上周投了一些简历,约了8-9家面试,其中完成了3家的第一轮面试,由于面试的是Java 的实习生,感觉问的题目都比较基础,不过有些问题回答的不是很好,在这里对回答的不太好的题目做一下总结和复盘。
目录
一、后端开发Java面试复盘
1.1、23种设计模式
1.2、数据库(MySQL)的索引失效情况
1.3、线程池的使用
1.4、ConcurrentHashMap的使用及底层原理
1.5、Spring的传递依赖问题
1.6、MySQL事务的四种隔离级别
一、后端开发Java面试复盘
1.1、23种设计模式
设计模式:就是代码设计经验的总结。使用设计模式可以提高代码的可靠性和可重用性。
设计模式共有23中,整体分为3大类,如下:
创建型模式,共五种:工厂方法模式、抽象工厂模式、单例模式、建造者模式、原型模式
结构型模式,共七种:适配器模式、装饰器模式、代理模式、外观模式、桥接模式、组合模式、享元模式
行为型模式,共十一种:策略模式、模板方法模式、观察者模式、迭代子模式、责任链模式、命令模式、备忘录模式、状态模式、访问者模式、中介者模式、解释器模式
设计模型有6大原则,具体如下:
1)开放封闭原则:尽量通过扩展软件实体应对需求的改变,而不是修改原有代码
2)里氏代换原则:使用的基类可以在任何地方使用继承的字类,完美的替换基类
3)依赖倒转原则:即面向接口编程,依赖抽象而不依赖具体
4)接口隔离原则:使用多个隔离的接口替代单个接口,降低耦合
5)迪米特法则:一个类尽量减少对其他类的依赖
6)单一职责:一个方法尽量只负责一件事
单例模式,分为饿汉模式和懒汉模式,都是每个类中只创建一个实例,并提供全局访问点来访问这个实例。饿汉模型是线程安全的,懒汉模式线程不安全,需要使用双重检测锁保证线程安全,具体的Java代码实现如下:
/**
* 单例模式:确保每个类只有一个实例,并提供全局访问点来访问这个实例
*/
//饿汉模式:线程安全
class Singleton1 {
private static Singleton1 instance = new Singleton1() ;
public Singleton1 getInstance(){
return instance ;
}
}
//懒汉模式:线程不安全,需要通过双重检查锁定机制控制
class Singleton2{
private static Singleton2 instance2 = null ;
public Singleton2 getInstance2(){
if(instance2 == null){
instance2 = new Singleton2() ;
}
return instance2 ;
}
}
//使用双重检查锁的方式保重线程安全
class Singleton3{
//使用双重检查进行初始化的实例必须使volatile关键字修饰
private volatile static Singleton3 instance3 = null ;
public Singleton3 getInstance3(){
if(instance3 == null){
synchronized (Singleton3.class){
if(instance3 == null){
instance3 = new Singleton3();
}
}
}
return instance3 ;
}
}
public class Main {
public static void main(String[] args) {
Singleton1 singleton1 = new Singleton1() ;
Singleton1 singleton2 = new Singleton1() ;
Singleton2 singleton21 = new Singleton2() ;
Singleton2 singleton22 = new Singleton2() ;
Singleton1 instance1 = singleton1.getInstance();
Singleton1 instance2 = singleton2.getInstance();
Singleton2 instance21 = singleton21.getInstance2();
Singleton2 instance22 = singleton22.getInstance2();
System.out.println(instance1 == instance2);
System.out.println(instance21 == instance22);
}
}
下面在了解一下工厂模式和代理模式。
工厂模式是一种创建对象的最佳方式,在创建对象时不对客户端暴露创建逻辑,通过使用一个共同的接口来指向新创建的对象,实现创建者和调用者的分离,工厂模式分为简单工厂,工厂方法和抽象工厂。我们熟知的Spring的IOC容器使用工厂模式创建Bean,只需要交给Bean进行管理即可,这样我们在业务层调接口层的方法时候就不需要再new了,可以直接注入。
1)简单工厂模式:也称为静态工厂方法,可以根据参数的不同返回不同类的实例,简单工厂模式专门定义一个类来负责创建其它类的实例,被创建的实例通常都有共同的父类。
首先创建工厂:
public interface Car {
public void run() ;
}定义工厂中的两个产品:
public class Car1 implements Car {
@Override
public void run() {
System.out.println("我是小汽车");
}
}
public class Bus implements Car {
@Override
public void run() {
System.out.println("我是大卡车");
}
}
创建核心工厂类,决定调用工厂中的哪一种方法,具体如下:
/**
* 创建工厂类,在工厂类中决定调用哪一种产品
*/
public class CarFactory {
public static Car createCar(String name){
if("小汽车".equals(name)){
return new Car1() ;
}
if("大卡车".equals(name)){
return new Bus() ;
}
return null ;
}
}
演示创建共创对象,并调用工厂中的产品,具体如下:
/**
* 演示简单工厂
*/
public class Factory1 {
public static void main(String[] args) {
//通过工厂类创建工厂对象
Car car = CarFactory.createCar("小汽车");
Car car1 = CarFactory.createCar("大卡车");
//调用工厂方法
car.run();
car1.run();
}
}
- 优点:简单工厂模式能够根据外界给定的信息,决定究竟应该创建哪个具体类的对象。明确区分了各自的职责和权力,有利于整个软件体系结构的优化。
- 缺点:很明显工厂类集中了所有实例的创建逻辑,容易违反GRASPR的高内聚的责任分配原则。
2)工厂方法模式:也称多态性工厂模式,核心的工厂类不在负责所有产品实例的创建,而是将具体的创建交给具体的子类去做,该核心类成为一个抽象工厂角色,仅仅给出具体工厂字类必须实现的接口,而不涉及具体哪一个产品被实例化。
首先是创建工厂和工厂的两个产品,具体如下:
public interface Car {
public void run() ;
}
public class Car1 implements Car {
@Override
public void run() {
System.out.println("我是小汽车");
}
}
public class Bus implements Car {
@Override
public void run() {
System.out.println("我是大卡车");
}
}然后创建工厂方法调用接口,并创建工厂实例。
/**
* 创建创建工厂方法调用接口,所有工厂产品需要实现该接口,并重写接口方法
*/
public interface Factorys {
Car createFactory() ;
}
public class CarF implements Factorys {
@Override
public Car createFactory() {
return new Car1() ;
}
}
public class BusF implements Factorys {
@Override
public Car createFactory() {
return new Bus() ;
}
}
最后演示工厂方法的实现。
public class Factory2 {
public static void main(String[] args) {
Car car = new CarF().createFactory();
Car car1 = new BusF().createFactory();
car.run() ;
car1.run() ;
}
}
3)抽象工厂模式:即工厂的工厂 ,抽象工厂可以创建具体工厂,由具体工厂来生产具体产品。
首先创建第一个子工厂及其实现类,如下:
/**
* 创建第一个工厂接口及其实现类
*/
public interface A {
void run() ;
}
class CarA implements A{
@Override
public void run() {
System.out.println("奔驰");
}
}
class CarB implements A{
@Override
public void run() {
System.out.println("宝马");
}
}创建第2个子工厂及其实现类,具体如下:
public interface B {
void run() ;
}
class Animal1 implements B{
@Override
public void run() {
System.out.println("狗");
}
}
class Animal implements B{
@Override
public void run() {
System.out.println("猫");
}
}创建一个总工厂及其实现类,由总工厂的实现类决定调用哪个工厂的哪个实例。
/**
* 总工厂,包含创建工厂工厂的接口
*/
public interface TotalFactory {
A createA() ;
B createB() ;
}
/**
* 总工厂的实现类,决定创建哪个工厂的哪个实例
*/
class TotalFactoryImpl implements TotalFactory{
@Override
public A createA() {
return new CarA() ;
}
@Override
public B createB() {
return new Animal1();
}
}
最后演示抽象工厂模式,如下:
public class Test {
public static void main(String[] args) {
A a = new TotalFactoryImpl().createA();
B b = new TotalFactoryImpl().createB();
a.run();
b.run() ;
}
}
下面我们看一下代理模式,我们正常在Spring会接触到代理模式。我们先了解一下什么是代理。
- 通过代理控制对象的访问,可以在这个对象调用方法之前、调用方法之后去处理/添加新的功能。(也就是AOP的实现)
- 代理在原有代码乃至原业务流程都不修改的情况下,直接在业务流程中切入新代码,增加新功能,这也和Spring的(面向切面编程)很相似
我们常见的代理模式分为3种,即静态代理,JDK动态代理和CGLIB动态代理。
静态代理:简单代理模式,是动态代理的理论基础。常见使用在代理模式。
JDK 代理 : 基于接口的动态代理技术·:利用拦截器(必须实现invocationHandler)加上反射机制生成一个代理接口的匿名类,在调用具体方法前调用InvokeHandler来处理,从而实现方法增强。
CGLIB代理:基于父类的动态代理技术:动态生成一个要代理的子类,子类重写要代理的类的所有不是final的方法。在子类中采用方法拦截技术拦截所有的父类方法的调用,顺势织入横切逻辑,对方法进行增强。
1)静态代理
我们首先看如下一个接口类,如何在不改变接口类的基础上,在接口方法中开启和关闭事务,我们可以使用静态代理的方式。
public interface UserDao {
void save() ;
}
class UserDaoImpl implements UserDao{
@Override
public void save() {
System.out.println("添加数据");
}
}
public class Test2 {
public static void main(String[] args) {
UserDaoImpl userDao = new UserDaoImpl();
userDao.save();
}
}
下面是静态代理实现的代码,如下:
public class UserDaoProxy extends UserDaoImpl {
public UserDaoImpl userDao ;
public UserDaoProxy(UserDaoImpl userDao){
this.userDao = userDao ;
}
@Override
public void save() {
System.out.println("开启事务");
super.save();
System.out.println("关闭事务");
}
}
public class Test2 {
public static void main(String[] args) {
UserDaoImpl userDao = new UserDaoImpl();
UserDaoProxy userDaoProxy = new UserDaoProxy(userDao);
userDaoProxy.save();
}
}2)下面看一下JDK动态代理,它是基于接口的动态代理技术,用拦截器(必须实现invocationHandler)加上反射机制生成一个代理接口的匿名类,在调用具体方法前调用InvokeHandler来处理,从而实现方法增强。
首先编写可以重复使用的代理类,如下,可以重复使用,不像静态代理那样每次都要重复编写带泪类,具体如下:
import java.lang.reflect.InvocationHandler;
import java.lang.reflect.Method;
public class InvocationHandlerImpl implements InvocationHandler {
//通过构造方法传入目标对象
public Object target ;
InvocationHandlerImpl(Object target){
this.target = target ;
}
/**
* 动态代理实际运行的代理方法,以反射的方式创建对象
* @param proxy
* @param method
* @param args
* @return
* @throws Throwable
*/
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
System.out.println("开始");
Object invoke = method.invoke(target, args);
System.out.println("结束");
return invoke ;
}
}public class Test2 {
public static void main(String[] args) {
//已构造方法的方式传入被代理的对象
UserDaoImpl userDaoImpl = new UserDaoImpl() ;
InvocationHandlerImpl invocationHandler = new InvocationHandlerImpl(userDaoImpl);
//类加载器
ClassLoader classLoader = userDaoImpl.getClass().getClassLoader();
Class<?>[] interfaces = userDaoImpl.getClass().getInterfaces();
UserDao proxyInstance = (UserDao)Proxy.newProxyInstance(classLoader, interfaces, invocationHandler);
proxyInstance.save();
}
}
3)最后我们看一下CGLIB动态代理,基于父类的动态代理技术:动态生成一个要代理的子类,子类重写要代理的类的所有不是final的方法。在子类中采用方法拦截技术拦截所有的父类方法的调用,顺势织入横切逻辑,对方法进行增强。
简单地说就是实现MethodInterceptor接口并重写intercept()方法实现动态代理。
1.2、数据库(MySQL)的索引失效情况
1)查询条件有or关键字(必须所有查询条件都有索引)
2)模糊查询like以%开头
3)索引列上的条件where部分涉及计算或者函数
4)复合索引缺少左列字段
5)数据库认为全表扫描比索引更高效
1.3、线程池的使用
创建线程常见的几种方法包括继承Thread类并重写run()方法,实现Runnable()接口或实现Collable()等。一般来说,我们使用传统的方法每次创建和销毁线程的开销都比较大,故我们可以使用线程池的方式,减小开销。
使用线程池主要有如下的优势:
1)提高效率,创建好一定数量的线程放在池中,等需要使用的时候就从池中拿一个,这要比需要的时候创建一个线程对象要快的多。
2)减少了创建和销毁线程的次数,每个工作线程都可以被重复利用,可执行多个任务。
3)提升系统响应速度,假如创建线程用的时间为T1,执行任务用的时间为T2,销毁线程用的时间为T3,那么使用线程池就免去了T1和T3的时间。
Executors类(并发包)提供了4种创建线程池方法,这些方法最终都是通过配置ThreadPoolExecutor的不同参数,来达到不同的线程管理效果。
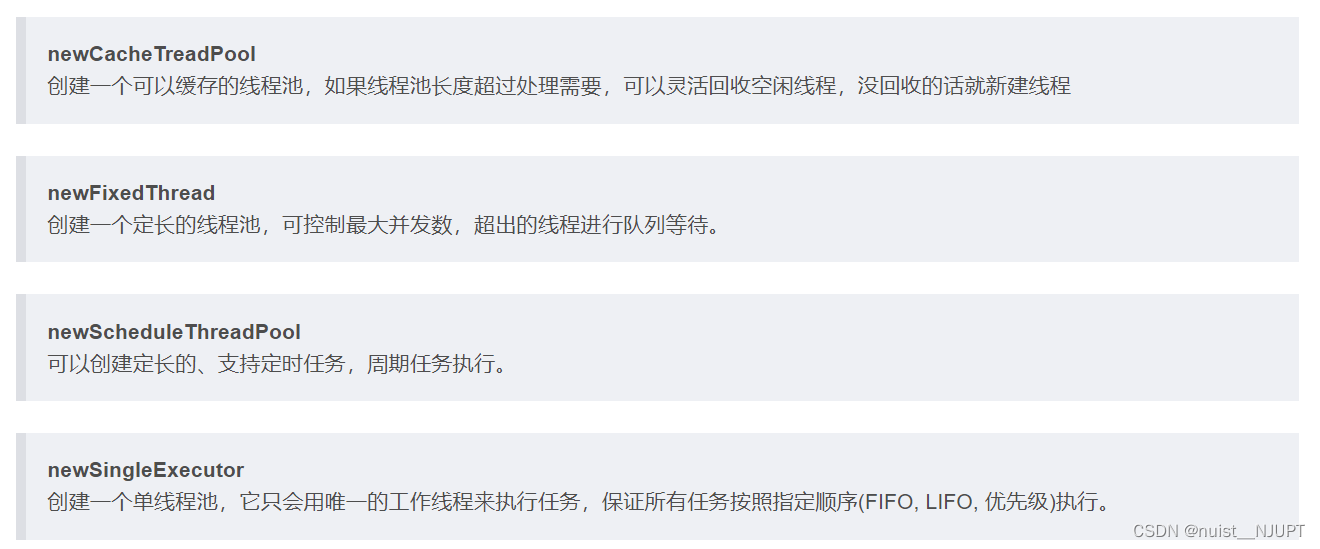
推荐通过 new ThreadPoolExecutor() 的写法创建线程池,这样写线程数量更灵活,开发中多数用这个类创建线程。
该类包含如下核心参数:核心线程数,最大线程数,闲置超时时间,超时时间的单位,线程池中的任务队列,线程工厂,拒绝策略。

最后一个参数为拒绝策略,一半包含四种拒绝策略,如下:
1. AbortPolicy
当任务添加到线程池中被拒绝时,直接丢弃任务,并抛出RejectedExecutionException异常。
2. DiscardPolicy
当任务添加到线程池中被拒绝时,丢弃被拒绝的任务,不抛异常。
3. DiscardOldestPolicy
当任务添加到线程池中被拒绝时,丢弃任务队列中最旧的未处理任务,然后将被拒绝的任务添加到等待队列中。
4. CallerRunsPolicy
被拒绝任务的处理程序,直接在execute方法的调用线程中运行被拒绝的任务。
总结:就是被拒绝的任务,直接在主线程中运行,不再进入线程池。
下面看一个demo,创建线程池,并设置最大线程数目为2,设置拒绝策略为CallerRunsPolicy。
import java.util.concurrent.LinkedBlockingDeque;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit;
public class Test {
public static void main(String[] args) {
// 创建单线程-线程池,任务依次执行
ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(2, 2,
60, TimeUnit.SECONDS,
new LinkedBlockingDeque<>(2),
new ThreadPoolExecutor.CallerRunsPolicy());
for (int i = 0; i < 10; i++) {
//创建任务
Runnable runnable = new Runnable() {
@Override
public void run() {
try {
Thread.sleep(20);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName());
}
};
// 将任务交给线程池管理
threadPoolExecutor.execute(runnable);
}
}
}
1.4、ConcurrentHashMap的使用及底层原理
Map包括HashMap和HashTable。
HashMap性能高,但不是线程安全:
HashMap的性能比较高,但是HashMap不是线程安全的,在并发环境下,可能会形成环状链表导致get操作时,cpu空转,所以,在并发环境中使用HashMap是非常危险的。
HashTable是线程安全的,但性能差:
HashTable和HashMap的实现原理几乎一样,差别:HashTable不允许key和value为null。
HashTable是线程安全的,但是HashTable线程安全的策略实现代价却比较大,get/put所有相关操作都是synchronized的,这相当于给整个哈希表加了一把大锁,多线程访问时候,只要有一个线程访问或操作该对象,那其他线程只能阻塞,这就导致性能比较低。
ConcurrentHashMap是线程安全的且性能高:
JDK1.7版本: 容器中有多把锁,每一把锁锁一段数据,这样在多线程访问时不同段的数据时,就不会存在锁竞争了,这样便可以有效地提高并发效率。
JDK1.8版本:做了2点修改,取消segments字段,直接采用transient volatile HashEntry<K,V>[] table保存数据,采用table数组元素作为锁,从而实现了对每一行数据进行加锁,并发控制使用Synchronized和CAS来操作将原先table数组+单向链表的数据结构,变更为table数组+单向链表+红黑树的结构。
1.5、Spring的传递依赖问题
maven环境存在的依赖冲突问题,可以在pom文件中使用<exlusions>标签排除依赖,主动断开依赖的资源,被排除的资源无需指定版本。
在Spring中解决循环依赖问题,可以使用三级缓存,三级缓存如下:

1.6、MySQL事务的四种隔离级别
MySQL支持四种事务隔离级别,默认的事务隔离级别为repeatable read,Oracle数据库默认的隔离级别是read committed。
四种隔离级别分别为读未提交,读已提交,可重复读, 序列化/串行化。其中,读未提交是最低的隔离级别,序列化隔离级别最高。
1.读未提交(read uncommitted):没有提交就读取到了。
2.读已提交(read committed):已经提交的才能读取。
3.可重复读(repeatable read):事务结束之前。永远读取不到真实数据,提交了也读取不到,读取的永远都是最初的数据,即假象。
4.序列化(serializable):表示事务排队,不能并发,每次读取的都是最真实的数据。
同时运行多个事务,当这些事务访问数据库中相同的数据时,如果没有采取必要的隔离机制,就会导致各种并发问题。
1-脏读:对于两个事务T1和T2,T1读取了已经被T2更新但还没有提交的字段,之后,若T2回滚,则T1读取的数据就是临时且无效的。
2-不可重复读:对于两个事务T1和T2,T1读取了该字段,但是T2更新了该字段,T1再次读取这个字段,值就不同了。
3-幻读:对于两个事务T1和T2,T1从表中读取了一些字段,T2在表中插入了一些新的行,T1再次读取该表发现多几行。
read uncommitted:可以出现脏读,幻读,不可重复读。
read committed:避免脏读,出现幻读和不可重复读。
repeatable read:避免脏读和不可重复读,出现幻读。
serializable:避免脏读,幻读,不可重复读。