文章目录
- 前言
- 一、分布式ID需要满足的条件
- 二、分布式ID生成方式
- 基于UUID
- 数据库自增
- 数据库集群
- 数据库号段模式
- redis ID生成
- 基于雪花算法(Snowflake)模式
- 百度(uid-generator)
- 美团(Leaf)
- 滴滴(Tinyid)
前言
对于单体系统来说,主键ID可能会常用主键自动的方式进行设置,这种ID生成方法在单体项目是可行的,但是对于分布式系统,分库分表之后,就不适应了,比如订单表数据量太大了,分成了多个库,如果还采用数据库主键自增的方式,就会出现在不同库id一致的情况。
一、分布式ID需要满足的条件
① 全局唯一:必须保证ID是全局性唯一的。
② 趋势有序:业务上分页查询需求,排序需求,如果ID直接有序,则不必建立更多的索引,增加查询条件。
而且Mysql InnoDB存储引擎主键使用聚集索引,主键有序则写入性能更高。
③ 高可用:ID是一条数据的唯一标识,如果ID生成失败,则影响很大,业务执行不下去。所以好的ID方案需要有高可用。
④ 信息安全:ID虽然趋势有序,但是不可以被看出规则,免得被爬取信息。
二、分布式ID生成方式
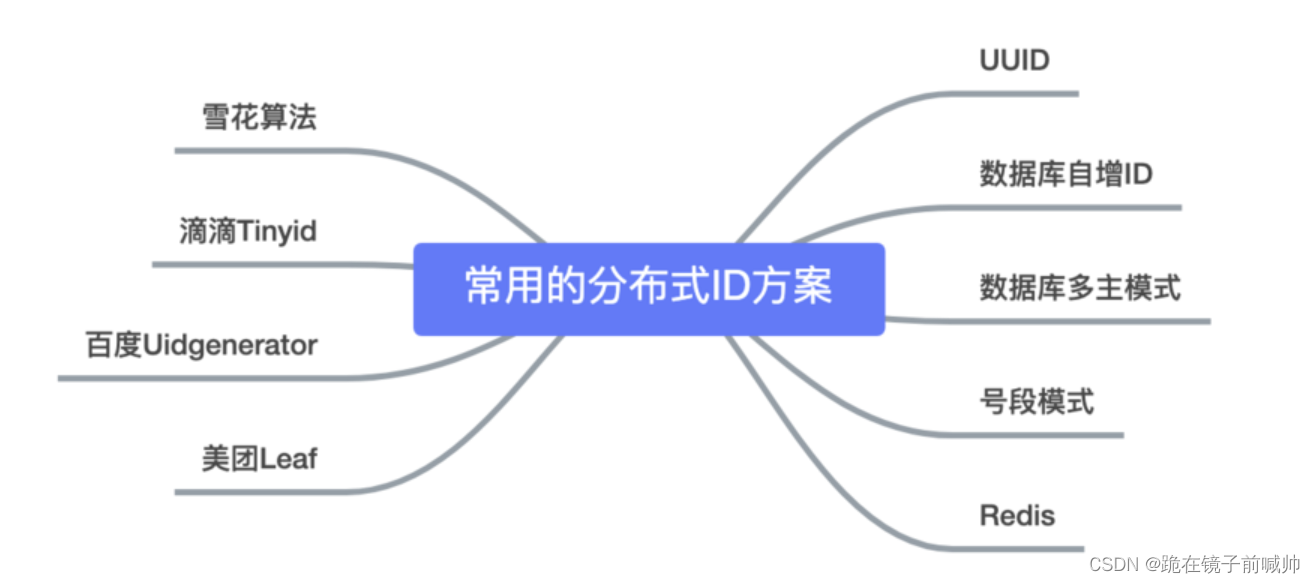
今天主要分析一下以下9种,分布式ID生成器方式以及优缺点:
- UUID
- 数据库自增ID
- 数据库多主模式
- 号段模式
- Redis
- 雪花算法(SnowFlake)
- 滴滴出品(TinyID)
- 百度 (Uidgenerator)
- 美团(Leaf)
注:主流生成ID方案都是基于数据库号段模式和雪花算法
基于UUID
UUID (Universally Unique Identifier),通用唯一识别码的缩写。UUID的标准型式包含32个16进制数字,以连字号分为五段,形式为8-4-4-4-12的36个字符,示例: 863e254b-ae34-4371-87da-204b71d46a7b。
String uuid = UUID.randomUUID().toString().replaceAll("-","");
System.out.println(uuid);// 9c58226555c248018be2032964de2de6
优点:
- 性能非常高,本地生成的,不依赖于网络。
缺点:
- 无序。
- 不能标识出此ID的含义,不可读。
- 字符串太长且无序,作为MySQL主键,影响性能。
数据库自增
基于数据库的 auto_increment 自增ID完全可以充当分布式ID。
优点:
- 实现起来比较简单,ID 有序递增,存储消耗空间小。
缺点:
- 存在数据库单点问题(可以使用数据库集群解决,不过增加了复杂度)。
- ID 没有具体业务含义。
- 安全问题(比如根据订单 ID 的递增规律就能推算出每天的订单量)。
- 每次获取 ID 都要访问一次数据库(增加了对数据库的压力,获取速度也慢)。
- 分库分表后,同一数据表的自增ID容易重复,无法直接使用(可以设置步长,但局限性很明显),ID没有了单调递增的特性,只能趋势递增,有些业务场景可能不符合。
数据库集群
前边说了单点数据库方式不可取,那对上边的方式做一些高可用优化,换成主从模式集群。害怕一个主节点挂掉没法用,那就做双主模式集群,也就是两个Mysql实例都能单独的生产自增ID。
设置起始值和自增步长
MySQL_1 配置:
set @@auto_increment_offset = 1; -- 起始值
set @@auto_increment_increment = 2; -- 步长
MySQL_2 配置:
set @@auto_increment_offset = 2; -- 起始值
set @@auto_increment_increment = 2; -- 步长
这样两个MySQL实例的自增ID分别就是:
1、3、5、7、9
2、4、6、8、10
水平扩展的数据库集群,有利于解决数据库单点压力的问题,同时为了ID生成特性,将自增步长按照机器数量来设置。
增加第三台MySQL实例需要人工修改一、二两台MySQL实例的起始值和步长,把第三台机器的ID起始生成位置设定在比现有最大自增ID的位置远一些,但必须在一、二两台MySQL实例ID还没有增长到第三台MySQL实例的起始ID值的时候,否则自增ID就要出现重复了,必要时可能还需要停机修改。
优点:
- 解决DB单点问题
缺点:
- 不利于后续扩容。
- 实际上单个数据库自身压力还是大,依旧无法满足高并发场景。
数据库号段模式
这种模式也是现在生成分布式ID的一种方法,实现思路是会从数据库获取一个号段范围,比如[1,1000],生成1到1000的自增ID加载到内存中,建表结构如:
CREATE TABLE `sequence_id_generator` (
`id` int(10) NOT NULL,
`current_max_id` bigint(20) NOT NULL COMMENT '当前最大id',
`step` int(10) NOT NULL COMMENT '号段的长度',
`version` int(20) NOT NULL COMMENT '版本号',
`biz_type` int(20) NOT NULL COMMENT '业务类型',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
current_max_id 字段和 step 字段主要用于获取批量 ID,id 为: current_max_id ~ current_max_id + step 。
version 字段主要用于解决并发问题(乐观锁),biz_type 主要用于表示业务类型。
① 先插入一行数据
INSERT INTO `sequence_id_generator` (`id`, `current_max_id`, `step`, `version`, `biz_type`) VALUES(1, 0, 100, 0, 101);
② 通过 SELECT 获取指定业务下的批量唯一 ID
SELECT `current_max_id`, `step`,`version` FROM `sequence_id_generator` where `biz_type` = 101
③ 不够用的话,更新之后重新 SELECT 即可。
UPDATE sequence_id_generator SET current_max_id = 0+100, version=version+1 WHERE version = 0 AND `biz_type` = 101
SELECT `current_max_id`, `step`,`version` FROM `sequence_id_generator` where `biz_type` = 101
相比于数据库主键自增的方式,数据库的号段模式对于数据库的访问次数更少,数据库压力更小。
另外,为了避免单点问题,你可以从使用主从模式来提高可用性。
优点:
- ID 有序递增,存储消耗空间小,有比较成熟的方案,像百度Uidgenerator,美团Leaf
缺点:
- 依赖于数据库实现。
redis ID生成
Redis分布式ID实现主要是通过提供像 INCR 和 INCRBY 这样的自增原子命令,由于Redis单线程的特点,可以保证ID的唯一性和有序性。
这种实现方式,如果并发请求量上来后,就需要集群,不过集群后,又要和传统数据库一样,设置分段和步长。
时间+用redis的incr自增命令(每日从1开始),代码如下:
public class RedisCounterRepository {
private final DateTimeFormatter dateTimeFormatter = DateTimeFormatter.ofPattern("yyyyMMdd");
private RedisTemplate<String, Object> redisTemplate;
@Autowired
public RedisCounterRepository(RedisTemplate<String, Object> redisTemplate) {
this.redisTemplate = redisTemplate;
}
// 根据获取的自增数据,添加日期标识构造分布式全局唯一标识,changeNumPrefix是自己定义的随机前缀
private String getNumFromRedis(String changeNumPrefix) {
String dateStr = LocalDate.now().format(dateTimeFormatter);
Long value = incrementNum(changeNumPrefix + dateStr);
//不足4位补0,redis从1开始生成的,每天再次请0
return dateStr + StringUtils.leftPad(String.valueOf(value), 4, '0');
}
// 从redis中获取自增数据(redis保证自增是原子操作)
private long incrementNum(String key) {
RedisConnectionFactory factory = redisTemplate.getConnectionFactory();
if (null == factory) {
log.error("Unable to connect to redis.");
throw new UserException(AppStatus.INTERNAL_SERVER_ERROR);
}
RedisAtomicLong redisAtomicLong = new RedisAtomicLong(key, factory);
long increment = redisAtomicLong.incrementAndGet();
if (1 == increment) {
// 如果数据是初次设置,需要设置超时时间
redisAtomicLong.expire(1, TimeUnit.DAYS);
}
return increment;
}
}
用redis实现需要注意一点,要考虑到redis持久化的问题。redis有两种持久化方式RDB和AOF
RDB会定时打一个快照进行持久化,假如连续自增但redis没及时持久化,而这会Redis挂掉了,重启Redis后会出现ID重复的情况。AOF会对每条写命令进行持久化,即使Redis挂掉了也不会出现ID重复的情况,但由于incr命令的特殊性,会导致Redis重启恢复的数据时间过长。
优点:
- 性能不错、每秒10万并发量。
- 生成的 ID 是有序递增的
缺点:
- redis 宕机后不可用,RDB重启数据丢失会重复ID。
- 自增,数据量易暴露。
基于雪花算法(Snowflake)模式
根据这个算法的逻辑,只需要将这个算法用Java语言实现出来,封装为一个工具方法,那么各个业务应用可以直接使用该工具方法来获取分布式ID,只需保证每个业务应用有自己的工作机器id即可,而不需要单独去搭建一个获取分布式ID的应用。
https://blog.csdn.net/yy139926/article/details/128468074
优点:
- 雪花算法生成的ID是趋势递增,不依赖数据库等第三方系统,生成ID的效率非常高,稳定性好,可以根据自身业务特性分配bit位,比较灵活。
缺点:
- 每台机器的时钟不同,当时钟回拨可能会发生重复ID。
- 当数据量大时,需要对ID取模分库分表,在跨毫秒时,序列号总是归0,会发生取模后分布不均衡。
如何解决时间回拨问题
时间回拨是指,当机器出现问题,时间可能回到之前,此时雪花算法生成的id可能与之前的id值相同,从而导致id重复。
- 系统抛出异常,运维来手动调整时间。
- 延迟等待,对于偶然性的时间回拨,也许是机器出现了一次小故障,频繁出现的概率并不大,所以对于这种情况没必要中断业务,可以采用阻塞线程5ms,再获取时间,对比看时间是否比上一次请求的时间大,如果大了,说明恢复正常了,则不用管;如果还小,说明真出问题了,则抛出异常,呼唤程序员处理。
- 备用机方式来解决,当前机器出现问题,迅速换一台机器,通过高可用解决。
百度(uid-generator)
略
美团(Leaf)
https://blog.csdn.net/yy139926/article/details/126740614
滴滴(Tinyid)
略

![[MySQL教程②] - MySQL介绍和发展史](https://img-blog.csdnimg.cn/img_convert/cfd671ea384c882876037805e9673e57.png)



![[全栈工程师]从0到封神](https://img-blog.csdnimg.cn/4430451040574a9f9a111904372be42b.png)