BlazePose: On-device Real-time Body Pose tracking
BlazePose:设备上实时人体姿态跟踪
论文地址:[2006.10204] BlazePose: On-device Real-time Body Pose tracking (arxiv.org)
主要贡献:
(1)提出一个新颖的身体姿态跟踪解决方案和一个轻量级的身体姿态估计神经网络,同时使用了热图(heatmap)和对关键点坐标的回归。
(2)基于堆叠沙漏结构(the stacked hourglass architecture),并使用编码器-解码器网络架构来预测所有关节的热图,然后使用另一个编码器直接回归到所有关节的坐标。
(3)在推断过程中可以丢弃热图分支,使其足够轻便,可以在手机上运行,FPS达到30+。

目录
一、摘要
二、介绍
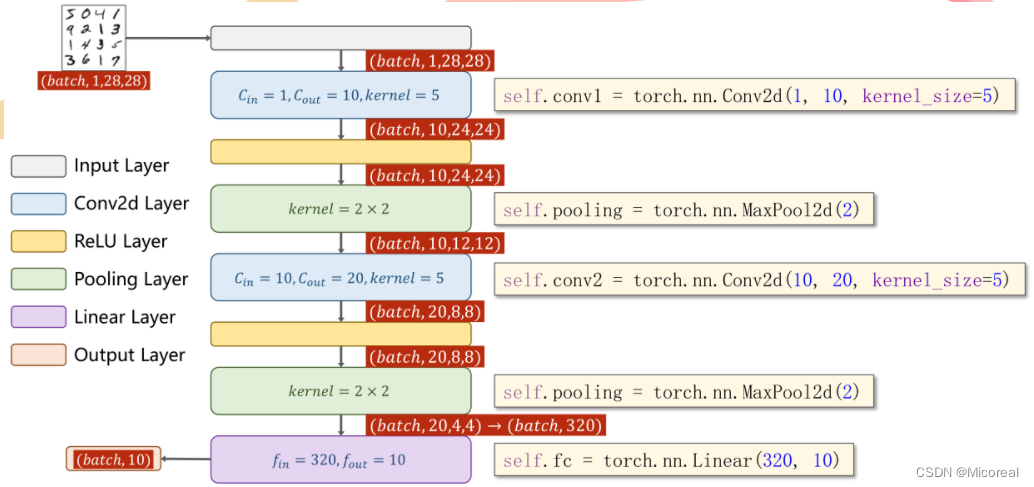
三、模型架构和管道(Pipeline)设计
(1)推理管道
(2)人员探测器
(3)Topology
(4)数据集
(5)神经网络架构
(6)对齐和遮挡增强
四、实验
五、应用
一、摘要
我们提出了BlazePose,一种用于人体姿态估计的轻量级卷积神经网络架构,用于在移动设备上进行实时推理。在推理过程中,该网络为单个人生成33个身体关键点,并在Pixel2手机上以每秒30帧以上的速度运行。这使得它特别适合实时用例图,如健身跟踪和手语识别。我们的主要贡献包括一个新颖的身体姿态跟踪解决方案和一个轻量级的身体姿态估计神经网络,它同时使用了热图(heatmap)和对关键点坐标的回归。
二、介绍
从图像或视频中进行人体姿态估计在各种应用中起着核心作用,如健康跟踪、手语识别和手势控制。这项任务是具有挑战性的,由于各种各样的姿势,许多自由度和遮挡。最近的工作《Deephigh-resolution representation learning for human pose estimation》《Pifpaf:Composite fields for human pose estimation》在位姿估计方面取得了显著的进展。常用的方法是为每个关节生成热图,同时为每个坐标细化偏移量。虽然这种热图的选择以最小的开销扩展到多个人,但它使单个人的模型比适用于手机上的实时推断大得多。在本文中,我们解决了这个特殊的用例,并展示了模型在几乎没有质量下降的情况下的显著加速。
与基于热图的技术相比,基于回归的方法虽然计算量较小,可扩展性强,但试图预测平均坐标值,往往无法解决潜在的歧义。《Stacked hour-glass networks for human pose estimation》的研究表明,堆叠沙漏结构(the stacked hourglass architecture)可以显著提高预测的质量,即使参数数量较少。在我们的工作中扩展这个想法,并使用编码器-解码器网络架构来预测所有关节的热图,然后使用另一个编码器直接回归到所有关节的坐标。我们工作背后的关键见解是,在推断过程中可以丢弃热图分支,使其足够轻便,可以在手机上运行。
三、模型架构和管道(Pipeline)设计
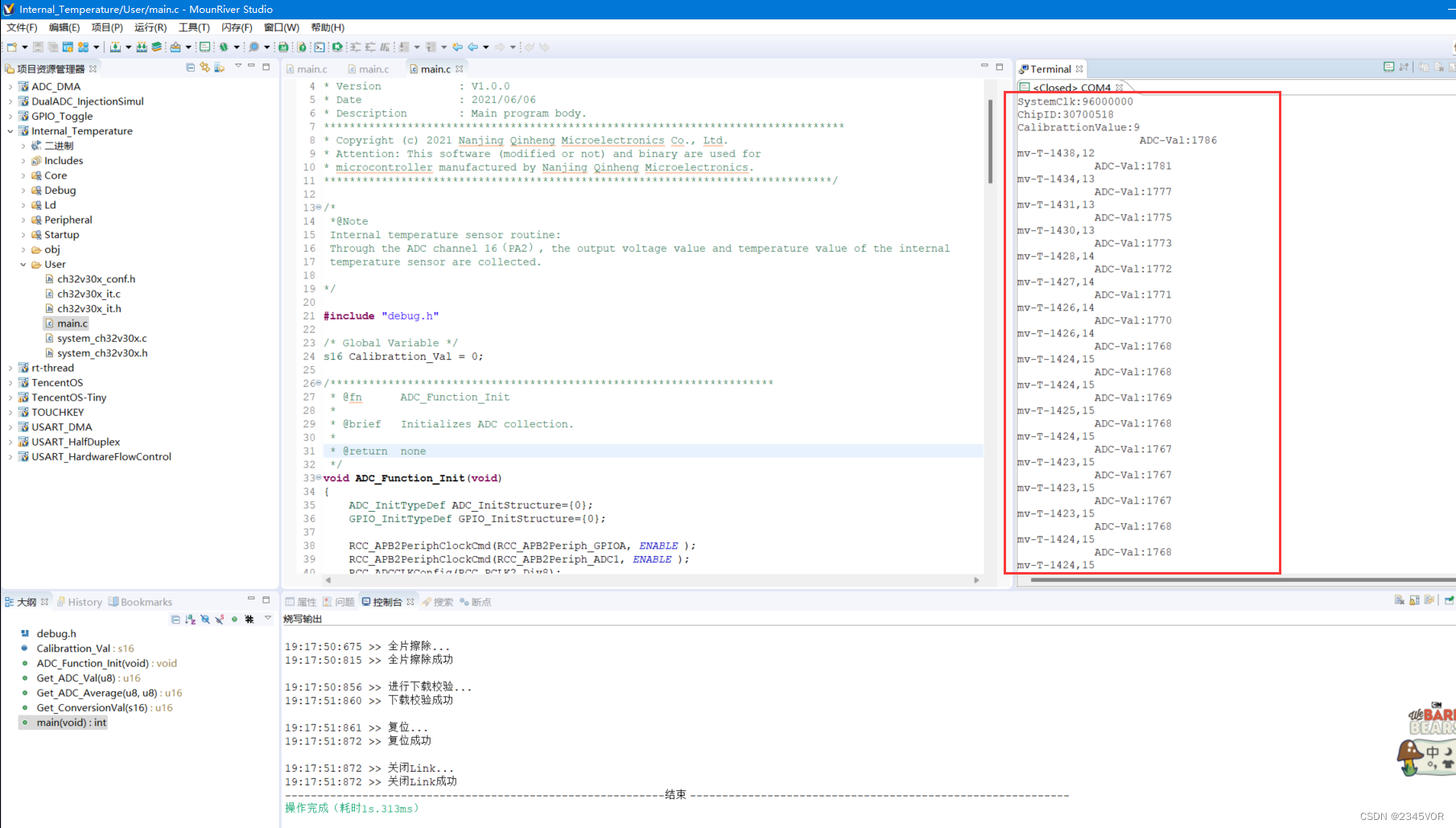
(1)推理管道

图1 推理管道
在推理过程中,我们使用了一个检测器跟踪器setup(见图1),它在各种任务上表现出优异的实时性能,例如 hand landmark pre-diction《On-device, real-timehand tracking with mediapipe》AND dense face landmark prediction《Real-time facial surface ge-ometry from monocular video on mobile gpus》。我们的管道由一个轻量级的身体姿态探测器和一个姿态跟踪器网络组成。跟踪器预测关键点坐标、当前帧中人物的存在以及当前帧的细化感兴趣区域。当跟踪器指示没有人类在场时,我们在下一帧重新运行检测器网络。
(2)人员探测器
大多数现代目标检测解决方案的最后一个后处理步骤都依赖于非极大值抑制( NMS )算法。这对于自由度较少的刚性物体效果较好。然而,该算法适用于像人类那样包含高度关节化姿态的场景,例如人们挥手或拥抱。这是因为对于NMS算法,多个模糊框满足交并比( IoU )阈值。为了克服这一限制,我们专注于检测一个相对僵硬的身体部分,如人体面部或躯干的边界框。我们观察到,在很多情况下,神经网络关于躯干位置的最强信号是人的面部(因为它具有高对比度的特征和较少的外观变化)。为了使这样的人物检测器快速轻量级,我们使强而有效的AR(增强现实)应用程序,假设在我们的单人用例中,人物的头部应该始终可见。因此,我们使用快速的设备上人脸检测器《Blaze-face: Sub-millisecond neural face detection on mobile gpus》作为人员检测器的代理。

图2 维特鲁威人通过我们的检测器与人脸检测边界框进行对齐
这个人脸检测器预测额外的个人特异性对齐参数:人的臀部之间的中点,环绕整个人的圆的大小,以及倾斜的(两肩中点和臀中点连线之间的夹角)。
(3)Topology

图3 33个关键点拓扑
我们提出了一种新的拓扑结构,使用人体上的33个点,采用了BlazeFace、BlazePalm和Coco使用的超集。这使得我们能够与各自的数据集和推理网络保持一致。
与OpenPose和Kinect的Topologies不同,我们仅使用面部、手部和脚部的最少数量的关键点来估计后续模型感兴趣区域的旋转、大小和位置。我们使用的拓扑结构如图3所示。其他信息见附录A。
Appendix A. BlazePose keypoint names
| 0. Nose | 11. Left shoulder | 22. Right thumb #2 knuckle |
| 1. Left eye inner | 12. Right shoulder | 23. Left hip |
| 2. Left eye | 13. Left elbow | 24. Right hip |
| 3. Left eye outer | 14. Right elbow | 25. Left knee |
| 4. Right eye inner | 15. Left wrist | 26. Right knee |
| 5. Right eye | 16. Right wrist | 27. Left ankle |
| 6. Right eye outer | 17. Left pinky #1 knuckle | 28. Right ankle |
| 7. Left ear | 18. Right pinky #1 knuckle | 29. Left heel |
| 8. Right ear | 19. Left index #1 knuckle | 30. Right heel |
| 9. Mouth left | 20. Right index #1 knuckle | 31. Left foot index |
| 10. Mouth right | 21. Left thumb #2 knuckle | 32. Right foot index |
(4)数据集
基于解决方案需要初始位姿对齐。我们将我们的数据集限制在整个人都可见的情况下,或者在臀部和肩部关键点可以自信地注释的情况下。为了确保模型支持数据集中不存在的严重遮挡,我们使用大量的遮挡模拟增强。我们的训练数据集由60K张单人或少人在场景中常见姿势的图像和25K张单人在场景中进行健身练习的图像组成。这些图像均由人类标注。
(5)神经网络架构
本系统的姿态估计组件预测所有33个行人关键点的位置,并使用流水线第一阶段提供的行人对齐建议( 3.1节)。

图4 网络架构
我们采用了热图、偏移和回归相结合的方法,如图4所示。我们只在训练阶段使用heatmap和offset loss,并在运行推断之前从模型中删除相应的输出层。因此,我们有效地使用热图来监督轻量级嵌入,然后由回归编码器网络使用。该方法部分受到了Stacked Hourglass方法的启发,但在我们的案例中,我们堆叠了一个微小的基于编码器-解码器热图的网络和一个后续的回归编码器网络。
我们积极利用网络所有阶段之间的跳跃连接,以实现高级和低级功能之间的平衡。然而,来自回归编码器的梯度并没有传播回热图训练的特征(注意图4 中的渐变停止连接)。我们发现这不仅改善了热图的预测,而且大大提高了坐标回归的精度。
(6)对齐和遮挡增强
相关的位姿先验是所提解决方案的重要部分。在增强和训练时的数据准备过程中,我们特意限制了角度、尺度和平移的支持范围。这允许我们降低网络容量,使网络更快,同时需要更少的计算和主机设备上的能量资源。
基于检测阶段或前一帧关键点,我们对齐人,使臀部之间的点位于通过的正方形图像的中心作为神经网络输入。我们估计旋转作为中间臀部和中间肩点之间的直线L,并旋转图像,使L平行于y轴。缩放比例是这样估计的,这样所有的身体点都适合于一个围绕身体的正方形包围盒,如图2所示。除此之外,我们还应用了10%的比例和移位增强,以确保跟踪器处理帧之间的身体运动和扭曲的调整。

图5 上半身情况的结果
为了支持不可见点的预测,我们在训练过程中模拟遮挡(填充不同颜色的随机矩形),并引入一个点可见性分类器,该分类器指示特定点是否被遮挡以及位置预测是否被认为不准确。这允许跟踪一个人,即使是在重要的遮挡情况下,如上半身,或者当大多数人的身体不在场景中时,如图5所示。
四、实验
为了评估模型的质量,我们选择OpenPose《Openpose: Realtime multi-person 2d pose estimation using part affinity fields》作为基线。为此,我们手动注释了两个内部数据集的1000幅图像,每个数据集都有1 - 2人在现场。第一个数据集,称为AR数据集,由各种各样的人类在野外的姿势组成,而第二个数据集只包括瑜伽/健身姿势。对于一致性,我们只使用了MS Coco [ 8 ]拓扑中的17个点进行评估,它是OpenPose和BlazePose的共同子集。作为评价指标,我们使用具有20 %容忍度的正确点百分比( PCK @ 0.2 ) (其中,如果2D Eu - clidean误差小于误差小于相应的每个子的躯干尺寸的20 % ,则要正确检测的点)。为了验证人类基线,我们要求两个注释器独立地重新注释AR数据集,并获得了97.2的平均PCK @ 0.2。
我们训练了两个不同能力的模型:BlazePose Full ( 6.9 MFlop , 3.5M Params)和BlazePoseLite ( 2.7 MFlop , 1.3M Params)。尽管我们的模型在AR数据集上表现出略差于OpenPose模型的性能,但在Yoga / Fitness用例上,BlazePose Full优于OpenPose。同时,BlazePose在单个中间层手机CPU上的执行速度是OpenPose在20个核心桌面CPU上执行速度的25 - 75倍,具体取决于所请求的质量。

表1 BlazePose vs OpenPose
1. Desktop CPU with 20 cores (Intel i9-7900X)
2. Pixel 2 Single Core via XNNPACK backend
五、应用
我们开发了这个新的、设备上的、单一的个人特异性人体姿态估计模型,以启用各种性能要求的用例,如手语、瑜伽/健身跟踪和AR。此模型可在移动CPU上近实时工作,并可在移动GPU上加速到超实时延迟。由于其33个关键点拓扑与BlazeFace《Blaze-face: Sub-millisecond neural face detection on mobile gpus》和BlazePalm《On-device, real-timehand tracking with mediapipe》一致,因此它可以作为后续手部姿态和面部几何估计《Real-time facial surface ge-ometry from monocular video on mobile gpus.》模型的基础。
我们的方法原生地扩展到更多的关键点、3D支持和额外的关键点属性,因为它不是基于热图/偏移图,因此不需要为每个新特性类型添加额外的全分辨率层。
>>> 如有疑问,欢迎评论区一起探讨!