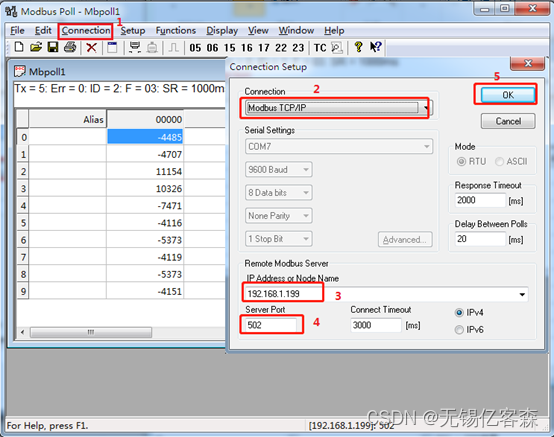
2.2、Spark SQL
2.2.1、Execute Engine

SparkSql的整体提交执行流程和Hive的执行流程基本上一致。站在通用的角度,对于SparkSql来说,从Sql到Spark的RDD执行需要经历两个大的阶段:逻辑计划和物理计划
逻辑计划层面会把用户提交的sql转换成树型结构,把sql中的逻辑映射到逻辑算子树的不同节点,该阶段并不会真正的进行提交执行,只是作为中间阶段。在这个过程中会经历三个阶段:
1、未解析的逻辑算子树(Unresolved LogicalPlan),该阶段只是通过Antlr Parser把sql进行词法分析,语法验证得到数据结构,并不包含任何数据信息。
2、解析后的逻辑算子数(Analyzed LogicalPlan),这个阶段会结合Catalog元数据信息对第一阶段得到的节点进行绑定
3、优化逻辑算子树(Optimized LogicalPlan),该阶段结合节点数据信息,应用一些优化规则对一些低效的逻辑计划进行转换。
物理计划层面会把上一步优化后的逻辑算子树进行进一步的转换,生成物理算子树,物理算子树上的节点会直接生成RDD或者对RDD进行transformation操作,并最终执行。那么对物理计划进行细分的话,又可以分为三个子阶段:
1、物理算子树列表(Iterable[PhysicalPlan]):根据优化后得到的逻辑算子树进行转换生成物理算子树的列表。
2、最优物理算子树(SparkPlan):从物理算子树列表中按照一定的策略选取最优的物理算子树。
3、准备算子树(Prepared SparkPlan):得到最优的算子树之后,那么就开始准备一些执行工作,如执行代码生成、确保分区操作正确、物理算子树节点重用等工作。
最后会对生成的RDD执行Action操作进行真正的作业执行。以上所有的流程均是在Spark的Driver端完成的,这个时候还不涉及到集群环境。
上述的所有流程可以通过SparkSession类的sql方法作为入口,调用SessionState各种对象(SparkSqlParser、Analyzer、Optimizer、SparkPlanner),最后封装一个QueryExecution对象。所以上面的每一步流程都有单独独立的类功能实现,对于我们日常开发工作中进一步剥离分析进行二次加工提供了很大的。
Spark SQL在执行SQL之前,会将SQL或者Dataset程序解析成逻辑计划,然后经历一系列的优化,最后确定一个可执行的物理计划。最终选择的物理计划的不同对性能有很大的影响。如何选择最佳的执行计划,这便是Spark SQL的Catalyst优化器的核心工作。Catalyst早期主要是基于规则的优化器(RBO),在Spark 2.2中又加入了基于代价的优化(CBO)。
2.2.1.1. RBO
根据上面的执行流程,SparkSql在逻辑优化层面主要是基于规则的优化,即RBO(Rule-Based-Optimization)
1、每个优化都是以Rule的形式存在,每条Rule都是对Analyzed Plan的等价转换
2、RBO易于扩展,新增规则可以非常方便嵌入到Optimizer中
3、RBO优化的主要思路在于减少参与计算的数据量以及计算本身的代价。
如常见的谓词下推、常量合并、列裁剪等优化手段
2.2.1.2、CBO
RBO层面的优化主要是针对逻辑计划,未考虑到数据本身的特点(数据分布、大小)以及算子执行(中间结果集分布、大小)的代价,因此sparksql又引入了CBO优化机制(Cost-Based Optimized),该优化主要在物理计划层面,其原理是计算所有可能的物理计划的代价,并挑选出代价最小的物理计划,其核心在于评估一个给定的物理执行计划的代价,其代价等于每个执行节点的代价总和。而每个执行节点的代价,又分为两个部分:
1、该执行节点对数据集的影响,或者说该节点输出数据集的大小和分布。
2、该执行节点操作算子的代价。操作算子的代价相对比较固定,可以用规则来描述。
而执行节点输出数据集主要分为两部分:
1、初始数据集,例如原始文件,其数据集的大小和分布可以直接统计得到的。
2、中间节点输出数据集的大小和分布可以根据输入数据集的信息和操作本身的特点来推算。
因此CBO优化最主要需要先解决两个问题:
1、怎么样子可以获取到原始数据集的统计信息
2、如何根据输入数据集估算特定算子的输出数据特征情况
2.2.1.2.1、如何统计到原始数据集的信息
可以通过Analyze table来分析统计出原始数据集的大小(略)
2.2.1.2.2、算子代价估计
SQL中最常见的就是Join操作,这里以Join方法为例,说明SparkSql的CBO是如何进行估价的。主要是通过以下公式:
Cost = rows * weight + size * (1-weight) ;其中rows为行数代表CPU代价,Size为大小代表IO代价。
Cost = CostCpu * weight + CostIO * (1-weight)
Weight权重的配置可以通过spark.sql.cbo.joinRecorder.card.weight决定,默认为0.7
2.2.1.3、AE
2.2.1.3.1、背景
在生产环境中,往往需要提前配置好分区数以及使用资源,然后在运行的过程中或者事后进行不断的调整参数值来达到最优。但是由于每次计算的数据量可能会变化很大,那么可能需要每次都会人工干涉进行调优,这也意味sql作业很难以最优的性能去运行。而且Catalyst优化器的一些优化工作是在计划阶段,一旦优化完成之后,在运行期间就不能改变。因此需要在运行期间拿到更多的运行信息,不断调整执行计划来达到最优,因此在Spark2.3之后引入了一个Adaptive(自适应)执行机制,需要通过spark.sql.adaptive.enabled参数来开启其机制
2.2.1.3.2、执行原理
根据Spark作业执行流程可知是先根据RDD的DAG图进行划分生成Stage然后提交作业执行,因此在执行过程中计划是不会发生变化的。那么
自适应执行的基本思路是在执行计划中事先划分好stage,然后按stage提交执行,在运行时收集当前stage的shuffle统计信息,以此来优化下一个stage的执行计划,然后再提交执行后续的stage。
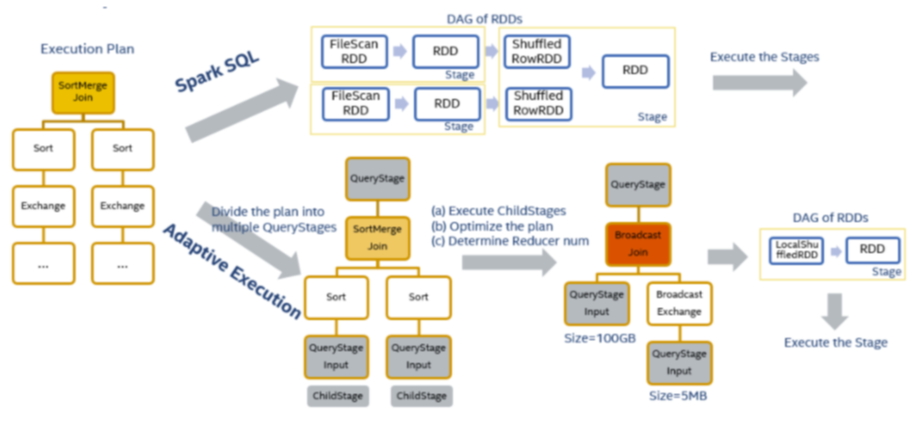
对于图中两表join的执行计划来说会创建3个QueryStage。最后一个QueryStage中的执行计划是join本身,它有2个QueryStageInput代表它的输入,分别指向2个孩子的QueryStage。在执行QueryStage时,我们首先提交它的孩子stage,并且收集这些stage运行时的信息。当这些孩子stage运行完毕后,我们可以知道它们的大小等信息,以此来判断QueryStage中的计划是否可以优化更新。例如当我们获知某一张表的大小是5M,它小于broadcast的阈值时,我们可以将SortMergeJoin转化成BroadcastHashJoin来优化当前的执行计划。我们也可以根据孩子stage产生的shuffle数据量,来动态地调整该stage的reducer个数。在完成一系列的优化处理后,最终我们为该QueryStage生成RDD的DAG图,并且提交给DAG Scheduler来执行
2.2.1.3.3、实现点
该机制主要有三个功能点:
1、自动设置shuffle分区数
主要解决的问题有以下几点:
1.1、如果设置分区数过小可能会导致每个task处理大量的数据,会发生溢写磁盘的情况影响性能,甚至发生频繁GC或者OOM。
1.2、如果设置分区数过大可能会导致每个task处理小量的数据,而且会有可能产生小文件,甚至会出现资源空闲的情况。
1.3、设置分区数是对所有的Stage都会生效,而每个Stage所处理的数据量和分布都不太一样,所以全局的分区数只能对某些Stage是最优的,无法做到全局最优。
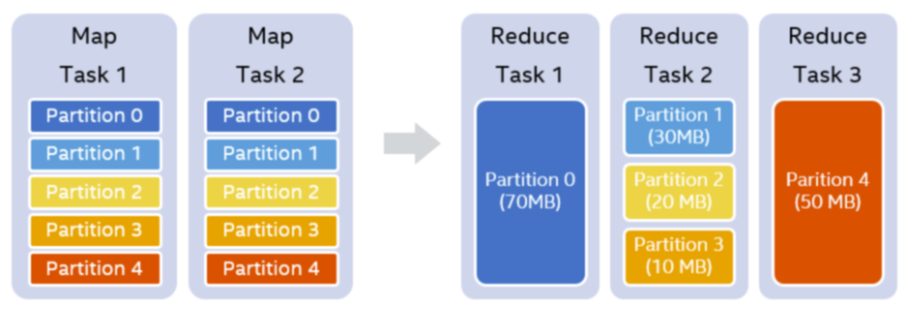
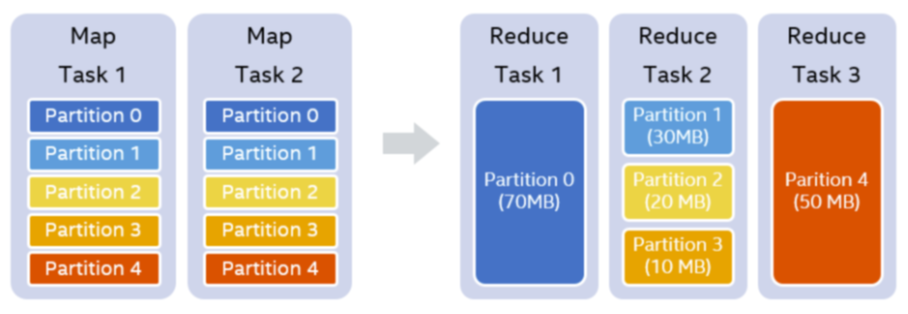
例如我们设置的shufflepartition个数为5,在map stage结束之后,我们知道每一个partition的大小分别是70MB,30MB,20MB,10MB和50MB。假设我们设置每一个reducer处理的目标数据量是64MB,那么在运行时,我们可以实际使用3个reducer。第一个reducer处理partition 0 (70MB),第二个reducer处理连续的partition 1 到3,共60MB,第三个reducer处理partition 4 (50MB)
2、动态调整执行计算
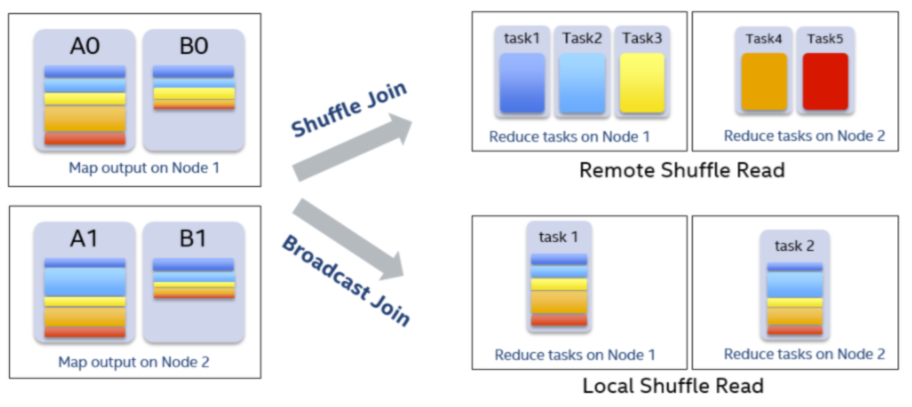
以join操作为例,在Spark中最常见的策略是BroadcastHashJoin和SortMergeJoin。BroadcastHashJoin属于map side join,其原理是当其中一张表存储空间大小小于broadcast阈值时,Spark选择将这张小表广播到每一个Executor上,然后在map阶段,每一个mapper读取大表的一个分片,并且和整张小表进行join,整个过程中避免了把大表的数据在集群中进行shuffle。而SortMergeJoin在map阶段2张数据表都按相同的分区方式进行shuffle写,reduce阶段每个reducer将两张表属于对应partition的数据拉取到同一个任务中做join。CBO根据数据的大小,尽可能把join操作优化成BroadcastHashJoin。Spark中使用参数spark.sql.autoBroadcastJoinThreshold来控制选择BroadcastHashJoin的阈值,默认是10MB。然而对于复杂的SQL查询,它可能使用中间结果来作为join的输入,在计划阶段,Spark并不能精确地知道join中两表的大小或者会错误地估计它们的大小,以致于错失了使用BroadcastHashJoin策略来优化join执行的机会。但是在运行时,通过从shuffle写得到的信息,我们可以动态地选用BroadcastHashJoin。
3、动态处理数据倾斜
在SQL作业中,数据倾斜是很常见的问题,但都是事后人为通过一些手段进行解决的,那么能不能在运行时自动处理掉呢?
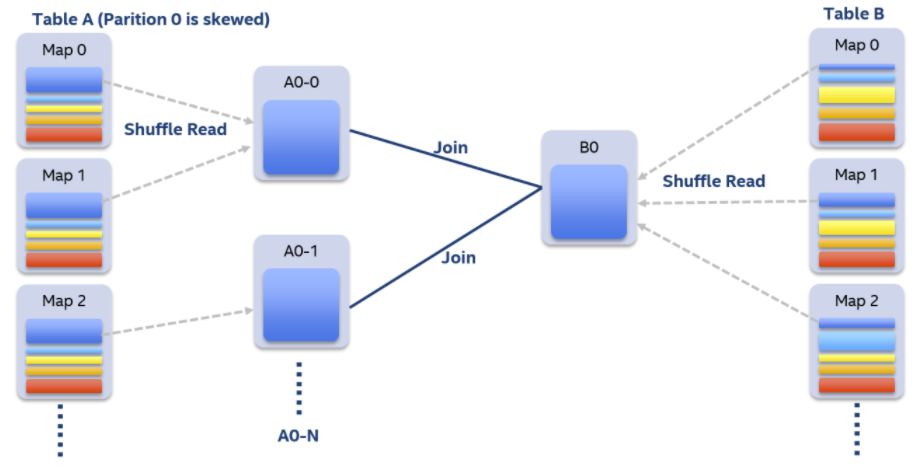
假设A表和B表做inner join,并且A表中第0个partition是一个倾斜的partition。
一般情况下,A表和B表中partition 0的数据都会shuffle到同一个reducer中进行处理,由于这个reducer需要通过网络拉取大量的数据并且进行处理,它会成为一个最慢的任务拖慢整体的性能。
在自适应执行框架下,一旦我们发现A表的partition 0发生倾斜,我们随后使用N个任务去处理该partition,每个任务只读取若干个mapper的shuffle 输出文件,然后读取B表partition 0的数据做join。最后,我们将N个任务join的结果通过Union操作合并起来。
为了实现这样的处理,我们对shuffle read的接口也做了改变,允许它只读取部分mapper中某一个partition的数据。在这样的处理中,B表的partition 0会被读取N次,虽然这增加了一定的额外代价,但是通过N个任务处理倾斜数据带来的收益仍然大于这样的代价。
如果B表中partition 0也发生倾斜,对于inner join来说我们也可以将B表的partition 0分成若干块,分别与A表的partition 0进行join,最终union起来。但对于其它的join类型例如Left Semi Join我们暂时不支持将B表的partition 0拆分。
4、Left join build left side map
对于left join的情况,可以对左表进行HashMapBuild。可以实现小左表left join 大右表的情况下进行ShuffledHashJoin调整。
原理:
1、在构建左表Map的时候,额外维持一个“是否匹配成功”的映射表。
2、在和右表join结束之后,把所有没有匹配到的key,用null来join填充。


![[全栈工程师]从0到封神](https://img-blog.csdnimg.cn/4430451040574a9f9a111904372be42b.png)