类似pandas里面的groupby函数,SQL里面的GROUP BY子句也是可以达到分组聚合的效果。
常用的聚合函数有COUNT(),SUM(),AVG(),MAX(),MIN(),其用法看名字都看的出来,下面一一介绍
聚合函数
COUNT()计数
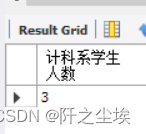
统计student表中计科系学生的人数。
SELECT COUNT(*) AS 计科系学生人数
FROM student WHERE institute='计算机学院';
COUNT函数的参数都是星号(*),除了星号可以当COUNT函数的参数以外,字段名也可以当函数参数。当字段名作为函数参数时,如果该字段中没有NULL值,则与星号作函数参数的效果相同。而如果字段中含有NULL值,加上DISTINCT函数,则统计个数时会排除含有NULL值的记录,请看下面的例子。
从foreign_teacher表中,统计外籍教师的所有人数、拥有电话的人数和拥有email的教师人数。
SELECT COUNT(*) AS 外籍教师总人数, COUNT(DISTINCT tel) AS 有电话的人数,
COUNT(DISTINCT email) AS 有email的人数 FROM foreign_teacher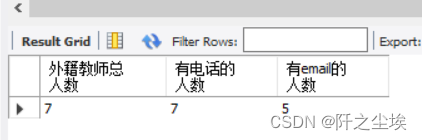
统计外籍教师中,没有email的教师人数。
分析:统计没有email的教师人数,其实就是在统计该字段上有几个NULL值。下面是具体的解决办法。
SELECT COUNT(*) AS 没有email的人数
FROM foreign_teacher
WHERE email IS NULL; 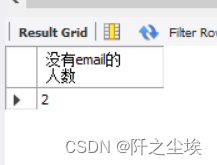
使用SUM函数求某字段的和
在course表中,求所有课程的总学分。
求所有课程的总学分,就是把学分字段的所有数值累加起来,下面的语句完成了这一任务。
SELECT SUM(credit) AS 总学分 FROM course; 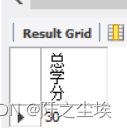
SUM函数不仅可以累加所有记录值以外,同COUNT函数一样,也可以只将满足条件的记录值累加起来,请看下面的例子。
在course表中,求课程类型为“必修”的课程的学分总和。
SELECT SUM(credit) AS 必修课的学分总和
FROM course WHERE type='必修' ; 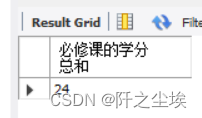
从score表中,求“计算机基础”课的考试成绩总和。
分析:因为score表中只有课号,而并没有课名,因此,首先,需要从course表中,查找“计算机基础”课的课号,其次,才能从score表中,通过“计算机基础”课的课号,查找满足条件的记录,最后,将考试成绩通过SUM函数加起来得到总和。所以,下面使用了两条SELECT语句。
SELECT ID AS 计算机基础课号
FROM course WHERE course='计算机基础'; 
运行上面的查询语句后得到结果中显示了“计算机基础”课的课号为“004”,根据这一结果,从Score表中,求“计算机基础”课的考试成绩总和。
SELECT SUM(result1) AS 计算机基础总成绩 FROM score WHERE c_id='004';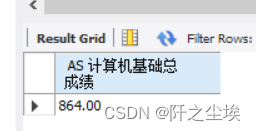
使用AVG函数求某字段的平均值
数据库操作中,除了求字段和以外,还经常需要求字段的平均值。AVG函数用于求字段的平均值,其用法和SUM函数的用法基本相同。AVG函数的参数也必须是数值类型的字段名或者结果为数值的表达式。
从score表中,求“计算机基础”课的考试成绩的平均分。
SELECT AVG(result1) AS 计算机基础平均成绩 FROM score
WHERE c_id IN (SELECT ID FROM course WHERE course="计算机基础");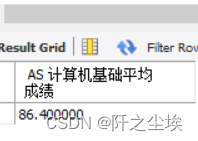
使用MAX、MIN函数求最大、最小值
MAX和MIN函数用于求指定字段中的最大值和最小值,例如,想要知道student表中,最早(最晚)的出生日期是多少时便可以用到MAX(MIN)函数。MAX和MIN两个函数可以用于文本类型、数值类型和日期时间类型的字段上。这两个函数都忽略含有NULL值的记录。下面通过例题学习这两个函数的用法。
从score表中,求“计算机基础”课的考试成绩的最高分和最低分。
SELECT MAX(result1) AS 最高分数, MIN(result1) AS 最低分数 FROM score
WHERE c_id IN (SELECT ID FROM course WHERE course='计算机基础');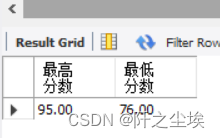
求年龄最小(出生日期最大)的学生的姓名,出生日期和所属院系。
SELECT name AS 姓名, birthday AS 出生日期, institute AS 所属院系
FROM student WHERE birthday IN (SELECT MAX(birthday) FROM student);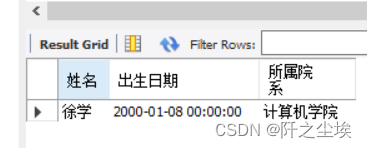
注意:WHERE子句后的条件表达式不能写成如下形式。
birthday= MAX(birthday),原因是,聚合函数不能出现在WHERE子句中。
统计汇总相异值(不同值)记录
数据库操作中,有时需要统计相异值记录,例如,统计Student表中的学生来自几个地区等。这时可以使用DISTINCT关键字完成统计任务。
统计student表中的学生来自几个地区。
分析:本例只要统计出不同来源地的个数即可。由于student表中的来源地字段中有重复值出现,因此,必须将重复值去掉,然后才能使用COUNT函数统计个数。
SELECT COUNT(DISTINCT(origin)) AS 地区个数 FROM student;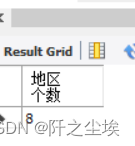
除COUNT函数可以使用DISTINCT以外,上面介绍的其它4个聚合函数中也能使用DISTINCT关键字。
SUM(),AVG(),MAX(),MIN()都是会忽略NULL值的。
数据分组
开始介绍groupby语句。
groupby用来查看一个分类变量有多少类会很快捷。
将student表中的数据,按所属院系字段分组。
SELECT institute FROM student GROUP BY institute;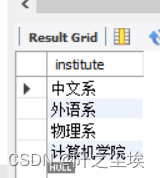
这里需要说明的一点是,如果将上面的SELECT子句字段列表中的“institute”改为星号(*),则会产生一系列的错误 。
通过错误提示可以得到如下启示,如果查询语句带有GROUP BY子句,则SELECT子句中通常不单独使用星号通配符。如果非要单独使用星号通配符,则应当在GROUP BY子句中列出表的所有字段名,字段名之间用逗号分隔。不过这样会使GROUP BY子句失去它的作用。因为,此时并不是按单个字段分组,而是使用GROUP BY后列出的所有字段的组合分组。
如果SELECT子句后是字段名列表,而这些字段名又不在聚合函数中,则应当在GROUP BY子句中列出所有这些字段名。此时,需要注意的还是,分组是按GROUP BY后的所有字段的组合分组,而并非是按单个字段分组。例如“GROUP BY institute, name”表示只有某几个记录中的所属院系和姓名都相同时才把这些记录分为一组。
聚合函数与分组配合使用
将数据分成小组的的很大原因是用于统计汇总,而统计汇总通常都要使用聚合函数,因此,聚合函数和分组经常被人们放在一起使用。
统计student表中,男生的总人数和女生的总人数。
SELECT sex AS 性别, COUNT(*) AS 人数
FROM student GROUP BY sex;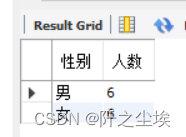
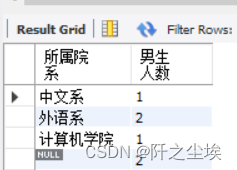
统计student表中,每个院系的男生人数。
SELECT institute AS 所属院系, COUNT(*) AS 男生人数
FROM student WHERE sex="男" GROUP BY institute;
GROUP BY子句中也可以有表达式,就是说可以按照表达式的结果分组数据。
为了方便查看哪一年雇佣了多少名外籍教师,在foreign_teacher表中按雇佣日期的年份统计人数。
SELECT YEAR(hiredate) AS 雇佣年份, COUNT(*) 雇用人数
FROM foreign_teacher GROUP BY YEAR(hiredate);除COUNT函数以外,GROUP BY子句还可以与其它聚合函数配合使用,下面是SUM函数与GROUP BY子句配合使用的例子。
统计查询course表中必修课的学分总和与选修课的学分总和。
SELECT type AS 类型, SUM(credit) AS 学分总和
FROM course GROUP BY type;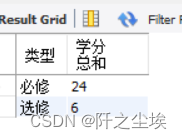
查询数据的直方图
直方图是表示不同实体之间数据相对分布的条状图。在一个查询语句中使用GROUP BY子句,不仅可以查询数据,又可以格式化数据生成图表。请看下面的例题。
从student表中,查询一个表示每个院系学生人数的直方图。
SELECT institute AS 所属院系, RPAD("",COUNT(*)*2,"=") AS 人数对比图
FROM student GROUP BY institute;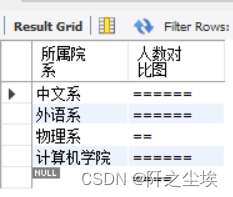
排序分组结果
如果想排序分组结果,则应当用使用ORDER BY子句。ORDER BY子句要放在GROUP BY子句的后面。实际上,ORDER BY子句要永远放在其它子句的后面。
在student表中,统计每个院系的学生人数,并按学生人数降序排序。
SELECT institute AS 所属院系, COUNT(*) AS 人数
FROM student GROUP BY institute ORDER BY COUNT(*) DESC; 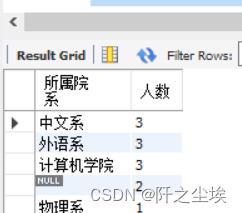
翻转查询结果
从student表中,查询每个院系的男生人数和女生人数。
SELECT institute AS 所属院系, sex AS 性别, COUNT(*) AS 人数
FROM student GROUP BY institute , sex ORDER BY institute;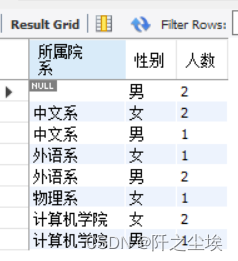
执行查询语句后得到的数据虽然正确无误,但是,当人们查看时会很不方便
在MySQL或SQL Server环境中,CASE表达式和GROUP BY子句联合使用会得到很多有用的数据表示,其中就包括反转查询结果的数据表示,请看下面的语句。
SELECT institute AS 所属院系, COUNT(CASE WHEN sex='男' THEN 1 ELSE NULL END) AS 男生人数,
COUNT(CASE WHEN sex='女' THEN 1 ELSE NULL END) AS 女生人数
FROM student GROUP BY institute;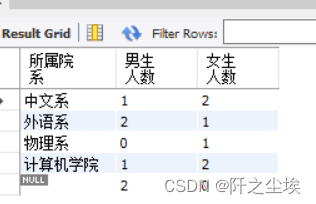
(其实就是类似pandas里面的.unstack()的用法,反解堆就行。)
使用HAVING子句设置分组查询条件
HAVING子句用于设置分组查询条件,即过滤不需要的分组。该子句通常和GROUP BY子句一起使用。单独使用HAVING子句没有太大的意义。
在student表中,统计计算机系和外语系的学生人数,并按学生人数降序排序。
SELECT institute AS 所属院系, COUNT(*) AS 人数
FROM student GROUP BY institute
HAVING institute IN('计算机学院','外语系')
ORDER BY COUNT(*);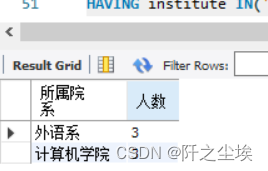
另一种实现方式:用WHERE子句代替HAVING子句,其语句如下所示。
SELECT institute AS 所属院系, COUNT(*) AS 人数
FROM student WHERE institute IN('计算机学院','外语系')
GROUP BY institute ORDER BY COUNT(*);
HAVING子句与WHERE子句的区别
HAVING子句与WHERE子句之后都写条件表达式,而且都会根据条件表达式的结果筛选数据。但它们是有区别的,主要区别汇总如下。
通常,HAVING子句总是和GROUP BY 子句配合使用,而WHERE子句可以不用任何子句的配合。下面来看一个非常典型的例子,该例题只能用HAVING子句筛选条件。
统计score表中,考试总成绩大于450分的学生的信息。
SELECT s_id AS 学号, SUM(result1) AS 考试总成绩
FROM score GROUP BY s_id HAVING SUM(result1)>=450
ORDER BY 考试总成绩 DESC; 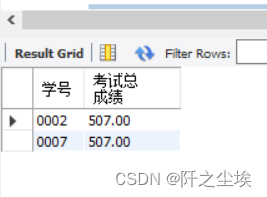
本例,必须用HAVING子句指定筛选条件,因为只有HAVING子句中才能使用聚合函数,而WHERE子句中不能使用聚合函数。下面使用前面介绍过的一个例题,演示WHERE子句不能用HAVING子句代替的情况。
统计student表中,每个院系的男生人数。
SELECT institute AS 所属院系,COUNT(*) AS 男生人数
FROM student WHERE sex='男' GROUP BY institute;