensor(2**-14)
tensor(0.1251)
# FP16
>>> torch.tensor(2**-3).half() + torch.tensor(2**-14).half()
tensor(0.1250, dtype=torch.float16)

对于 float16:
- 如果 Exponent 位全部为 0:
- 如果 fraction 位全部为 0,则表示数字 0
- 如果 fraction 位不为 0,则表示一个非常小的数字 (subnormal numbers),其计算方式为 ( − 1 ) s i g n b i t × 2 − 14 × ( 0 + f r a c t i o n 1024 ) (-1)^{signbit}\times2^{-14}\times(0+\frac{fraction}{1024}) (−1)signbit×2−14×(0+1024fraction)
- 如果 Exponent 位全部为 1:
- 如果 fraction 位全部为 0,则表示 ± i n f ±inf ±inf
- 如果 fraction 位不为0,则表示 NAN
- Exponent 位的其他情况: ( − 1 ) s i g n b i t × ( e x p o n e n t × 2 − 15 ) × ( 1 + f r a c t i o n 1024 ) (-1)^{signbit}\times(exponent\times2^{-15})\times(1+\frac{fraction}{1024}) (−1)signbit×(exponent×2−15)×(1+1024fraction)

为什么要用 FP16
- 如果我们在训练过程中将 FP32 替代为 FP16,有以下两个好处:(1) 减少显存占用: FP16 的显存占用只有 FP32 的一半,这使得我们可以用更大的 batch size;(2) 加速训练: 使用 FP16,模型的训练速度几乎可以提升 1 倍
为什么只用 FP16 会有问题
如果我们简单地把模型权重和输入从 FP32 转化成 FP16,虽然速度可以翻倍,但是模型的精度会被严重影响。原因如下:
- 上/下溢出: FP16 的表示范围不大,超过
6.5
e
4
6.5 e^{4}
6.5e4 的数字会上溢出变成 inf,小于
5.9 e − 8 5.9 e^{-8} 5.9e−8 的数字会下溢出变成 0。下溢出更加常见,因为在网络训练的后期,模型的梯度往往很小,甚至会小于 FP16 的下限,此时梯度值就会变成 0,模型参数无法更新。下图为 SSD 网络在训练过程中的梯度统计,有 67% 的值下溢出变成 0

- 舍入误差: 就算梯度不会上/下溢出,如果梯度值和模型的参数值相差太远,也会发生舍入误差的问题。假设模型参数 w = 2 − 3 w=2^{-3} w=2−3,学习率 η = 2 − 2 \eta=2^{-2} η=2−2,梯度 g = 2 − 12 g=2^{-12} g=2−12,则 w ′ = w + η × g = 2 − 3 + 2 − 2 × 2 − 12 = 2 − 3 w'=w+\eta\times g=2^{-3}+2^{-2}\times 2^{-12}=2^{-3} w′=w+η×g=2−3+2−2×2−12=2−3
解决方案
损失缩放 (Loss Scaling)
- 为了解决下溢出的问题,论文中对计算出来的 loss 值进行缩放 (scale),由于链式法则的存在,对 loss 的缩放会作用在每个梯度上。缩放后的梯度,就会平移到 FP16 的有效范围内。这样就可以用 FP16 存储梯度而又不会溢出了。此外,在进行更新之前,需要先将缩放后的梯度转化为 FP32,再将梯度反缩放 (unscale) 回去以便进行参数的梯度下降 (注意这里一定要先转成 FP32,不然 unscale 的时候还是会下溢出)
- 缩放因子 (loss_scale) 一般都是框架自动确定的,只要没有发生 inf 或者 nan,loss_scale 越大越好。因为随着训练的进行,网络的梯度会越来越小,更大的 loss_scale 可以更加充分地利用 FP16 的表示范围
FP32 权重备份
- 为了实现 FP16 的训练,我们需要把模型权重和输入数据都转成 FP16,反向传播的时候就会得到 FP16 的梯度。如果此时直接进行更新,因为梯度 × \times × 学习率的值往往较小,和模型权重的差距会很大,可能会出现舍入误差的问题
- 解决思路是: 将模型权重、激活值、梯度等数据用 FP16 来存储,同时维护一份 FP32 的模型权重副本用于更新。在反向传播得到 FP16 的梯度以后,将其转化成 FP32 并 unscale,最后更新 FP32 的模型权重。因为整个更新过程是在 FP32 的环境中进行的,所以不会出现舍入误差
黑名单
- 对于那些在 FP16 环境中运行不稳定的模块,我们会将其添加到黑名单中,强制它在 FP32 的精度下运行。比如需要计算 batch 均值的 BN 层就应该在 FP32 下运行,否则会发生舍入误差。还有一些函数对于算法精度要求很高,比如 torch.acos(),也应该在 FP32 下运行
- 如何保证黑名单模块在 FP32 环境中运行: 以 BN 层为例,将其权重转为 FP32,并且将输入从 FP16 转成 FP32,这样就可以保证整个模块是在 FP32 下运行的
Tensor Core
- Tensor Core 可以让 FP16 做矩阵相乘,然后把结果累加到 FP32 的矩阵中。这样既可以享受 FP16 高速的矩阵乘法,又可以利用 FP32 来消除舍入误差

NVIDIA apex 库代码解读
opt-level (o1, o2, o3, o4)
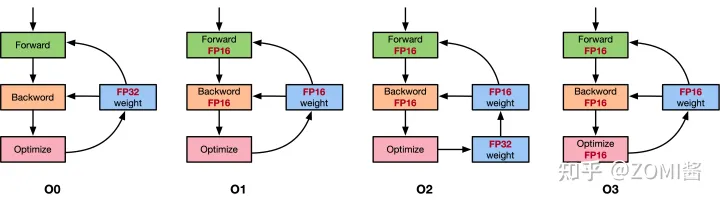
- 首先介绍下 apex 提供的几种 opt-level: o1, o2, o3, o4
- o0 是纯 FP32,用来当精度的基准。o3 是纯 FP16,用来当速度的基准
- 重点讲 o1 和 o2 。我们之前讲的 AMP 策略其实就是 o2: 除了 BN 层的权重和输入使用 FP32,模型的其余权重和输入都会转化为 FP16。此外还会创建一个 FP32 的权重副本来执行更新操作
- 和 o2 不同, o1 不再需要 FP32 权重备份,因为 o1 的模型一直都是 FP32。 可能有些读者会好奇,既然模型参数是 FP32,那怎么在训练过程中使用 FP16 呢?答案是 o1 建立了一个 PyTorch 函数的黑白名单,对于白名单上的函数,强制要求其用 FP16,即会将函数的参数先转化为 FP16,再执行函数本身。黑名单则强制要求 FP32。以
nn.Linear为例, 这个模块有两个权重参数 weight 和 bias,输入为 input,前向传播就是调用了torch.nn.functional.linear(input, weight, bias)。 o1 模式会将 input、weight、bias 先转化为 FP16 格式 input_fp16、weight_fp16、bias_fp16,再调用函数torch.nn.functional.linear(input_fp16, weight_fp16, bias_fp16)。这样一来就实现了模型参数是 FP32,但是仍然可以使用 FP16 来加速训练。o1 还有一个细节: 虽然白名单上的 PyTorch 函数是以 FP16 运行的,但是产生的梯度是 FP32,所以不需要手动将其转成 FP32 再 unscale,直接 unscale 即可。通常来说 o1 比 o2 更稳,一般先选择 o1,再尝试 o2 看是否掉点,如果不掉点就用 o2
apex 的 o1 实现
- (1) 根据黑白名单对 PyTorch 内置的函数进行包装。白名单函数强制 FP16,黑名单函数强制 FP32。其余函数则根据参数类型自动判断,如果参数都是 FP16,则以 FP16 运行,如果有一个参数为 FP32,则以 FP32 运行
- (2) 将 loss_scale 初始化为一个很大的值
- (3) 对于每次迭代
- (a). 前向传播: 模型权重是 FP32,按照黑白名单自动选择算子精度
- (b). 将 loss 乘以 loss_scale
- ( c c c). 反向传播: 因为模型权重是 FP32,所以即使函数以 FP16 运行,也会得到 FP32 的梯度
- (d). 将梯度 unscale,即除以 loss_scale
- (e). 如果检测到 inf 或 nan.
- i. loss_scale /= 2
- ii. 跳过此次更新
- (f).
optimizer.step(),执行此次更新 - (g). 如果连续 2000 次迭代都没有出现 inf 或 nan,则 loss_scale *= 2
apex 的 o2 实现
- (1) 将除了 BN 层以外的模型权重转化为 FP16,并且包装了 forward 函数,将其参数也转化为 FP16
- (2) 维护一个 FP32 的模型权重副本用于更新
- (3) 将 loss_scale 初始化为一个很大的值
- (4) 对于每次迭代
- (a). 前向传播: 除了 BN 层是 FP32,模型其它部分都是 FP16
- (b). 将 loss 乘以 loss_scale
- ( c c c). 反向传播,得到 FP16 的梯度
- (d). 将 FP16 梯度转化为 FP32,并 unscale
- (e). 如果检测到 inf 或 nan
- i. loss_scale /= 2
- ii. 跳过此次更新
- (f). optimizer.step(),执行此次更新
- (g). 如果连续 2000 次迭代都没有出现 inf 或 nan,则 loss_scale *= 2
在 PyTorch 中使用混合精度训练
Automatic Mixed Precision (AMP)
from torch.cuda.amp import autocast, GradScaler
- 通常 AMP 需要同时使用 autocast 和 GradScaler,其中 autocast 的实例对象是作为上下文管理器 (context manger) 或装饰器 (decorator) 来允许用户代码的某些区域在混合精度下运行,自动为 CUDA 算子选择(单/半)精度来提升性能并保持精度 (See the Autocast Op Reference for details on what precision autocast chooses for each op, and under what circumstances.),并且 autocast 区域是可以嵌套的,这可以强制让 FP16 下可能溢出的模型部分以 FP32 运行;而 GradScaler 则是用来进行 loss scale
- autocast 应该只封装网络的前向传播 (forward pass(es)),以及损失计算 (loss computation(s))。反向传播不推荐在 autocast 区域内执行,反向传播的操作会自动以对应的前向传播的操作的数据类型运行
Typical Mixed Precision Training
# Creates model and optimizer in default precision
model = Net().cuda()
optimizer = optim.SGD(model.parameters(), ...)
# Creates a GradScaler once at the beginning of training.
scaler = GradScaler(enabled=True)
for epoch in epochs:
for input, target in data:
optimizer.zero_grad()
# Runs the forward pass with autocasting.
with autocast(enabled=True, dtype=torch.float16):
output = model(input)
loss = loss_fn(output, target)
# Scales loss. Calls backward() on scaled loss to create scaled gradients.
scaler.scale(loss).backward()
# scaler.step() first unscales the gradients of the optimizer's assigned params.
# If these gradients do not contain infs or NaNs, optimizer.step() is then called,
# otherwise, optimizer.step() is skipped.
scaler.step(optimizer)
# Updates the loss scale value for next iteration.
scaler.update()
Saving/Resuming
checkpoint = {"model": net.state_dict(),
"optimizer": opt.state_dict(),
"scaler": scaler.state_dict()}
net.load_state_dict(checkpoint["model"])
opt.load_state_dict(checkpoint["optimizer"])
scaler.load_state_dict(checkpoint["scaler"])
Working with Unscaled Gradients (Gradient Clipping)
- 经过
scaler.scale(loss).backward()得到的梯度是 scaled gradient,如果想要在scaler.step(optimizer)前进行梯度裁剪等操作,就必须先用scaler.unscale_(optimizer)得到 unscaled gradient
scaler = GradScaler()
for epoch in epochs:
for input, target in data:
optimizer.zero_grad()
with autocast(dtype=torch.float16):
output = model(input)
loss = loss_fn(output, target)
scaler.scale(loss).backward()
# Unscales the gradients of optimizer's assigned params in-place
scaler.unscale_(optimizer)
# Since the gradients of optimizer's assigned params are unscaled, clips as usual:
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm)
# optimizer's gradients are already unscaled, so scaler.step does not unscale them,
# although it still skips optimizer.step() if the gradients contain infs or NaNs.
scaler.step(optimizer)
# Updates the scale for next iteration.
scaler.update()
Working with Scaled Gradients
Gradient accumulation
- Gradient accumulation 基于 effective batch of size
batch_per_iter*iters_to_accumulate(*num_procsif distributed) 进行梯度累加,因此属于同一个 effective batch 的多个迭代 batch 内,scale factor 应该保持不变 (scale updates should occur at effective-batch granularity),并且累加的梯度应该是 Scaled Gradients。因为如果在梯度累加结束前的某一个迭代中 unscale gradient (或改变 scale factor),那么下一个迭代的梯度回传就会把 scaled grads 加到 unscaled grads (或乘上了不同 scale factor 的 scaled grads) 上,这会使得在最后进行梯度更新时,我们无法恢复出 accumulated unscaled grads. 如果想要 unscaled grads,应该在梯度累加结束后调用scaler.unscale_(optimizer)
scaler = GradScaler()
for epoch in epochs:
for i, (input, target) in enumerate(data):
with autocast(dtype=torch.float16):
output = model(input)
loss = loss_fn(output, target)
loss = loss / iters_to_accumulate
# Accumulates scaled gradients.
scaler.scale(loss).backward()
if (i + 1) % iters_to_accumulate == 0:
# may unscale_ here if desired (e.g., to allow clipping unscaled gradients)
scaler.step(optimizer)
scaler.update()
optimizer.zero_grad()
Gradient penalty
- https://pytorch.org/docs/stable/notes/amp_examples.html#gradient-penalty
Working with Multiple GPUs
- 目前的版本中 (v1.13),不管是 DP (one GPU per thread) (多线程) 还是 DDP (one GPU per process) (多进程),上述代码都无需改动。只有当使用 DDP (multiple GPUs per process) 时,才需要给 model 的 forwad 方法添加 autocast 装饰器或上下文管理器
- 当然,如果使用老版本的 pytorch,是否需要改动代码请参考官方文档
其他注意事项
- 常数的范围:为了保证计算不溢出,首先要保证人为设定的常数不溢出,如各种 epsilon,INF (改成
-float('inf')就可以啦)
References
- paper: Micikevicius, Paulius, et al. “Mixed precision training.” (ICLR, 2018).
- AUTOMATIC MIXED PRECISION PACKAGE - TORCH.AMP
- CUDA AUTOMATIC MIXED PRECISION EXAMPLES
- Automatic Mixed Precision Recipe
- 由浅入深的混合精度训练教程
- 【PyTorch】唯快不破:基于 Apex 的混合精度加速
- 浅谈混合精度训练
- 【Trick2】torch.cuda.amp自动混合精度训练 —— 节省显存并加快推理速度
- 自动混合精度训练 (AMP) – PyTorch