文章目录
- 摘要
- 1 引言
- 1.1 贡献
- 3 模型
- 3.4 基于Rasch模型的嵌入
摘要
知识追踪(KT)是指根据学习者在教育应用中的过去表现预测未来学习者表现的问题。KT最近使用灵活的基于深度神经网络的模型的发展在这一任务中表现出色。然而,这些模型通常提供有限的可解释性,从而使它们不足以用于个性化学习,这需要使用可解释的反馈和可操作的建议来帮助学习者获得更好的学习结果。在本文中,我们提出了注意力知识追踪(AKT),它将灵活的基于注意力的神经网络模型与一系列受认知和心理测量模型启发的新颖、可解释的模型组件相结合。AKT使用了一种新颖的单调注意力机制,将学习者对评估问题的未来反应与他们过去的反应联系起来;除了问题之间的相似性外,注意力权重还使用指数衰减和上下文感知的相对距离测量来计算。此外,我们使用Rasch模型对概念和问题嵌入进行正则化;这些嵌入能够在不使用过多参数的情况下,捕获关于同一概念的问题之间的个体差异。我们在几个真实世界的基准数据集上进行了实验,结果表明AKT在预测未来学习者反应方面优于现有的KT方法(在某些情况下,AUC高达6%)。我们还进行了几个案例研究,并表明AKT具有出色的可解释性,因此在现实世界的教育环境中具有自动反馈和个性化的潜力。
1 引言
数据分析和智能辅导系统[32]的最新进展使大规模学习者数据的收集和分析成为可能;这些进步暗示了大规模个性化学习的潜力,通过分析每个学习者的学习历史数据,自动为他们提供个性化反馈[24]和学习活动推荐[11]。
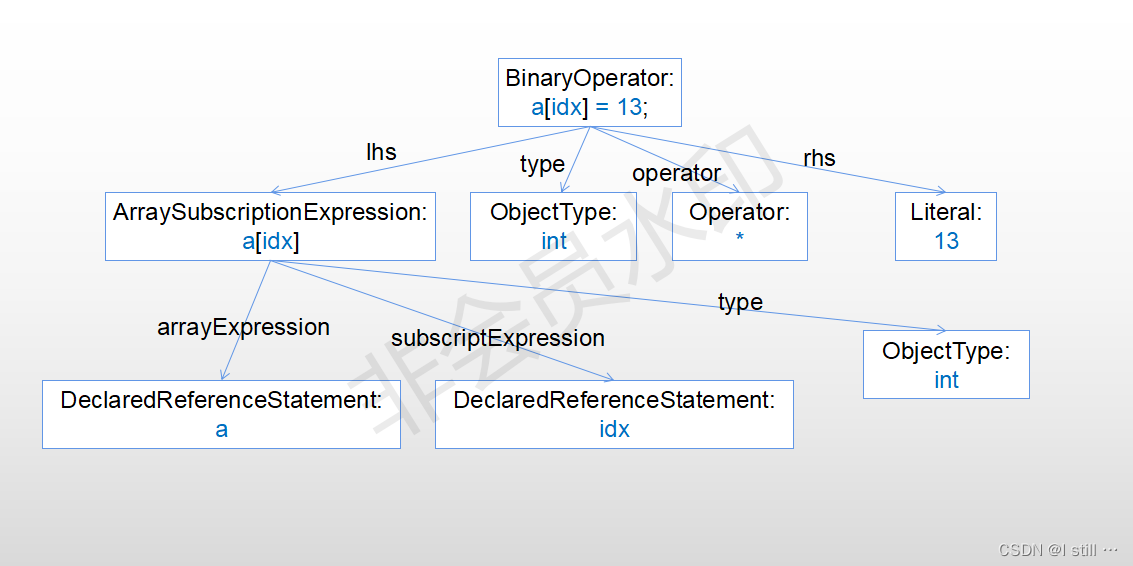
学习者数据分析中的一个关键问题是根据他们过去的表现预测未来学习者的表现(他们对评估问题的反应),这被称为知识追踪(KT)问题[3]。在过去的30年里,解决KT问题的许多方法都是基于两个常见的假设:i)学习者过去的表现可以通过一组变量来概括,这些变量代表了他们在一组概念/技能/知识组件上的当前潜在知识水平;ii)学习者未来的表现可以使用他们当前的潜在概念知识水平来预测。具体地说,让t表示一组离散时间指标,我们有以下学习者的知识和表现的通用模型:
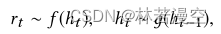
2010年以前KT方法的早期发展可分为两类。第一种围绕贝叶斯知识追踪(BKT)方法[19,35]展开,其中知识(ht)是一个二值标量,表征学习者是否掌握了问题所涵盖的(单个)概念。由于响应(rt)也是二进制值,响应和知识演化模型只是简单的噪声二进制通道,由猜测、滑动、学习和遗忘概率参数化。第二类以项目响应理论(IRT)模型[16]为中心,将这些模型(尤其是s型链接函数)作为响应模型f(·);对于涵盖多个概念的问题,学习者的知识水平被建模为实值向量(ht)。
其中SPARFA-Trace方法[13]使用了一个简单的仿射变换模型作为显式知识演化模型д(·)。其他方法,例如,加法因子模型[1],性能因子分析[22],难度,能力和学生历史(DASH)模型[15],以及一些最近的方法,包括知识因子分解机[30]和DASH模型的扩展,DAS3H模型[2],使用手工制作的特征,如以前尝试的次数,成功和失败的每个概念在他们的知识进化模型。这两种方法都依赖于专家标签将问题与概念联系起来,因此具有良好的可解释性,因为它们可以有效地估计每个学习者对专家定义概念的知识水平。
KT最近的发展集中在使用更复杂和灵活的模型来充分利用大规模学习者反应数据集中包含的信息。深度知识追踪(DKT)方法[23]是通过使用长短期记忆(LSTM)网络[7]作为知识演化模型д(·)来探索KT使用(可能是深度)神经网络的第一个方法。由于LSTM单元是非线性的复杂函数,它们比仿射变换更灵活,更能捕捉真实数据中的细微差别。
动态键值记忆网络(DKVMN)方法通过使用外部记忆矩阵(Ht)来表征学习者知识[36],对DKT进行了扩展。矩阵被分为两部分:一个静态的“关键”矩阵,包含每个概念的固定表示;一个动态的“价值”矩阵,包含每个学习者在每个概念上不断发展的知识水平。DKVMN还在响应和知识演化模型的外部矩阵上使用单独的“读”和“写”过程;这些过程使它比DKT更灵活。DKT和KVMN在预测未来学习者表现[9]方面表现最先进,并已成为新KT方法的基准。
**自注意知识追踪(self- attention knowledge tracing, SAKT)方法[18]是第一个在KT背景下使用注意机制的方法。**注意力机制比循环和基于记忆的神经网络更灵活,并在自然语言处理任务中表现出优越的性能。SAKT的基本设置与Transformer模型[29]有许多相似之处,Transformer模型[29]是许多序列到序列预测任务的有效模型。然而,我们观察到,在我们的实验中,SAKT并不优于DKT和DKVMN;详见第四节。可能的原因包括i)不像语言任务中单词之间强烈的远距离依赖更常见,未来学习者表现对过去的依赖可能局限在一个更短的窗口内,以及ii)学习者反应数据集的规模比自然语言数据集低几个量级,不太可能从高度灵活和大规模的注意力模型中受益。
更重要的是,现有的KT方法中没有一种能够同时兼顾未来性能预测和可解释性。早期的KT方法表现出出色的可解释性,但在未来学习者表现预测方面并没有提供最先进的表现。最近基于深度学习的KT方法在这方面表现出色,但可解释性有限。因此,这些KT方法并不能完全满足个性化学习的需求,个性化学习不仅需要准确的成绩预测,还需要能够提供自动化的、可解释的反馈和可操作的建议,以帮助学习者获得更好的学习结果。
1.1 贡献
为了预测学习者对当前问题的反应,我们提出了注意力知识追踪(AKT)方法,该方法使用一系列注意力网络来在这个问题和学习者过去回答过的每个问题之间建立联系。我们将我们的主要创新总结如下:
- 与现有的使用原始问题和回答嵌入的注意力方法相反,我们将原始嵌入放入上下文中,并通过考虑学习者的整个实践历史来使用过去问题和回答的上下文感知表示。
- 受认知科学关于遗忘机制的发现的启发,我们提出了一种新的单调注意力机制,该机制使用指数衰减曲线来降低遥远过去问题的重要性。我们还开发了一种上下文感知的测量方法来描述学习者过去回答的问题之间的时间距离。
- 利用Rasch模型(一个简单且可解释的IRT模型),我们使用一系列基于Rasch模型的嵌入来捕获问题之间的个体差异,而无需引入过多的模型参数。
我们在几个基准的现实世界教育数据集上进行了一系列实验,将AKT方法与最先进的KT方法进行比较。我们的研究结果表明,AKT(有时显著)在预测未来学习者表现方面优于其他KT方法。此外,我们对每个关键的AKT模型组分进行了消融研究,以证明其价值。我们还进行了几个案例研究,以表明AKT具有出色的可解释性,并具有自动反馈和实践问题推荐的潜力,这两个都是个性化学习的关键要求
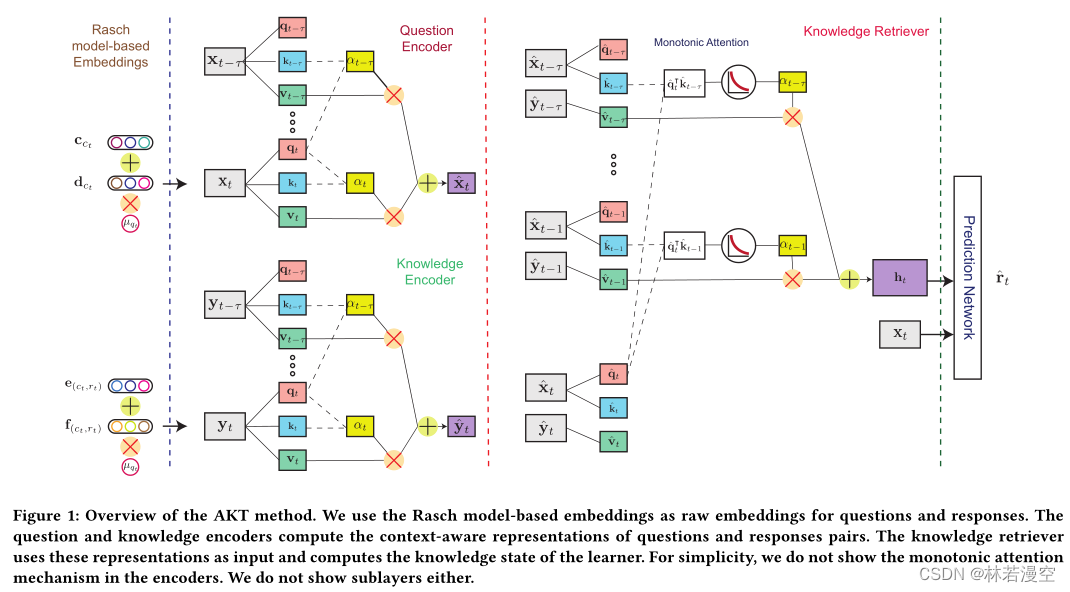
3 模型
3.4 基于Rasch模型的嵌入
正如我们上面讨论的,现有的KT方法使用概念来索引问题,即设置qt = ct。由于数据稀疏性,这个设置是必要的。设Q表示问题总数,L表示学习者数量。在大多数真实世界的学习者反应数据集中,学习者反应的数量与CL相当,远低于QL,因为许多问题分配给少数学习者。因此,使用概念来索引问题可以有效地避免过度参数化和过拟合。然而,这种基本设置忽略了涵盖相同概念的问题之间的个体差异,从而限制了KT方法的灵活性及其个性化潜力。
我们使用心理测量学中一个经典而强大的模型,即Rasch模型(也称为1PL IRT模型)[16,25]来构建原始问题和知识嵌入。Rasch模型用两个标量来描述学习者正确回答问题的概率:问题的难度和学习者的能力。尽管它很简单,但当知识是静态的时,它已被证明在正式评估中实现了与更复杂的学习者表现预测模型相当的性能[12,31]。