版权声明: 本文禁止转载
机械硬盘的存储系统由于内部结构,其IO访问性能无法进一步提高,CPU与存储器之间的性能差距逐渐扩大。以Nand Flash为存储介质的固态硬盘技术的发展,性能瓶颈得到缓解。

1. 什么是SSD
固态硬盘(Solid State Drives),用固态电子存储芯片阵列而制成的硬盘,由控制单元和存储单元(FLASH芯片、DRAM芯片)组成。固态硬盘被广泛使用于军事方面、车载系统方面、工程控制技术方面、视频监控存储、网络监控存储、网络终端保存、电力系统方面、医疗信息存储方面、航空技术方面、导航设备存储等重要领域。
2. SSD的存储介质分类
固态硬盘(SSD)的存储介质分为两种,一种是采用闪存(FLASH芯片)作为存储介质,另外一种是采用DRAM作为存储介质。
基于闪存类:基于闪存的固态硬盘(IDEFLASH DISK、Serial ATA Flash Disk),采用FLASH芯片作为存储介质,这也是通常所说的SSD。它的外观可以被制作成多种模样,例如:笔记本硬盘、微硬盘、存储卡、U盘等样式。这种SSD固态硬盘最大的优点就是可以移动,而且数据保护不受电源控制,能适应于各种环境,适合于个人用户使用。
基于DRAM类:基于DRAM的固态硬盘,采用DRAM作为存储介质,应用范围较窄。它仿效传统硬盘的设计,可被绝大部分操作系统的文件系统工具进行卷设置和管理,并提供工业标准的PCI和FC接口用于连接主机或者服务器。应用方式可分为SSD硬盘和SSD硬盘阵列两种。它是一种高性能的存储器,而且使用寿命很长,美中不足的是需要独立电源来保护数据安全。DRAM固态硬盘属于比较非主流的设备。
基于3D XPoint类:在闪存与DRAM之间开创新市场的新一代内存技术, 3D XPoint是一种新的非易失性存储技术,也就是能像NAND闪存那样断电保持数据,但同时又有着极高的速度和性能,能够达到DRAM内存级别,因此它既能做成硬盘,也能做成内存,而且单位容量成本介于二者之间,堪称梦幻黑科技。3D XPoint的首款产品将是“Optane”傲腾品牌的固态硬盘。只有少数高端系列有, 而且已经放弃了3D XPoint技术,可惜了这么强大的技术,性能秒杀各种NAND SSD,最终输给了市场, 昙花一现。
3. SSD的结构
SSD主要由主控制器芯片,闪存芯片,缓存芯片(可选),以及跟HOST接口(诸如SATA,SAS, PCIe等)组成。SSD作为数据存储设备, 其实是一种典型的(System on Chip) 单机系统, 有主控CPU、 RAM、 操作加速器、 总线、 数据编码译码等模块(见图2-1) , 操作对象为协议、 数据命令、 介质, 操作目的是写入和读取用户数据。[7]
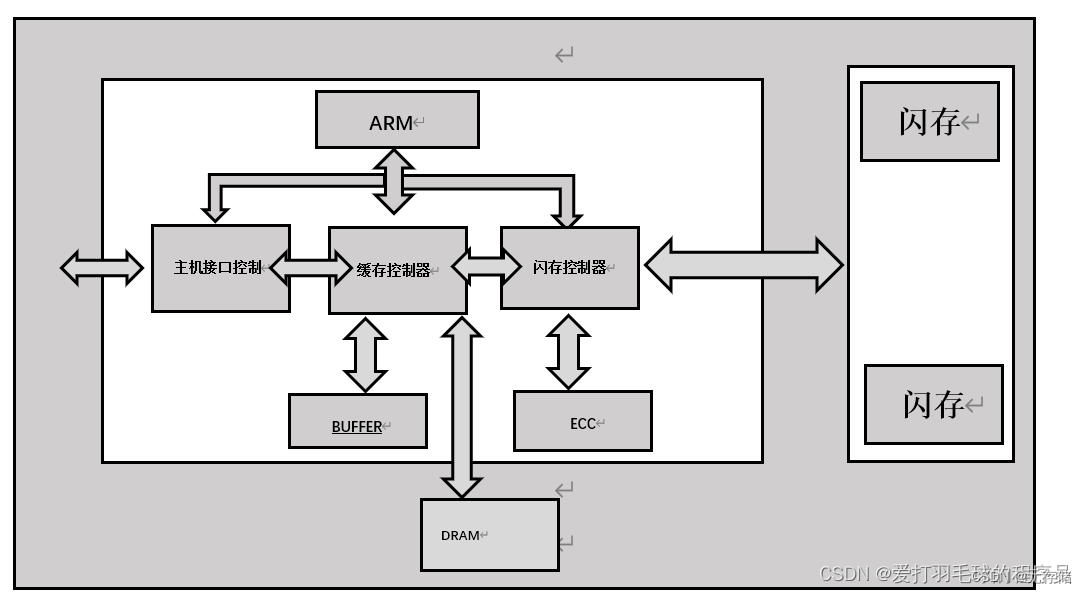
图片来源 [11]
3.1 主控制器
SSD控制器是固态硬盘的主要控制芯片, 负责指挥、运算和协调SSD设备, FTL (Flash Translation Layer) 算法的运行[8]。目前主流的SSD主控架构如下图:
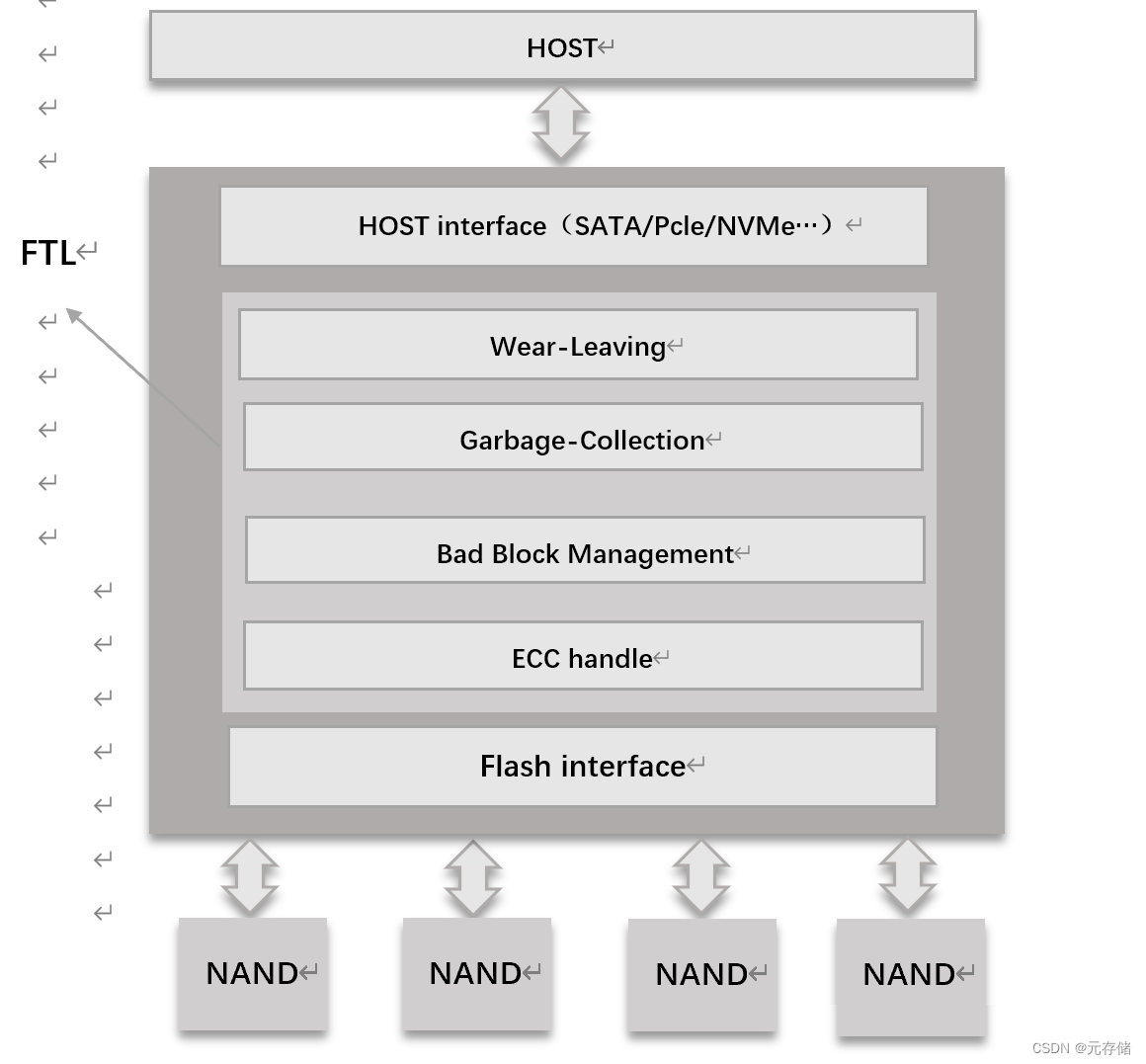
主要有三大部分组成:与Host对接的界面(Host interface, ) 称为前端, 闪存转换层FTL,称为中端以及闪存对接界面(Flash interface),称为后端。
每个 SSD 都有一个控制器(controller)将存储单元连接到电脑,主控器可以通过若干个通道(channel)并行操作多块FLASH颗粒,类似RAID0,大大提高底层的带宽。控制器是一个执行固件(firmware)代码的嵌入式处理器。主要功能如下:
Read
Write
Trim
错误检查和纠正(ECC)
Address Translation——映射管理
Garbage Collection——垃圾回收
Wear Leveling——磨损平衡
Power off Recovery —— 掉电恢复
Error Handler——坏块管理
SLC Cache
Read Disturb & Data Retention
Over Privision——预留空间
Latecncy 平滑管理
WAF写入放大
缓存控制
加密
压缩
重复数据去冗
HMB(host memory buffer) 管理
固件升级
Self Test
3.2 存储单元
尽管有某些厂商推出了基于更高速的 DRAM 内存的产品,但 NAND 闪存依然最常见,占据着绝对主导地位。一般采用 TLC(multi-level cell) 甚至 QLC(Triple Level Cell) 闪存,其特点是容量大、速度慢、可靠性低、存取次数低、价格也低。高端产品一般采用 SLC(single-level cell) 闪存,其特点是技术成熟、容量小、速度快、可靠性高、存取次数高、价格也高。但是事实上,取决于不同产品的内部架构设计,速度和可靠性的差别也可以通过各种技术加以弥补甚至反转。
闪存内部结构
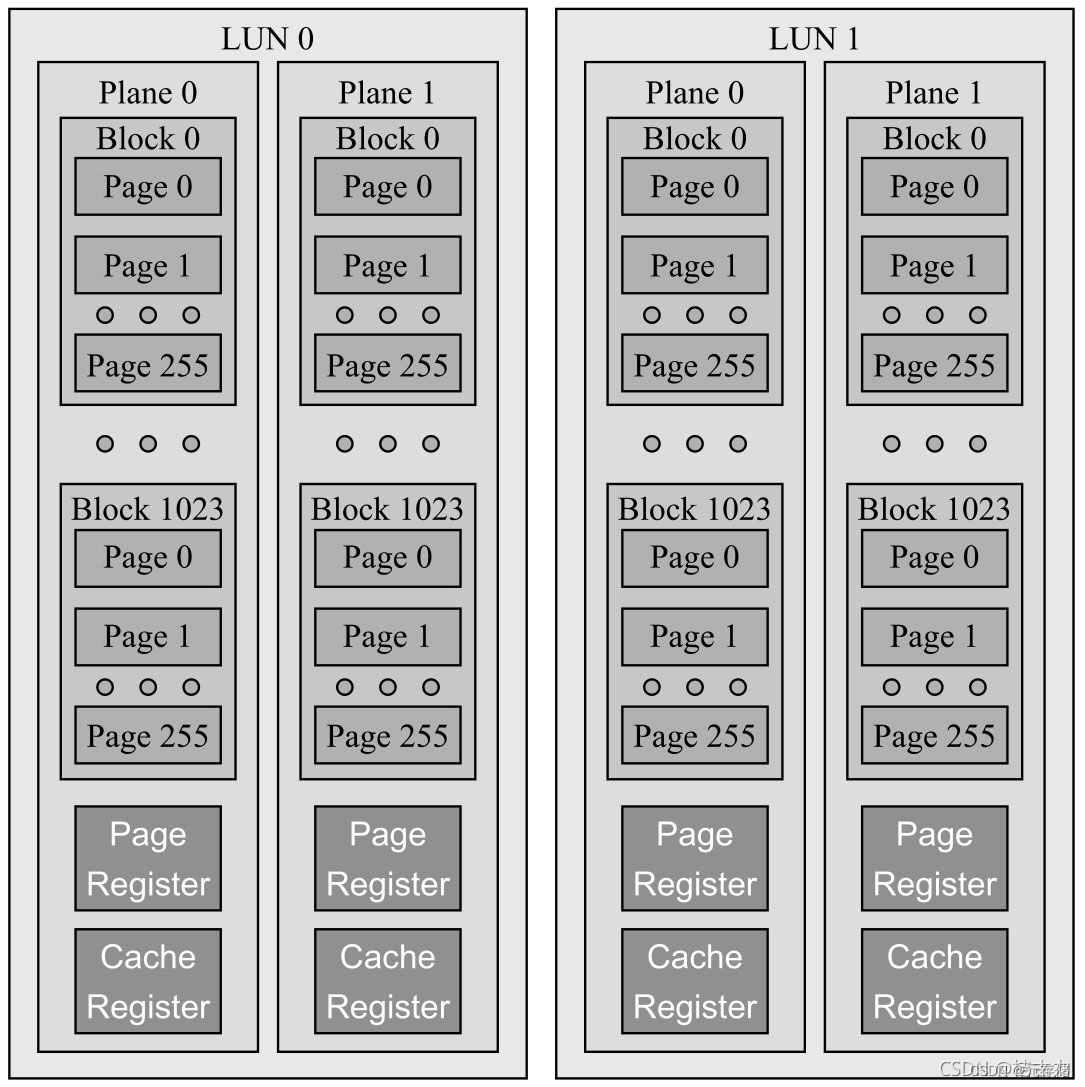
一个Die又可以分为多个Plane,而每个Plane又包含多个多个Block,每个Block又分为多个Page。以Samsung 4GB Flash为例,共享8位I/0数据总线和一些控制信号线。每个Die由4个Plane组成,每个Plane包含2048个Block,每个Block又包含64个4KB大小的Page。我们顺序写入4个逻辑页,分别写到不同的plane上,这样写的目的是增加底层的并行性,提升写入性能。
参考:[121114961]
3.3 闪存的分类
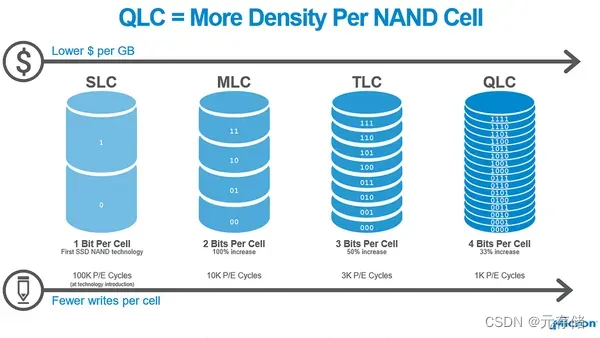
NAND FLASH 从 SLC -> MLC -> TLC -> QLC,每个单元存储的比特数增加,这样晶圆的存储密度会成倍提高,但对应的整卡可写入/擦除次数(P/E Cycle) 也降低(意味着寿命也越短),读写性能会越差。最重要的单位GB的成本会更低,芯片的成本是和面积直接相关的。面积越小,一个晶圆切出的Die(片)数目就更多,单Die的成本就降下来了。[12]
各大原厂孜孜不倦地提高每个单元的比特数,目的就是为了减少成本,成本才是王道!
4. Host访问SSD的原理
固态硬盘的存储器件采用的是闪存,具有以下几个特点:
(1)读写基本单位是以页(Page)为单位,擦除是以块(Block)为单位。
(2)每个物理块,必须先擦除,才能够写入数据。
基于这些问题,在固态硬盘中引入了闪存转换层映射表。
Host是通过LBA(Logical BlockAddress,逻辑地址块)访问SSD的,每个LBA代表着一个Sector(一般为512B大小),文件系统一般以4KB为单位访问SSD,我们把Host访问SSD的基本单元叫用户页(Host Page)。而在SSD内部,SSD主控与Flash之间是Flash Page为基本单元访问Flash的,我们称Flash Page为物理页(Physical Page)。Host每写入一个Host Page, SSD主控会找一个Physical Page把Host数据写入,SSD内部同时记录了这样一条映射(Map)。有了这样一个映射关系后,下次Host需要读某个Host Page 时,SSD就知道从Flash的哪个位置把数据读取上来。
SSD内部维护了一张映射表(Map Table),Host每写入一个Host Page,就会产生一个新的映射关系,这个映射关系会加入(第一次写)或者更改(覆盖写)Map Table;当读取某个Host Page时, SSD首先查找Map Table中该Host Page对应的Physical Page,然后再访问Flash读取相应的Host数据。
大多数SSD,我们可以看到上面都有板载DRAM,其主要作用就是用来存储这张映射表。也有例外,比如基于Sandforce主控的SSD,它并不支持板载DRAM,那么它的映射表存在哪里呢?SSD工作时,它的绝大部分映射是存储在FLASH里面,还有一部分存储在片上RAM上。当Host需要读取一笔数据时,对有板载DRAM的SSD来说,只要查找DRAM当中的映射表,获取到物理地址后访问Flash从而得到Host数据.这期间只需要访问一次FlashH;而对Sandforce的SSD来说,它首先看看该Host Page对应的映射关系是否在RAM内,如果在,那好办,直接根据映射关系读取FLASH;如果该映射关系不在RAM内,那么它首先需要把映射关系从FLASH里面读取出来,然后再根据这个映射关系读取Host数据,这就意味着相比有DRAM的SSD,它需要读取两次FLASH才能把HOST数据读取出来,底层有效带宽减半。对HOST随机读来说,由于片上RAM有限,映射关系Cache命中(映射关系在片上RAM)的概率很小,所以对它来说,基本每次读都需要访问两次FLASH,所以我们可以看到基于Sandforce主控的SSD随机读取性能是不太理想的。
5. SSD相关概念和技术
5.1 多Plane操作
多 Plane NAND 是一种能够有效提升性能的设计。例如,一个晶片内部分成了4个 Plane,想象我们在操作时,也可以进行多Plane并行操作来提升性能,
不同的Die 是独立工作的,可以并行操作。
多个SSD Channel 可以并行操作。
5.2 多Die交错操作
交错操作可以成倍提升NAND的传输率,因为NAND颗粒封装时候可能有多Die、多Plane(每个plane都有4KB寄存器),不同Die操作时候可以交叉操作(第一个plane接到指令后,在操作的同时第二个指令已经发送给了第二个Die,以此类推),达到接近双倍甚至4倍的传输能力(看闪存颗粒支持度)。
5.3 FTL
操作系统通常将硬盘理解为一连串 512B 大小的扇区[注意:操作系统对磁盘进行一次读或写的最小单位并不是扇区,而是文件系统的块,一般为 512B/1KB/4KB 之一(也可能更大),其具体大小在格式化时设定],但是闪存的读写单位是 4KB 或 8KB 大小的页,而且闪存的擦除(又叫编程)操作是按照 128 或 256 页大小的块来操作的。更要命的是写入数据前必须要先擦除整个块,而不能直接覆盖。这完全不符合现有的、针对传统硬盘设计的文件系统的操作方式,很明显,我们需要更高级、专门针对 SSD 设计的文件系统来适应这种操作方式。但遗憾的是,目前还没有这样的文件系统。为了兼容现有的文件系统,就出现了 FTL(闪存转换层),它位于文件系统和物理介质之间,把闪存的操作习惯虚拟成以传统硬盘的 512B 扇区进行操作。这样,操作系统就可以按照传统的扇区方式操作,而不用担心之前说的擦除/读/写问题。一切逻辑到物理的转换,全部由 FTL 层包了。
FTL 算法,本质上就是一种逻辑到物理的映射,因此,当文件系统发送指令说要写入或者更新一个特定的逻辑扇区时,FTL 实际上写入了另一个空闲物理页,并更新映射表,再把这个页上包含的旧数据标记为无效(更新后的数据已经写入新地址了,旧地址的数据自然就无效了)。
5.4 磨损平衡(Wear leveling)
简单说来,磨损平衡是确保闪存的每个块被写入的次数相等的一种机制。
如果系统中的所有块都定期更新,这就没有问题,因为当页面被标记为无效然后被回收时,磨损均衡几乎会自然发生。通常情况下,在 NAND 块里的数据更新频度是不同的。具体来说:如果我们有一些冷块,即数据永远不会改变的位置,那么我们必须采取措施手动重新定位该数据,否则这些块将永远不会磨损……磨损均衡需要将数据搬移到新的块,这意味着我们也在增加写入工作量,这最终意味着增加磨损。
因此,简而言之,我们对均匀磨损均衡的要求越高,我们造成的磨损就越多。但不够积极可能会导致热点和冷点,因为磨损变得更加不均匀。一如既往,这是一个找到正确平衡的问题。或者,如果您愿意,找到写入平衡。
磨损平衡算法分静态和动态。动态磨损算法是基本的磨损算法:只有用户在使用中更新的文件占用的物理页地址被磨损平衡了。而静态磨损算法是更高级的磨损算法:在动态磨损算法的基础上,增加了对于那些不常更新的文件占用的物理地址进行磨损平衡,这才算是真正的全盘磨损平衡。简单点说来,动态算法就是每次都挑最年轻的 NAND 块来用,老的 NAND 块尽量不用。静态算法就是把长期没有修改的老数据从一个年轻 NAND 块里面搬出来,重新找个最老的 NAND 块放着,这样年轻的 NAND 块就能再度进入经常使用区。
尽管磨损均衡的目的是避免数据重复在某个空间写入,以保证各个存储区域内磨损程度基本一致,从而达到延长固态硬盘的目的。但是,它对固态硬盘的性能有不利影响,并且会增加磨损。
5.5 垃圾回收(Garbagecollection)
当整个SSD写满后,从用户角度来看,如果想写入新的数据,则必须删除一些数据,然后腾出空间再写。用户在删除和写入数据的过程中,会导致一些Block里面的数据变无效或者变老。Block中的数据变老或者无效,是指没有任何映射关系指向它们,用户不会访问到这些FLASH空间,它们被新的映射关系所取代。比如有一个Host Page A,开始它存储在FLASH空间的X,映射关系为A->X。后来,HOST重写了该Host Page,由于FLASH不能覆盖写,SSD内部必须寻找一个没有写过的位置写入新的数据,假设为Y,这个时候新的映射关系建立:A->Y,之前的映射关系解除,位置X上的数据变老失效,我们把这些数据叫垃圾数据。随着HOST的持续写入,FLASH存储空间慢慢变小,直到耗尽。如果不及时清除这些垃圾数据,HOST就无法写入。SSD内部都有垃圾回收机制,它的基本原理是把几个Block中的有效数据(非垃圾数据)集中搬到一个新的Block上面去,然后再把这几个Block擦除掉,这样就产生新的可用Block了.
另一方面,由前面的磨损平衡机制知道,磨损平衡的执行需要有“空白块”来写入更新后的数据。当可以直接写入数据的“备用空白块”数量低于一个阀值后,SSD主控制器就会把那些包含无效数据的块里的所有有效数据合并起来写到新的“空白块”中,然后擦除这个块以增加“备用空白块”的数量。
有三种垃圾回收策略:
闲置垃圾回收:很明显在进行垃圾回收时候会消耗大量的主控处理能力和带宽造成处理用户请求的性能下降,SSD 主控制器可以设置在系统闲置时候做“预先”垃圾回收(提前做垃圾回收操作),保证一定数量的"备用空白块",让 SSD 在运行时候能够保持较高的性能。闲置垃圾回收的缺点是会增加额外的"写入放大",因为你刚刚垃圾回收的"有效数据",也许马上就会被更新后的数据替代而变成"无效数据",这样就造成之前的垃圾回收做无用功了。
被动垃圾回收:每个 SSD 都支持的技术,但是对主控制器的性能提出了很高的要求,适合在服务器里用到,SandForce 的主控就属这类。在垃圾回收操作消耗带宽和处理能力的同时处理用户操作数据,如果没有足够强劲的主控制器性能则会造成明显的速度下降。这就是为啥很多 SSD 在全盘写满一次后会出现性能下降的道理,因为要想继续写入数据就必须要边垃圾回收边做写入。
手动垃圾回收:用户自己手动选择合适的时机运行垃圾回收软件,执行垃圾回收操作。
可以想象,如果系统经常进行垃圾回收处理,频繁的将一些区块进行擦除操作,那么 SSD 的寿命反而也会进一步下降。由此把握这个垃圾回收的频繁程度,同时确保 SSD 中的闪存芯片拥有更高的使用寿命,这确实需要找到一个完美的平衡点。所以,SSD 必须要支持 Trim 技术,不然 GC 就显不出他的优势了。
5.6 Trim
Trim 是一个 ATA 指令,当操作系统删除文件或格式化的时候,由操作系统同时把这个文件地址发送给 SSD 的主控制器,让主控制器知道这个地址的数据无效了。当你删除一个文件的时候,文件系统其实并不会真正去删除它,而只是把这个文件地址标记为“已删除”,可以被再次使用,这意味着这个文件占的地址已经是“无效”的了。这就会带来一个问题,硬盘并不知道操作系统把这个地址标记为“已删除”了,机械盘的话无所谓,因为可以直接在这个地址上重新覆盖写入,但是到了 SSD 上问题就来了。NAND 需要先擦除才能再次写入数据,要得到空闲的 NAND 空间,SSD 必须复制所有的有效页到新的空闲块里,并擦除旧块(垃圾回收)。如果没有 Trim 指令,意味着 SSD 主控制器不知道这个页是“无效”的,除非再次被操作系统要求覆盖上去。
Trim 只是条指令,让操作系统告诉 SSD 主控制器这个页已经“无效”了。Trim 会减少写入放大,因为主控制器不需要复制“无效”的页(没 Trim 就是“有效”的)到空白块里,这同时代表复制的“有效”页变少了,垃圾回收的效率和 SSD 性能也提升了。Trim 能大量减少伪有效页的数量,它能大大提升垃圾回收的效率。目前,支持 Trim 需要三个要素,
(1)系统:操作系统必须会发送 Trim 指令,Win7, Win2008R2 , Linux-2.6.33 以上。
(2)固件: SSD 的厂商在固件里要放有 Trim 算法,也就是 SSD 的主控制器必须认识 Trim 指令。
(3)驱动: 控制器驱动必须要支持 Trim 指令的传输,也就是能够将 Trim 指令传输到 SSD 控制器。MS 的驱动,Intel 的 AHCI 驱动目前支持。别的要看之后的更新了。
目前,RAID 阵列里的盘明确不支持 TRIM,不过 RAID 阵列支持 GC。
5.7 预留空间(Over-provisioning)
预留空间是指用户不可操作的容量,为实际物理闪存容量减去用户可用容量。这块区域一般被用来做优化,包括磨损均衡,GC和坏块映射。
第一层为固定的7.37%,这个数字是如何得出的哪?我们知道机械硬盘和 SSD 的厂商容量是这样算的,1GB 是1,000,000,000字节(10的9 次方),但是闪存的实际容量是每 GB=1,073,741,824,(2的30次方) ,两者相差7.37%。所以说假设1块 128GB 的 SSD,用户得到的容量是 128,000,000,000 字节,多出来的那个 7.37% 就被主控固件用做OP了。
第二层来自制造商的设置,通常为 0%,7%,28% 等,打个比方,对于 128G 颗粒的 SandForce 主控 SSD,市场上会有 120G 和 100G 两种型号卖,这个取决于厂商的固件设置,这个容量不包括之前的第一层 7.37% 。
第三层是用户在日常使用中可以分配的预留空间,用户可以在分区的时候,不分到完全的 SSD 容量来达到这个目的。不过需要注意的是,需要先做安全擦除(Secure Erase),以保证此空间确实没有被使用过。
预留空间的具体作用:
(1)垃圾回收:就是要把数据搬来搬去,那就需要始终有空的地方来放搬的数据。空的越多,搬的越快,多多益善,有些SSD为了更快,还会再拿走一些用户的容量。
(2)映射表等内部数据保存:SSD里面有一个巨大的映射表,把用户地址转成物理Flash颗粒地址,需要保存,以防掉电丢失。这个大概是千分之三的容量。
(3)坏块替换:写得多了,坏块会逐渐增加,需要用好的顶替。随着Flash的制程从32nm不断变小,变到现在的14nm,Flash质量越来越差,坏块越来越多,这部分可能会到3%甚至更多。
5.8 写入放大(Write amplification)
因为闪存必须先擦除(也叫编程)才能写入,在执行这些操作的时候,移动或覆盖用户数据和元数据(metadata)不止一次。这些额外的操作,不但增加了写入数据量,减少了SSD的使用寿命,而且还吃光了闪存的带宽,间接地影响了随机写入性能。这种效应就叫写入放大(Write amplification)。一个主控的好坏主要体现在写入放大上。
比如我要写入一个 4KB 的数据,最坏的情况是,一个块里已经没有干净空间了,但是有无效数据可以擦除,所以主控就把所有的数据读到缓存,擦除块,从缓存里更新整个块的数据,再把新数据写回去。这个操作带来的写入放大就是:我实际写4K的数据,造成了整个块(1024KB)的写入操作,那就是256倍放大。同时带来了原本只需要简单的写4KB的操作变成闪存读取(1024KB),缓存改(4KB),闪存擦(1024KB),闪存写(1024KB),造成了延迟大大增加,速度急剧下降也就是自然的事了。所以,写入放大是影响 SSD 随机写入性能和寿命的关键因素。
用100%随机4KB来写入 SSD,对于目前的大多数 SSD 主控而言,在最糟糕的情况下,写入放大的实际值可能会达到或超过20倍。当然,用户也可以设置一定的预留空间来减少写入放大,假设你有个 128G 的 SSD,你只分了 64G 的区使用,那么最坏情况下的写入放大就能减少约3倍。
许多因素影响 SSD 的写入放大。下面列出了主要因素,以及它们如何影响写入放大。
(1)垃圾回收虽然增加了写入放大(被动垃圾回收不影响,闲置垃圾回收影响),但是速度有提升。
(2)预留空间可以减少写入放大,预留空间越大,写入放大越低。
(3)开启 TRIM 指令后可以减少写入放大
(4)用户使用中没有用到的空间越大,写入放大越低(需要有 Trim 支持)。
(5)持续写入可以减少写入放大。理论上来说,持续写入的写入放大为1,但是某些因素还是会影响这个数值。
(6)随机写入将会大大提升写入放大,因为会写入很多非连续的 LBA。
(7)磨损平衡机制直接提高了写入放大
5.9 ECC
ECC的全称是Error Checking and Correction,是一种用于Nand的差错检测和修正算法。由于NAND Flash的工艺不能保证NAND在其生命周期中保持性能的可靠,因此,在NAND的生产中及使用过程中会产生坏块。为了检测数据的可靠性,在应用NAND Flash的系统中一般都会采用一定的坏区管理机制,而管理坏区的前提是能比较可靠的进行坏区检测。如果操作时序和电路稳定性不存在问题的话,NAND Flash出错的时候一般不会造成整个Block或是Page不能读取或是全部出错,而是整个Page中只有一个或几个bit出错,这时候ECC就能发挥作用了。不同颗粒有不同的基本ECC要求,不同主控制器支持的ECC能力也不同,理论上说主控越强ECC能力越强。
参考:
[1] SSD(固态硬盘)简介 http://www.jinbuguo.com/storage/ssd_intro.html
[2] SSD背后的秘密:SSD基本工作原理 http://www.ssdfans.com/?p=131
[3] 固态硬盘(SSD)原理及相关介绍 https://blog.csdn.net/cighao/article/details/48135137
[4] [SSD固态硬盘技术 15] FTL映射表的神秘面纱 https://blog.csdn.net/vagrant0407/article/details/128983639
[5] [SSD固态硬盘技术 9] FTL详解 https://blog.csdn.net/vagrant0407/article/details/128978780
[6] 王发宽.基于NADA闪存的混合固态硬盘设计研究[D].杭州:杭州电子科技大学,2017.
[7] SSD Fans.深入浅出SSD[M].机械工业出版社,2018.
[8] 李想.基于软件架构的固态硬盘FTL设计[D].武汉:华中科技大学,2015.
[9] 赵鹏,白石.基于随机游走的大容量固态硬盘磨损均衡算法[J].计算机学报,2012,35(5):972-978.
[10] 周懿,戴紫彬,面向Nand Flash自适应纠错码方案研究与设计[J].计算机工程与设计,2017,38(6):1681-1685.
[11] 固态硬盘存储技术的分析https://blog.csdn.net/weixin_46637351/article/details/126013567
[12] NOR Flash 和 NAND Flash 闪存详解https://blog.csdn.net/vagrant0407/article/details/127813278

![[LeetCode 1138]字母板上的路径](https://img-blog.csdnimg.cn/107e2cfdb4ac4bbcab58938efa82fe10.png)







![[个人笔记] Zabbix实现自定义脚本监控Agent端](https://img-blog.csdnimg.cn/ba9a32e68079454889251c63a0169816.png)