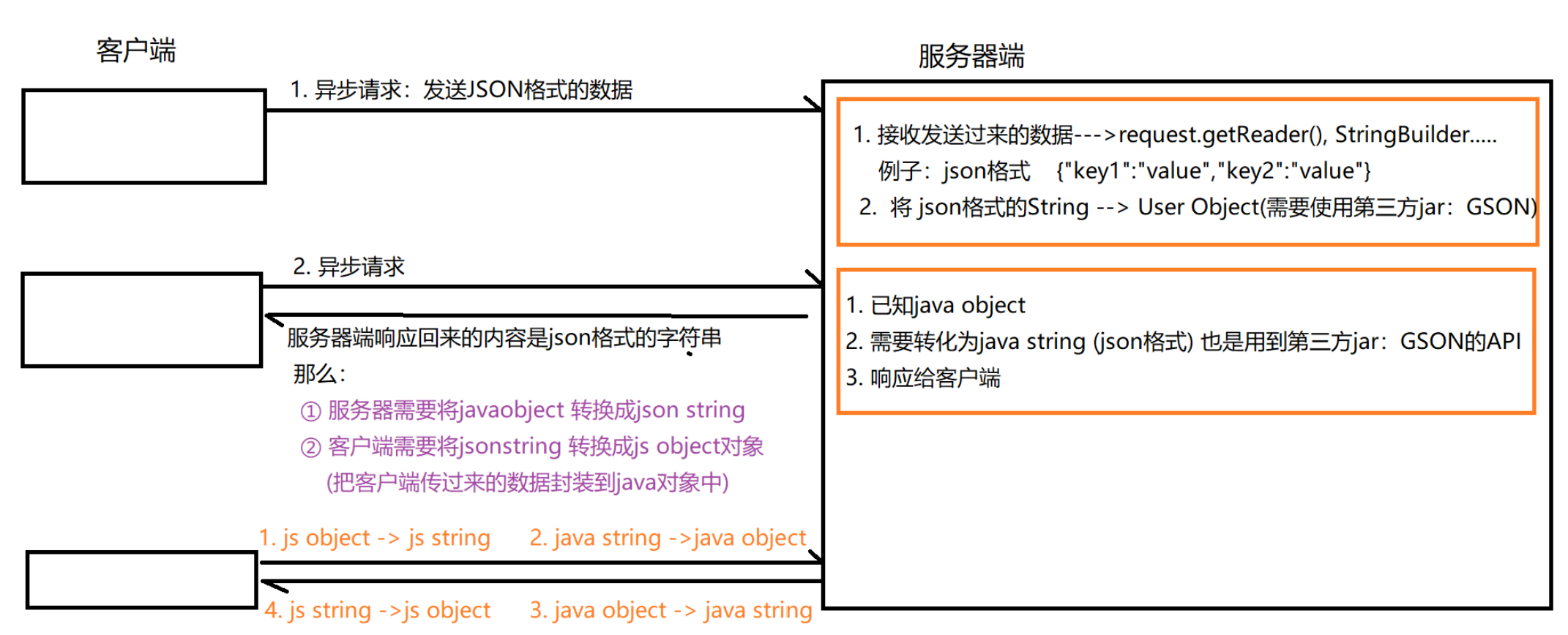
从read_split_data中得到:训练数据集,验证数据集,训练标签,验证标签。的所有的具体详细路径
数据集位置:https://download.csdn.net/download/guoguozgw/87437634
import os
#一种轻量级的数据交换格式,
import json
#文件读/写操作
import pickle
import random
import matplotlib.pyplot as plt
def read_split_data(root:str,val_rate:float = 0.2):
random.seed(0)#保证随机结果可重复出现
assert os.path.exists(root),'dataset root:{} does not exist.'.format(root)
#遍历文件夹,一个文件夹对应一个类别
flower_class = [cla for cla in os.listdir(root) if os.path.isdir(os.path.join(root,cla))]
#排序,保证顺序一致
flower_class.sort()
#生成类别名称以及对应的数字索引,将数据转换为字典的类型。将标签分好类之后,其类别是key,对应的唯一值是value
class_indices = dict((k,v) for v,k in enumerate(flower_class))
#将数据编写成json文件
json_str = json.dumps(class_indices,indent=4)
with open('json_str','w') as json_file:
json_file.write(json_str)
train_images_path = [] #存储训练集的所有图片路径
train_images_label = [] #存储训练集所有图片的标签
val_images_path = [] #存储验证机所有图片的路径
val_images_label = [] #存储验证机所有图片的标签
every_class_num = [] #存储每个类别的样本总数
supported = [".jpg", ".JPG", ".png", ".PNG"] # 支持的文件后缀类型
#遍历每一个文件夹下的文件
for cla in flower_class:
cla_path = os.path.join(root,cla)
#遍历获取supported支持的所有文件路径,得到所有图片的路径地址。针对的是某一个类别。
images = [os.path.join(root,cla,i) for i in os.listdir(cla_path) if os.path.splitext(i)[-1] in supported]
#获取该类别对应的索引,此时对应就是数字了。对应的只是一个数字
image_class = class_indices[cla]
#记录该类别的样本数量
every_class_num.append(len(images))
#按比例随机采样验证样本,按照0.2的比例来作为测试集。
val_path = random.sample(images,k=int(len(images)*val_rate))
for img_path in images:
#如果该路径在采样的验证集样本中则存入验证集。否则的话存入到训练集当中。其中label和image是相互对应的。
if img_path in val_path:
val_images_path.append(img_path)
val_images_label.append(image_class)
else:
train_images_path.append(img_path)
train_images_label.append(image_class)
print('该数据集一共有{}多张图片。'.format(sum(every_class_num)))
print('一共有{}张图片是训练集'.format(len(train_images_path)))
print('一共有{}张图片是验证集'.format(len(val_images_path)))
#输出每一个类别对应的图片个数
for i in every_class_num:
print(i)
plot_image = False
if plot_image:
#绘制每一种类别个数柱状图
plt.bar(range(len(flower_class)),every_class_num,align='center')
#将横坐标0,1,2,3,4替换成相应类别的名称
plt.xticks(range(len(flower_class)),flower_class)
#在柱状图上添加数值标签
for i,v in enumerate(every_class_num):
plt.text(x=i,y=v+5,s=str(v),ha='center')
#设置x坐标
plt.xlabel('image class')
plt.ylabel('number of images')
#
plt.title('flower class distribution')
plt.show()
return train_images_path,train_images_label,val_images_path,val_images_label
if __name__ == '__main__':
root = '../11Flowers_Predict/flower_photos'
read_split_data(root)
最后得到的数据信息分别如此,代码中的路径需要进行更换(替换为自己的路径)。
从写Dataset类
from PIL import Image
import torch
from torch.utils.data import Dataset
class MyDataSet(Dataset):
'''
自定义数据集
'''
def __init__(self,images_path:list,images_classes:list,transform = None):
super(MyDataSet, self).__init__()
self.images_path = images_path
self.images_classes = images_classes
self.transform = transform
def __len__(self):
return len(self.images_path)
def __getitem__(self, item):
img = Image.open(self.images_path[item])
#RGB为彩色图片,L为灰度图片
if img.mode != 'RGB':
#直接在这里终止程序的运行
raise ValueError('image :{} is not RGB mode.'.format(self.images_path[item]))
label = self.images_classes[item]
if self.transform is not None:
img = self.transform(img)
return img , label
对数据集的预处理部分
import os
import torch
from torchvision import transforms
from utils import read_split_data
from my_dataset import MyDataSet
#数据集所在的位置
root = '../11Flowers_Predict/flower_photos'
def main():
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print('using {} device.'.format(device))
#接下来这一行是对数据的读取
train_images_path,train_images_label,val_images_path,val_images_label = read_split_data(root)
#设置transform,compose立main必须是列表
data_transform = {
"train": transforms.Compose([transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])]),
"val": transforms.Compose([transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])}
train_data_set = MyDataSet(images_path=train_images_path,
images_classes=train_images_label,
transform=data_transform['train'])
val_data_set = MyDataSet(images_path=val_images_path,
images_classes=val_images_label,
transform=data_transform['val'])
batch_size = 32
#number of workers
#nw = min([os.cpu_count() , batch_size if batch_size>1 else 0,8])
#print('Using {} dataloader workers'.format(nw))
train_loader = torch.utils.data.DataLoader(train_data_set,
batch_size=batch_size,
shuffle=True,
num_workers = 0
)
val_loader = torch.utils.data.DataLoader(val_data_set,
batch_size=batch_size,
shuffle=True,
num_workers = 0)
for step,data in enumerate(train_loader):
images,labels = data
#print(images.shape)
#print(labels)
#print(labels.shape)
return train_loader,val_loader
if __name__ == '__main__':
main()
开始对数据集进行训练
import torch
from torch import nn
import torchvision
from torchvision import transforms,models
from tqdm import tqdm
from main import *
import time
HP = {
'epochs':25,
'batch_size':32,
'learning_rate':1e-3,
'momentum':0.9,
'test_size':0.05,
'seed':1
}
#创建一个残差网络34层结果,使用预训练参数
model = models.resnet34(pretrained=True)
model.fc = torch.nn.Sequential(
torch.nn.Dropout(0.1),
torch.nn.Linear(model.fc.in_features,5)
)
device = 'cuda' if torch.cuda.is_available() else 'cpu'
if device == 'cuda':
torch.backends.cudnn.benchmark = True
print(f'using {device} device')
#将模型添加到gpu当中
model = model.to(device)
#分类问题使用交叉熵函数损失
criterion = torch.nn.CrossEntropyLoss()
#优化器使用SGD随机梯度下降法
optimizer = torch.optim.SGD(model.parameters(),lr=HP['learning_rate'],momentum=HP['momentum'])
train_loader,val_loader = main()
def train(model,criterion,optimizer,train_loader,val_loader):
#设置总的训练损失和验证损失,以及训练准确度和验证准确度。
total_train_loss = 0
total_val_loss = 0
total_train_accracy = 0
total_val_accracy = 0
model.train()#设置为训练模式
loop = tqdm(enumerate(train_loader),total=len(train_loader))
loop.set_description(f'training')
for step,data in loop:
images,labels = data
#将数据添加到GPU当中
images = images.to(device)
labels = labels.to(device)
output = model(images)
#单个损失
loss = criterion(output,labels)
#计算准确率
accracy = (output.argmax(1)==labels).sum()
#将所有的损失进行相加
total_train_loss += loss.item()
#将所有正确的全部相加起来
total_train_accracy += accracy
#开始进行层数更新
optimizer.zero_grad()
loss.backward()
optimizer.step()
model.eval()
loop_val = tqdm(enumerate(val_loader),total=len(val_loader))
loop_val.set_description(f'valuing')
for step,data in loop_val:
images,labels = data
images = images.to(device)
labels = labels.to(device)
output = model(images)
loss = criterion(output,labels)
accracy_val = (output.argmax(1)==labels).sum()
total_val_loss += loss.item()
total_val_accracy += accracy_val
train_acc = total_train_accracy/(2939)
val_acc = total_val_accracy/(731)
train_loss = total_train_loss/(2939)
val_loss = total_val_loss/(731)
print(f'训练集损失率: {train_loss:.4f} 训练集准确率: {train_acc:.4f}')
print(f'验证集损失率: {val_loss:.4f} 验证集准确率: {val_acc:.4f}')
if __name__ == '__main__':
time_start = time.time()
for i in range(HP['epochs']):
print(f"Epoch {i+1}/{HP['epochs']}")
train(model, criterion, optimizer, train_loader, val_loader)
time_end = time.time()
print(time_end-time_start)
json_str
{
"daisy": 0,
"dandelion": 1,
"roses": 2,
"sunflowers": 3,
"tulips": 4
}
训练结束之后,可以得出来训练出来的结果。
总结部分:
一:针对全部是目录,且目录里面是已经分好类的数据集,且数据没有分成训练集和测试集
1:函数参数设置为:路径,划分的概率
2:设置一定的随机结果
3:判断该路径是否存在,使用assert
4:根据传过来的root,来判断当前路径下所有的文件夹,如果是文件夹将其写入到列表当中
5:同时这个列表也是所有的类别,将该列表进行排序
6:使用enumerate来使其成为字典,其中key对应的是分类,value对应的是数值
7:(可以选择)使用json可以将其写入到文件当中
8:创建训练集图片路径,训练集标签路径,验证集图片路径,验证集标签路径,每个类别的数目,都是列表形式
9:开始对文件进行遍历,然后将其存放到上面的集合当中
10:以根据类别以及root使用join将其连接起来。根据类别来进行循环,然后进行拼接
11:接这这个类别循环的时候,使用随机数来将其划分验证数据集和训练数据集
二:如果数据已经分好训练集和测试集的情况下,如果存在csv的文件情况下,可以使用pandas来进行数据处理
(shuffle函数是sklearn utils里面的类),
(对csv文件读取,主要使用到的是pandas库)
1:对读取到的csv文件可以首先使用head查看前几个数据
2:使用sklearn里面的shuffle方法来进行打乱顺序
3:使用pandas里面的factorize对标签进行数据化显示(把复杂计算分解为基本运算),其返回值为元祖
4:使用unique返回的是列表,将标签封装成列表
5:再将其相互对应封装为字典:key是类别,value是数字
6:使用sklearn中的train_test_split方法来对数据集进行划分,传入参数为(DataFrame,比例)
7:使用value_count来对标签进行计数
对DataSet的重写:
1:主要是实现其中的三个方法,init,getitem,len
2:init主要是接受参数,路径,类别,以及transforms,在这里一定要吧image处理到对应的每一张图片的身上
3:返回的是image格式的图片,以及一个标签数字
部分测试代码
#
import os
def main(root:int,images_class: list,transform = None):
print('root:',root)
print('int:', int)
print('images_class:', images_class)
print('list:', list)
def read_split_data(root:str,val_rate:float = 0.2):
print('root:', root)
print('str:', str)
print('val_rate:', val_rate)
print('float:', float)
root = '../11Flowers_Predict/flower_photos'
#遍历文件夹
'''
os.listdir是展示当前所在层的所有文件
os.isdir判断当前这个文件是否属于文件夹
os.path.join()将两个字符串进行连接中间用/
os.path.splittext()返回的是一个元祖
'''
flowers_classes = [cla for cla in os.listdir(root) if os.path.isdir(os.path.join(root,cla))]
print(flowers_classes)
flowers_classes_copy = flowers_classes.copy()
flowers_classes.sort()
print(os.path.isdir('../11Flowers_Predict/flower_photos'))
print(os.path.join(root,'roses'))
print(flowers_classes)
class_ind = dict((k, v) for v, k in enumerate(flowers_classes))
for v,k in enumerate(flowers_classes):
print('此时标号{},对应的类别是{}.'.format(v,k))
for v,k in class_ind.items():
print(v,k)
import json
json_str = json.dumps(class_ind,indent=2)
print(json_str)
with open('json_str','w') as json_file:
json_file.write(json_str)
AA = os.path.splitext('123.jpg')
print(type(os.path.splitext('123.jpg')))
supported = [".jpg", ".JPG", ".png", ".PNG"] # 支持的文件后缀类型
print(AA[-1] in supported)
list = [1,2,3,4]
#main(root,list)
for cla in flowers_classes:
image_class = class_ind[cla]
print(image_class)
import matplotlib.pyplot as plt
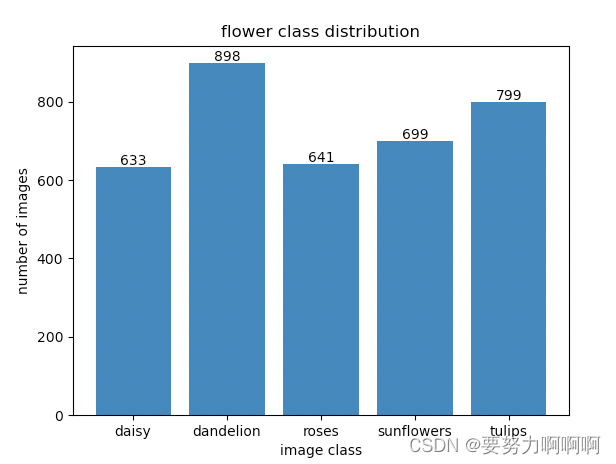
every_class_num = [633,898,641,699,799]
plt.bar(flowers_classes,every_class_num,align='center')
# 这个东西就是用来替换的
#plt.xticks(range(len(flowers_classes)),[10,11,12,13,14])
for i,v in enumerate(every_class_num):
plt.text(x=i,y=v,s=str(v))
plt.show()



![[项目设计]高并发内存池](https://img-blog.csdnimg.cn/557d0057e0334814b2169465941b7076.png)