Tube Convolutional Neural Network (T-CNN) for Action Detection in Videos
文章目录
- Tube Convolutional Neural Network (T-CNN) for Action Detection in Videos
- 摘要及贡献
- 相关工作
- Generalizing R-CNN from 2D to 3D
- 框架结构
- Tube Proposal Network(TPN)
- 结果及讨论
- Region proposal network (RPN)vs Tubelet proposal network(TPN)理解
- Related
摘要及贡献
本文提出了端到端的深度卷积网络T-CNN
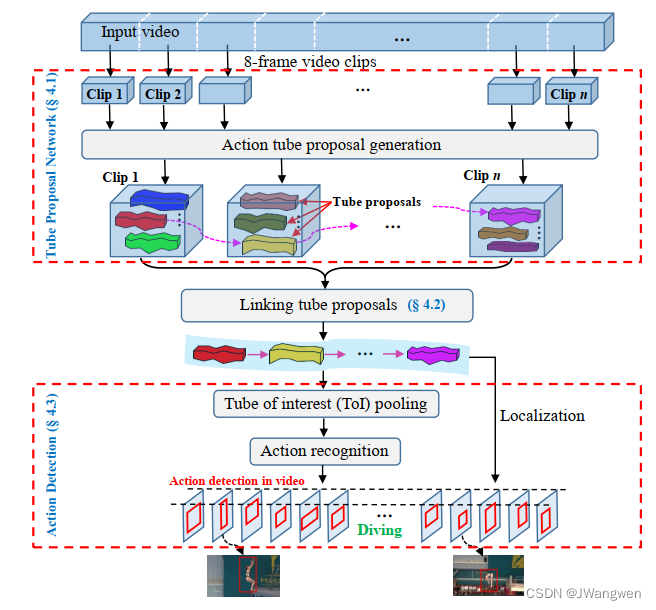
首先一段视频首先被分割成固定长度的片段(8帧)-------> 这些片段被送到Tube Proposal Network(TPN)并生成一系列的 tube proposal --------> 根据每个视频片段中的tube proposal 的行为得分和相邻proposal之间的重叠进行连接起来(即linking tube proposals),形成一个完整的tube proposal用于视频中的时空行为定位 -------> 最后the Tube-of-Interest(TOI)pooling被用于连接的行为tube proposal 来形成一个固定长度的特征向量用于行为标签预测。
贡献如下:
- 提出了一种基于端到端深度学习的视频行为检测方法。它直接对原始视频进行操作,利用单个3D网络捕捉时空信息,根据3D卷积特征进行行为定位和识别。据我们所知,这是第一个利用3D ConvNet进行行为检测的工作。
- 我们引入了一个Tube Proposal Network (TPN),它利用在时间域的跳跃池,以保存时间信息的行动定位在三维体积。
- 我们在T-CNN中提出了一种新的池化层Tube-of-Interest (ToI) pooling,ToI pooling是R-CNN感兴趣区域(Region-of-Interest, RoI)池化层的3D形式。它有效地缓解了变化的空间和时间大小的Tube Proposal Network的问题。我们证明了ToI池化可以大大提高识别结果。
相关工作
-
CNN和3DCNN在action detection的相关方法
-
action detecction相关方法
-
object detection流程
本文将R-CNN从2D图像区域推广到3D视频用于action detection
Generalizing R-CNN from 2D to 3D
与可以裁剪的图像不同,视频在时间维度上有很大差异,因此,我们将输入视频分成固定长度(8帧)的视频片段,这样视频片段就可以在固定大小的ConvNet架构下进行处理。此外,基于剪辑的处理降低了GPU内存的成本。
3D CNN相对于2D CNN的一个优点是它通过在时间和空间上应用卷积来捕捉运动信息,由于我们的方法不仅在空间维度上使用了3D卷积和3D max pooling,而且在时间维度上也使用了3D卷积和3D max pooling,从而减小了视频片段的大小,同时集中了可区分的信息。temporal pooling在识别任务中是很重要的,因为它能更好地建模视频的时空信息并减少一些背景噪声。然而,时间顺序信息丢失了。这意味着如果我们任意改变视频剪辑中的帧的顺序,最终的3D最大特征集将是相同的。这在行为检测中是有问题的,因为它依赖于特征立方体来获得原始帧的边界框。——时间信息很重要,不能任意改变帧的顺序
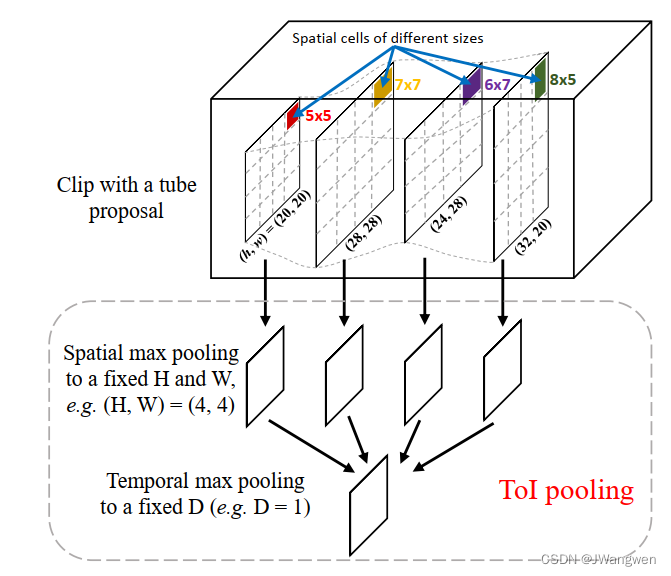
由于一个视频被一个片段一个片段地处理,action tube为不同的片段产生了不同的空间和时间大小的action tube proposal。这些片段候选框需要链接到一个tube proposal sequence,该序列用于行为标签预测和定位。为了产生一个固定长度的特征向量,我们提出了一种新的池化层-Tube-of Interest。ToI池化层是R-CNN感兴趣区域(Region-of-Interest, RoI)池化层的三维泛化。经典的最大池化层定义了内核大小、步长和填充,这些决定了输出的形状。而对于RoI池化层,首先确定输出形状,然后确定核的大小和步幅。相对于以二维特征图和二维区域作为输入的RoI池,ToI pooling deals with feature cube and 3D tubes。表示特征立方体的大小为d × h × w ,其中d、h、w分别表示特征立方体的深度、高度和宽度。feature cube中的ToI由一个d-by-4 矩阵定义,该矩阵由分布在所有帧中的d个box组成。Box由一个四元组( x 1 i , y 1 i , x 2 i , y 2 i )定义,该四元组指定第i个特征图的左上角和右下角,由于d bounding boxes 不同的大小、纵横比和位置,为了应用时空池化,空间域池化和时间域池化是分开进行的。首先,h × w 特征图映射被分为H × W bins,每个单元对应一个大小为h/w的单元,在每个单元格钟,应用最大池化来选择最大值,其次,空间池化的d个特征被暂时分为D bins,和第一步相似,d/D相邻特征图杯分组在一起来形成标准的时间最大池化。因此,TOI池化层的固定输出大小是DxHxW,如下图
框架结构
核心结构是TPN为每个片段产生tube proposals
Tube Proposal Network(TPN)
- 目标:输入8帧图片,输出8个连续的bbox。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3mQKPXSy-1675910590283)(C:%5CUsers%5C%E7%8E%8B%E4%B8%80%E4%BA%8C%5CAppData%5CRoaming%5CTypora%5Ctypora-user-images%5Cimage-20230207165308635.png)]](https://img-blog.csdnimg.cn/5f0c7cacc87141d5a1fc6eea4eed3ccb.png)
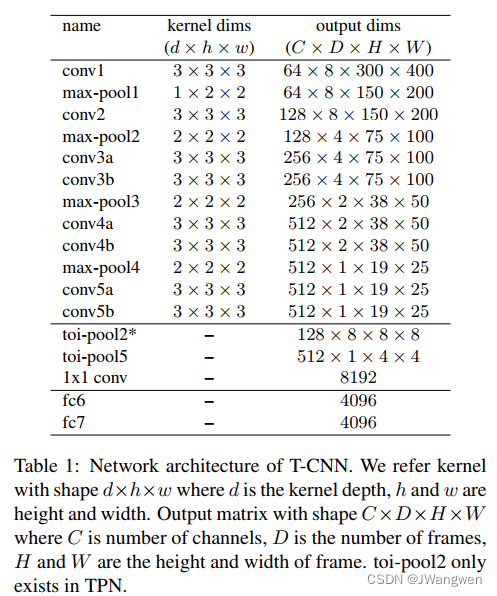
针对8帧视频片段,采用三维卷积和三维池化方法提取spatio-temporal feature cube ,我们的3D ConvNet由七个三维卷积层和四个三维最大池化层组成。我们用d×h×w表示三维卷积/池化的核形状,其中d;h;W分别为深度、高度和宽度。在所有卷积层中,kernel size 为3×3×3, padding和stride保持为1。filter数量是前3个卷积层分别为64、128和256,其余的卷积层为512。第一个3D最大池化层的kernel size设置为1 ×2×2,其余3D最大池化层的内核大小设置为2×2×2。网络架构的详细信息如表1所示。我们使用C3D模型作为预训练模型,并在我们的实验中对每个数据集进行微调.
在conv5之后,时间大小减少到1帧(即深度为D = 1的特征立方体),我们在conv5 feature tube生成bounding box proposals
Anchor bounding boxes selection
在Faster RCNN中,Anchor的数量被手工定义例如,9个anchor包含3个尺度和3个横纵比,在本文中我们不选择手工挑选的anchor boxes,而是在训练集上应用k-means聚类来学习12个anchor boxes(即聚类质心)。这种数据驱动的anchor boxes方法可以适应不同的数据集
每个包围框都与一个“actionness”分数相关联,该分数衡量框中的内容对应于有效动作的概率,我们为每个包围框分配一个二进制类标签(是否是一个动作),动作得分小于阈值的包围框将被丢弃。在训练阶段,IoU与任意ground-truth box重叠大于0.7或Intersection-over-Union最大的边界框(IoU)与ground-truth box(后一种情况被考虑,以防前一种情况可能找不到正样本)重叠被认为是正边界盒的建议
Temporal skip pooling
- 存在的问题:3D CNN其实丢失了帧的顺序信息(order),而temporal skip pooling就是为了保留order信息。
由conv5 feature cube生成的bounding box可用于边界框回归的帧级动作检测,然而,由于时间最大池化的时间集中(8帧到1帧)会导致原始8帧的时间顺序丢失。因此,我们使用时间跳过池(temporal skip pooling) 引入时间顺序进行帧级检测。
- 具体实现:
- 8帧输入到conv5的时候temporal纬度已经变为1了,通过普通的检测方法获取bbox propoals。
- 在对上述proposal提取特征的时候,到conv2提取。因为conv2时没有对temporal纬度进行操作,可以认为conv2还保留着order信息。
- 输入 conv5 的 proposal + conv2 的 feature,通过类似于RoI Pooling的操作就能提取定长特征,用于后面的操作。
- 后面bbox reg的输入是通过 proposal + (conv2 & conv5) 提取的。
- 8次bbox reg的输入都一致。
因此,以conv5 feature cube中有5个边界框为例,则在每个conv2特征片中对应的位置映射5个缩放的边界框。这将创建5个tube proposals ,如图3所示
Linking Tube Proposals
-
目标:连接不同clip的tube。
-
link的主要条件有两个:actionness(即每个clip中tube的动作得分,得分越高表示存在动作的概率越大)和overlap(即不同clip间tube的IoU,前一个tube最后一帧与后一个tube第一帧的IoU)。
-
通过公式计算前后帧tube之间的得分,按照得分高低进行连接
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Xn8qhgaM-1675910590284)(C:%5CUsers%5C%E7%8E%8B%E4%B8%80%E4%BA%8C%5CAppData%5CRoaming%5CTypora%5Ctypora-user-images%5Cimage-20230207112043252.png)]](https://img-blog.csdnimg.cn/20942573d0824585bba5d968a28ba89c.png)
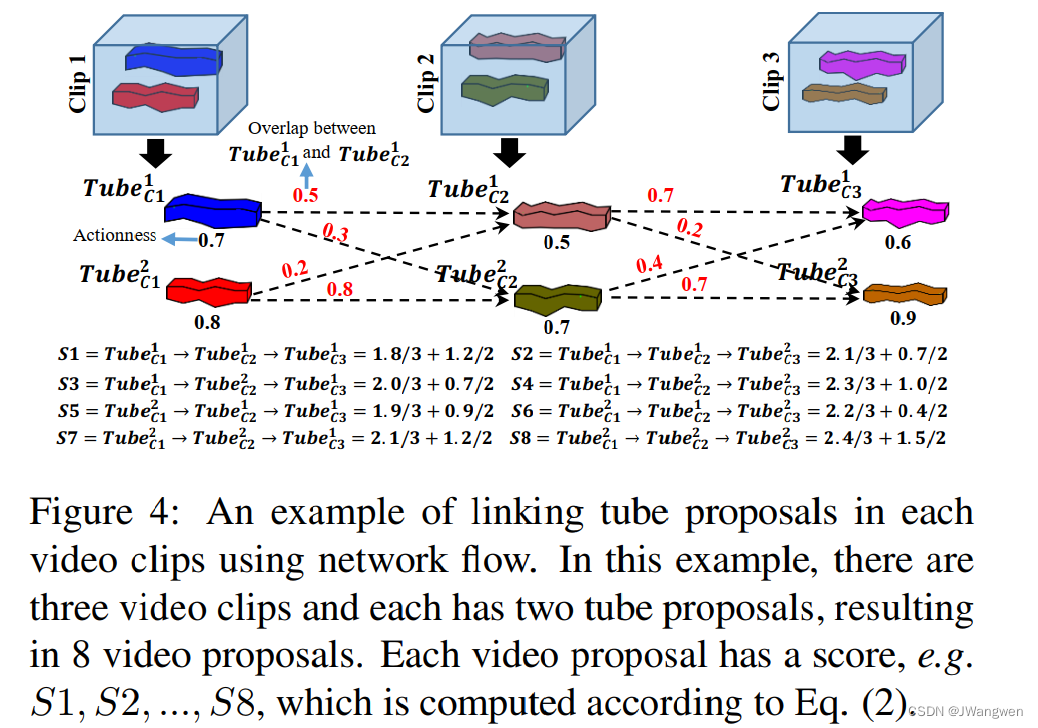
Action Detection
-
目标:输入上一部得到的Linked之后的tube,对tube进行行为分类。
-
由于tube长度不一样,要对所有tube提取得到定长特征,就需要使用文中提出的ToI Pooling。
结果及讨论
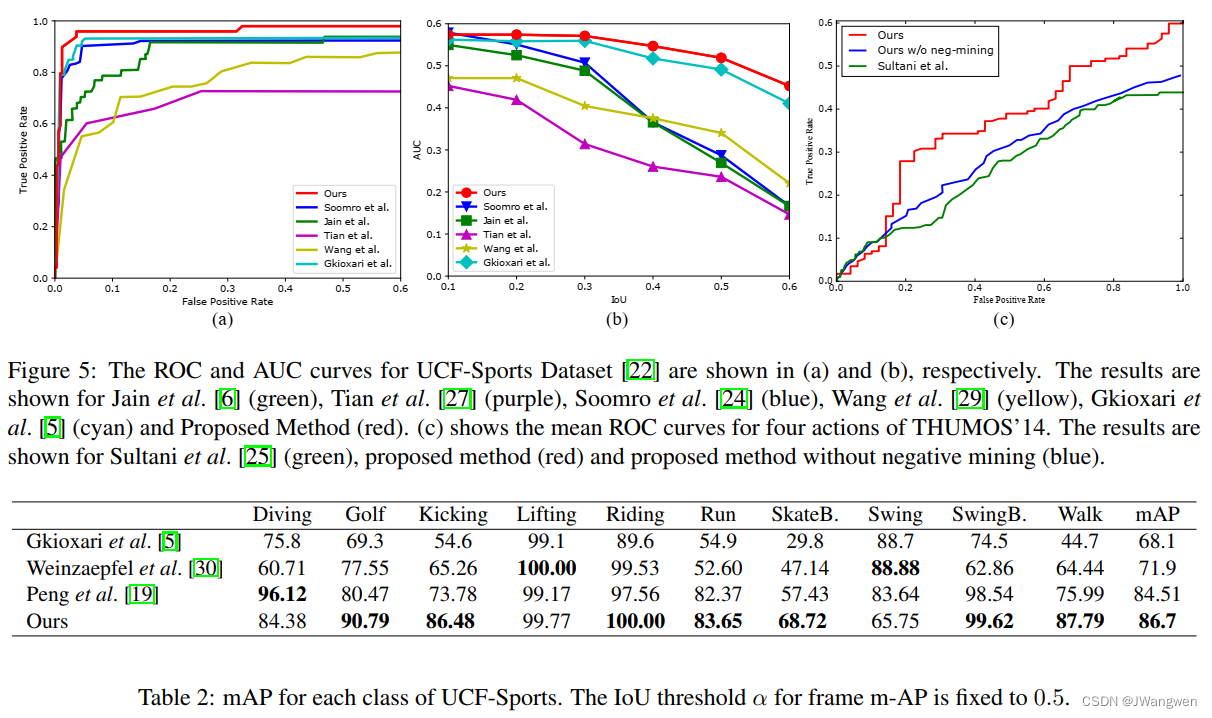

- 这个不能用在online版本中。
- TOI pooling 可以与two-stream CNN结合
Region proposal network (RPN)vs Tubelet proposal network(TPN)理解
首先我们先回顾一下物体检测的主流方式,通常会包含以下几步:
生成一系列的候选框,这些候选框称为proposals
根据候选框判断候选框里的内容是前景还是背景,即是否包含了检测物体
用回归的方式去微调候选框,使其更准确地框取物体,这过程我们称bounding box regression
region proposal: 候选框区域,选出来的区域。
anchor box: 手工设计或者聚类得到的定位中心点框(与proposal区别是这些框是基于某一点的)
Bounding box(bbox): 将这些 anchor bbox回归之后的结果叫bounding box,就是更进一步的候选框,离标答更近了,从某种程度也是proposal(候选框)。
RPN主要包含以下几步:
生成Anchor boxes.
判断anchor boxes包含的是前景还是背景.
回归学习anchor boxes和groud truth的标注的位置差,来精确定位物体
假设每个anchor生成了k个boxes,每个anchor box会输入到2个卷积网络,分别是cls layaer和reg layer。RPN的训练数据是通过比较anchor boxes和GT boxes生成的,会在图片中采样一些anchor boxes,然后计算anchor box和GT box的IOU来判断该box是前景还是背景,对于是前景的box还要计算其与GT box之间各个坐标offset。

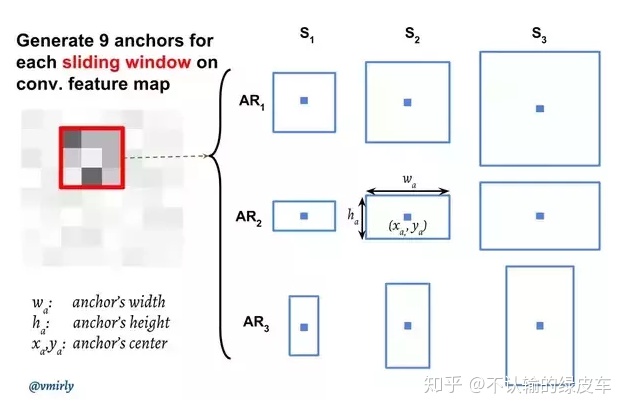
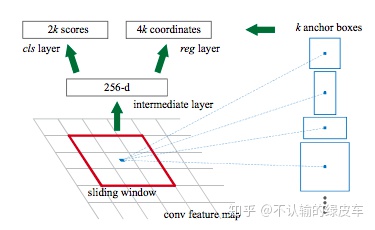
Tubelet Proposal Network(TPN)
与静态目标检测中的候选边框(bounding box proposals)相同,视频目标检测中的边框被称为tube,tube是一系列候选边框的集合,视频目标检测算法使用tube来获得时间上的信息。因此,在Tubelet Proposal Network(TPN)中,从上一步得到了base 3D network的特征图,采用手工设计或者聚类的方法设计tube anchor ,每个tube anchor都有两个标签,一个是CLS——显示来自该空间位置的foreground tube与proposal tube是否有很高的重叠。一个是REG——输出一个4T-dimensional矢量编码位移,该位移是根据tube anchor中每个box的坐标得来tube bounding box。
相当于
region proposal = tube proposal
feature map = feature cube 由d个boxes组成的四维矩阵(因为加了时间)
anchor = tube anchor 采用手工设计或者聚类的方法设计tube anchor(如本文使用的12个anchor聚类)
bounding box = tube bounding box 从tube anchor中进行有无action进行打分并计算IOU,坐标为(x1,y1,x2,y2)为左上和右下角
conv5得到的feature cube
Related
论文浏览(38) Tube Convolutional Neural Network (T-CNN) for Action Detection in Videos - 爱码网 (likecs.com)
详解Region Proposal Network - 知乎 (zhihu.com)
【目标检测】概念理解:region proposal、bounding box、anchor box、ground truth、IoU、NMS、RoI Pooling_kentocho的博客-CSDN博客_ground truth iou