您好,我是湘王,这是我的CSDN博客,欢迎您来,欢迎您再来~
缓存的存储空间是远远小于磁盘的。所以对于有些过期的数据,就需要定期进行清理,腾出存储空间。Caffeine又是怎么做的呢?
Caffeine和进程外缓存Redis一样,也有主动失效和被动失效。主动失效就是数据过期后由淘汰算法自动清除,被动失效就是由开发同学手动清理了。但这种被动失效还可以增加一些自定义功能,也就是增加回调事件。
普通的被动失效只需要调用invalidate()方法就行了:

如果需要增加一些自定义功能,那么可以增加一个「移除」监听器:
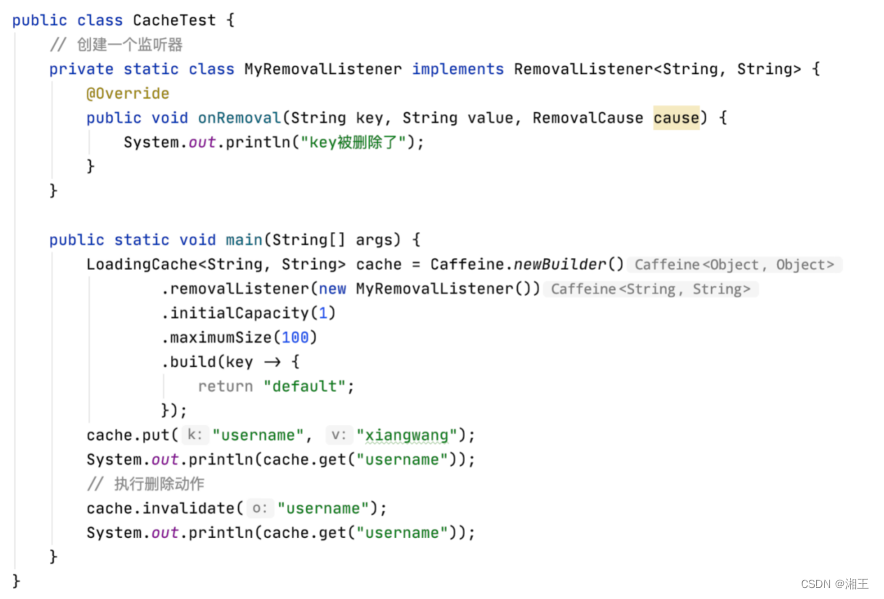
和Guava一样,Caffeine也提供了一个仪表盘来监控缓存状态:
hitRate():返回命中与请求的比率;
hitCount(): 返回命中缓存的总数;
evictionCount():缓存逐出的数量;
averageLoadPenalty():加载新值所花费的平均时间。

Caffeine作为进程内缓存,也吸收了进程外缓存Redis的一些特性,比如持久化。但Caffeine只做到了半持久化:它可以充当一个底层资源的代理,也就是说可以通过Caffeine操作其他存储资源。Caffeine把操作缓存和操作外部资源这两种操作,封装成一个同步的原子性操作。

其中,CacheWriter可能用来集成多个缓存进而实现多级缓存,受害者缓存(Victim Cache)将被删除数据被写入二级缓存。
了解了被动失效之后,再来看看Caffeine的主动失效算法。
常见的淘汰算法包括下面这些:
1、FIFO:First In First Out,先进先出算法,就是谁先来就淘汰谁,众生平等,只能顺序读写,使用也非常简单,这是最早使用的淘汰算法,问题在于如果某些数据经常使用,也会被淘汰掉。

2、LRU:Least Recently Used,最近最少使用算法,就是谁用得最少就淘汰谁,这是目前主流的缓存淘汰算法,问题在于,如果某些数据隔一段时间就会被频繁使用,也会被淘汰掉。
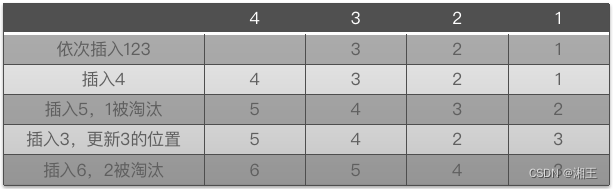
3、LFU:Least Frequently Used,最近不经常使用算法,就是淘汰最近用得最少的那些数据,这是对LRU的一种改进,但同样也有问题,就是某个数据如果只是一开始出现的很频繁,但后面再也没出现过,那么仍然可能被缓存着。
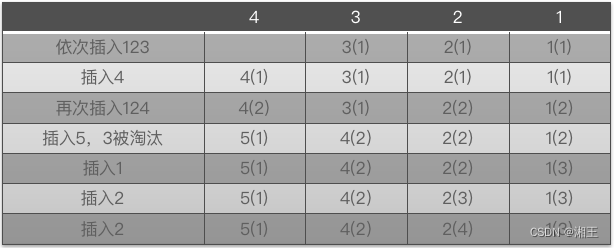
LFU有两个很明显的缺点:
1、需要维护大而复杂的元数据来实现算法,而且每次访问都需要更新,开销巨大;
2、如果访问频率变化,LFU的频率信息却无法随之变化,造成命中率急剧下降。
为了解决LFU算法存储开销大的问题,TinyLFU出现了。TinyLFU利用Count-Min Sketch算法维护近期访问数据的频率信息,可以在具有较大访问量的场景下近似的替代LFU的数据统计部分,其原理有些类似布隆过滤器(Bloom Filter)。
Bloom Filter是一种空间利用效率很高的随机数据结构,它能用bit数组很简洁地表示一个集合:
1、使用一个大的bit数组存储所有key,每一个key通过多次不同的hash计算映射到数组的不同bit位;
2、如果key存在就将对应的bit位设置增加1,这样就可以通过少量的存储空间进行大量的数据过滤;
3、TinyLFU把多个bit位看做一个整体,用来统计key的使用频率,在读取时,取映射的所有值中的最小的值作为key的使用频率。
比如针对key的hash计算结果会映射到下面的bit数组中,TinyLFU会读取数值最小的h2(a)作为key的使用频率数据:
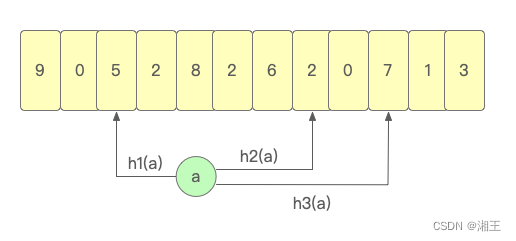
Caffeine中维护了一个4-bit的Count-Min Sketch用来记录key的使用频率,这也意味着统计的key最大使用频率为15。
TinyLFU仍然有一个缺点,也就是LFU的第二个问题:如果访问频率突变,会造成缓存命中率的急剧下降,比如微博热点事件,某些词当天被搜索10W次,但是热度过去了,可能就再也不会出现了,然而相关数据却依然还在缓存中没被清理。
W-TinyLFU正是为了解决这类数据过期问题而诞生,它由两部分组成:
1、窗口缓存Window Cache使用没有任何回收策略的LRU,占总缓存大小的1%,用于存储新到来的数据,主要为应对短期流量突发的访问场景;
2、主缓存Main Cache使用分段SLRU + TinyLFU,占总缓存大小的99%;
3、其中分段SLRU又被分为两个区:Probation区,用于存储比较冷门的数据,占用主缓存20%空间,另一个Protected区,用于存储比较热门的数据,占用主缓存80%空间。
具体的淘汰过程是:
1、新添加的数据首先放入窗口缓存Window Cache(LRU)中,同时由TinyLFU完成计数;
2、如果Window Cache满了,就把Window Cache淘汰的数据转移到主缓存Probation区中;
3、如果Probation区还未满,并且其中的数据在后续操作中再次被访问时,那么该条数据会进入Protected区;
4、如果Probation区也满了,就比较从窗口缓存Window Cache转移过来的数据(候选者)和Probation要淘汰的数据(受害者);
5、如果Protected区也满了,那么会按照LRU策略将数据驱逐到Probation区。

不得不说,W-TinyLFU算法的淘汰过程和JVM GC过程非常像:
1、在区域划分上:Window Cache对应S0和S1、Probation区对应Eden区、Protected区对应老年代;
2、在数据淘汰流程上:先进入Window Cache(S0和S1)、再进入Probation区(Eden区)或从Probation区淘汰、再进入Protected区(老年代)或从Protected区淘汰。
感谢您的大驾光临!咨询技术、产品、运营和管理相关问题,请关注后留言。欢迎骚扰,不胜荣幸~