本文我们学习MapReduce默认分区以及自定义分区实践
当我们要求将统计结果按照条件输出到不同文件(分区),比如按照统计结果将手机归属地不同省份输出到不同文件中(分区)
1.默认Partitioner分区
public class HashPartitioner<K, V> extends Partitioner<K, V> {
public int getPartition(K key, V value,
int numReduceTasks) {
return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks;
}
}
默认分区是根据key的hashCode对ReduceTasks[通过job.setNumReduceTasks(2)赋值]取模得到,用户没法控制key存储到哪个分区
2. 自定义Partitioner分区
- 我们在resources目录下新建phone2.txt
1 13764368888 196.168.0.11 1116 854 200
2 13764368888 196.168.0.11 1136 834 200
3 13764368888 196.168.0.11 1146 824 200
4 13764368888 196.168.0.11 1116 804 200
5 13664368888 196.168.0.11 1116 854 200
6 13864368888 196.168.0.11 1136 834 200
7 13964368888 196.168.0.11 1146 824 200
8 13764368888 196.168.0.11 1116 804 200
- 新建自定义ProvincePartitioner类
public class ProvincePartitioner extends Partitioner<Text, FlowBean> {
@Override
public int getPartition(Text text, FlowBean flowBean, int numPartitions) {
// Text是手机号
String phone = text.toString().substring(0, 3);
// 注意分区号需要连续,从0开始分区
int partition;
if ("136".equals(phone)) {
partition = 0;
} else if ("137".equals(phone)) {
partition = 1;
} else if ("138".equals(phone)) {
partition = 2;
} else if ("139".equals(phone)) {
partition = 3;
} else {
partition = 4;
}
return partition;
}
}
- 新建FlowPartitionerDriver类
public class FlowPartitionerDriver {
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "flowPartitioner");
job.setJarByClass(FlowPartitionerDriver.class);
job.setMapperClass(FlowMapper.class);
job.setCombinerClass(FlowReduce.class);
job.setReducerClass(FlowReduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(FlowBean.class);
// 关联自定义分区类
job.setPartitionerClass(ProvincePartitioner.class);
// 设置ReduceTask任务数
job.setNumReduceTasks(5);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
- 传参运行
E:\Java\blogCode\hadoop\src\main\resources\phone2.txt E:\Java\blogCode\hadoop\src\main\resources\phone_ret2.txt
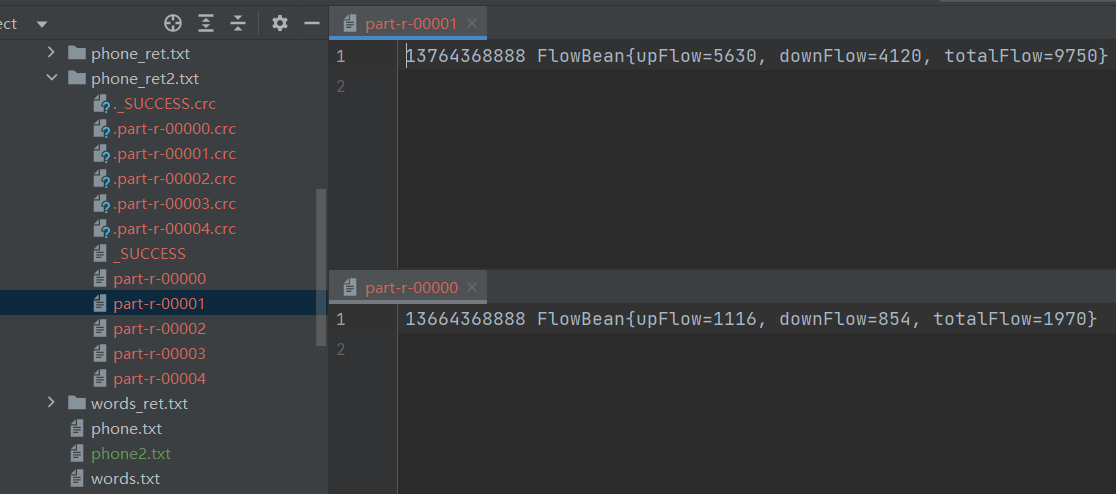
由图可知,产生了5个分区,实现了手机归属地不同省份输出到不同文件中
3.分区总结
- 如果ReduceTask数量>getPartition结果数,则会多产生空的part-r-000xx文件
- 如果1<ReduceTask数量<getPartition结果数,则有一部分数据无处写,会Exception
- 如果ReduceTask数量=1,则不管MapTask输出多少分区文件,最终结果都会交给一个ReduceTask,只会产生一个文件part-r-00000
- 分区号必须从零开始,逐一累加
欢迎关注公众号算法小生与我沟通交流